文章目錄
- 一、商業資料分析概念
- 1.商業資料分析引入
- 2.什么是商業資料分析?
- 3.所需技能
- 4.基本分析流程和供應鏈各個環節
- 5.商業理解
- 6.需要用到的工具
- 二、資料特性
-
- 三、資料分析型別、可視化與資料驅動開發團隊
- 1.不同型別的分析
- 2.資料可視化
- 3.資料驅動開發團隊
一、商業資料分析概念
1.商業資料分析引入
先列舉幾個案例:
(1)請估計一下2020年八月份在北京賣出有多少雙鞋子?
顯然,這是一個很開放的問題,并不像在學校里的題目都有標準答案,是需要經過自己的思考、定義和分析的,
(2)Corley主營在網上賣手機殼,根據銷售資料,發現8月份比7月份購買手機殼的顧客數量下降了10%,怎么回事?
這也是一個開放的問題,可以從內部和外部兩方面來思考問題:
- 外部
是手機銷售量下降了還是同行業競爭對手出現了,或者經濟不景氣?物流延遲? - 內部
銷售環節出了問題?哪一類用戶下降?
重點需要分析背后的原因,因此需要分析問題的能力,
很多時候我們覺得學校學到的東西都沒用,那只是因為我們沒有將學校的知識與實際應用結合起來,
2.什么是商業資料分析?
商業資料分析從業要求:
舉一個例子,拿學武功來說,武功秘籍就是基礎知識,寶劍就是工具,在實際練武程序中就得到了面對不同武功和不同對手所需要的方法和技巧,慢慢培養出了業務能力,出神入化之后形成了自己的軟技能,
基于資料通過分析手段挖掘出商業價值,解決商業問題,并通過分析商業問題建立相應的分析模型,
上面的幾個案例都可以通過資料分析的手段得出結論,
3.所需技能
資料分析大致分為5個階段:資料獲取、資料處理、資料分析與建模、資料解釋與呈現、驗證及優化,
這五個階段在上述的基礎知識、工具和業務能力方面又有不同的要求,具體如下:
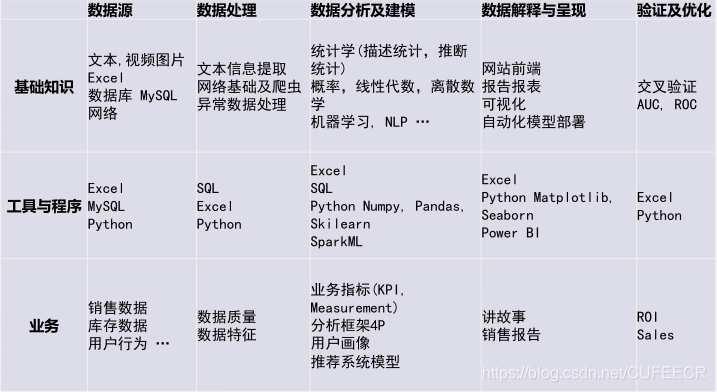
4.基本分析流程和供應鏈各個環節
再舉一個案例:
(3)Corley賣鞋,2020年9月前10天就完成了本月計劃的80%,業績是好還是不好?
可能有人會覺得好,畢竟三分之一的時間就賣出了大部分,但是實際上并不一定好:
要看整個月的銷售情況,如果前10天銷量處于上升趨勢,剩下的時間處于快速下降并保持很低的水平,有可能是完成不了計劃的;
還好看以前的銷售情況,比如說同比銷售額,是不是可能比現在還好;
和其他競爭對手相比,是否比他們好,
銷量好或者不好需要從多個維度進行衡量,而不是單純地給出一個答案;
每個行業不同,相應的分析方法和思路也千差萬別,
一個基本的分析流程如下:
- 理解商業問題
根據具體的商業場景理解商業問題, - 準備階段
根據相應的商業場景進行計劃和準備,需要哪些資料、怎么進行分析, - 資料分析
- 解釋結果
供應鏈的各個環節如下:
分析時,不僅要從銷售價格來分析,也要從源頭即成本進行分析,處于供應鏈的哪個位置;
找整個商業供應鏈出現問題的主要環節,找出問題,
5.商業理解
對于一個事件,會有很多因素,可能都會影響到結果,
在商業資料分析中,需要進行多維度思考,包括產品、位置、時間等角度,比如零售業中有人、貨、場的概念,如下:
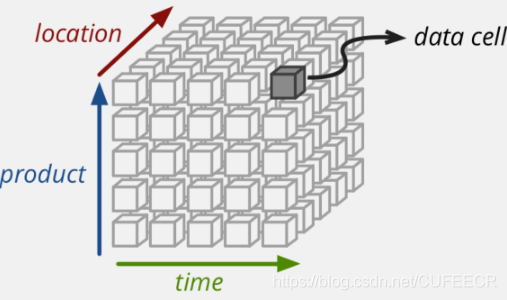
從點、線、面的角度評價銷售業績:
分析自己9月份業績即為點;
分析與去年同期相比即為線;
與其他人相比即為面,
獲取知識的金字塔DIKW如下:
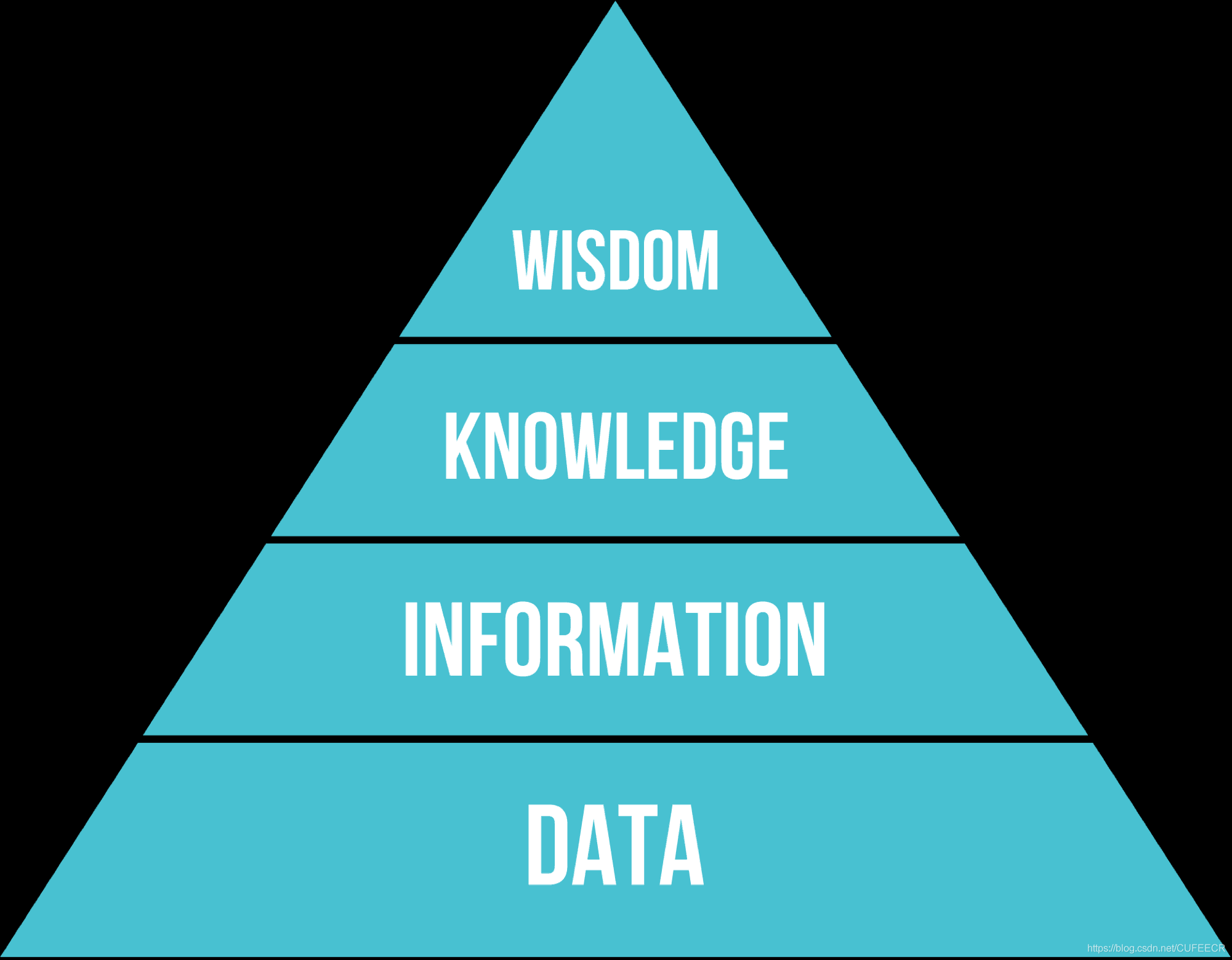
從原始資料中提取出資訊,并通過總結得到知識,逐漸積累成為智慧,
6.需要用到的工具
(1)Excel是最普及的資料處理和分析工具,作為Office三件套之一,受到各行業廣泛的使用,也很容易上手,
(2)思維導圖工具,如XMind、Mind Master等,可以整理知識體系、梳理思維,
(3)專業的Python資料分析工具Anaconda,可以進行Python基礎編程、資料分析、建模計算等,自帶了很多包,可以直接點擊加QQ群  963624318 在群檔案夾Python相關安裝包中下載安裝,
