目錄
- [Daimayuan] T1 倒數第n個字串(C++,進制)
- 輸入格式
- 輸出格式
- 樣例輸入
- 樣例輸出
- 解題思路
- [Daimayuan] T2 排隊(C++,并查集)
- 輸入格式
- 輸出格式
- 樣例輸入1
- 樣例輸出1
- 樣例輸入2
- 樣例輸出2
- 樣例輸入3
- 樣例輸出3
- 資料規模
- 解題思路
- [Daimayuan] T3 素數之歡(C++,BFS)
- 資料規模
- 輸入格式
- 輸出格式
- 樣例輸入
- 樣例輸出
- 說明
- 解題思路
- [Daimayuan] T4 國家鐵路(C++,數學,動態規劃)
- 題目描述
- 題目輸入
- 題目輸出
- 樣例輸入1
- 樣例輸出1
- 樣例輸入2
- 樣例輸出2
- 解題思路
- [Daimayuan] T5 吃糖果(C++,貪心)
- 輸入格式
- 輸出格式
- 資料范圍
- 輸入樣例
- 輸出樣例
- 解題思路
- [Daimayuan] T6 切割(C++,貪心,哈夫曼樹)
- 題目描述
- 輸入格式
- 輸出格式
- 樣例輸入
- 樣例輸出
- 資料范圍
- 附加說明
- 解題思路
- [Daimayuan] T7 異或和(C++,異或,數學)
- 輸入格式
- 輸出格式
- 樣例輸入
- 樣例輸出
- 資料規模
- 解題思路
- [Daimayuan] T8 分數拆分(C++,數學)
- 輸入格式
- 輸出格式
- 樣例輸入
- 樣例輸出
- 解題思路
- [Daimayuan] T9 簡單子段和(C++,前綴和)
- 輸入格式
- 輸出格式
- 樣例輸入1
- 樣例輸出1
- 樣例輸入2
- 樣例輸出2
- 資料規模
- 解題思路
- [Daimayuan] T10 Good Permutations(C++,數學)
- 輸入描述
- 輸出描述
- 樣例輸入
- 樣例輸出
- 解題思路
[Daimayuan] T1 倒數第n個字串(C++,進制)
給定一個完全由小寫英文字母組成的字串等差遞增序列,該序列中的每個字串的長度固定為 \(L\),從 \(L\) 個 \(a\) 開始,以 \(1\) 為步長遞增,例如當 \(L\) 為 \(3\) 時,序列為 \(aaa,aab,aac,...,aaz,aba,abb,...,abz,...,zzz\),這個序列的倒數第 \(2\) 個字串就是 \(zzy\),對于任意給定的 \(L\),本題要求你給出對應序列倒數第 \(N\) 個字串,
輸入格式
輸入在一行中給出兩個正整數 \(L\) (\(1≤L≤6\))和 \(N\)( \(N≤10^5\)).
注意:資料范圍有修改!!!
輸出格式
在一行中輸出對應序列倒數第 \(N\) 個字串,題目保證這個字串是存在的,
樣例輸入
6 789
樣例輸出
zzzyvr
解題思路
把字串看作\(26\)進制:
0->a
1->b
2->c
...
25->z
然后把我們進制轉換的輾轉相除法拿出來:
int idx = len - 1;
while (num) {
arr[idx--] = -(num % 26);
num /= 26;
}
最后用zzz...z減去我們求得的\(26\)進制串即可,
AC代碼如下:
#include <iostream>
using namespace std;
const int max_len = 10;
const int max_num = 1e5;
int arr[max_len];
int main() {
int len, num;
cin >> len >> num;
num--;
int idx = len - 1;
while (num) {
arr[idx--] = -(num % 26);
num /= 26;
}
for (int i = 0; i < len; i++) {
printf("%c", char(arr[i] + 122));
}
return 0;
}
[Daimayuan] T2 排隊(C++,并查集)
請判斷有沒有一種方法可以將編號從 \(1\) 到 \(N\) 的 \(N\) 個人排成一排,并且滿足給定的 \(M\) 個要求,
對于每個要求會給出兩個整數 \(A_i\) 和 \(B_i\),表示編號 \(A_i\) 和 \(B_i\) 的人是相鄰的,
保證每個要求都不同,比如已經給出了 \(1,5\),就不會再給出 \(1,5\) 或 \(5,1\),
輸入格式
第一行兩個整數 \(N\) 和 \(M\),表示 \(N\) 個人和 \(M\) 個要求,
輸出格式
如果有一種能把這些人拍成一排并滿足所有條件的方法,就輸出 Yes,否則,輸出 No,
樣例輸入1
4 2
1 3
2 3
樣例輸出1
Yes
樣例輸入2
4 3
1 4
2 4
3 4
樣例輸出2
No
樣例輸入3
3 3
1 2
1 3
2 3
樣例輸出3
No
資料規模
對于全部資料保證 \(2≤N≤10^5\),\(0≤M≤10^5\),\(1≤A_i<B_i≤N\),
解題思路
本題是一道邏輯推理題,
我們推理的基礎就是:一個人最多與兩個人相鄰,
根據這個定理,我們可以得出以下規律:
(1)在\(M\)個要求中,一個人最多出現兩次;
(2)因為是佇列不是環,隊首和隊尾不可能相鄰,
條件\(1\)很容易就能用陣列維護;
條件\(2\)采用并查集維護(常用于強連通分量),思路是任意兩個元素只會被合并一次,所以當嘗試合并在同一個集合中的元素時,判斷不合理,最后,AC代碼如下:
#include <iostream>
#include <vector>
using namespace std;
const int max_len = 1e5;
int fa[max_len + 1], sum[max_len + 1];
int find(int x) {
