作者:京東零售 李文濤
一、簡介
1.1 Background
字串匹配在文本處理的廣泛領域中是一個非常重要的主題,字串匹配包括在文本中找到一個,或者更一般地說,所有字串(通常來講稱其為模式)的出現,該模式表示為p=p[0..m-1];它的長度等于m,文本表示為t=t[0..n-1],它的長度等于n,兩個字串都建立在一個有限的字符集上,
一個比較常見的字串匹配方法作業原理如下,在一個大小通常等于m的視窗幫助下掃描文本,首先將視窗和文本的左端對齊,然后將視窗的字符與文本中的字符進行比較,這一特定的作業被稱為嘗試,在完全匹配或不匹配之后,將視窗移到右側,繼續重復同樣的程序,直到視窗的右端超過文本的右端,一般稱為滑動視窗機制,
1.2 Brute force
BF演算法檢查文本中0到n-m之間的所有位置,是否有模式從那里開始出現,然后,在每次嘗試之后,它將模式串向右移動一個位置,
BF演算法不需要預處理階段,除了模式和文本之外,還需要一個恒定的額外空間,在搜索階段,文本字符比較可以以任何順序進行,該搜索階段的時間復雜度為O(mn),
public static int strMatch(String s, String p){
int i = 0, j = 0;
while(i < s.length() && j < p.length()){
if(s.charAt(i) == p.charAt(j)){
i++;
j++;
}else{
i = i - j + 1;
j = 0;
}
if (j == p.length()){
return i - j;
}
}
return -1;
}
二、KMP
先回顧下brute force中匹配的情況,我們在文本串BBC#ABCDAB$ABCDABCDABDE中查找模式串ABCDABD,文本串中第1個字符“B”與模式串中第1個字符“A”不匹配,所以我們將模式傳后移一位,
文本串中的第2個字符“B”和模式串中的第一個字符“A”不匹配,繼續后移,
基于這種方式不斷比較并且移動,我們發現文本串中的第5個字符“A”和模式串中的第1個字符“A”是匹配的,那么繼續比較文本串和模式串的下一個字符,
不斷比較之后我們發現,文本串中的字符“$”和模式串中的最后一個字符“D”不匹配,
根據BF演算法,我們應該繼續將模式串向后移動一位,然后從頭開始重新比較,
那我們不妨觀察下,上次匹配失敗的情況,當文本串中“$”與模式串中“D”不匹配時,我們其實已經完成了6次匹配,也就是說我們在文本串和模式串中已經找到了"ABCDAB",同時我們可以發現模式串中前綴“AB”是可以和文本串中已匹配成功部分的后綴“AB”相匹配,我們利用這個資訊,可以把模式串右移多位,而不僅僅是1位來去繼續匹配(換句話說,我們不需要回退文本串的搜索位置),這加快了搜索速率,
同樣的,當搜索到下面情況時,文本串中的字符“C”和模式串中的字符“D”不匹配,利用已知的資訊,我們右移模式串,不回退搜索位置,繼續去查找匹配,
最終,查找成功,
簡單來說,文本串和模式串匹配失敗時,kmp演算法并沒有像bf演算法描述中一樣,將模式串右移1位,從頭重新進行搜索,而是利用已匹配資訊,不回退文本串的搜索位置,繼續將模式串向后移動,減少比較次數,提高了效率,那么當匹配失敗時,模式串究竟要向后移動多少位呢?
2.1 前綴函式
前綴是指從串首開始到某個位置結束的一個特殊子串,字串S以i結尾的前綴表示為Prefix(S,i),也就是Prefix(S,i)=S[0..i],
真前綴指除了S本身的S的前綴,
后綴是指從某個位置開始到整個串末尾結束的一個特殊子串,字串S的從i開頭的后綴表示為Suffix(S,i),也就是Suffix(S,i)=S[i..|S|-1],
真后綴指除了S本身的S的后綴,
回到上文kmp演算法匹配流程中,當文本串和模式串匹配失敗時,我們右移模式串的位數是多少呢?或者說,當文本串中字符與模式串中字符匹配失敗時,應該重新跟模式串中哪個字符再進行匹配呢?
