1.概述
ChatGPT是當前自然語言處理領域的重要進展之一,通過預訓練和微調的方式,ChatGPT可以生成高質量的文本,可應用于多種場景,如智能客服、聊天機器人、語音助手等,本文將詳細介紹ChatGPT的原理、實戰演練和流程圖,幫助讀者更好地理解ChatGPT技術的應用和優勢,
2.內容
在當今快速發展的人工智能領域,自然語言處理(Natural Language Processing, NLP)技術是研究的重要方向之一,NLP技術的目標是幫助計算機更好地理解和處理人類語言,從而實作人機互動、自然語言搜索、文本摘要、語音識別等應用場景,
ChatGPT是當前自然語言處理領域的重要進展之一,可以生成高質量的文本,可應用于多種場景,如智能客服、聊天機器人、語音助手等,本文將詳細介紹ChatGPT的原理、實戰演練和流程圖,幫助讀者更好地理解ChatGPT技術的應用和優勢,
2.1 原理分析
ChatGPT是由OpenAI推出的一種基于Transformer的預訓練語言模型,在自然語言處理中,預訓練語言模型通常是指使用無標簽文本資料訓練的模型,目的是為了提高下游任務(如文本分類、命名物體識別、情感分析)的性能,ChatGPT是預訓練語言模型的一種,它采用了單向的Transformer模型,通過大規模的文本資料預訓練模型,再在具體任務上進行微調,從而實作高質量的文本生成和自然對話,
下面我們來詳細介紹一下ChatGPT的原理,
2.1.1 Transformer模型
ChatGPT模型采用了單向的Transformer模型,Transformer模型是一種基于注意力機制的編碼-解碼框架,由Google在2017年提出,它是目前自然語言處理中應用最廣泛的模型之一,已經被證明在多種任務上取得了比較好的性能,
Transformer模型的核心是多頭注意力機制,它允許模型在不同位置上對輸入的資訊進行不同的關注,從而提高模型的表達能力,同時,Transformer模型采用了殘差連接和Layer Normalization等技術,使得模型訓練更加穩定,減少了梯度消失和梯度爆炸等問題,
在Transformer模型中,輸入的序列首先經過Embedding層,將每個詞映射為一個向量表示,然后輸入到多層Transformer Encoder中,每一層包括多頭注意力機制和前向傳播網路,在多頭注意力機制中,模型會計算出每個位置與其他位置的關聯程度,從而得到一個權重向量,將這個權重向量應用到輸入上,就得到了每個位置的加權表示,接下來,模型會將每個位置的加權表示與原始輸入進行殘差連接和Layer Normalization,從而得到更好的表達,
