摘要:涂鴉線稿秒變絕美影像,ControlNet-Scribble2Img適配華為云ModelArts,提供更加便利和創新的影像生成體驗,將你的想象變為真實的影像,
本文分享自華為云社區《AIGC拯救手殘黨:涂鴉線稿秒變絕美影像》,作者:Emma_Liu ,
ControlNet
什么是ControlNet?簡而言之,文本到影像的生成涉及使用預訓練的擴散模型來生成基于某些文本的影像,
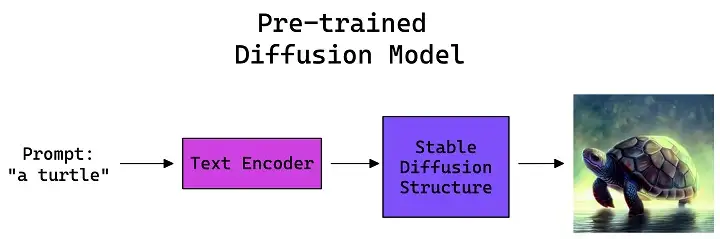
從輸入影像中提取特定資訊的程序稱為注釋(在paper中)或預處理(在 ControlNet extension中),
這個擴散模型是在數十億張圖片上預訓練的,當我們輸入文字時,模型會根據輸入的內容生成一張圖片,然而,有時輸出結果與我們的意圖并不完全一致,這就是ControlNet的作用…
ControlNet最早是在L.Zhang等人的論文《Adding Conditional Control to Text-to-Image Diffusion Model》中提出的,目的是提高預訓練的擴散模型的性能,特別是,在預訓練的擴散模型中加入另一個神經網路模型(ControlNet),使我們對輸出有更多的控制,
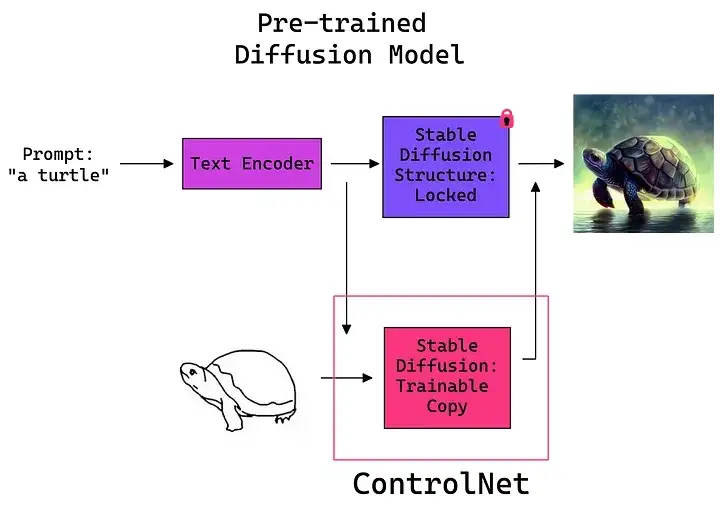
ControlNet 的作業原理是將可訓練的網路模塊附加到穩定擴散模型的U-Net (噪聲預測器)的各個部分,Stable Diffusion 模型的權重是鎖定的,在訓練程序中它們是不變的,在訓練期間僅修改附加模塊,
研究論文中的模型圖很好地總結了這一點,最初,附加網路模塊的權重全部為零,使新模型能夠利用經過訓練和鎖定的模型,
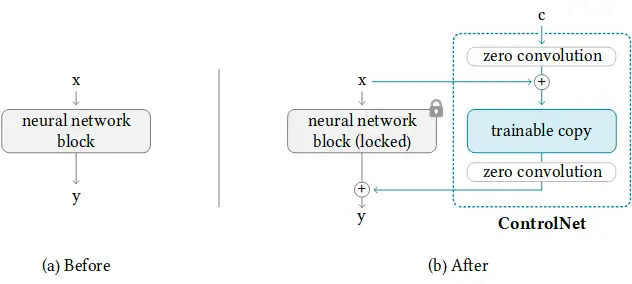
訓練 ControlNet 包括以下步驟:
- 克隆擴散模型的預訓練引數,如Stable Diffusion的潛在UNet,(稱為 “可訓練副本”),同時也單獨保留預訓練的引數(“鎖定副本”),這樣做是為了使鎖定的引數副本能夠保留從大型資料集中學習到的大量知識,而可訓練的副本則用于學習特定的任務方面,
- 引數的可訓練副本和鎖定副本通過 "零卷積 "層連接,該層作為ControlNet框架的一部分被優化,這是一個訓練技巧,在訓練新的條件時,保留凍結模型已經學會的語意,
從圖上看,訓練ControlNet是這樣的:
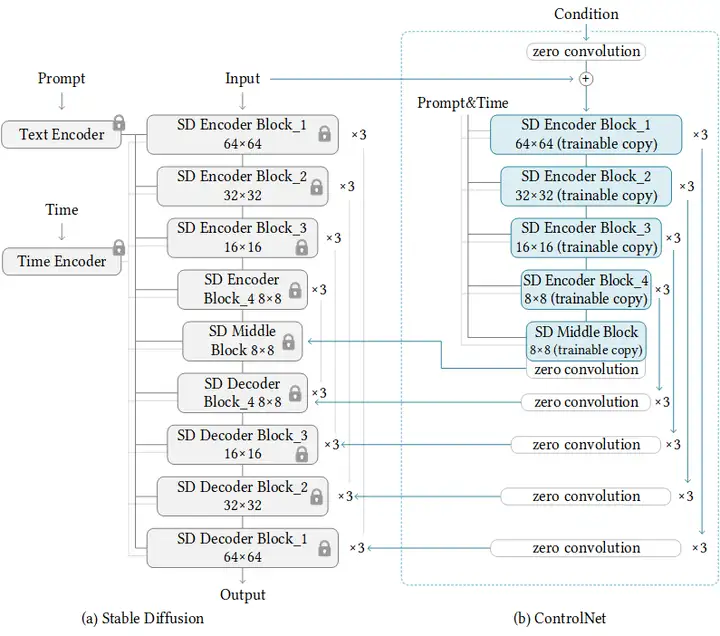
ControlNet提供了八個擴展,每個擴展都可以對擴散模型進行不同的控制,這些擴展是Canny, Depth, HED, M-LSD, Normal, Openpose, Scribble, and Semantic Segmentation.
ControlNet-Scribble2img
Scribble 用于預處理用戶繪制的涂鴉, 這個預處理程式不應該用在真實的影像上,由于它能夠根據簡單的草圖生成令人驚嘆、逼真或改進的影像,理想情況下,不需要任何提示,通過輸入一個基本的圖畫,模型可以推斷出細節和紋理,從而產生一個更高質量的影像,
下面是用ModelArts的Notebook適配Scribble2img生成的幾幅圖,一起來看看吧,
浮世繪風格的海浪 || 滿天繁星 || 小兔子和蘿卜