return x == fa[x] ? x : (fa[x] = find(fa[x]));
}
bool is_insame(int x, int y) {
x = find(x); y = find(y);
return x == y;
}
void merge(int x, int y) {
x = find(x); y = find(y);
fa[x] = y;
}
int main() {
int n, m, x, y, flag = 0;
cin >> n >> m;
for (int i = 1; i <= n; i++) fa[i] = i;//并查集初始化
for (int i = 0; i < m; i++) {
cin >> x >> y;
if (!flag) {
if (sum[x] < 2 && sum[y] < 2) {//一個人最多與兩個人相鄰
if (is_insame(x, y)) {//成環
flag = 1;
}
else {
merge(x, y);
sum[x]++; sum[y]++;
}
}
else flag = 1;
}
}
if (flag) cout << "No" << endl;
else cout << "Yes" << endl;
return 0;
}
[Daimayuan] T3 素數之歡(C++,BFS)
現給定兩個 四位素數 \(a,b\), 你可以執行多次下面的操作:
修改數字 \(a\) 的某一位, 使其成為另一個 四位素數,
例如,\(1033→1733\),其中 \(1033\) 與 \(1733\) 均為素數,
問至少多少次變換后能從 \(a\) 得到 \(b\) ? 或回答不可能,
資料規模
- 多組資料 \(1≤T≤100\)
輸入格式
第一行一個數字 \(T\),表示接下來將會有 \(T\) 組資料,
接下來包含 \(T\) 行,每行包含用空格分開的兩個 四位素數 \(a,b\),
輸出格式
輸出 \(T\) 行,如果可以,輸出最小變換次數,反之輸出 \(?1\),
樣例輸入
2
1033 1033
1033 8779
樣例輸出
0
5
說明
\(1033→1733→3733→3739→3779→8779\)
tips: you only operate \(8\) times if possible.
解題思路
找出規律困難,資料規模不大,于是考慮暴力搜索,
每次對四位數都嘗試一次變換,每位數有九種變換的可能,那么每輪的操作次數就是\(9^4=6561\)
對于每組測驗資料,提示說明我們最多會進行\(8\)次嘗試,所以每組測驗資料的最多操作次數為\(6561*8=52488\)
最多有\(100\)組測驗資料,所以最多累加操作次數為\(5248800≈5*10^6\)
時間復雜度可以接受,爆搜開始,
采用廣度優先搜索還是深度優先搜索?,
深度優先搜索與廣度優先搜索不同在于:
深度優先搜索會嘗試每一種可能的解決方法;
廣度優先搜索保證搜索到的解決方法中每一步都是最少步驟,
顯然廣度優先搜索更適合本題的爆搜,
然后是代碼實作:
(1)常規的\(BFS\)演算法:
bool vis[max_n]; //訪問標記物
queue<pair<int, int>>q; //前者為數字,后者為操作次數
//佇列初始化
q.push({ num1,0 });
vis[num1] = true;
while (!q.empty()) {
//取出隊首
q.front();
q.pop();
//BFS主體
for (/* 對每一位進行嘗試 */) {
for (/* 變換9種數字 */) {
int temp;
if (temp == num2) { //結束條件
break;
}
else (!vis[temp] && prime.count(temp)){ //繼續搜索
q.push({ temp, step + 1 });
vis[temp] = true;
}
}
}
}
保證每一步都是最小步驟數,
(2)素數判斷:
注意到這里有一個prime集合用于素數判斷,這里提供兩種方法制作素數集合:
常規方法:
void PrimeList(int n) {
for (int i = 2; i <= n; i++) {
bool flag = true;
for (int j = 2; j * j <= i; j++) {
if (i % j == 0) {
flag = false;
break;
}
}
if (flag) prime.insert(i);
}
}
歐拉篩(歐拉篩傳送門):
void PrimeList(int* Prime, bool* isPrime, int n) {
/* 歐拉篩 */
int i = 0, j = 0, count = 0;
memset(isPrime, true, sizeof(bool) * (n + 1));
isPrime[0] = isPrime[1] = false;
for (i = 2; i <= n; i++) {
if (isPrime[i]) {
Prime[count++] = i;
prime.insert(i);
}
for (j = 0; j < count && Prime[j] * i <= n; j++) {
isPrime[i * Prime[j]] = false;
//歐拉篩核心,每一個合數都能拆成最小因數與最大因數的乘積
if (i % Prime[j] == 0) break;
}
}
}
最后,AC代碼如下
#include <iostream>
#include <string.h>
#include <queue>
#include <set>
using namespace std;
const int max_t = 100;
const int max_epoch = 8;