在ChatGPT模型中,Encoder和Decoder是相同的,因為它是單向的模型,只能使用歷史資訊生成當前的文本,每次生成一個新的詞時,模型會將歷史文本作為輸入,通過Decoder生成下一個詞,
2.1.2 預訓練
ChatGPT模型的預訓練使用的是大規模的無標簽文本資料,例如維基百科、網頁文本等,這些資料可以包含數十億甚至數百億的單詞,預訓練的目的是讓模型學習到文本的語言規律和語意資訊,從而提高模型的泛化能力,預訓練使用的是語言建模任務,即在給定部分文本的情況下,模型預測下一個詞是什么,預測的損失函式采用交叉熵損失函式,通過反向傳播和隨機梯度下降演算法更新模型引數,
2.1.3 微調
ChatGPT模型的微調是指在特定的任務上,針對不同的資料集,對預訓練模型進行微調,微調的目的是將模型應用到具體的場景中,例如聊天機器人、智能客服等,微調程序中,我們會為模型添加一些特定的輸出層,根據具體的任務來調整模型的引數,
2.2 ChatGPT
ChatGPT是一款通用的自然語言生成模型,即GPT翻譯成中文就是生成型預訓練變換模型,這個模型被互聯網巨大的語料庫訓練之后,它就可以根據你輸入的文字內容,來生成對應的文字回答,也就是常見的聊天問答模式,比如:
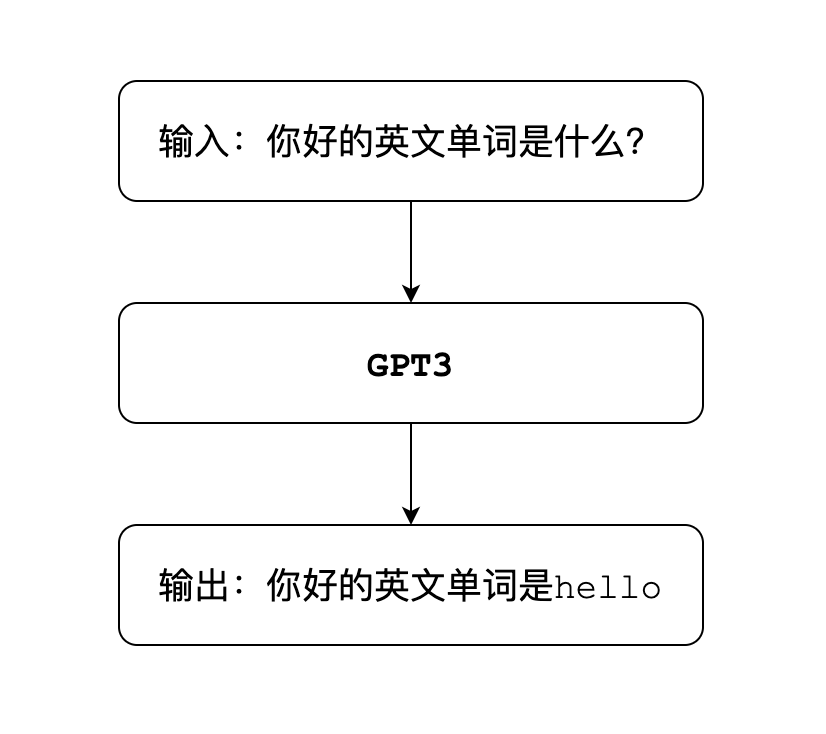
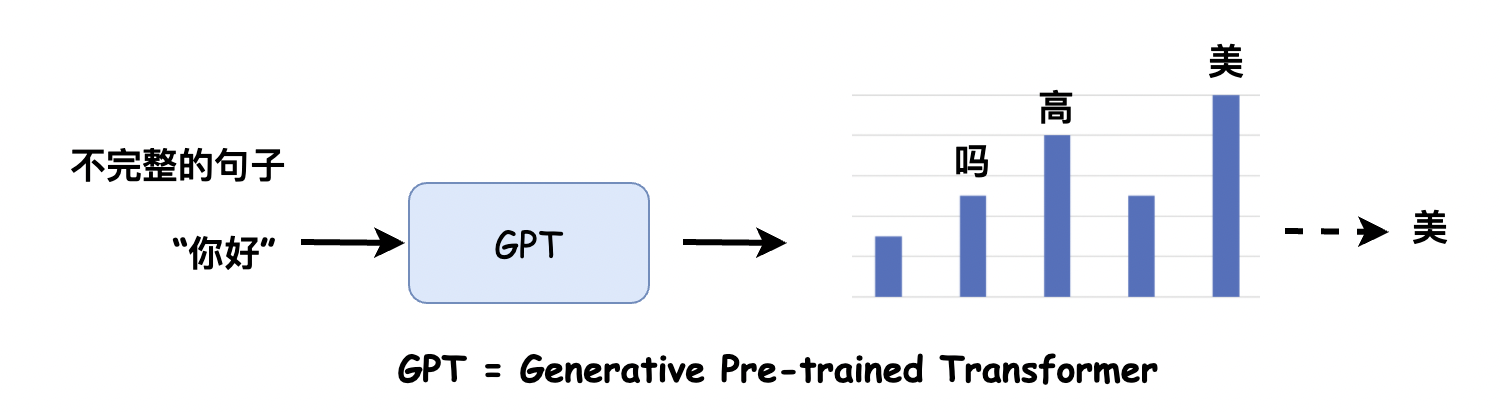
語言模型的作業方式,是對語言文本進行概率建模,

用來預測下一段輸出內容的概率,形式上非常類似于我們小時候玩的文字接龍游戲,比如輸入的內容是你好,模型就會在可能的結果中,選出概率最高的那一個,用來生成下一部分的內容
從體驗的反饋來看,ChatGPT對比其他的聊天機器人,主要在這樣幾個方面上進步明顯:
- 首先,它對用戶實際意圖的理解有了明顯的提升,以前用過類似的聊天機器人,或者自動客服的朋友,應該會經常遇到機器人兜圈子,甚至答非所問的情況,而ChatGPT在這方面有了顯著的提升,大家在實際體驗了之后感覺都非常的明顯;
- 其次,是非常強的背景關系銜接能力,你不僅能夠問他一個問題,而且還可以通過不斷追加提問的方式,讓它不斷的改進回答內容,最終達到用戶想要的理想效果,
- 然后,是對知識和邏輯的理解能力,當你遇到某個問題,它不僅只是給一個完整的回答,同時,你對這個問題的各種細節追問,它都能回答出來,
ChatGPT目前暫時還沒有看到與之相關的論文,但是,官網有一篇Instruct GPT和ChatGPT是非常接近的,在官網上也指出了ChatGPT是InstructGPT的兄弟模型,它經過訓練可以按照指示中的說明進行操作并提供詳細的回應,