963624318 在群檔案夾Python相關安裝包中下載安裝,
(4)關系型資料庫軟體MySQL,是最常見的的資料庫之一,個人一般直接使用社區版即可,可以到MySQL官網https://dev.mysql.com/downloads/mysql/中下載,由于官網下載較慢也點擊加QQ群 963624318 在群檔案夾資料庫軟體中下載,然后解壓并執行安裝配置即可,具體可參考https://www.cnblogs.com/zhangkanghui/p/9613844.html,
除此之外,還可以充分利用Github開源平臺https://github.com/,可以查詢一些開源專案、查看原始碼,是一個學習的平臺,
二、資料特性
1.資料粒度
資料存在特定的特點,其中之一為粒度,
較標準的定義為:
資料粒度是指資料倉庫中資料的細化和綜合程度,
根據資料粒度細化標準:細化程度越高,粒度越小;細化程度越低,粒度越大,
很多時候得到的資料為匯總的資料,比如對于電商來說,得到了每個月的銷售情況,要預測每天的銷售情況是不現實的;
匯總資料可以獲取整體趨勢,
而對于原始資料,可以為每一種商業模式確定相應的指標KPI,比如電商行業的常見指標如下:
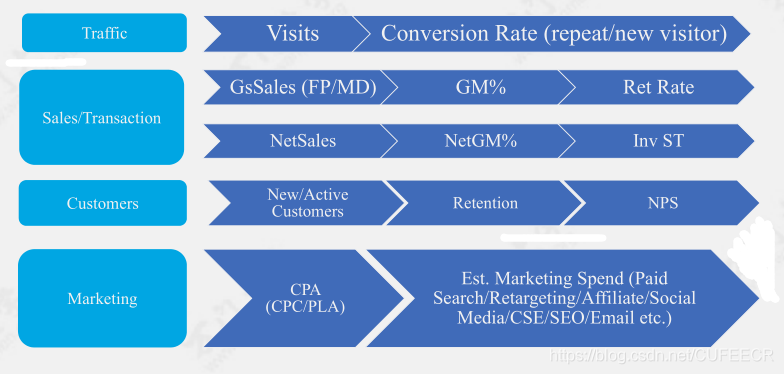
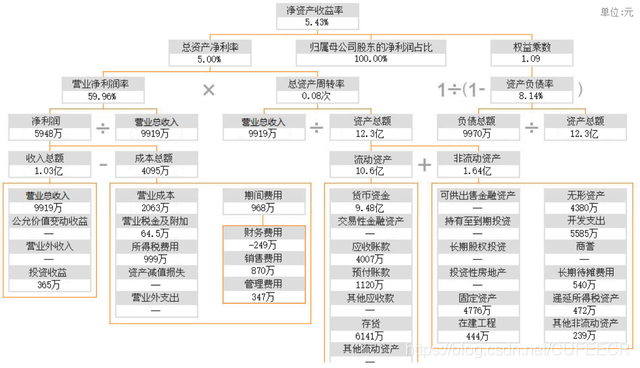
并且可以使用杜邦分析法評價指標組合進而確定經營業績,示意如下:
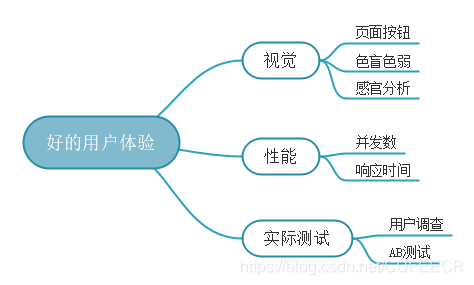
對于Leader來說,很重要的一個要求是用戶體驗好,好的用戶體驗好主要包括以下方面:
分析流程可以進一步細分如下:
- 目標
比如設定PV、DAU(榷訓)等指標, - 收集資料
根據需求、按照指定的方法獲取資料,并過濾掉無用的資訊, - 資料探索
