一分鐘精華速覽
在典型的分布式系統中,用戶的一個請求到達組合的前端服務后,前端服務會分發請求到內部的各個服務,每次呼叫都涉及跨系統的一次請求和一次回應,在有大規模、高并發請求量的系統中,如何標識這些請求及存盤這些呼叫資訊,并形成呼叫鏈?如果系統的某兩個服務間出了問題,又如何為業務方提供可視化的展現形式以快速排障?
本文總結了微盟支持千億級規模的呼叫鏈實踐,詳解平臺的建設目標、設計思路和落地效果,

作者介紹

微盟APM團隊負責人——向明亨
TakinTalks穩定性社區專家團成員,2017年加入微盟,目前負責公司APM體系建設,包含APM體系從規范到實施,推動APM體系在公司的落地,主導了微盟APM平臺、監控告警平臺等平臺的建設,
溫馨提醒:本文約5000字,預計花費10分鐘閱讀,
后臺回復 “交流” 進入讀者交流群;回復“0411”獲取課件資料;
背景
作為SaaS領域唯二在港交所上市的企業之一,微盟累計服務了300萬+入駐商家,并基于騰訊社交網路為眾多商家提供SaaS和營銷服務,微盟業務的復雜性,體現在其技術團隊不僅需要滿足內部能力建設需求,也需兼顧營銷云上大量外部租戶的使用需求,
在流量生態方面,微盟集團SaaS產品拓展了多個流量平臺,如QQ小程式、QQ瀏覽器、抖音小店等,隨著業務端的渠道復雜化和流量的日益增長,業務方的觀測和排障需求也產生了變化,
一、微盟為什么自主設計呼叫鏈體系?
1.1 多集群排障,依賴呼叫鏈工具
在單應用場景下,大家通常通過監控或者日志來排障,但在集群狀態下它就會出現問題,比如一個下單流程,同時涉及了 A/B/C/D/E 服務,此時需先確定故障出現在哪個應用,而依賴傳統的日志或者監控,無法做到快速定位故障,
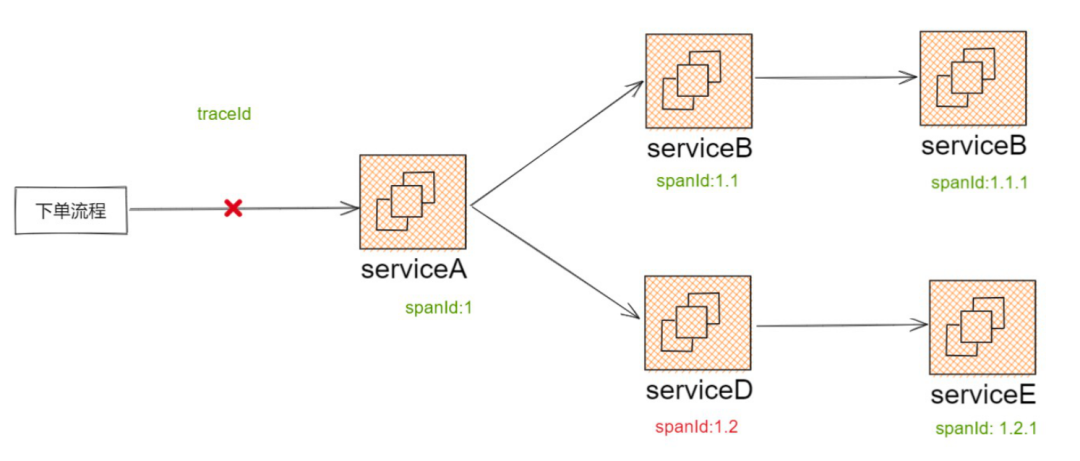
利用呼叫鏈工具,則可以串起請求的全程序,在鏈路中能直觀看到是哪個服務出現了問題,幫助快速定位故障,它是多集群狀態下排障的最佳解決方案,
1.2 鏈路開源組件多,但無法滿足需求
1.2.1 開源呼叫鏈工具
業界常用的鏈路開源工具有Skywalking 、ZipKin、 Jaeger 等等,我們根據微盟需求做了以下比對和分析,
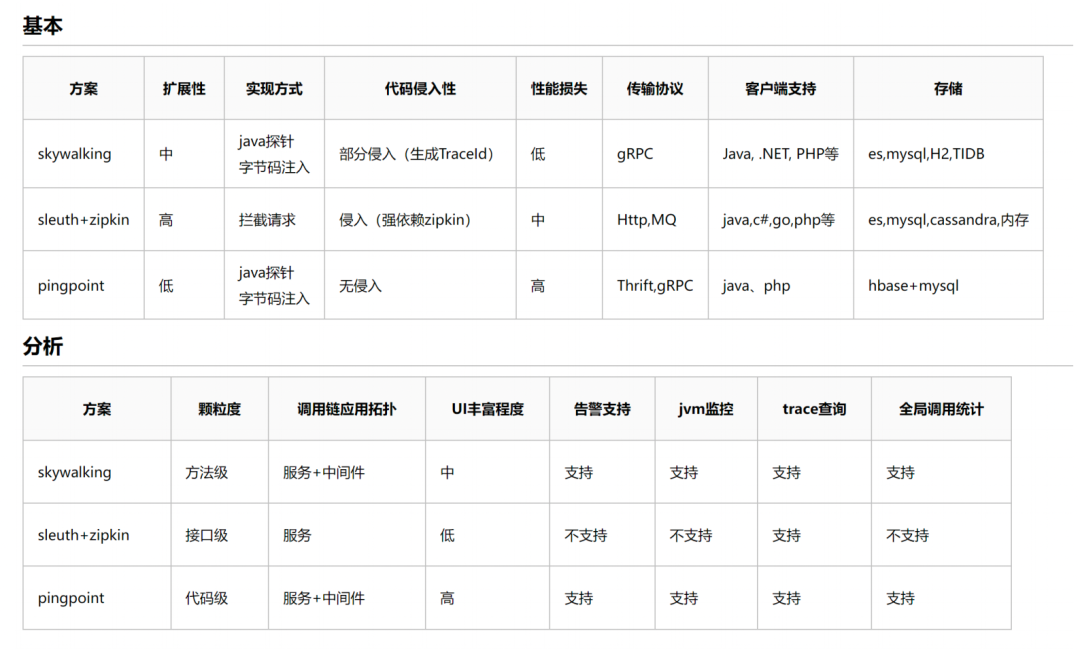
1.2.2 為何不選用開源鏈路系統
市面上有如此多開源工具,微盟為何還要做自己的呼叫鏈體系?