const int max_n = 10000;
bool isPrime[max_n], vis[max_n];
int Prime[max_n];
set<int>prime;
void PrimeList(int* Prime, bool* isPrime, int n) {
/* 歐拉篩 */
int i = 0, j = 0, count = 0;
memset(isPrime, true, sizeof(bool) * (n + 1));
isPrime[0] = isPrime[1] = false;
for (i = 2; i <= n; i++) {
if (isPrime[i]) {
Prime[count++] = i;
prime.insert(i);
}
for (j = 0; j < count && Prime[j] * i <= n; j++) {
isPrime[i * Prime[j]] = false;
//歐拉篩核心,每一個合數都能拆成最小因數與最大因數的乘積
if (i % Prime[j] == 0) break;
}
}
}
//void PrimeList(int n) {
// for (int i = 2; i <= n; i++) {
// bool flag = true;
// for (int j = 2; j * j <= i; j++) {
// if (i % j == 0) {
// flag = false;
// break;
// }
// }
// if (flag) prime.insert(i);
// }
//}
int main() {
PrimeList(Prime, isPrime, max_n);
//PrimeList(max_n);
int t, num1, num2;
cin >> t;
while (t--) {
cin >> num1 >> num2;
if (num1 == num2) {//特判
cout << 0 << endl;
continue;
}
queue<pair<int, int>>q; //初始化佇列
memset(vis, false, sizeof(bool) * (max_n));
vis[num1] = true;
q.push({ num1,0 });
bool flag = true; //初始化標記物
int ans = -1;
while (flag && !q.empty()) {
int num3 = q.front().first, step = q.front().second;
q.pop();
for (int i = 1; flag && i <= 1000; i *= 10) {//對每一位進行嘗試
int num4 = num3 / i / 10 * 10 * i + num3 % i;
for (int j = 0; flag && j < 10; j++) {//變換9種數字
int num5 = num4 + j * i;
if (num5 == num2) {//找到數字
flag = false;
ans = step + 1;
break;
}
if (!vis[num5] && prime.count(num5)) {//未找到,但是為質數
q.push({ num5,step + 1 });
vis[num5] = true;
}
}
}
}
cout << ans << endl;
}
return 0;
}
[Daimayuan] T4 國家鐵路(C++,數學,動態規劃)
題目描述
\(dls\)的算競王國可以被表示為一個有 \(H\)行和 \(W\)列的網格,我們讓 \((i,j)\)表示從北邊第\(i\)行和從西邊第\(j\)列的網格,最近此王國的公民希望國王能夠修建一條鐵路,
鐵路的修建分為兩個階段:
- 從所有網格中挑選\(2\)個不同的網格,在這兩個網格上分別修建一個火車站,在一個網路上修建一個火車站的代價是\(A_{i,j}\),
- 在這兩個網格間修建一條鐵軌,假設我們選擇的網格是 \((x_1,y_1)\)和\((x_2,y_2)\),其代價是 \(C×(|x_1?x_2|+|y_1?y_2|)\),
\(dls\)的愿望是希望用最少的花費去修建一條鐵路造福公民們,現在請你求出這個最小花費,
題目輸入
第一行輸入三個整數分別代表\(H,W,C(2≤H,W≤1000,1≤C≤10^9)\),
接下來\(H\)行,每行\(W\)個整數,代表\(A_{i,j}(1≤A_{i,j}≤10^9)\),
題目輸出
輸出一個整數代表最小花費,
樣例輸入1
3 4 2
1 7 7 9
9 6 3 7
7 8 6 4
樣例輸出1
10
樣例輸入2
3 3 1000000000
1000000 1000000 1
1000000 1000000 1000000
1 1000000 1000000
樣例輸出2
1001000001
解題思路
這道題有億點點難QAQ,
直接列舉的時間復雜度為\(o(n^4)\),直接\(T\)飛,所以我們需要想辦法優化,
題中給出,修建一條鐵軌的總花費為\(A_{x_1,y_1}+A_{x_2,y_2}+C*(|x_1-x_2|+|y_1-y_2|)\),
顯然,交換一下\((x_1,y_1)\)和\((x_2,y_2)\)的坐標對花費沒有任何影響,
所以,為了方便計算,我們規定情況\(1\)為\(x_1\ge x_2,y_1\ge y_2\),情況\(2\)為\(x_1\ge x_2,y_1\le y_2\),
直觀的來說,以上兩種情況分別為矩陣的主對角線方向和副對角線方向,
只需要討論一種情況的演算法,另外一種情況則不證自明:
對于情況\(1\),總花費可以寫為:
\[\begin{aligned} cost\_sum & = A_{x_1,y_1}+A_{x_2,y_2}+C*(x_1-x_2+y_1-y_2) \\ & = A_{x_1,y_1}+C*(x_1+y_1)+A_{x_2,y_2}-C*(x_2+y_2) \end{aligned} \]在公式的形式簡化之后,再去考慮尋找最小值的問題:
我們發現對于給定的\((x_1,y_1)\),我們需要列舉所有符合條件的\((x_2,y_2)\)(條件為\(x_1\ge x_2,y_1\ge y_2\),在一個小矩陣中),并找出最小值,
但與之前不同,我們現在可以對\((x_2,y_2)\)進行動態規劃,然后就可以在\(O(1)\)時間內獲取對于給定\((x_1,y_1)\)的最小值,
規劃公式為dp[i][j] = min{ dp[i][j-1], dp[i-1][j], station[i][j] - C * (i + j)}?,
for (int i = 1; i <= h; i++) {
for (int j = 1; j <= w; j++) {
dp[i][j] = min(dp[i][j - 1], min(dp[i - 1][j], station[i][j] - C * (i + j)));
}
}
那么計算主對角線情況下的最小值,只需要列舉另外一個點:
for (int i = 1; i <= h; i++) {
for (int j = 1; j <= w; j++) {
ans = min(ans, min(dp[i - 1][j] + dp[i][j - 1]) + station[i][j] + C * (i + j));
}
}
最后簡單給出計算副對角線情況下最小值的代碼以及AC代碼:
副對角線演算法:
for (int i = 1; i <= h; i++) {
for (int j = w; j >= 1; j--) {
dp[i][j] = min(dp[i][j + 1], min(dp[i - 1][j], station[i][j] + C * (j - i)));
}
}
for (int i = 1; i <= h; i++) {
for (int j = 1; j <= w; j++) {
ans = min(ans, min(dp[i - 1][j], dp[i][j + 1]) + station[i][j] + C * (i - j));
}
}
AC代碼:
#include <iostream>
#include <string.h>
using namespace std;
const long long max_h = 1000;
const long long max_w = 1000;
const long long NaN = 0x3F3F3F3F3F3F3F3F;
const long long max_c = 1e9;
long long station[max_h + 2][max_w + 2], dp1[max_h + 2][max_w + 2], dp2[max_h + 2][max_w + 2]; //多開一圈,防止越界
long long h, w, C;
int main() {
cin >> h >> w >> C;
for (int i = 1; i <= h; i++) {
for (int j = 1; j <= w; j++) {
cin >> station[i][j];
}
}
//DP1(主對角線)
memset(dp1, 0x3F, sizeof(long long) * (max_h + 2) * (max_w + 2));
for (int i = 1; i <= h; i++) {
for (int j = 1; j <= w; j++) {
dp1[i][j] = min(dp1[i - 1][j], min(dp1[i][j - 1], station[i][j] - C * (i + j)));
}
}
//DP2(副對角線)
memset(dp2, 0x3F, sizeof(long long) * (max_h + 2) * (max_w + 2));
for (int i = 1; i <= h; i++) {
for (int j = w; j >= 1; j--) {
dp2[i][j] = min(dp2[i][j + 1], min(dp2[i - 1][j], station[i][j] + C * (j - i)));
}
}
long long ans = NaN;
//ans1(主對角線)
for (int i = 1; i <= h; i++) {
for (int j = 1; j <= w; j++) {
ans = min(ans, min(dp1[i - 1][j], dp1[i][j - 1]) + station[i][j] + C * (i + j));
}
}
//ans2(副對角線)
for (int i = 1; i <= h; i++) {
for (int j = 1; j <= w; j++) {
ans = min(ans, min(dp2[i - 1][j], dp2[i][j + 1]) + station[i][j] + C * (i - j));
}
}
cout << ans << endl;
return 0;
}
[Daimayuan] T5 吃糖果(C++,貪心)
桌子上從左到右放著 \(n\) 個糖果,糖果從左到右編號,第 \(i\) 塊糖果的重量為 \(w_i\),小明和小紅要吃糖果,
小明從左邊開始吃任意數量的糖果,(連續吃,不能跳過糖果)
小紅從右邊開始吃任意數量的糖果,(連續吃,不能跳過糖果)
當然,如果小明吃了某個糖果,小紅就不能吃它(反之亦然),
他們的目標是吃同樣重量的糖果,請問此時他們總共最多能吃多少個糖果?
