說在前面的話:
一個月前,OpenAI向外界展示了GPT-4如何通過手繪草圖直接生成網站,令當時的觀眾瞠目結舌,
在GPT-4發布會之后,相信大家對ChatGPT的對話能力已有所了解,圈內的朋友們應該已經親身體驗過無論是文本生成、撰寫代碼,還是背景關系關聯對話能力,這些功能都一次又一次地震撼著我們,
還記得發布會上,GPT-4展示的多模態能力,輸入不僅僅局限于文字,還可以包括文本和影像,讓我大開眼界,
例如:畫個網站的草圖,GPT4 就可以立馬生成網站的 HTML 代碼,
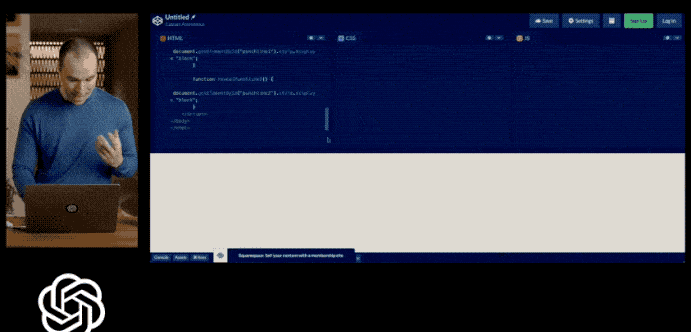
然而,時光荏苒!OpenAI至今尚未提供發布會上展示的多模態處理能力!