從整體設計要求考慮——
主Java:微盟大部分應用都是Java;
多語言:除Java外,還有Go、Node.js、Python等語言;
海量資料:要求監控資料盡可能多,因此資料規模較大;
業務復雜:既有 SaaS 也有PaaS,業務背景相對比較復雜,

從技術選型角度分析——
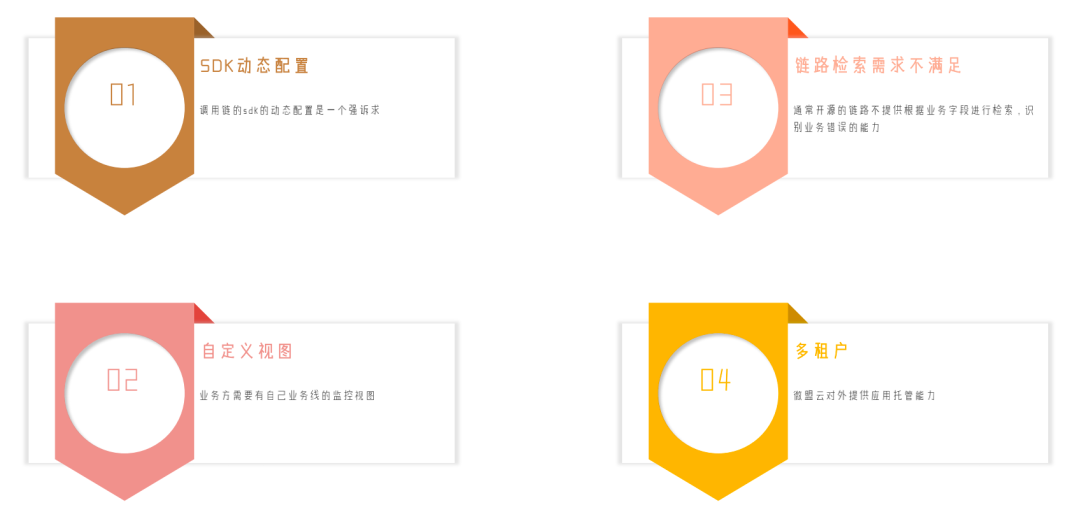
SDK動態配置:呼叫鏈的SDK動態配置是一個強訴求,而開源的呼叫鏈工具不支持自定義配置,比如,需要設定攔截哪些組件、哪些組件不收集呼叫鏈等,開源工具無法實作;
自定義視圖:業務方需要有自己業務線的監控視圖,微盟業務線眾多,業務方會有基于團隊和業務線的監控訴求,而開源工具無法滿足該類訴求;
鏈路檢索需求不滿足:通常開源的鏈路不提供根據業務欄位進行檢索,識別業務錯誤的能力,需要在不侵入業務方業務流程的前提下,滿足業務方的更高階要求;
多租戶:微盟云對外提供應用托管能力,除滿足對內需求外,也對在微盟云平臺部署應用的租戶提供呼叫鏈服務,
二、微盟呼叫鏈體系做了哪些設計?
2.1 新呼叫鏈架構設計
我將從三個部分來講述新的呼叫鏈設計——資料收集、資料傳輸協議、資料應用,
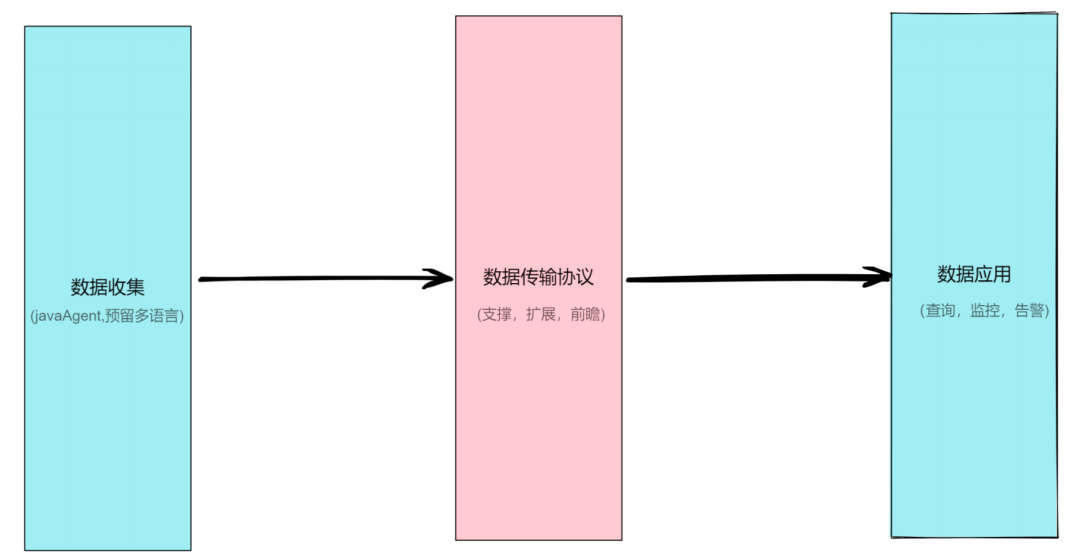
資料收集:采用 JavaAgent 來提供無侵入的支持,同時我們也在設計階段預留了多語言的支持,
資料傳輸協議:資料傳輸協議相對來說沒那么好改,它需要具有前瞻性、支撐性和擴展性,在協議設計時需更慎重,
資料應用:支撐豐富的檢索、監控、告警的訴求,
基于以上三點考慮,我們設計了微盟呼叫鏈體系,其整體架構如圖所示,
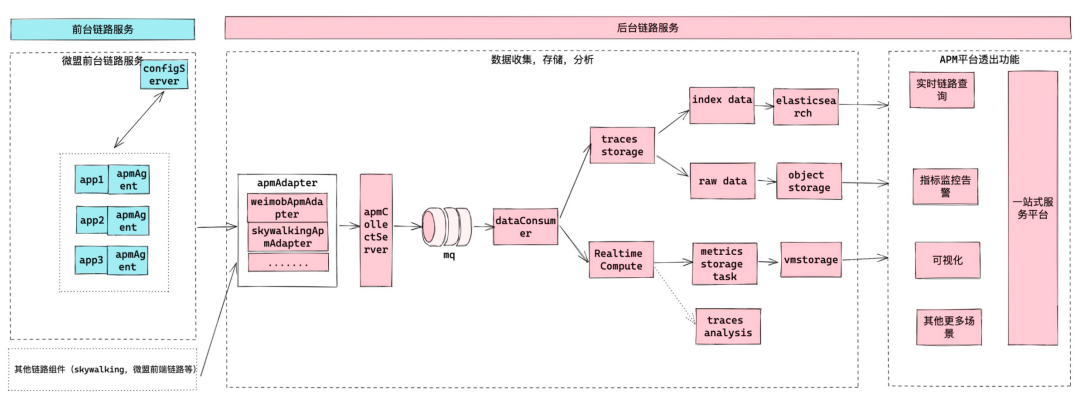
(微盟呼叫鏈體系架構圖)