上面的例子文本串中$與模式串中D匹配失敗,而由于已經匹配成功了“ABCDAB”這6個字符,我們發現可以將模式串右移4位再進行比較,或者說此時,當匹配至模式串第7個字符失敗后,可以重新和模式串的第3個字符,也就是“C”進行比較,這是由于文本串中的“AB”恰好和模式串中的前綴“AB”相匹配,而且我們發現匹配失敗前文本串中的“AB”和已匹配的模式串中的后綴“AB”也是相匹配的,所以實際上我們根據模式串自身的特點,就能知道匹配失敗時如何去匹配新的位置,
我們定義陣列prefix,其中prefix[i]表示以S.charAt(i)為結尾的即S[0..i]中最長的相同真前后綴的長度,以字串“aabaaab”為例:
i=0時,子串“a”無真前后綴,prefix[0]=0
i=1時,子串“aa”,其中[a]a和a[a]最長的相同真前后綴為a,prefix[1]=1
i=2時,子串“aab”無相同的真前后綴,prefix[2]=0
i=3時,子串“aaba”,其中[a]aba aab[a]最長的相同真前后綴為a,prefix[3]=1
i=4時,子串“aabaa”,其中 [aa]baa aab[aa] 最長的相同真前后綴為aa,prefix[4]=2
i=5時,子串“aabaaa”,其中[aa]baaa aaba[aa] 最長的相同真前后綴為aa,prefix[5]=2
i=6時,子串“aabaaab”,其中[aab]aaab aaba[aab]最長的相同真前后綴為aab,prefix[6]=3
上文匹配的prefix陣列如下:
如何求解prefix呢,很容易想到一種方法是,我們使用兩個for回圈來遍歷給定字串的前綴中的真前綴和真后綴,內部去比較真前綴和真后綴是否相同,即便我們從最長的真前后綴來嘗試匹配,這個方法的時間復雜度還是很高,
public static int[] getPrefix(String str){
int[] res = new int[str.length()];
for(int i = 1; i < res.length; ++i){
for(int j = i; j > 0; --j){
if (str.substring(0, j).equals(str.substring(i-j+1,i+1))){
res[i] = j;
break;
}
}
}
return res;
}
2.2 第一個優化
我們觀察下由s[i]至s[i+1]求解最長的真前后綴匹配情況變化,
// compute "ABCDA" -> compute "ABCDAB"
// A A <-"ABCDA"時最長前綴、后綴匹配
// AB DA
// ABC CDA
// ABCD BCDA
// ->
// A B
// AB AB <-"ABCDAB"時最長前綴、后綴匹配
// ABC DAB
// ABCD CDAB
// ABCDA BCDAB
// compute "ABCDA" -> compute "ABCDAP"
// A A <-"ABCDA"時最長前綴、后綴匹配
// AB DA
// ABC CDA
// ABCD BCDA
// ->
// A P
// AB AP
// ABC DAP
// ABCD CDAP
// ABCDA BCDAP
// 無匹配
// A->AB
// 也就是說最好的情況下,以s[i]為結尾的最長的相同的真前后綴長度,一定是以s[i-1]為結尾的最大的相同的真前后綴相同的長度+1
根據上面的描述,在嘗試匹配真前后綴的時候,我們可以減少回圈次數,
public static int[] getPrefix1(String str){
int[] prefix = new int[str.length()];
prefix[0] = 0;
for (int i = 1; i < str.length(); ++i){
for(int j = prefix[i-1] + 1; j > 0; --j){
if (str.substring(0, j).equals(str.substring(i-j+1, i+1))){
prefix[i] = j;
break;
}
}
}
return prefix;
}
考慮一種情況,計算字串“baabaab”的prefix的時候,在計算i=5的時候,我們已經完成了“baa”的比較,當計算i=6的時候,我們比較前綴“baab”和后綴“baab”,但是在上一次比較,我們知道前綴“baa”和后綴“baa”已經匹配了,
為了減少這種重復的匹配,我們考慮一下利用雙指標來不斷的去比較所指的兩個字符
// if(s.charAt(i) == s.charAt(j))
// prefix[i] = prefix[j-1] + 1;
// or
// prefix[i] = j + 1;
// }
具體實作如下:
public static int[] getPrefix2(String str){
int[] prefix = new int[str.length()];
int j = 0;
int i = 1;
while(i < str.length()){
if (str.charAt(j) == str.charAt(i)){
j++;
prefix[i] = j;
i++;
}else{
// 匹配失敗時,
while(j > 0 && !str.substring(0, j).equals(str.substring(i-j+1, i+1))){
j--;
}
prefix[i] = j;
i++;
}
}
return prefix;
}
2.3 第二個優化
上面的優化是針對匹配成功時候的情況,那么匹配失敗時,難道真的需要重新去列舉其他的真前后綴,來去不斷的嘗試匹配嗎?我們觀察下,匹配失敗時,能否利用前面已經計算完的結果呢?