原本以為我們還需要再等上一段時間才能看到這一功能的更新,然而意想不到的是,我發現了這樣一個專案,
這個專案被稱為MiniGPT-4,由著名的阿卜杜拉國王科技大學的幾位博士研究生共同完成,
更為重要的是,該專案完全開源!效果如視頻中所展示的那樣:
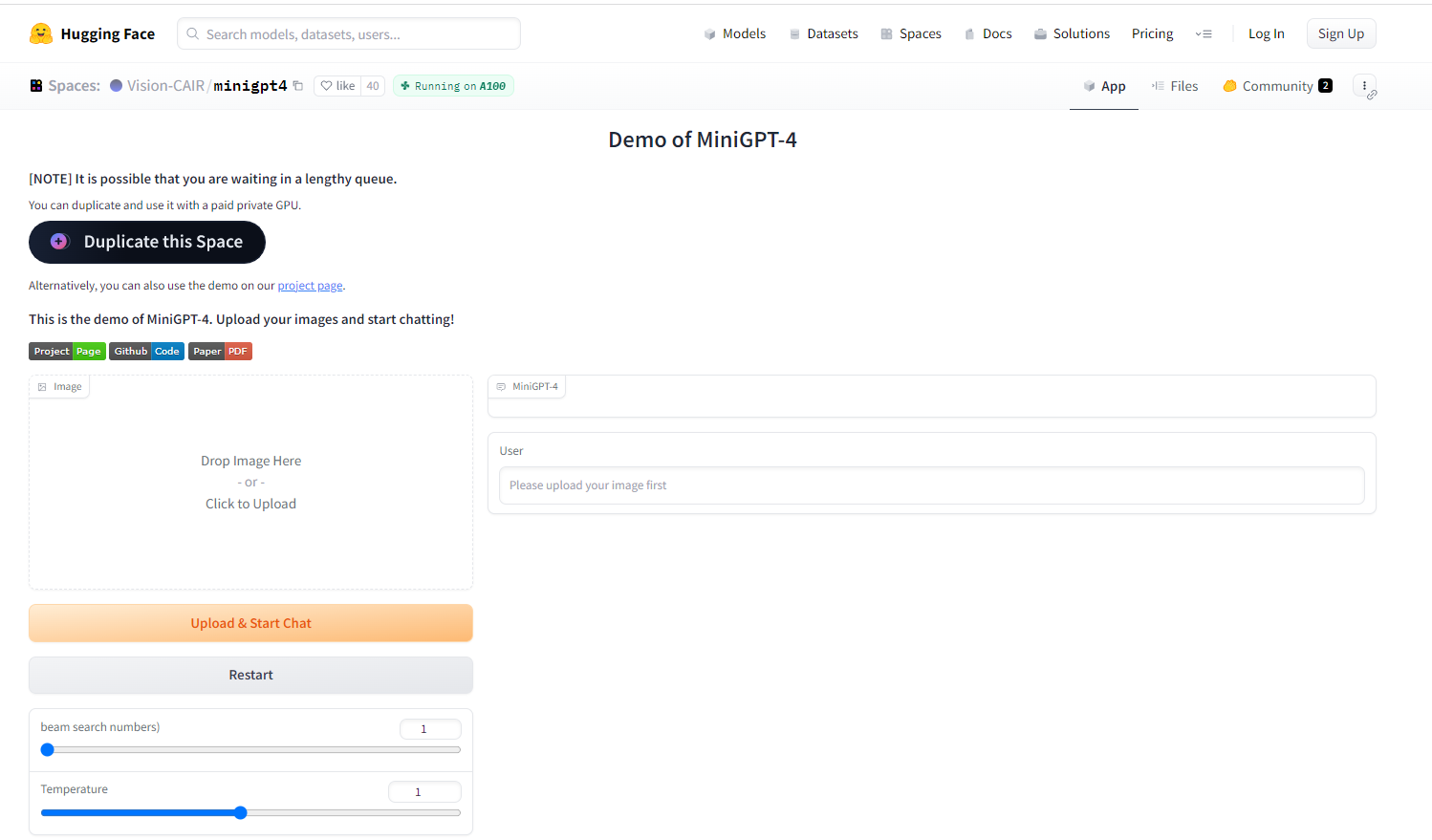
MiniGPT-4在線體驗DEMO
MiniGPT-4能夠支持文本和影像輸入,成功實作了多模態輸入功能,實在令人嘆為觀止!
GitHub專案地址:https://github.com/Vision-CAIR/MiniGPT-4
在線體驗鏈接:https://minigpt-4.github.io
另外作者還提供了網頁 Demo,可以直接體驗(這酸爽?):