2.2 前臺鏈路服務
前臺鏈路服務的建設,我們需要達到的三個目標:
- 降低接入成本;
- 支持動態化配置;
- 支持多語言,
2.2.1 降低接入成本-JavaAgent
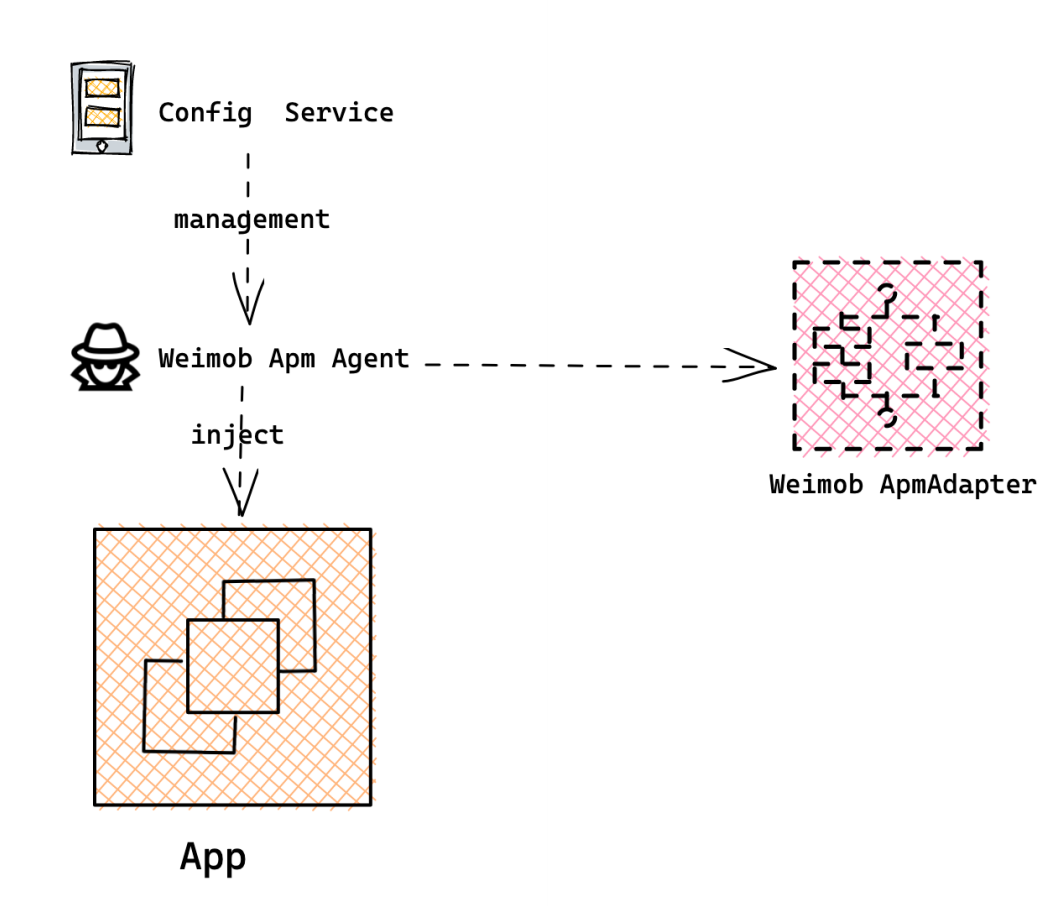
從節省成本的角度,我們選擇了無侵入的JavaAgent技術,而非使用SDK構建,
這里簡單先介紹JavaAgent的技術實作程序——在啟動JVM時注入一個插件,這個插件相當于一個“外掛”,我們在插件里對業務的一系列關鍵流程注入了觀察埋點,
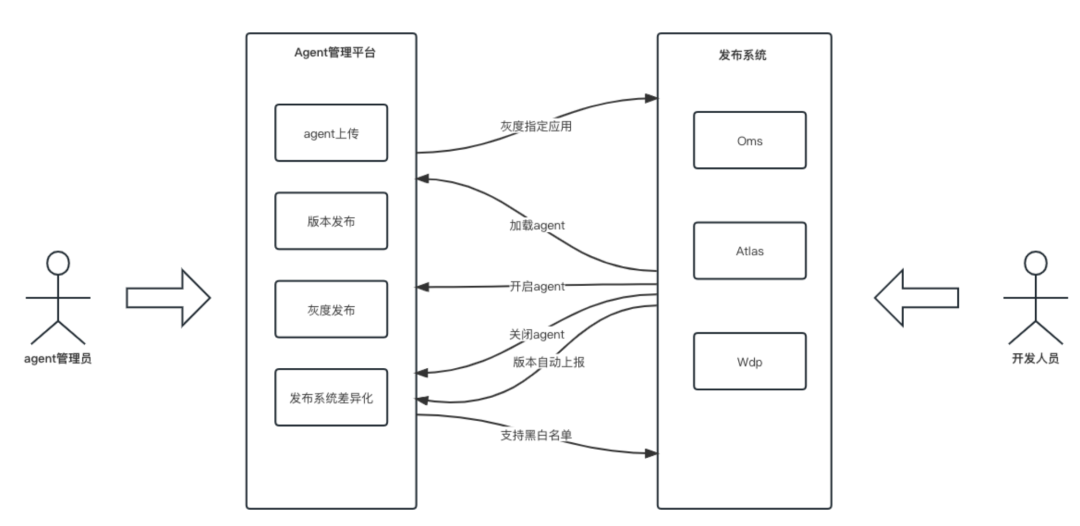
我們基于JavaAgent技術搭建了Agent管理平臺,實作Agent的上傳、版本發布、灰度、發布系統差異化等的一站式管理,同時由于微盟的主要語言是Java,所以大部分接入成本是非常低的,從業務方使用的角度,只需要在后臺通過開關操作,打開呼叫鏈并進行專案重啟后,即可自動顯示應用,并快速觀測其鏈路情況,
為何不選擇常規的SDK構建?因為業務方需要引入SDK并進行相關代碼注入和配置,隨著微盟業務的擴張,后續如果需要支撐更多組件,當系統需要升級或SDK出問題時,推動業務方升級的成本則會非常高,
因此最終我們推薦采用JavaAgent技術來實作,其在減少業務方接入成本、提高整體收益、多方協作滿意度等方面表現都相對出色,
2.2.2 動態化配置
1)實作原理-借助apollo配置中心
我們借助了開源的apollo(阿波羅)配置中心來支持動態化配置,其實作程序如圖,服務會動態地、實時地下發配置,Agent 接收到配置后進行相應的行為驗證,
2)踩坑分享-Agent 類加載問題
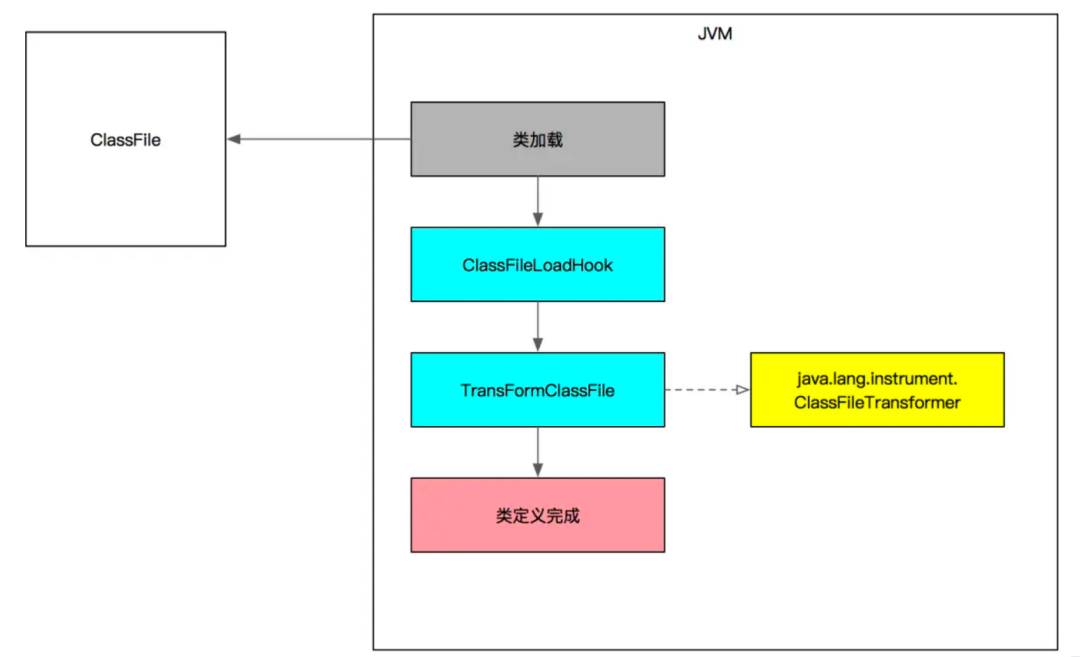