發現收集到的資料的特點、分布特征,并探索資料間的關系, - 特征工程
資料中哪些重要, - 開發計算
進行建模計算、并產生結果,如線性回歸、邏輯回歸, - 評估
假如有一個JSON格式的電影評分資料如下:

現在需要計算誰和誰更相似,對兩部電影建立坐標系如下:
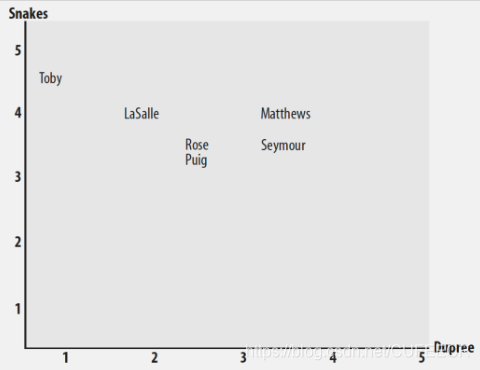
每個人的評分都以坐標的形式體現出來,可以通過兩者之間的距離計算出來,距離越近則相似度越高,最簡單的方式是通過勾股定理計算;
有多部電影則計算多維距離,
2.資料質量與形式
資料有一個很重要的特性是資料質量,
根據定義,資料質量是指在業務環境下,資料符合資料消費者的使用目的,能滿足業務場景具體需求的程度,
比如說,調查問卷因為設計不好而導致收集到的結果有失客觀性,這就是資料質量有問題,
衡量資料質量有一定的衡量指標:
- 重復
資料重復是否有意義, - 完整
資料探索時判斷資料是否完整, - 一致
資料之間是否一致,比如問卷資料前后部分是否符合, - 時效
資料一般在某個時間區間內有效,
資料還有一個特性是資料形式,主要包括:
- 結構資料
具有一定結構的資料,如MySQL資料庫中的資料,對資料型別有一定的限制, - 半結構資料
具有特定的格式,如之前的json資料就是半結構資料,一般來自網站, - 非結構資料
文本、圖片等檔案,沒有特定的結構,不能使用常規方法分析,
對于圖片檔案,圖都是有由像素組成的點陣,每一個像素點由RGB值確定,組成一個矩陣進行處理,
不同格式的資料也有不同的來源,
3.資料隱性
可以從資料中挖掘出資訊和價值,
再舉一個案例:
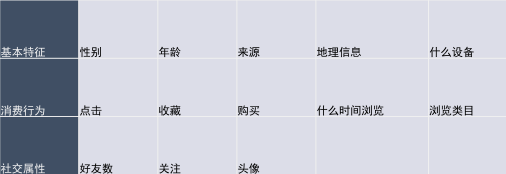
(4)對于電商行業,怎么分析客戶的男女比例:
假如有一個客戶叫孫悅,昵稱是小悅悅,最近老是頻繁登錄公司的APP,并且總是瀏覽美妝產品,而且最近三個月購買了大量女鞋和美妝,
那么孫悅是男還是女呢?