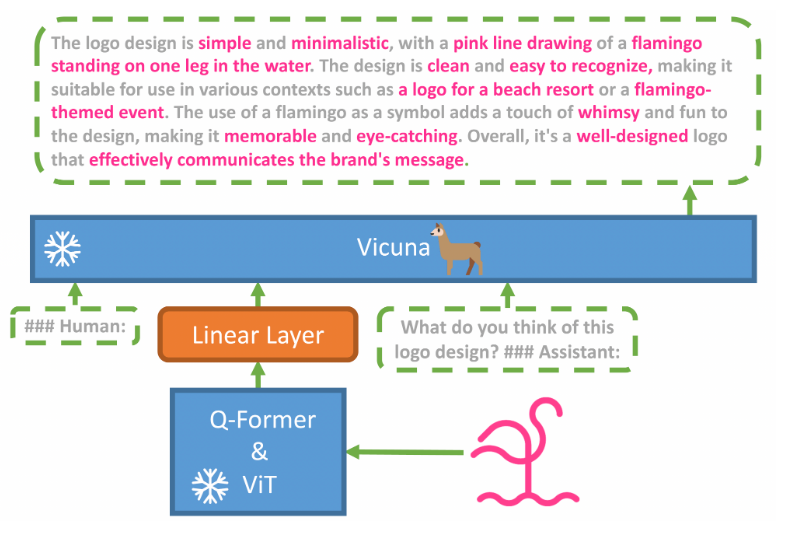
MiniGPT-4介紹
- MiniGPT-4利用一個投影層將BLIP-2的凍結視覺編碼器與凍結的LLM(Vicuna)對齊,
- 我們分兩個階段訓練MiniGPT-4,第一個傳統預訓練階段使用大約500萬個影像-文本對,在4個A100顯卡上訓練10小時,在第一階段之后,Vicuna能夠理解影像,但是,Vicuna的生成能力受到嚴重影響,
- 為解決這個問題并提高可用性,我們提出了一種新穎的方法,通過模型本身和ChatGPT共同創建高質量的影像-文本對,基于此,我們創建了一個小型(總共3500對)但高質量的資料集,