這里我們可以看到2個模型的訓練程序非常的相似,文章地址:
-
https://openai.com/research/instruction-following
- https://openai.com/blog/chatgpt
ChatGPT訓練流程如下所示:
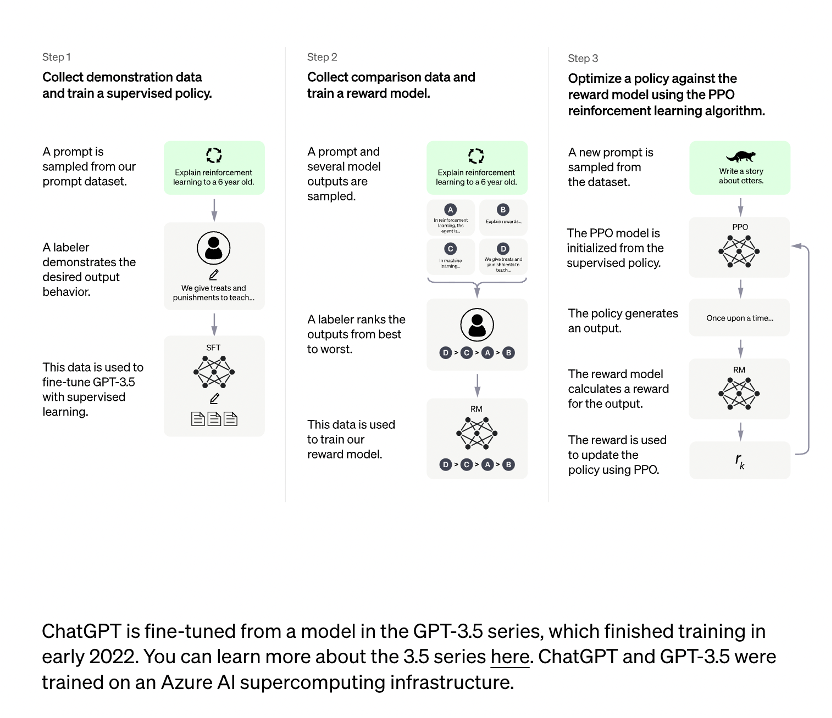
InstructGPT訓練流程如下所示:
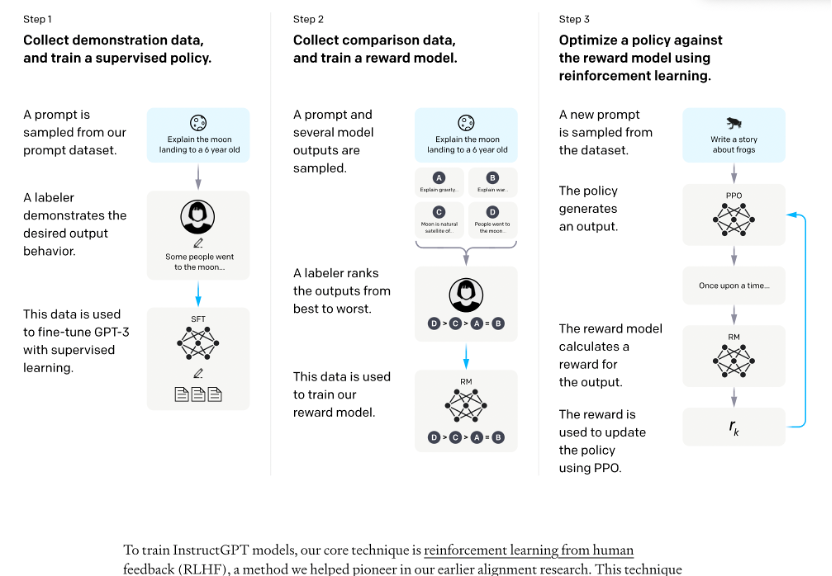
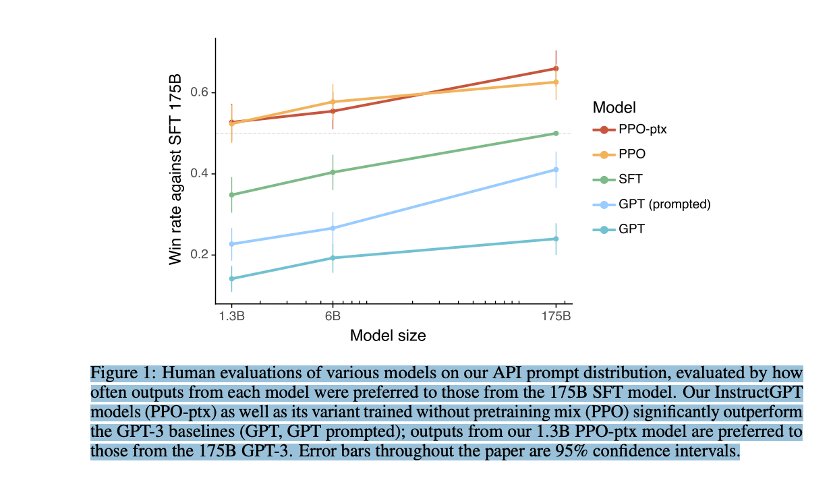
在OpenAI關于InstructiGPT中的論文中,有可以找到這些直觀優勢的量化分析,

InstructGPT對比上一代GPT3:
- 首先在71%的情況下,InstructGPT生成的回答要比GPT3模型的回答要更加符合訓練人員的喜好,這里提到GPT3是OpenAI的上一代自然語言生成模型,
- 其次,InstructGPT在回答問題的真實程度上,也會更加可靠,當兩個模型同時被問到他們完全不知道的內容時,InstructGPT只有21%的情況會編造結果,而GPT3就高了,多達到了41%,這里,我們可以發現,即便是最厲害的模型它也有五分之一的概率會胡說八道;
- 除此之外,InstructGPT在產生有毒回答的概率上也減小了25%,
所以,匯總下來,InstructGPT比上一代模型能夠提供更加真實可靠的回答,并且回答的內容也會遠比上一代更加符合用戶的意愿,
3.如何做到這些提升的呢?
我們要看清楚ChatGPT,為什么可以做到如此出色的效果,就需要我們把視角稍微拉遠一點,看一看這款模型,近幾年的發展歷史,
ChapGPT是OpenAI的另一款模型,它是InstructGPT的兄弟模型,也就是基于InstructGPT做了一些調整,而InstructGPT的上一代是GPT3,再往上一個版本是GPT2,再往上是GPT,那再往前就是Google的那一篇關于transformer的著名論文(https://arxiv.org/pdf/1706.03762.pdf),這里需要提一下的是,同樣是基于transformer結構的,還有Google自家的BERT架構,以及對應的分支,
所以,我們能夠得到這樣一個分支圖,
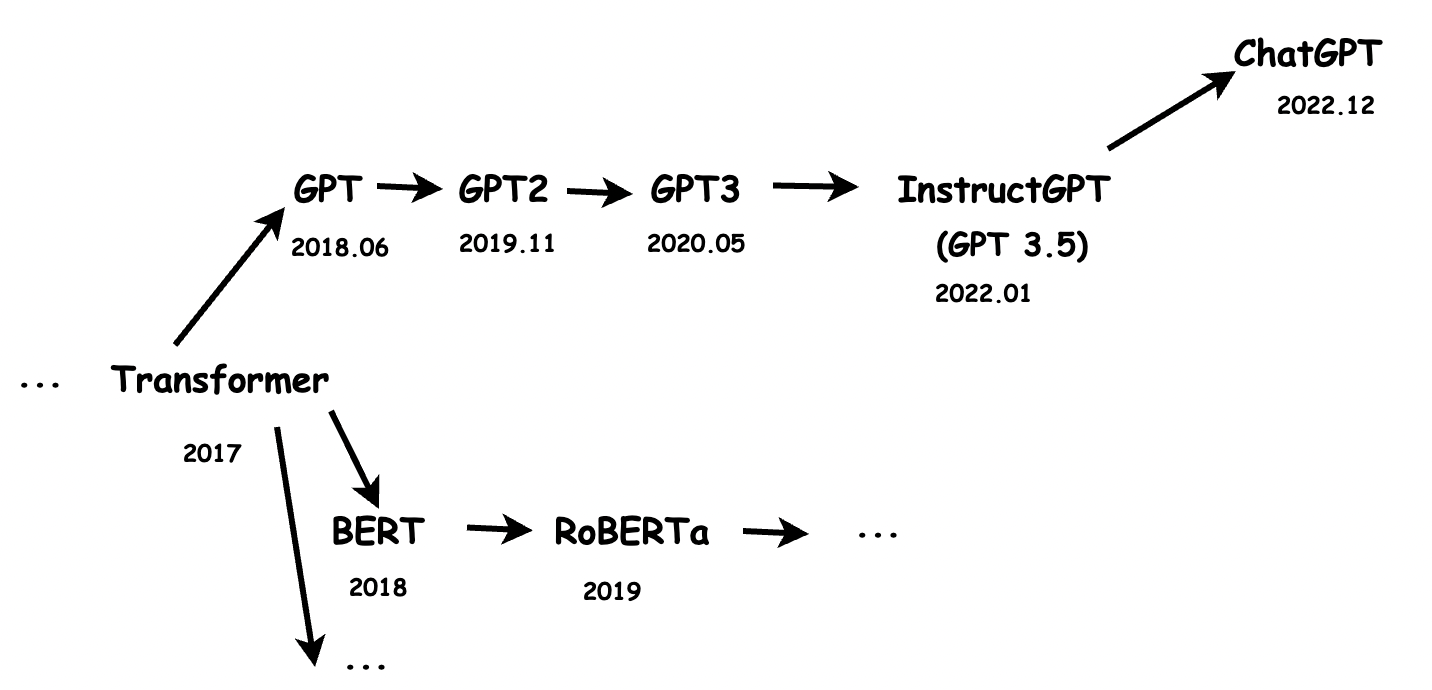
這里,本人能力有限,沒法對每一篇論文分析總結,但是,想提到一些自己在學習的程序中感覺比較有趣的決定和突破,