要判斷一個客戶是男性還是女性,可以從以下指標出發:
最簡單的方法:
男性概率=姓名倒數第一個字男性概率×權重1+姓名倒數第二個男性概率×權重2
女性=1–男性概率
這個模型只是依據姓名來判斷的,較為單一,
更進一步的分析:
在姓名判斷性別概率的基礎上,再依據消費行為(如購買剃須刀)的特征判斷性別概率,并確定權重計算加權概率,
這是一個分類問題,
進行資料分析的好處:
- 搞清事實
分析事情的好壞, - 接近真相
可以發現真相的可能情況, - 預測未知
比如預測消費曲線, - 幫助決策
如智能投顧,
三、資料分析型別、可視化與資料驅動開發團隊
1.不同型別的分析
不同型別分析的復雜度和價值如下:
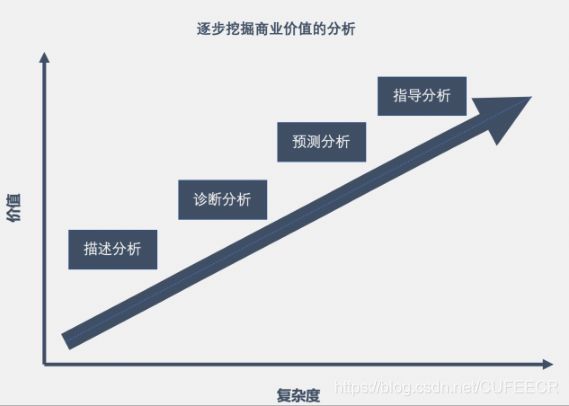
其中,描述性分析用于描述當前情況,比如分布、曲線等;
診斷分析主要分析問題原因,可能需要進行可視化;
預測分析主要預測未知,包括自動化推薦系統、銷量預測;
指導分析用于指導行動,
隨著難度的加大,所需要的資料也越來越多、工具越來越復雜,
常見的分析框架如下:
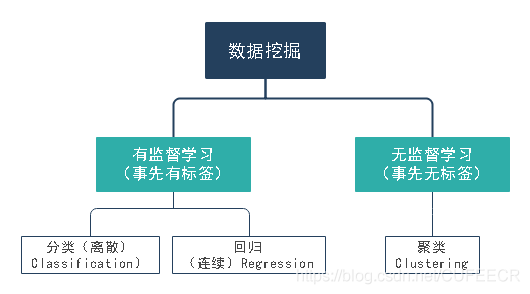
具體包括SVM、決策樹、邏輯回歸、神經網路、線性回歸、K-means、分層聚類等理論模型,
2.資料可視化
有了分析的結果,需要進行報告,其中可視化不可缺少,需要將結果呈現出來,
同時在資料探索時,資料可視化可以讓我們更加直觀地了解資料所呈現出的特點,
一個圖表示意如下:
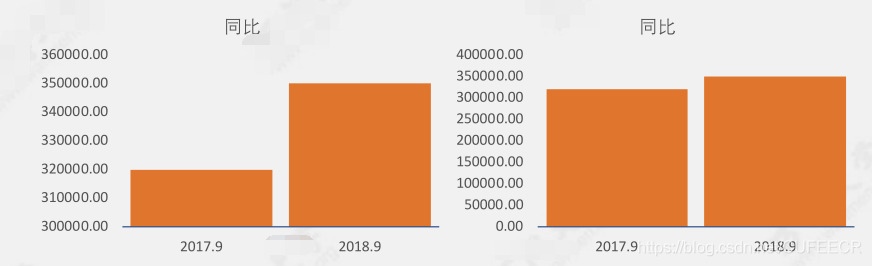
顯然,左右兩部分都是有問題的:
標題不規范;
刻度不一致,不協調;
坐標軸起點;
兩個表的差距感覺不同,但實際上差別是一樣的,
3.資料驅動開發團隊
一個典型的資料驅動開發團隊的成員如下:
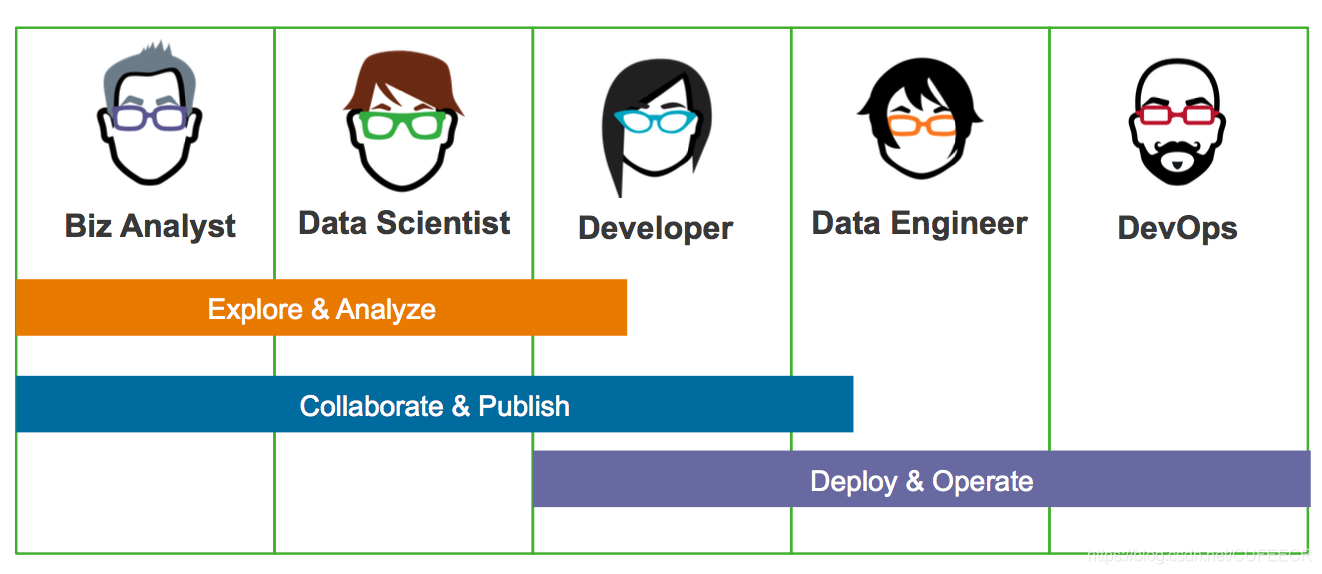
左側負責資料分析,右側負責專案開發,需要相互協調和配合,