在Agent接入時,也會碰到一些問題,其中踩過的最大的坑就是類加載問題,
在Agent中使用到的類和jar包和業務方使用的類產生了沖突,比如Agent 使用了一個低版本、業務方使用了高版本的類,此時既有可能加載高版本,也有可能加載低版本,就產生了版本沖突進而導致業務方系統故障,
我們的解決辦法是Agent利用Shade工具進行依賴包重命名,這樣類加載時就不再互相干擾,這個踩坑經驗希望能對其他實踐者產生幫助,避免重走彎路,
2.2.3 多語言支持
微盟老的呼叫鏈體系是基于自制的背景關系實作的,支持 Trace ID 、 RPC ID 等等,那么如何進一步提供多語言支持,盡可能地減少基礎架構的維護成本?
我們選擇借助開源的力量,除支持微盟協議外,平臺還支持了Skywalking的跨行程傳播的協議,借助Skywalking豐富的SDK,既能滿足的業務方更小眾的語言的監控訴求,也能同時減少維護成本,
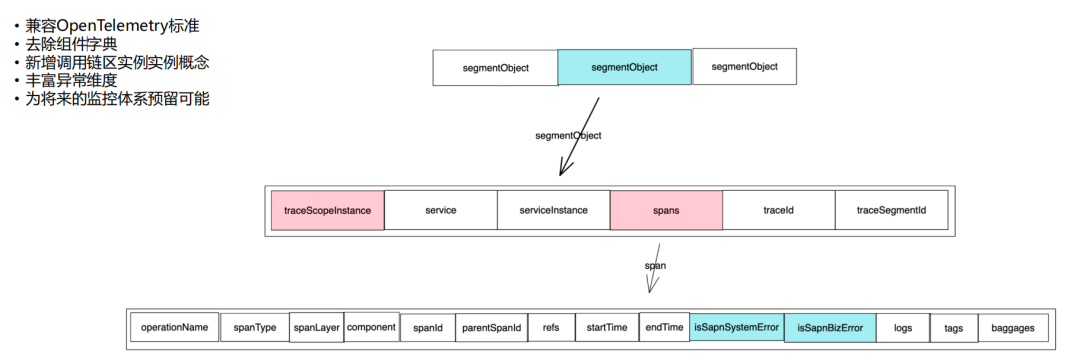
2.3 呼叫鏈資料結構
調鏈資料結構上我們想達成的三個目標——支撐性、擴展性、前瞻性,

我們借鑒了OpenTelemetry標準和Skywalking的協議,構建了微盟自己的鏈路資料結構,如下圖所示,
2.4 后臺鏈路服務
后臺鏈路服務我們需要達到以下四個目標:
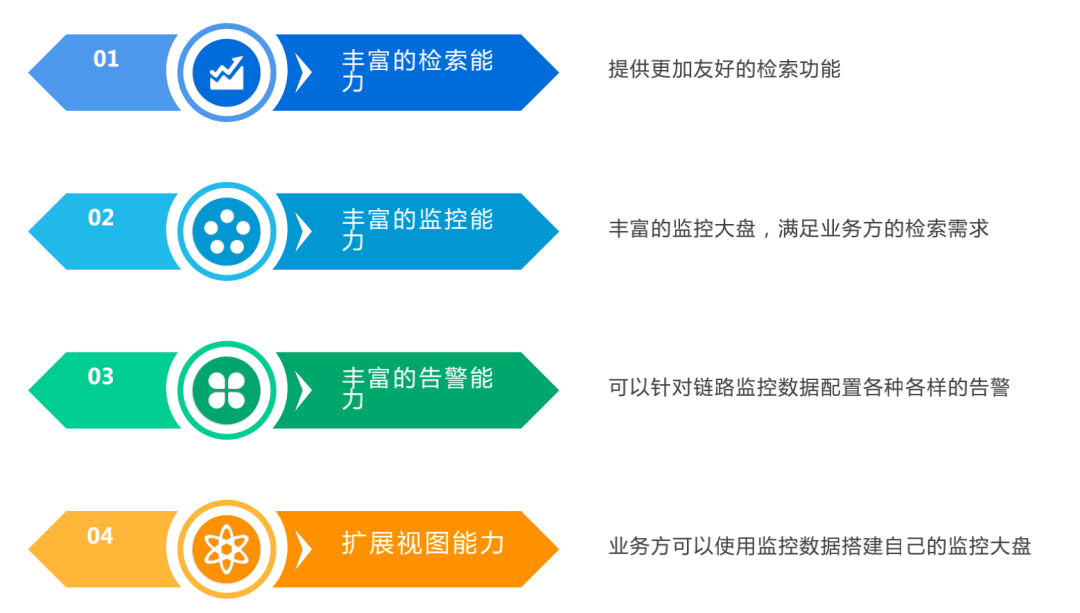
那么如何才能做到?首先是上面提到的資料結構擴展,然后構建了高性能的監控體系,把資料存盤到VictoriaMetrics(時序資料庫),做更多可視化展示,最后是支撐業務例外的檢索和關鍵業務的檢索,以滿足業務方多樣性的檢索、監控、可視化訴求,
三、呼叫鏈體系在微盟的落地效果如何?