輸入格式
第一行包含一個整數 \(n\),表示桌上糖果的數量,
第二行包含 \(n\) 個整數 \(w_1,w_2,…,w_n\),表示糖果從左到右的重量,
輸出格式
一個整數,表示小明和小紅在滿足條件的情況下總共可以吃的糖果的最大數量,
資料范圍
\(1≤n≤2*10^5,1≤w_i≤10^4\)
輸入樣例
9
7 3 20 5 15 1 11 8 10
輸出樣例
7
解題思路
采用貪心演算法(不斷嘗試吃更多的糖)解決此題:
初始化規定糖的重量相等,然后回圈分支:
(1)糖的重量相等,記錄當前總共吃了多少顆糖,雙方再吃一顆糖;
(2)糖的重量不相等,吃的少的一方再吃一顆糖,
結束條件:雙方吃糖發生沖突(題目規定:“如果小明吃了某個糖果,小紅就不能吃它(反之亦然)”),
AC代碼如下:
#include <iostream>
using namespace std;
const int max_n = 2e5;
const int max_w = 1e4;
int candies[max_n];
int main() {
int n;
cin >> n;
for (int i = 0; i < n; i++) cin >> candies[i];
int l = 0, r = n - 1, l_sum = 0, r_sum = 0, ans = 0;
while (l < r) {
if (l_sum == r_sum) {
ans = l - 0 + n - 1 - r;
l_sum += candies[l++];
r_sum += candies[r--];
}
else if (l_sum < r_sum) l_sum += candies[l++];
else r_sum += candies[r--];
}
cout << ans << endl;
return 0;
}
貪心證明:
初始化,規定雙方吃糖量相同,吃糖數目為\(0\),
為了確定是否存在比\(0\)大的解,我們必須要讓其中一方吃一顆糖,
那么這就會導致雙方吃糖量不等,要讓其相等,我們必須讓另一方吃一顆糖,
只要不平衡,我們就需要讓吃的少的那一方繼續吃,
當平衡的時候,設吃糖數目為\(ans\),
為了確定是否存在比\(ans\)大的解,我們必須要讓其中一方吃一顆糖...(依次類推,直到發生沖突)
[Daimayuan] T6 切割(C++,貪心,哈夫曼樹)
題目描述
有一個長度為 \(\sum a_i\) 的木板,需要切割成 \(n\) 段,每段木板的長度分別為 \(a_1,a_2,…,a_n\),
每次切割,會產生大小為被切割木板長度的開銷,
請你求出將此木板切割成如上 \(n\) 段的最小開銷,
輸入格式
第 \(1\) 行一個正整數表示 \(n\),
第 \(2\) 行包含 \(n\) 個正整數,即 \(a_1,a_2,…,a_n\),
輸出格式
輸出一個正整數,表示最小開銷,
樣例輸入
5
5 3 4 4 4
樣例輸出
47
資料范圍
對于全部測驗資料,滿足 \(1≤n,a_i≤10^5\),
附加說明
原題:[NOIP2004 提高組] 合并果子 / [USACO06NOV] Fence Repair G
需要 O(n) 解法的 資料加強版(\(1≤n≤10^7\))
解題思路
首先我們采用逆向思維,改變題意為:
把\(n\)塊長度分別為 \(a_1,a_2,…,a_n\)的木板合并成一塊,每次合并只能操作兩塊,會產生合并后木板長度的開銷,
可以很容易發現這和題意描述是一樣的,
然后引入核心思路:哈夫曼樹,
哈夫曼樹常用于資料壓縮(本質上是編碼方式),基本思想就是:
統計文本中的所有符號的詞頻,每次選擇詞頻最低的兩個進行操作,將它們連到一個新的父節點上,然后將父節點賦值為二者詞頻之和,直到生成一棵樹,
這種方式能夠保證詞頻越小的節點深度越深(編碼長度越長),詞頻越高的節點深度越淺(編碼長度越短),也就完成了資料壓縮,
那么這和本題有什么關系?