- 第二個微調階段在該資料集的會話模板上進行訓練,以顯著提高其生成可靠性和整體可用性,令我們驚訝的是,這個階段在計算上非常高效,僅使用單個A100花費約7分鐘,
- MiniGPT-4展現出許多類似于GPT-4演示的視覺-語言能力,
官方案例演示:
接下來,我將為大家展示幾個示例,

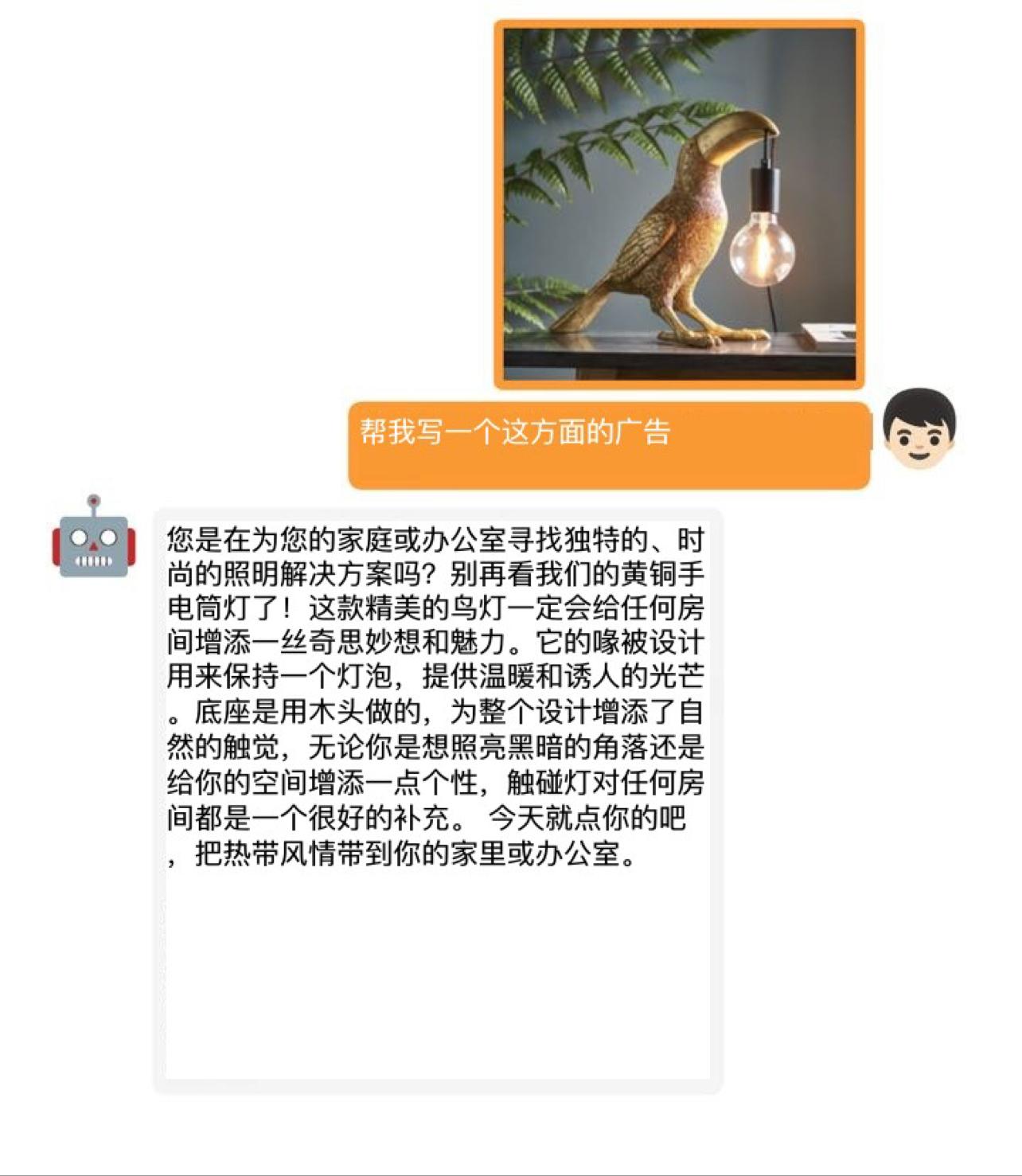
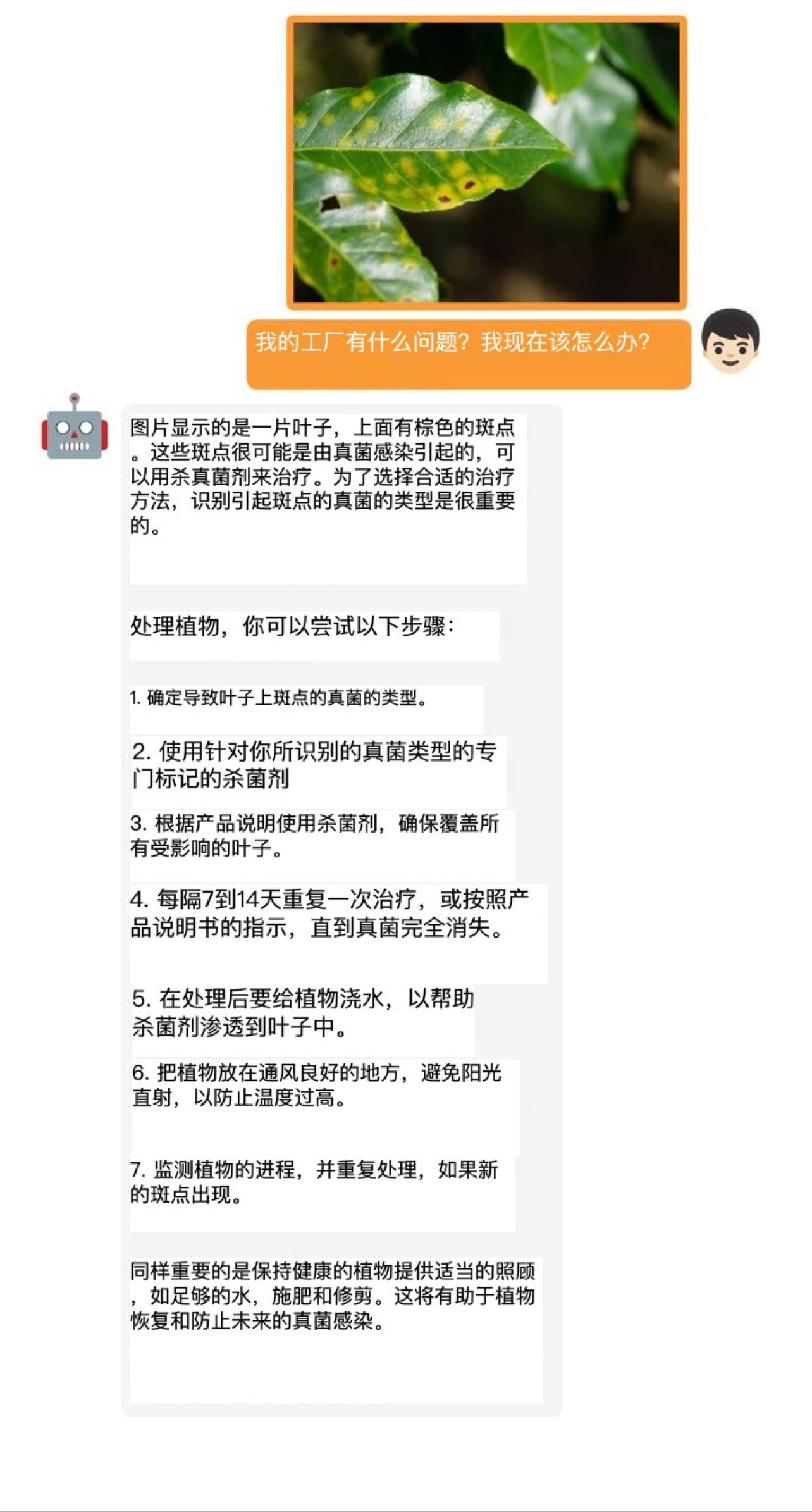
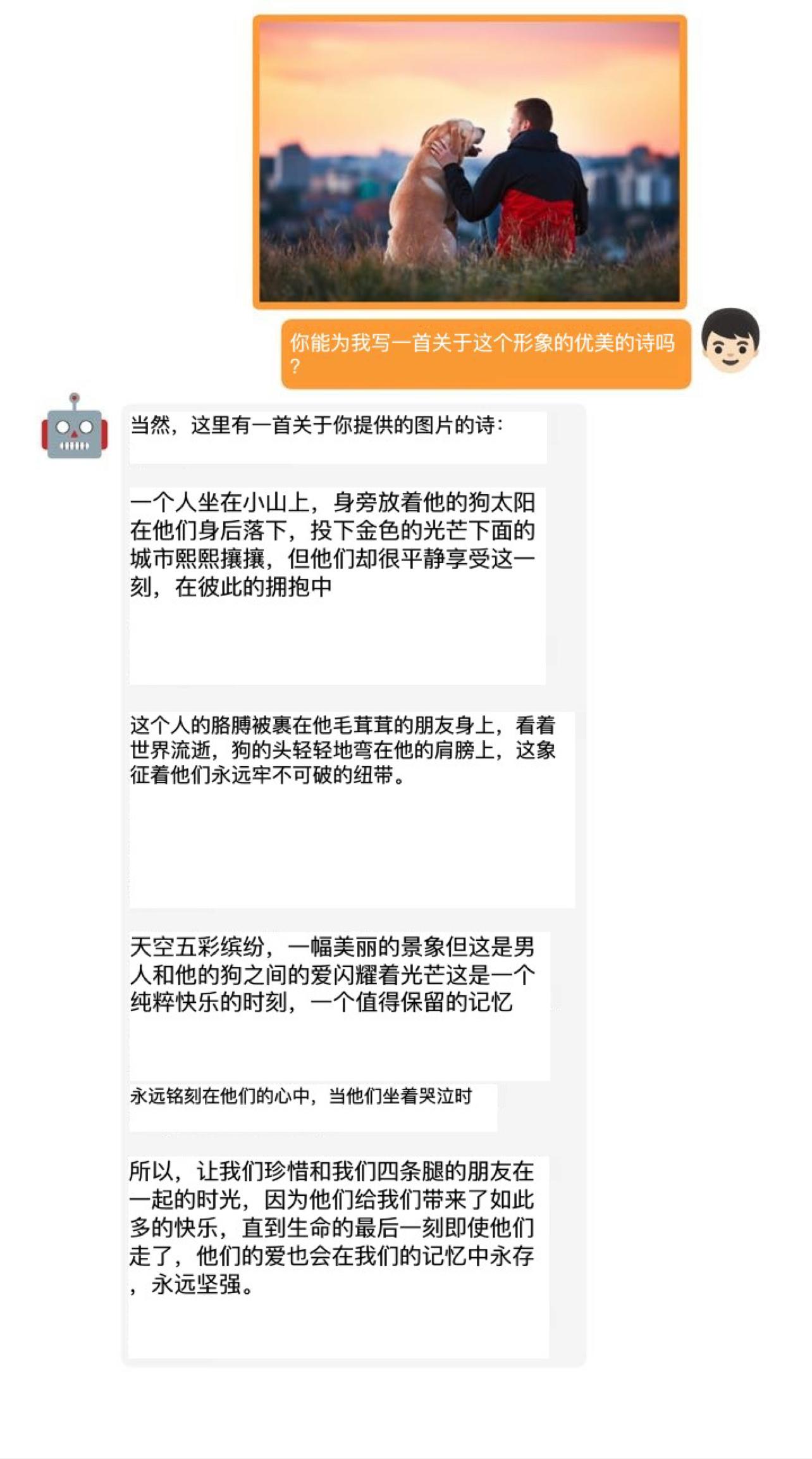
實驗結果表明,GPT-4的這些先進能力理論上可以歸因于它采用了更加先進的大型語言模型,
這意味著,未來在影像、聲音、視頻等領域,基于這些大型語言模型所開發的應用,在實際效果上都將表現不俗,
這個專案驗證了大型語言模型在影像領域的可行性,接下來,預計會有更多開發者加入,將GPT-4的能力擴展至音頻、視頻等領域,從而讓我們得以欣賞到更多有趣且令人驚艷的AI應用,
近日,我深入研究了許多關于ChatGPT注冊和變現的實用干活資訊, 為了方便我自己以后的學習和閱讀,我整理了一些ChatGPT的操作技巧和實用工具:https://y3if3fk7ce.feishu.cn/docx/QBqwdyde7omVf4x69paconlgnAc
有興趣的朋友們可以借此學習,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/550791.html
標籤:其他
上一篇:AIGC的阿克琉斯之踵
下一篇:返回列表