該部分我將結合微盟的實際落地效果,展開講解上一章末的目標是如何達成的,
3.1 業務關鍵字能力
基于對微盟業務的思考,我們做了業務關鍵字的能力,這里不在于技術的實作,而在于這個訴求本身如何滿足,
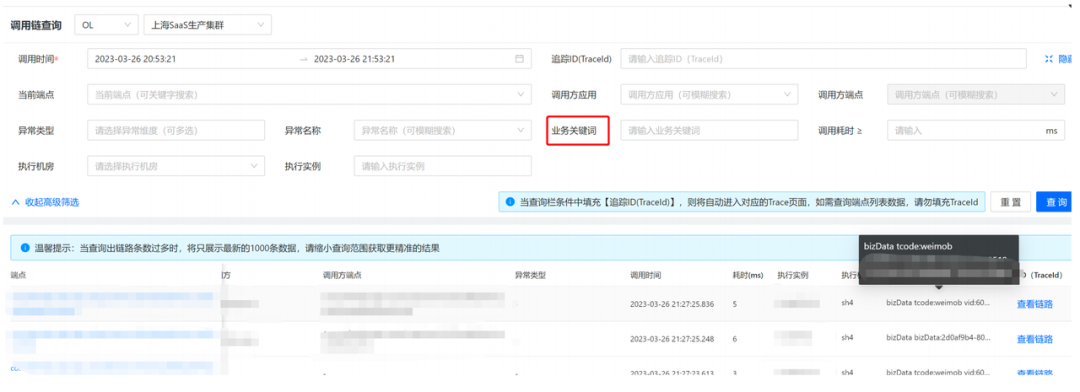
傳統的呼叫鏈體系通常會支持 Tag 類檢索,但是 Tag 檢索需要業務方做手動埋點,才能進行后續的檢索,除了業務方的人力投入問題,這類檢索常常不能完全滿足業務方檢索需求,而業務關鍵字能力則能以最小的人力、存盤成本,達成更好的效果,
以微盟的典型場景為例,某用戶下單出現問題,找到業務部門投訴,傳統的呼叫鏈此時是無法確定用戶鏈路的,而通過提取入參的關鍵業務引數,把它分析到業務關鍵字里去,此時只需要輸入該用戶的ID,在平臺進行檢索即可完成此項訴求,平臺會默認收集入參中的脫敏關鍵引數,其他無關資訊則不做保留,以此減輕ES存盤成本,用約10%的成本來完成100%的觀測訴求,
3.2 業務例外能力
收集業務場景的所有Dobbo介面的出參資訊并做序列化,業務方則可以通過例外碼來識別例外,

假設業務上有下單流程失敗了,此時會拋出一個例外碼,此時呼叫鏈上可以一目了然,并能下鉆到詳細資訊,
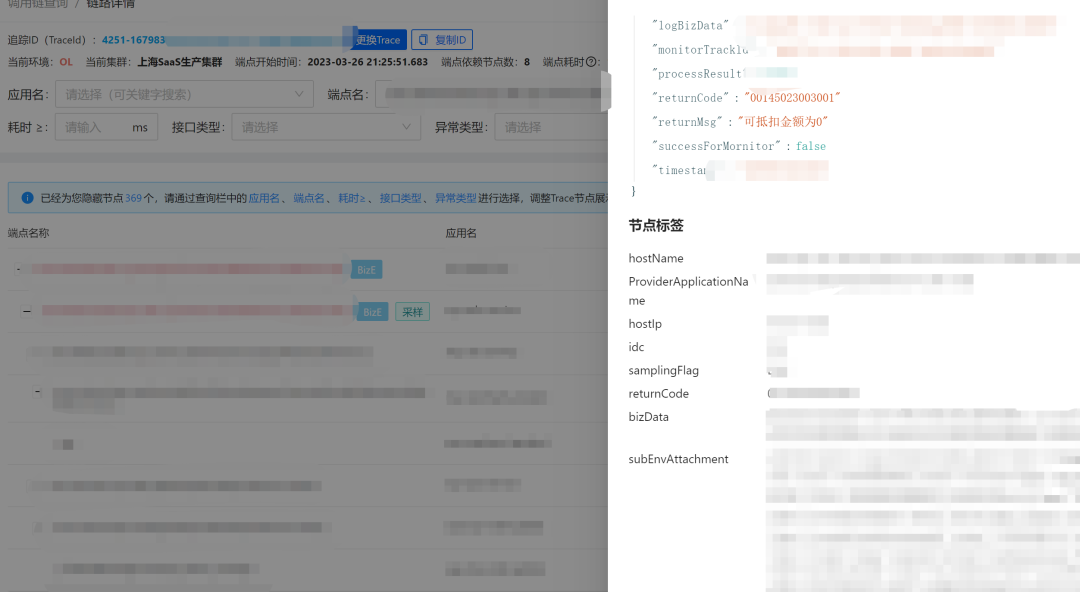
業務例外梳理后不僅可以做展示,也可以做監控大盤,看到業務例外的整體概況,

如果業務方有監控告警的訴求,也可以在平臺上設定想要監控的例外,并選擇業務例外碼進行監控,
3.3 指標能力
把指標存盤到了時序資料庫,它支持Prometheus 標準的查詢,在此基礎上,業務方可以各自進行大盤構建,
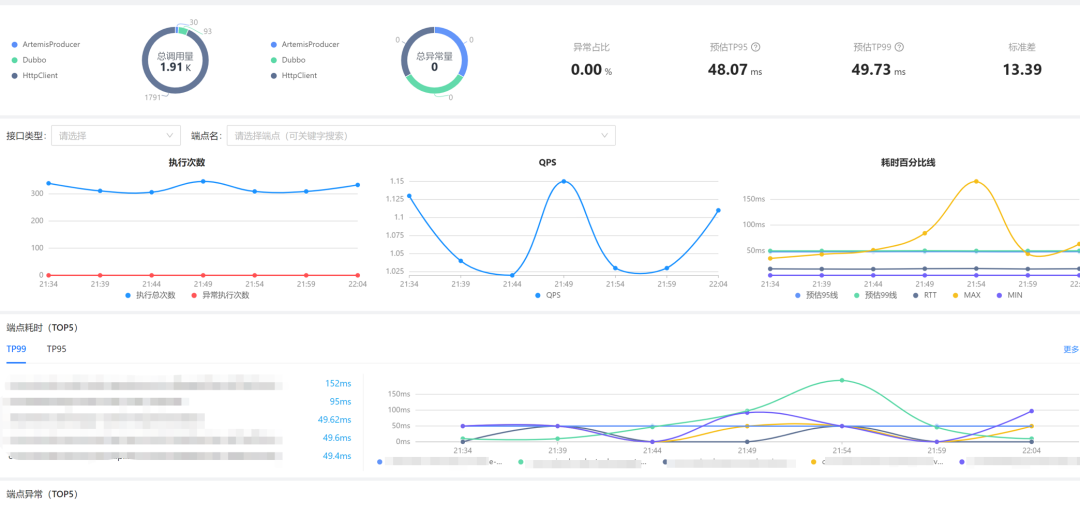