我們可以認為哈夫曼樹中的葉子節點就是\(n\)塊木板,節點深度就是木板被操作的次數,
(注:我們可以把合并后的木板仍然看成是多塊木板,只不過這幾塊木板可以一起操作,)
所以,深度越深也就代表著這塊木板被操作的次數越多,深度越淺也就代表著這塊木板被操作的次數越少,
故哈夫曼樹演算法能夠保證最小開銷,
代碼實作:
采用優先佇列維護木板,每次取出兩塊進行合并,然后將合并后的木板插入佇列,
AC代碼如下:
(前排提示:/* 十年OI一場空,不開long long見祖宗 */)
#include <iostream>
#include <queue>
using namespace std;
const int max_n = 1e5;
const int max_a = 1e5;
priority_queue<long long, vector<long long>, greater<long long>>pq;
int main() {
long long n, temp;
cin >> n;
for (int i = 0; i < n; i++) {
cin >> temp;
pq.push(temp);
}
long long ans = 0;
while (pq.size() > 1) {
long long b1 = pq.top(); pq.pop();
long long b2 = pq.top(); pq.pop();
pq.push(b1 + b2);
ans += (long long)(b1) + (long long)(b2);
}
cout << ans << endl;
return 0;
}
后排推一下我寫的合并果子\(qwq\)
然后是資料加強版合并果子:
貪心演算法是不能優化的了,可以優化的地方在于優先佇列,
因為我們每次將合并后的果堆插入佇列中,佇列都會運行排序演算法找到應該插入的位置,
優化的前提是這樣的:
每次合并后的果堆一定不會比上一次合并得到的果堆小,
那么我們就不需要將其插入優先佇列,只需要另外維護一個佇列用來存盤合并后的果堆,然后每次取出兩個佇列中隊首比較小的一個即可,
直觀的思路是這樣的:
首先采用比快速排序更快的排序演算法桶排序,將果堆維護在一個有序佇列中;
然后再維護一個佇列用于存盤合并后的果堆;
最后運行的貪心演算法與之前一致,
AC代碼如下:
#include <iostream>
#include <queue>
#include <cstdio>
#include <cstdlib>
using namespace std;
const int max_a = 1e5;
queue<long long>q1, q2;
int buckets[max_a + 1];
int main() {
int n, temp;
scanf("%d", &n);
for (int i = 0; i < n; i++) {
scanf("%d", &temp);
buckets[temp]++;
}
for (int i = 1; i <= max_a; i++) {
while (buckets[i]--) {
q1.push((long long)(i));
}
}
long long t1, t2, ans = 0;
for (int i = 1; i < n; i++) {
if (q2.empty() || !q1.empty() && q1.front() < q2.front()) {
t1 = q1.front();
q1.pop();
}
else {
t1 = q2.front();
q2.pop();
}
if (q2.empty() || !q1.empty() && q1.front() < q2.front()) {
t2 = q1.front();
q1.pop();
}
else {
t2 = q2.front();
q2.pop();
}
q2.push(t1 + t2);
ans += t1 + t2;
}
cout << ans << endl;
return 0;
}
其實這段代碼還會\(T\),怎么優化?當然是用無敵的快讀了:
void read(int& x) {
x = 0;
char c = getchar();
while ('0' <= c && c <= '9') {
x = x * 10 + c - '0';
c = getchar();
}
}
[Daimayuan] T7 異或和(C++,異或,數學)
給定一個長度為 \(n\) 的陣列 \(a_1,a_2,...,a_n\), 請你求出下面式子的模\(1e9+7\)的值,
\(\sum_{i=1}^{n-1}{\sum_{j=i+1}^{n}{(a_i\ XOR\ a_j)}}\)
輸入格式
第一行一個數字 \(n\),
接下來一行 \(n\) 個整數 \(a_1,a_2,…,a_n\),
輸出格式
一行一個整數表示答案,
樣例輸入
3
1 2 3
樣例輸出
6
資料規模
所有資料保證 \(2≤n≤300000,0≤a_i<2^{60}\),
解題思路
依照題意,我們只能直接跑二重回圈(因為\(a_i\)和\(a_j\)的組合不會重復,也就是說沒有子結構的概念),這肯定會\(TLE\),
那么我們考慮異或操作的性質:
異或操作是位操作,無視整個位串的意義,只能看到單個位,——條件(1)
然后重新審視\(\sum_{i=1}^{n-1}{\sum_{j=i+1}^{n}{(a_i\ XOR\ a_j)}}\),