首先,同樣是transformer架構上分支出來的,BERT和GPT的一大不同,來自于他們transformer具體結構的區別,BERT使用的是transformer的encoder組件,而encoder的組件在計算某個位置時,會關注他左右兩側的資訊,也就是文章的背景關系,而GPT使用的是transformer decoder組件,decoder組件在計算某個位置時,只關注它左側的資訊,也就是文章的上文,
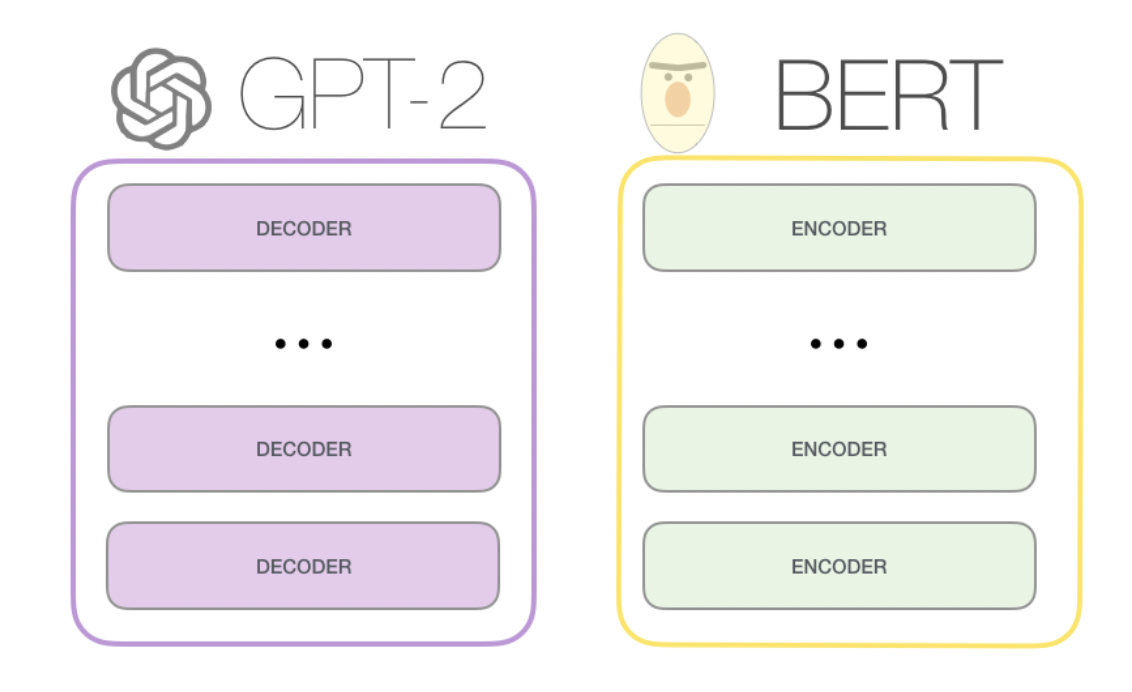
我們如果用一個通俗的比喻就是,BERT在結構上對背景關系的理解會更強,更適合嵌入式的表達,也就是完型填空式的任務,而GPT在結構上更適合只有上文,完全不知道下文的任務,而聊天恰好就是這樣的場景,
另一個有趣的突破,來自模型量級上的提升,
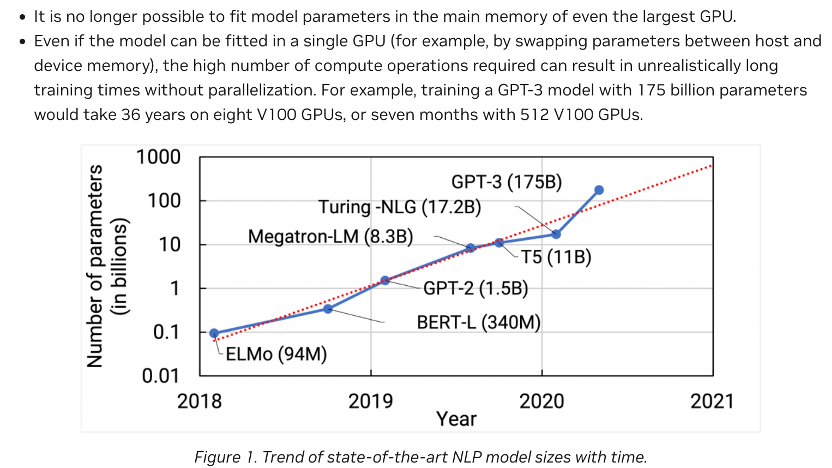
從GPT到GPT2,再到GPT3,OpenAI大力出奇跡,將模型引數從1.17億,提升到15億,然后進一步暴力提升到了1750億個,以至于GPT3比以前同型別的語言模型,引數量增加了10倍以上,
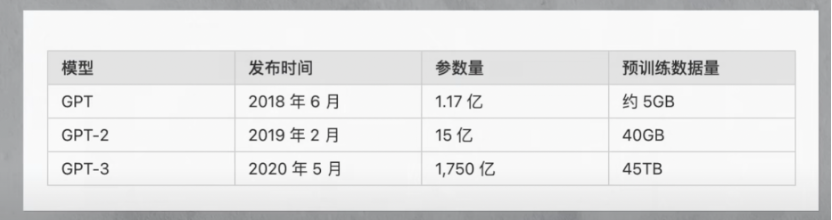
同時,訓練資料量也從GPT的5GB,增加到GPT2的40GB,再到GPT3的45TB,與此相關的是在方向上(https://arxiv.org/pdf/2005.14165.pdf)
OpenAI沒有追求模型在特定型別任務上的表現,而是不斷的增加模型的泛化能力,同時,GPT3的訓練費用,也到達了驚人的1200萬美元,

那下一個有趣的節點,就達到了今天的主角ChatGPT的兄弟,InstructGPT,從GPT3到InstructGPT的一個有趣改進,來自于引入了人類的反饋,用OpenAI論文的說法是,在InstructGPT之前,大部分大規模語言模型的目標,都是基于上一個輸入片段token,來推測下一個輸入片段,
然而這個目標和用戶的意圖是不一致的,用戶的意圖是讓語言模型,能夠有用并且安全的遵循用戶的指令,那這里的指令instruction,也就是InstructGPT名字的來源,當然,也就呼應的今天ChatGPT的最大優勢,對用戶意圖的理解,為了達到這個目的,他們引入了人類老師,也就是標記人員,通過標記人員的人工標記,來訓練出一個反饋模型,那這個反饋模型,實際上就是一個模仿喜好,用來給GPT3的結果來打分的模型,然后這個反饋模型再去訓練GPT3,之所以沒有讓標記人員,直接訓練GPT3,可能是因為資料量太大的原因吧,