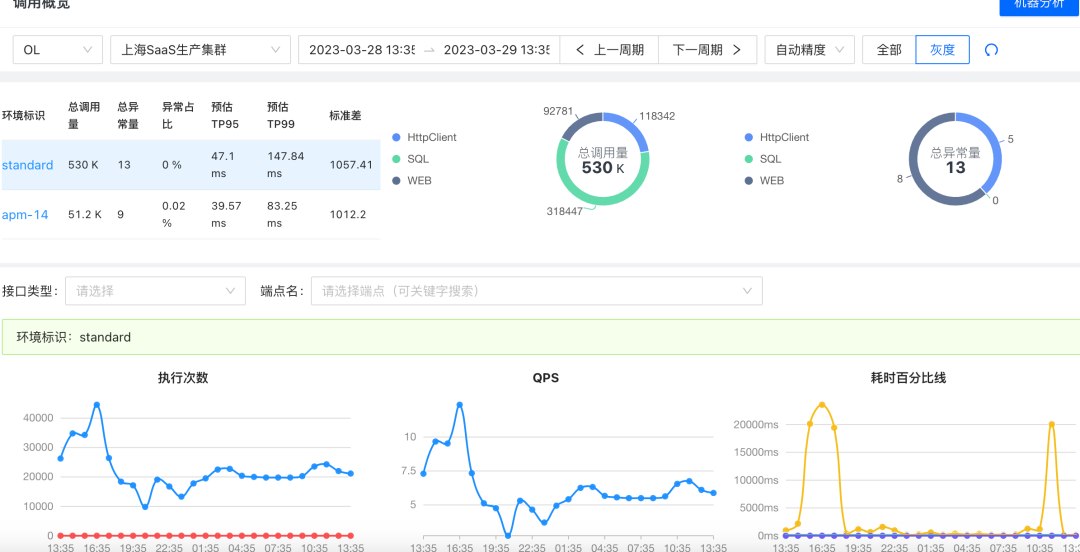
在大盤上可以看到總呼叫量、總例外量、例外占比、TP線等等,如業務方需要了解某介面的場景,也可輸入進行檢索,端點耗時、端點例外等排行,基于業務側應用維度的概況在平臺上一目了然,
平臺也和灰度做了打通,在呼叫鏈體系,也能深入識別到灰度環境下的鏈路概況,
3.4 端點分析
3.4.1 當前端點分析
端點分析中可以進行趨勢分析,查看高耗時鏈路,查看例外鏈路,點擊例外鏈路可以進入例外鏈路頁面,查看例外鏈路詳細情況,整個查詢體系、監控體系、告警體系、日志體系都互相聯動,
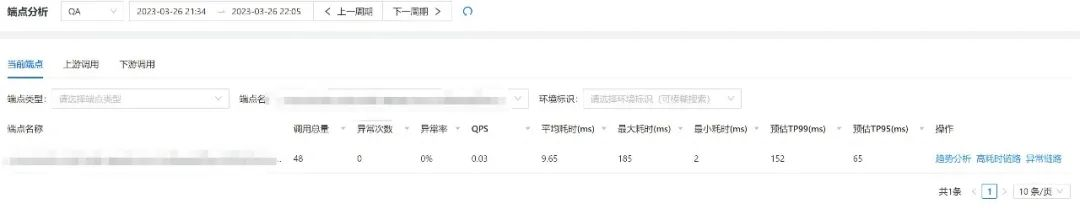
(微盟呼叫鏈-端點級別的展示查詢)
3.4.2 上下游分析
業務方有個比較普遍的訴求,是能看到應用的上下游呼叫情況,而不僅僅只是當前應用的概況,因此,我們基于呼叫鏈的資料采集功能,收集上下游呼叫的應用服務名稱、服務實體以及其他資訊,再進一步分析出上下游的鏈路呼叫情況,比如呼叫總量、例外次數、例外率、平均耗時等等,
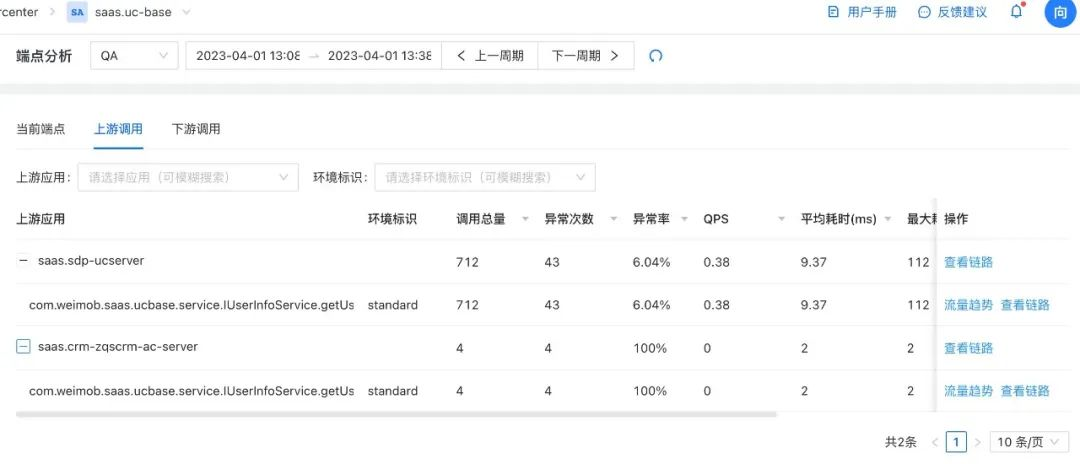
3.5 APM一體化
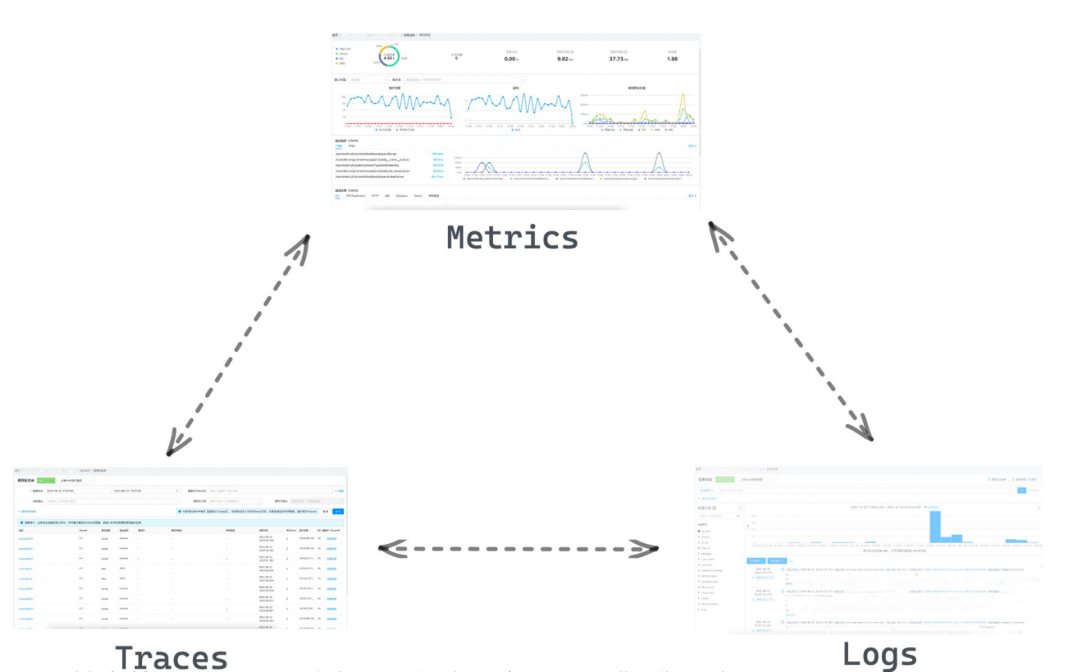
3.5.1 觀測能力
APM一體化不僅為鏈路提供了更豐富的能力,還和指標體系、日志體系打通,實作了體系間相互跳轉,為業務方提供更好的觀測能力,包括實體、CPU、記憶體以及其他應用自定義的指標觀測,
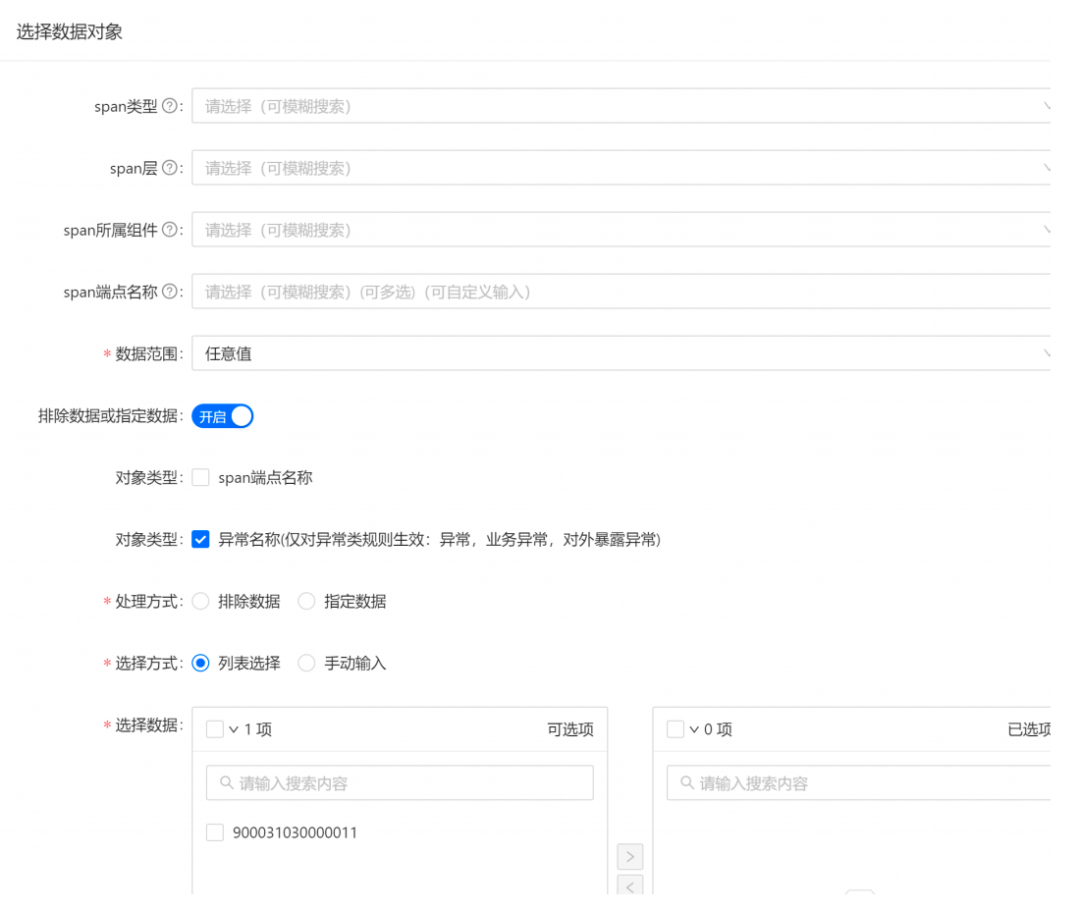
3.5.2 告警能力
一體化平臺的告警能力支持按Span型別、層次、所屬組件、端點名稱等進行資料指定或排除,
3.6 一個降本增效的案例
1)問題描述