當s[j]!=s[i]的時候,我們是知道s[0..j-1]和s[i-j..i-1]是相同的,到這里再回想一下prefix陣列的定義,prefix[j-1]表示的是以s.charAt(j-1)字符為結尾的即s[0..j-1]中最長的相同真前后綴的長度,如果prefix[j-1]=x(x!=0),我們很容易得到s[0..x-1]和s[j-x..j-1]是相同的,
再將s[i-j..i-1]展開來看一下,因為我們知道s[0..j-1]和s[i-j..i-1]是相同的,所以s[i-j..i-1]也同樣存在相同的真前后綴,即真前綴s[i-j-x..i-j]以及真后綴s[i-x..i-1],而且由于s[0..x-1]和s[j-x..j-1]是相同的,s[j-x..j-1]和s[i-x..i-1]是相同的(整體相同,對應的部分也是相同的),可以容易得到s[0..x-1]和s[i-x..i-1]是相同的,
再回到原始的字串上來觀察,s[0..x-1]正是字串s的真前綴,而s[i-x..i-1]是以i-1為結尾的真后綴,由于這兩部分相同,我們更新j=x=prefix[j-1],準確找到已經匹配的部分,繼續完成后續的匹配即可,
代碼實作如下:
public static int[] getPrefix4(String str){
int[] prefix = new int[str.length()];
int j = 0;
int i = 1;
while(i < str.length()){
if (str.charAt(j) == str.charAt(i)){
// 更新j,同時j++也正是已匹配的最大長度
j++;
prefix[i] = j;
i++;
}else if(j == 0){
// 當str.charAt(j) != str.charAt(i) && j == 0時,后移i即可
i++;
}else{
// 找到已匹配的部分,繼續匹配即可
j = prefix[j-1];
}
}
return prefix;
}
2.4 求解next
很多kmp演算法的講解都提到了next陣列,那么實際上next陣列求解和上面的prefix求解本質是一樣的,next[i]實際上就是以i-1為結尾的最長的相同真前后綴的長度,
定義next[j]為當s[i] != p[j]時,需要跳轉匹配的模式串的索引,特別的當next[0] = -1
public static int[] getNext(String str){
int[] next = new int[str.length()+1];
int i = 1;
int j = 0;
// next[0] = -1 指代匹配失敗,更新文本串索引+1
next[0] = -1;
while(i < str.length()){
if (j == -1 || str.charAt(i) == str.charAt(j)){
i++;
j++;
next[i] = j;
}else{
j = next[j];
}
}
return next;
}
2.5 完整代碼
public static int search(String s, String p){
int[] next = getNext(p);
int i = 0, j = 0;
while(i < s.length() && j < p.length()){
if (j == -1 || s.charAt(i) == p.charAt(j)){
i++;
j++;
}else{
j = next[j];
}
if (j == p.length()){
return i - j;
}
}
return -1;
}
2.6 優化next
以上面的next陣列為例,當i=5,匹配失敗時,應該跳轉i=1進行比較,但是我們知道s[5]=s[1]="B",這樣匹配下去也是必定會失敗的,基于這一點,還可以簡單優化下next陣列的求解程序,
public static int[] getNext1(String str){
int[] next = new int[str.length()+1];
int i = 1;
int j = 0;
next[0] = -1;
while(i < str.length()){
if (j == -1 || str.charAt(i) == str.charAt(j)){
i++;
j++;
if (i < str.length() && str.charAt(i) != str.charAt(j)){