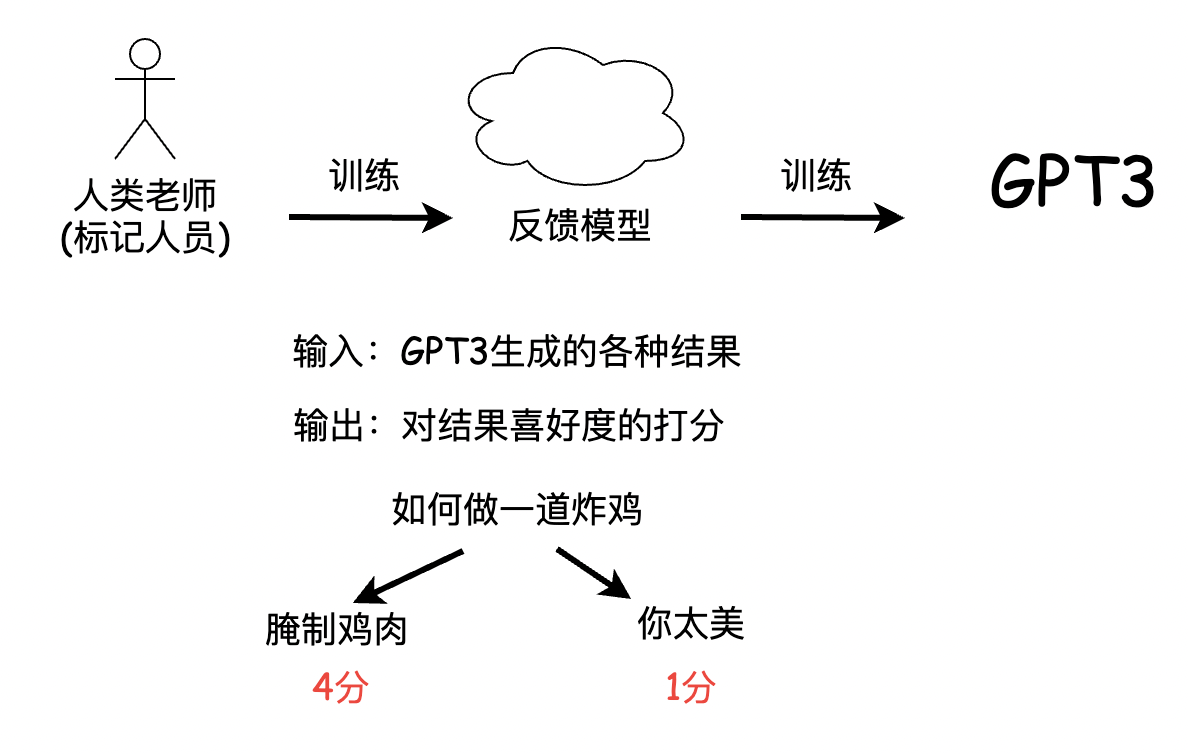
所以,這個反饋模型,就像是被抽象出來的人類意志,可以用來激勵GPT3的訓練,那整個訓練方法,就被叫做基于人類反饋的強化學習,至此簡易版的InstructGPT的前世今生就介紹完了,我們來回顧一下OpenAI一直在追求的幾個特點:
- 首先,是只有上文的decoder結構,這種結構下訓練出來的模型,天然適合問答這種互動方式;
- 然后,是通用模型,OpenAI一直避免在早期架構和訓練階段,就針對某個特定的行業做調優,這也讓GPT3有著很強的通用能力
- 最后,是巨量資料和巨量引數,從資訊論的角度來看,這就像深層的語言模型,涵蓋的人類生活中,會涉及的幾乎所有的自然語言和編程語言,當然,這也就極大的提高了個人或者小公司參與的門檻,
既然說到了原理,還有一個方面是前面沒有提及到的,就是連續對話的能力,所以,ChatGPT是如何做到能夠記住對話的背景關系的呢?
這一能力,其實在GPT3時代就已經具備了,具體做法是這樣的,語言模型生成回答的方式,其實是基于一個個的token,這里的token,可以粗略的理解為一個個單詞,所以ChatGPT給你生成一句話的回答,其實是從第一個詞開始,重復把你的問題以及當前生成的所有內容,再作為下一次的輸入,再生成下一個token,直到生成完整的回答,
4.實戰演練
為了更好地理解ChatGPT模型的實際應用,我們可以嘗試使用Hugging Face提供的Transformers庫來構建一個聊天機器人模型,
1.準備資料集
我們可以使用Cornell電影對話資料集來作為ChatGPT模型的訓練資料集,Cornell電影對話資料集包含了超過220,579條對話記錄,每條記錄都有一個問題和一個回答,我們可以將問題和回答組合在一起,形成聊天機器人的訓練樣本,
2.資料預處理
在訓練ChatGPT模型之前,我們需要對資料進行預處理,將文本轉換為數字表示,我們可以使用tokenizer將文本轉換為tokens,并將tokens轉換為模型輸入的數字表示,在使用Hugging Face的Transformers庫中,我們可以使用AutoTokenizer自動選擇適合的tokenizer,根據模型的型別和配置來進行初始化,
以下是對電影對話資料集進行預處理的代碼:
from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained('distilgpt2') pad_token_id = tokenizer.pad_token_id max_length = 512 def preprocess_data(filename): with open(filename, 'r', encoding='iso-8859-1') as f: lines = f.readlines() conversations = [] conversation = [] for line in lines: line = line.strip() if line.startswith('M '): conversation.append(line[2:]) elif line.startswith('E '): conversation.append(line[2:]) if len(conversation) > 1: conversations.append(conversation) conversation = [] questions = [] answers = [] for conversation in conversations: for i in range(len(conversation) - 1): questions.append(conversation[i]) answers.append(conversation[i+1]) inputs = tokenizer(questions, answers, truncation=True, padding=True, max_length=max_length) return inputs, pad_token_id inputs, pad_token_id = preprocess_data('movie_conversations.txt')
在上述代碼中,我們使用了AutoTokenizer來初始化tokenizer,并指定了最大的序列長度為512,同時,我們也定義了padding token的id,并使用preprocess_data函式來對Cornell電影對話資料集進行預處理,在預處理程序中,我們將每個問題和回答組合在一起,使用tokenizer將文本轉換為tokens,并將tokens轉換為數字表示,我們還設定了padding和truncation等引數,以使得所有輸入序列長度相同,
3.訓練模型
在對資料集進行預處理后,我們可以使用Hugging Face的Transformers庫中提供的GPT2LMHeadModel類來構建ChatGPT模型,GPT2LMHeadModel是一個帶有語言模型頭的GPT-2模型,用于生成與前面輸入的文本相關的下一個詞,