微盟此前資料存盤了 6000 多億條,但是線上呼叫鏈服務查詢可能只有幾千次,其中有非常大的資源浪費,在滿足業務方查詢訴求的基礎上,存盤成本需要做持續優化,

2)解決程序
- 采集例外鏈路資訊,丟棄正常資料
我們通過鏈路染色采樣來實作,其具體實作程序如下,
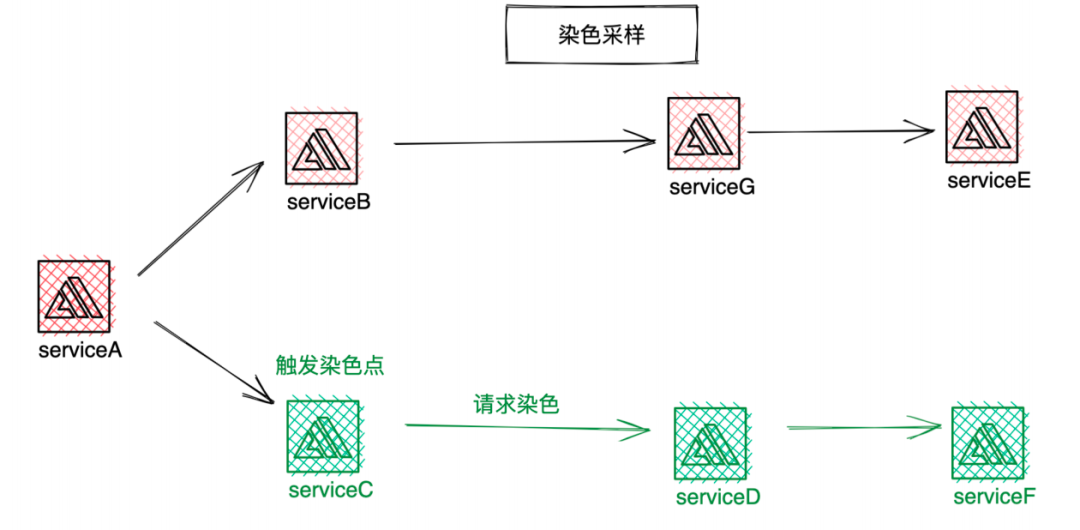
鏈路采樣中,系統發現需要保存的鏈路就會觸發染色,染色后的鏈路都會保存,染色的場景包括耗時染色采樣、例外染色采樣,比如某些耗時較高的鏈路則會染色保留,其他正常的鏈路會執行采樣流程,命中采樣規則后,Span會丟棄,微盟采樣有組件比例采樣和白名單模式兩種規則,
DB請求和Cache請求均僅保留10%
在實踐中我們發現鏈路有50%以上是 Redis 請求和DB請求,正常情況下呼叫鏈觀測的是應用和應用之間的呼叫,對于業務方不太關注和價值度不高的鏈路,微盟目前線上保留比例是10%,以節省整體存盤成本,
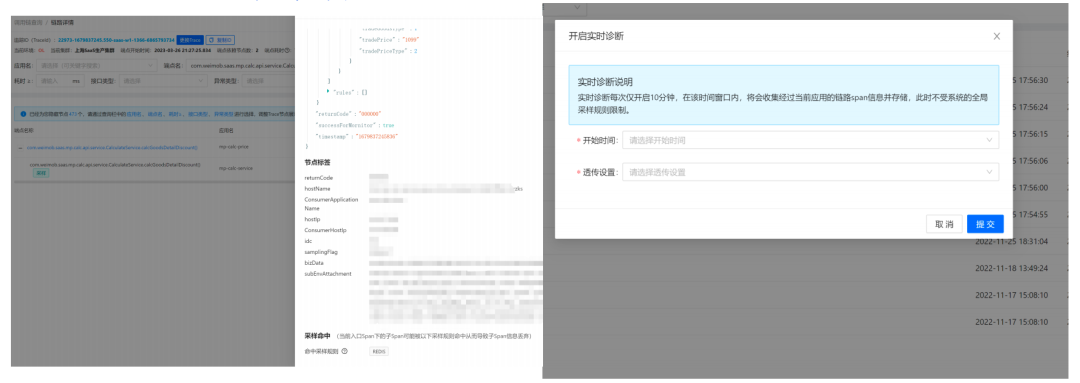
(鏈路采樣&實時診斷頁面)
若業務方希望在上線后觀測應用情況,可以開啟實時診斷,開啟實時診斷后的10分鐘內,鏈路資訊可以做全保留,在此期間不涉及采樣規則的限制,
3)實踐效果
成本降低40%,線上推廣鏈路采樣后,DB和Cache的流量下降非常明顯,鏈路的存盤規模降低了40%左右,整體存盤成本也降低了40%,
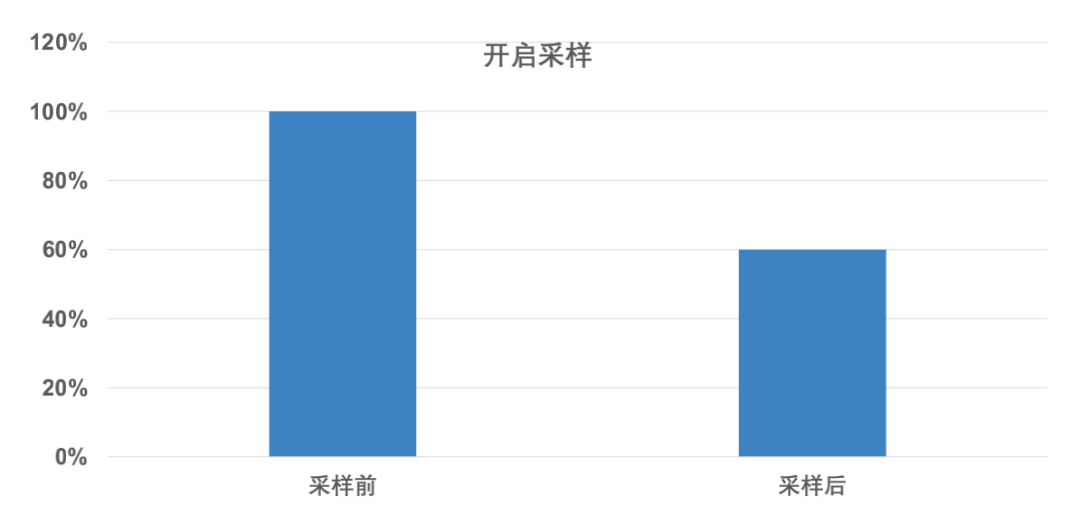
基本覆寫Online及QA環境中核心關鍵業務,