next[i] = j;
}else{
// 如果相同,根據next[j]跳轉即可
next[i] = next[j];
}
}else{
j = next[j];
}
}
return next;
}
三、其他演算法
這一部分,介紹幾種其他字串搜索的演算法
3.1 BM
1977 年,德克薩斯大學的 Robert S.Boyer 教授和 J StrotherMoore 教授發明了一種新的字串匹配演算法:Boyer-Moore演算法,簡稱BM 演算法,BM演算法的基本思想是通過后綴匹配獲得比前綴匹配更多的資訊來實作更快的字符跳轉,
通常我們都是從左至右去匹配文本串和模式串的,下面我們從右至左嘗試匹配并觀察下,文本串中的字符“S”,在模式串中未出現,那么我們是不是可以跳過多余的匹配,不用去考慮模式串從文本串中第1個、第2個、第m個字符進行匹配了,可以直接將模式串向后滑動m個字符進行匹配,
繼續觀察下面匹配失敗的情況,我們可以發現,模式串后三個字符“E”、“L”、“P”一定無法和文本串中的字符“M”進行匹配,換句話說,直到移動到模式串中最右邊的“M”(如果存在的話)之前,都是無法匹配成功的,基于這個觀察,我們可以直接向后移動模式串,使最右邊出現的“M”和文本串中的“M”對齊,再去繼續匹配,
總結:1.當出現失配字符時(文本串的字符),如果模式串不存在該字符,則將模式串右移至失配字符的右邊,
2.如果模式串中存在該字符,將模式串中該字符在最右邊的位置,和文本串的失配字符對齊,
我們再觀察下面的情況,我們發現文本串中字符“A”和模式串中的字符“B”匹配失敗,此時已匹配的后綴“AB”我們可以在模式串中找到同樣的子串“AB”,我們完全可以向后移動模式串,將兩個串中的“AB”來對齊,再繼續匹配,
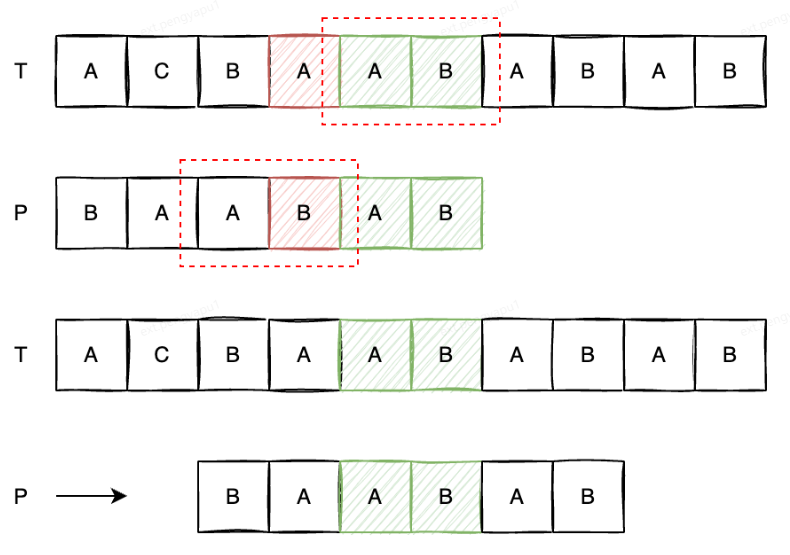
再觀察下面這種情況,已經匹配的后綴“CBAB”我們無法在模式串中找到同樣的部分,難道就沒有辦法加快匹配了嗎?我們以匹配的字串“CBAB”中的幾個真后綴“BAB”、“AB”、“B”,其中“AB”作為前綴出現在了模式串中,那我們可以后移模式串,將文本串中的后綴“AB”和模式串中的前綴“AB”對齊,從而繼續進行匹配,
為什么已匹配的字符的真后綴必須要和模式串中的前綴匹配才可以移動呢?我們可以看下面這個例子,已匹配的“CBAB”中的真后綴“AB”,在模式串中是存在的(非前綴),那我們向后移動模式串把這兩部分對齊繼續匹配如何呢?這樣做看似合理,但實際上卻是一個無效的匹配位置,很明顯,因為文本串中“AB”前的字符和模式串中“AB”前的字符一定是不匹配的,否則我們是可以找到一個比“AB”更長的匹配,且這個匹配的一定是模式串中的前綴,這就符合我們上面說的情況了,所以當沒有能夠匹配上合理后綴這種情況出現時,正確的移動是將模式串向后移動m位,
總結:1.當模式串中有子串和已匹配后綴完全相同,則將最靠右的那個子串移動到后綴的位置繼續進行匹配,
2.如果不存在和已匹配后綴完全匹配的子串,則在已匹配后綴中找到最長的真后綴,且是模式串的前綴(t[m-s…m]=P[0…s])
3.如果完全不存在和好后綴匹配的子串,則右移整個模式串,
BM演算法在實際匹配時,考慮上面兩種策略,當匹配失敗發生時,會選擇能夠移動的最大的距離,來去移動模式串,從而加速匹配,實際情況,失配字符移動策略已經能很好的加速匹配程序,因為模式串本身字符數量是要少于文本串的,Quick Search algorithm(Sunday)正是利用這一策略的演算法(有些許不同),或者說是一種簡化版的BM演算法,
3.2 Sunday
Sunday 演算法是 Daniel M.Sunday 于 1990 年提出的字串模式匹配,其效率在匹配隨機的字串時比其他匹配演算法還要更快,Sunday 演算法的實作可比 KMP,BM 的實作容易的多,
Sunday演算法思想跟BM演算法很相似,在匹配失敗時關注的是文本串中參加匹配的最末位字符的下一位字符,如果該字符沒有在模式串中出現則直接跳過,即移動步長= 模式串長度+1;否則,同BM演算法一樣其移動步長=模式串中最右端的該字符到末尾的距離+1,
文本串T中字符“c”和模式串中的字符“d”不匹配,我們觀察文本串參與匹配的末位的下一個字符“e”,可以知道“e”沒有出現在模式串中,于是移動模式串長度+1,
繼續匹配,我們發現文本串T中字符“a”和模式串中的字符“d”不匹配,我們觀察文本串參與匹配的末位的下一個字符“a”,可以知道“a”出現在模式串中(最右的位置),于是移動模式串該字符到末尾的距離+1,