這個式子就是對任意兩個元素進行異或操作然后做和,也就是說嘗試了所有的組合(\(C_n^2\)),——條件(2)
再來看一下異或操作的性質:同則為假,不同為真,——條件(3)
如何利用三個條件優化演算法?這里通過一個簡單的例子來理解:
有位串\(1000 0111\),我們對任意兩個位進行異或操作,然后做和,很容易發現,其和為\(4*4=16\),就是\(1\)的數量乘上\(0\)的數量,
然后我們回去看一眼題中的例子:
1 2 3
1 1 0 1 -> 2 * 1 = 2
2 0 1 1 -> 2 * 2 = 4
4 0 0 0 -> 0 * 4 = 0
比起之前那個簡單的例子,也就是多了個權重,僅此而已,
接下來簡單說一下代碼如何實作:
我們維護每一個位上\(1\)(也可以是\(0\))出現的次數;
然后遍歷每一個位,累計:\(0\)的數量\(*1\)的數量\(*\)權重,
AC代碼如下:
#include <iostream>
using namespace std;
const int max_len = 60;
const long long max_a = (1LL << 60LL) - 1LL;
const int max_n = 300000;
const long long mod_num = 1e9 + 7;
long long sum[max_len];
inline void read() {
long long x, idx = 0;
cin >> x;
while (x) {
sum[idx++] += x & 1;
x >>= 1;
}
}
int main() {
int n;
cin >> n;
for (int i = 0; i < n; i++) read();
long long ans = 0;
for (int i = 0; i < max_len; i++) {
long long power = (1LL << (long long)(i)) % mod_num;
long long comb = sum[i] * (n - sum[i]) % mod_num;
ans = (ans + (power * comb) % mod_num) % mod_num;
}
cout << ans << endl;
return 0;
}
[Daimayuan] T8 分數拆分(C++,數學)
輸入正整數 \(k\),找到所有的正整數 \(y≤x\), 使得 \(\frac1k=\frac1x+\frac1y\),
輸入格式
輸入一個正整數 \(k(1≤k≤10^7)\),
輸出格式
輸出一個數,表示滿足條件的\(x,y\)的個數,
樣例輸入
12
樣例輸出
8
解題思路
題目要求很好理解:找出的\(x,y\)使得\(k=\frac{xy}{(x+y)}\),
那么如何找出這樣的\(x,y\)?或者說,如何找到\(x,y\)中的一個?
我們進一步把公式變換為\(y=\frac{kx}{x-k}\)(其中\(k < x \le y\)),
但是仍然不好求解,
那么進一步研究公式的形式,有\(x=k+b(b>0)\),那么有:
\(y=\frac{k^2+bk}{b}\)
于是有\(k^2\ mod\ b =0\)和\(bk\ mod\ b=0\),
根據前者,我們可以知道\(b\)是\(k^2\)的因子,第二個條件是顯然成立的,
再考慮\(x\le y\)這個條件,根據題意有\(x\le 2k\),則有\(b\le k\),
那么求解就變得容易了,我們列舉因子即可,時間復雜度為\(o(k)\),
最后,AC代碼如下:
#include <iostream>
using namespace std;
long long max_k = 1e7;
int main() {
long long k, x, y, ans = 0;
cin >> k;
long long temp = k * k;
for (long long i = 1; i <= k; i++) {
if (temp % i == 0) {
ans++;
}
}
cout << ans << endl;
return 0;
}
[Daimayuan] T9 簡單子段和(C++,前綴和)
給出一個長為 \(N\) 的整數陣列 \(A\) 和一個整數 \(K\),
請問有陣列 \(A\) 中有多少個子陣列,其元素之和為 \(K\)?
輸入格式
第一行兩個整數 \(N\) 和 \(K\),表示陣列 \(A\) 的大小,和給出的整數 \(K\),
第二行 \(N\) 個整數,表示陣列 \(A\) 中的每個元素 \(A_1,...,A_n\),
輸出格式
輸出一個整數,表示答案,
樣例輸入1
6 5
8 -3 5 7 0 -4
樣例輸出1
3
有三個子陣列 (\(A_1,A_2\)),(\(A_3\)),(\(A_2,...,A_6\))滿足條件,
樣例輸入2
2 -1000000000000000
1000000000 -1000000000
樣例輸出2
0
資料規模
對于全部資料保證 \(1≤N≤2×10^5\),\(|A_i|≤10^9\),\(|k|≤10^{15}\),
解題思路
直接列舉的時間復雜度是\(O(N^2)\),必然\(TLE\),所以考慮優化,
對于連續區間和問題,我們常常會使用前綴和,
前綴和很好理解,也很好實作,但是怎么應用到這道題中?