研發排障效率大幅提升,通過體系化的一站式APM平臺大幅度提升了用戶體驗,同時減少了用戶的排障成本,舉個例子,業務方接到訂單介面告警后,到鏈路指標排查訂單介面指標,發現需要進一步排查,點擊進入鏈路查詢板塊,直接定位例外鏈路,查看鏈路詳情,假如需要進一步排障,點擊查看日志,進入日志板塊查看具體的鏈路資訊,整個排障流程,清晰明了,而在此之前,同樣的場景,排障流程繁瑣,用戶需要在多個平臺檢索,用戶同樣接收到訂單介面告警后,需要到鏈路平臺根據時間段檢索鏈路ID,或者從回應體中抓取鏈路ID,假如沒有及時抓到,那只能根據時間段進行檢索了,抓到鏈路后,再到ELK中根據時間檢索對應日志,
四、未來規劃
在鏈路體系和指標體系的基礎上,接下來我們會健全流量漏斗和告警溯源相關能力,
在大促場景下,通過流量拓撲圖,為業務方提供入口到后端應用的流量放大比例,讓業務方直觀看到流量可能會對哪些應用產生影響,當某個應用出現問題后,業務方能快速進行應用級別的定位,
目前我們正在做相關的調研和探索,也歡迎有經驗的朋友做交流,(全文完)
Q&A
1、技術實作上微盟還踩了哪些典型的坑?如何避坑?
2、Agent發布節奏如何把握?是否可以支持在運行時帶上?
3、異步訊息場景,上下游呼叫鏈如何串聯?
4、整個呼叫鏈平臺有開源計劃嗎?外部租戶是否可以接入?
5、幾千億的資料有沒有其他的資料價值,怎么利用?
更多詳細內容:https://news.shulie.io/?p=6157,
觀看完整版解答!


添加助理小姐姐,憑截圖免費領取以上所有資料
并免費加入「TakinTalks讀者交流群」

宣告:本文由公眾號「TakinTalks穩定性社區」聯合社區專家共同原創撰寫,如需轉載,請后臺回復“轉載”獲得授權,
本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/551294.html
標籤:其他
上一篇:億級榷訓業務穩如磐石,華為云CodeArts PerfTest發布
下一篇:返回列表