3.3 Rabin-Karp
Rabin-Karp 演算法,由 Richard M. Karp 和 Michael O. Rabin 在 1987 年發表,它也是用來解決多模式串匹配問題的,該演算法實作方式與上述的字符匹配不同,首先是計算兩個字串的哈希值,然后通過比較這兩個哈希值的大小來判斷是否出現匹配,
為了幫助更好的解決字串匹配問題,哈希函式應該具有以下屬性:
1.高效的、可計算的
2.更好的識別字串
3.在計算hash(y[j+1 ..j+m])應該可以容易的從hash(y[j..j+m-1])和y[j+m]中得到結果,即hash(y[j+1 ..j+m])=rehash(y[j],y[j+m],hash(y[j..j+m-1])
我們定義hash函式如下:
hash(w[0 ..m-1])=(w[0]*2m-1+w[1]*2m-2+···+w[m-1]*2^0) mod q
由于計算的hash值可能會很大,所以需要取模操作,q最好選取一個比較大的數,且是一個質數,w[i]表示y[i]對應的ASCII碼,
hash(w[1..m])=rehash(w[0],w[m],hash(w[0..m-1]))
rehash(a,b,h)= ((h-a*2^m-1)*2+b) mod q
匹配程序中,不斷滑動視窗來計算文本串的hash值和模式串的是否相同,當出現相同時,還需要再檢查一遍字串是否真正相同,因為會出現哈希碰撞的情況,
3.4 Shift-and/or
Shift-and演算法的總體思路是把模式串預處理成一種特殊編碼形式,然后根據這種編碼形式去逐位匹配文本串,
首先對模式串進行預處理,利用二進制數位進行編碼,如果模式串為“abac”,a出現在第0位和第2位,那么則可以保存a的資訊為5(二進制為0101),同樣的,我們把模式串出現的所有字符均用這種方式編碼,并保存起來,
對于每一位文本串字符,我們定義一個對應的狀態碼數字P,當P[i]=1時,則表示以這一位文本串為末尾時,能和模式串的第0位到第i位的字符能完全匹配,我們看一下具體的匹配程序,
文本串“aeabcaabace”和模式串“abac”,初始化P=0,遍歷文本串中的每一個字符,同時根據存盤的字符編碼資訊,來更新匹配結果,也就是狀態碼P,
在第一次計算完成后,狀態碼P=0001,根據我們上面的定義,P[0]=1即表示以這一位文本串為末尾,模式串中的第0位到第0位的字符是匹配的,
進行完一次匹配后,P左移一位,將第0位置1,同時和對應字符的編碼進行&操作(即嘗試匹配該字符),更新狀態碼P,
可以看到當狀態碼P=0101時,P[2]=1表示當前字符匹配了模式串p[0..2]=“aba”,P[0]=1表示當前字符匹配了模式串p[0..0]=“a”,也就是說,狀態碼P是能夠存盤多種部分匹配的結果,
繼續匹配
當P=1000時,也就是說P[3]=1即匹配模式串p[0...3]=“abac”,正好找到了一個對應的匹配,而我們也可以根據此條件來判斷是否已經找到了匹配,
Shift-and使用的二進制資訊來編碼模式串,使用位運算&來達到并行匹配字串,利用狀態碼P來保存當前位的匹配結果,可以觀察出演算法的時間復雜度很低,如果模式串的長度不超過機器字長,其效率是非常高的,
Shift-or在這里就不多做介紹了,其原理和Shift-and類似,只不過Shift-or使用0來標識存在,同時使用|來代替&進行狀態碼的計算,
相關參考:
1.http://igm.univ-mlv.fr/~lecroq/string/node8.html#SECTION0080
2.http://igm.univ-mlv.fr/~lecroq/string/node14.html#SECTION00140
3.https://shanire.gitee.io/oiwiki/string/kmp/#knuth-morris-pratt
4.https://shanire.gitee.io/oiwiki/string/bm/
5.http://igm.univ-mlv.fr/~lecroq/string/node6.html#SECTION0060
6.https://baike.baidu.com/item/sunday 演算法/1816405
7.http://igm.univ-mlv.fr/~lecroq/string/node5.html#SECTION0050
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/551194.html
標籤:其他
下一篇:返回列表