觀察這個式子:\(k=pre-(pre-k)\),(這不是廢話嘛)
\(pre\)和\(pre-k\)代表著兩個前綴和,
那么現在我們只需要遍歷每一個\(pre\),統計相應的\(pre-k\)數目即可,
這里采用在線做法實作:
(1)動態更新當前的前綴和;
(2)計算\(pre-k\)的數量;
(3)前綴和\(pre\)的數量++,
AC代碼如下:
#include <iostream>
#include <cstdlib>
#include <cstdio>
#include <map>
using namespace std;
const int max_n = 2e5;
const int max_a = 1e9;
const long long max_k = (long long)(1e10) * (long long)(1e5);
map<long long, int>m;
int main() {
long long n, k, temp, sum = 0, ans = 0;
m.insert({ 0LL,1 });
cin >> n >> k;
//scanf("%lld%lld", &n, &k);
for (int i = 1; i <= n; i++) {
cin >> temp;
//scanf("%lld", &temp);
sum += temp;
if (m.find(sum - k) != m.end())
ans += m[sum - k];
m[sum]++;
}
cout << ans << endl;
return 0;
}
[Daimayuan] T10 Good Permutations(C++,數學)
對于每一個長度為 \(n\) 的排列 \(a\),我們都可以按照下面的兩種方式將它建成一個圖:
1.對于每一個 \(1≤i≤n\),找到一個最大的 \(j\) 滿足 \(1≤j<i,a_j>a_i\),將 \(i\) 和 \(j\) 之間建一條無向邊
2.對于每一個 \(1≤i≤n\),找到一個最小的 \(j\) 滿足 \(i<j≤n,a_j>a_i\),將 \(i\) 和 \(j\) 之間建一條無向邊
注意:建立的邊是在對應的下標 \(i,j\) 之間建的邊
請問有多少種長度為 \(n\) 的排列 \(a\) 滿足,建出來的圖含環
排列的數量可能會非常大,請輸出它模上 \(10^9+7\) 后的值
輸入描述
第 \(1\) 行給出 \(1\) 個數 \(T(1≤T≤10^5)\),表示有 \(T\) 組測驗樣例
第 \(2\) 到 \(T+1\) 行每行給出一個數 \(n(3≤n≤10^6)\),表示排列的長度
輸出描述
輸出符合條件的排列的數量模上 \(10^9+7\) 后的值
樣例輸入
1
4
樣例輸出
16
解題思路
題意直觀理解:\(i\)與\(j\)建邊需要兩個條件
(1)\(a_i<a_j\);
(2)要求索引距離最近,
設函式\(f(x)=a_x\),觀察規律可以得到:只要函式存在極小值,那么就可以成環,
存在極小值的情況很多,正難則反,我們去求不可以成環的情況,也就是不存在極小值,
直觀來看,不存在極小值的\(f(x)\)大致是這樣的:
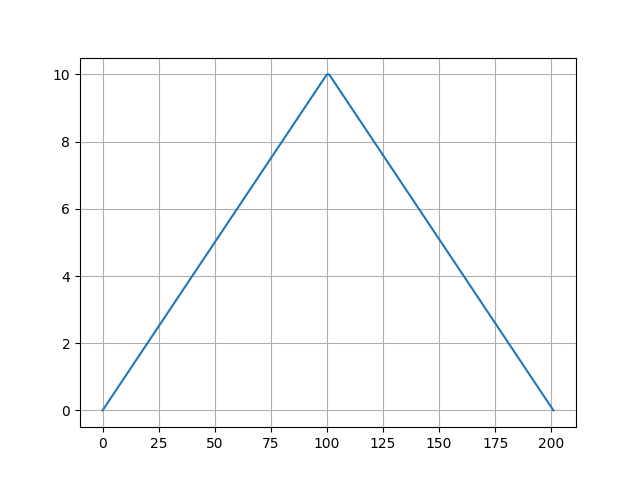
最大值點是固定的,我們只需要統計有多少種不同左右集合的組合:
\(C^0_{n-1}+C^1_{n-1}+...+C^{n-1}_{n-1}=2^{n-1}\)
所以計算公式為\(ans=n!-2^{n-1}\),
最后,AC代碼如下
#include <iostream>
using namespace std;
const long long mod_num = 1e9 + 7;
const long long max_n = 1e6;
long long factorial[max_n + 1], expo[max_n + 1];
void init() {
//階乘
factorial[0] = 1;
for (int i = 1; i <= max_n; i++) {
factorial[i] = (factorial[i - 1] * (long long)(i)) % mod_num;
}
//2的i次冪
expo[0] = 1;
for (int i = 1; i <= max_n; i++) {
expo[i] = (expo[i - 1] << 1LL) % mod_num;
}
}
long long solve(long long n) {
long long ret = (factorial[n] - expo[n - 1]) % mod_num;
if (ret < 0) ret += mod_num;
return ret;
}
int main() {
init();
long long T;
cin >> T;
while (T--) {
long long n;
cin >> n;
cout << solve(n) << endl;
}
return 0;
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/551624.html
標籤:其他
上一篇:基于MobileNet的人臉表情識別系統(MATLAB GUI版+原理詳解)
下一篇:返回列表