以下是使用GPT2LMHeadModel訓練ChatGPT模型的代碼:
from transformers import GPT2LMHeadModel, Trainer, TrainingArguments model = GPT2LMHeadModel.from_pretrained('distilgpt2') model.resize_token_embeddings(len(tokenizer)) training_args = TrainingArguments( output_dir='./results', num_train_epochs=3, per_device_train_batch_size=4, save_total_limit=2, save_steps=1000, logging_steps=500, evaluation_strategy='steps', eval_steps=1000, load_best_model_at_end=True, ) trainer = Trainer( model=model, args=training_args, train_dataset=inputs['input_ids'], data_collator=lambda data: {'input_ids': torch.stack(data)}, ) trainer.train()
在上述代碼中,我們首先使用GPT2LMHeadModel來初始化ChatGPT模型,并調整Embedding層的大小以適應我們的tokenizer,接下來,我們定義了TrainingArguments來配置訓練引數,其中包括了訓練的輪數、每批次的大小、模型保存路徑等資訊,最后,我們使用Trainer類來訓練模型,在這里,我們將輸入資料傳遞給train_dataset引數,并使用一個data_collator函式將輸入資料打包成一個批次,
4.生成文本
在訓練完成后,我們可以使用ChatGPT模型來生成文本,在Hugging Face的Transformers庫中,我們可以使用pipeline來實作文本生成,
以下是使用ChatGPT模型生成文本的代碼:
from transformers import pipeline generator = pipeline('text-generation', model=model, tokenizer=tokenizer) def generate_text(prompt): outputs = generator(prompt, max_length=1024, do_sample=True, temperature=0.7) generated_text = outputs[0]['generated_text'] return generated_text generated_text = generate_text('Hello, how are you?') print(generated_text)
在上述代碼中,我們首先使用pipeline函式來初始化一個文本生成器,其中指定了ChatGPT模型和tokenizer,接下來,我們定義了generate_text函式來使用生成器生成文本,在這里,我們傳入一個prompt字串作為生成的起始點,并使用max_length引數來指定生成文本的最大長度,使用do_sample和temperature引數來控制文本的隨機性和流暢度,
5.總結
ChatGPT是一個強大的自然語言生成模型,可以用于生成對話、推薦、文本摘要等多種任務,在本文中,我們介紹了ChatGPT的原理、實作流程和應用場景,并提供了Cornell電影對話資料集的預處理和ChatGPT模型的訓練代碼,通過使用Hugging Face的Transformers庫,我們可以輕松地構建和訓練ChatGPT模型,并使用pipeline來生成文本,希望本文能夠幫助讀者更好地理解ChatGPT,以及如何應用自然語言生成技術來解決實際問題,
因為,GPT3 API里面單次互動最多支持4000多個token(https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them)

因此,我猜測ChatGPT的背景關系大概也是4000個token左右,
聯系方式:郵箱:[email protected]
Twitter:https://twitter.com/smartloli
QQ群(Hadoop - 交流社區1):424769183
QQ群(Kafka并不難學): 825943084
溫馨提示:請大家加群的時候寫上加群理由(姓名+公司/學校),方便管理員審核,謝謝!
熱愛生活,享受編程,與君共勉!
公眾號:

作者:哥不是小蘿莉 [關于我][犒賞]
出處:http://www.cnblogs.com/smartloli/
轉載請注明出處,謝謝合作!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/551526.html
標籤:其他
上一篇:AtCoder Beginner Contest 300
下一篇:返回列表