摘要
提出SimCLR,用于視覺表征的對比學習,簡化了最近提出的對比自監督學習演算法,為了理解是什么使對比預測任務能夠學習有用的表示,系統研究了提出框架的主要組成部分,發現:
(1)資料增強的組成在定義有效的預測任務中起著關鍵的作用
(2)在表示和對比損失之間引入一個可學習的非線性變換,大大提高了已學習表示的質量
(3)與監督學習相比,對比學習受益于更大的批量規模和更多的訓練步驟
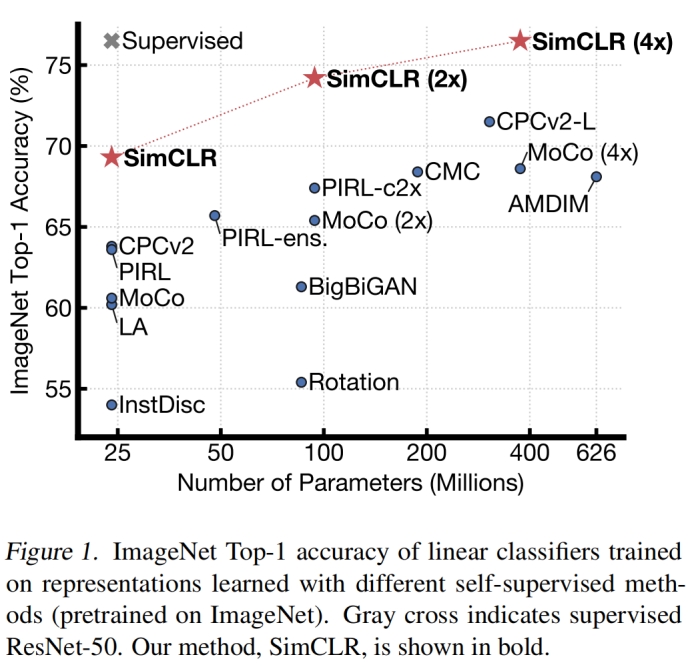
SimCLR學習的自監督表示訓練的線性分類器達到了76.5%的top-1精度,比之前的技術水平提高了7%,與監督ResNet-50的性能相匹配,
方法
- 對比學習框架
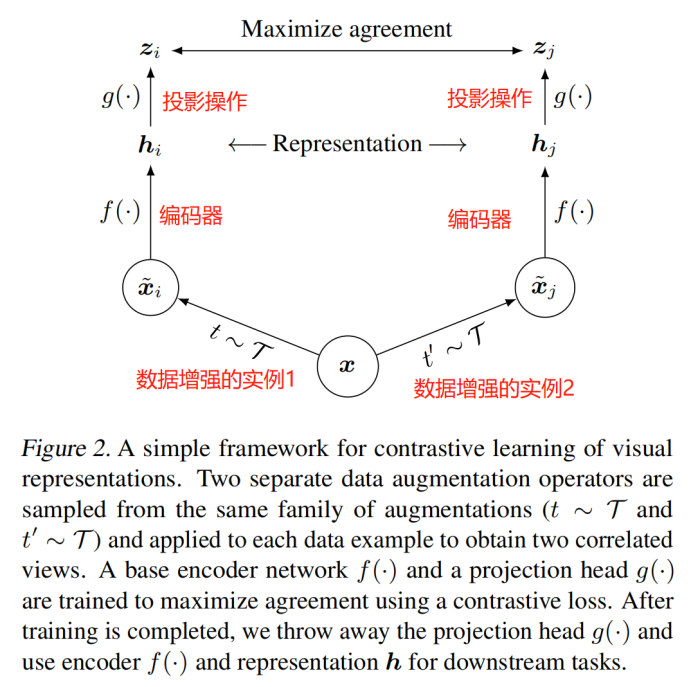
隨機采樣一個minibatch的資料(N個樣本),定義生成的增強樣本對的對比預測任務,得到2N個資料點,給定一個正例對,將其它2(N-1)個增強樣本當作負例,相似性度量采用余弦距離,則正例對(i,j)的損失函式為:
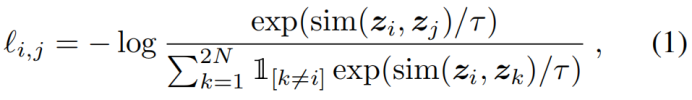
τ代表溫度引數,最后的損失是計算所有正例樣本對,包含(i,j)和(j,i),稱之為NT-Xent (the normalized temperature-scaled cross entropy loss)
提出的方法可總結為:

實驗
1. 投影頭實驗發現:
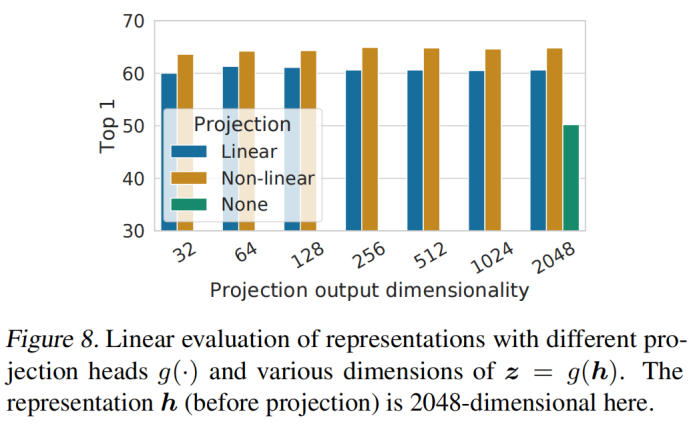
- 非線性投影比線性投影好(>3%),比不投影高很多(>10%)
- 隱藏層在投影頭前面比在層后面要好
2. NT-Xent損失與其它常用對比損失函式的比較(logistic loss、margin loss):

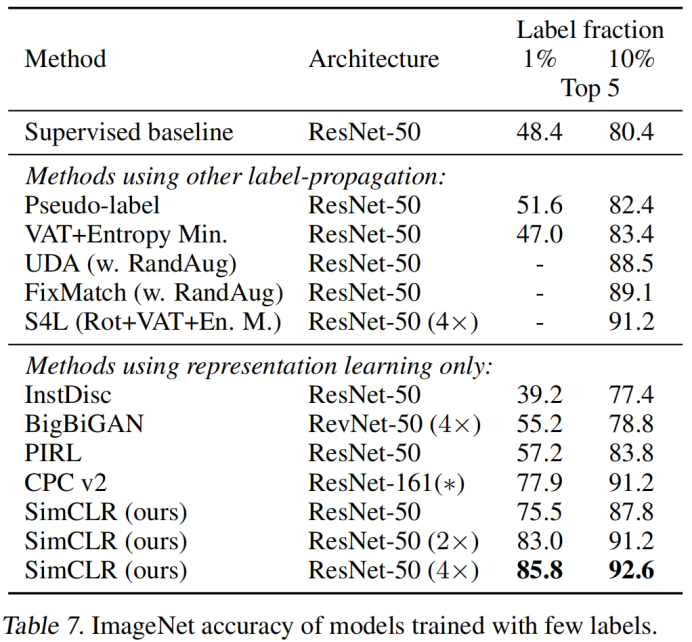
3. 采用不同標簽訓練時的指標對比:
公眾號

過去已逝,未來太遠,只爭今朝
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/550676.html
標籤:其他
上一篇:閱讀文獻《SCNet:Deep Learning-Based Downlink Channel Prediction for FDD Massive MIMO System》
下一篇:返回列表