發光水母||一筐橙子||小花喵||微笑的太陽

嘗試用自己畫的素描生成,效果也不錯

接下來讓我們從零開始,在ModelArts上一起來體驗Scribble2img涂鴉生圖的樂趣吧,
涂鴉生成影像 ControlNet-Scribble2img
本文介紹如何在ModelArts來實作 ControlNet-Scribble2img 涂鴉生成影像,
AI Gallery - Notebook鏈接:拯救手殘黨:AI涂鴉一鍵成圖 (huaweicloud.com)
前言
ModelArts 是面向開發者的一站式 AI 開發平臺,為機器學習與深度學習提供海量資料預處理及互動式智能標注、大規模分布式訓練、自動化模型生成,及端-邊-云模型按需部署能力,幫助用戶快速創建和部署模型,管理全周期 AI 作業流,
前期準備
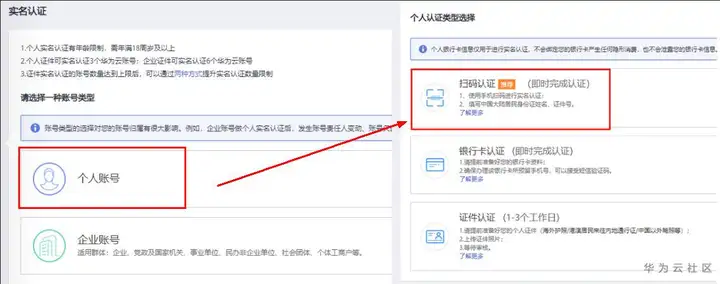
在使用ModelArts之前,需要進入華為云官網 https://www.huaweicloud.com/ ,然后注冊華為云賬號,再進行實名認證,主要分為3步(注冊–>實名認證–>服務授權)(如有已完成部分,請忽略)
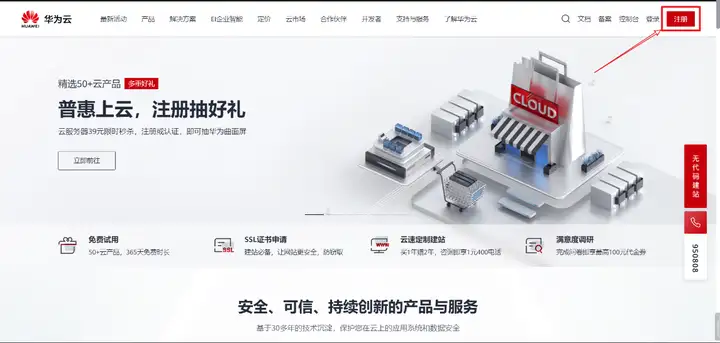
點去完成 實名認證,賬號型別選"個人",個人認證型別推薦使用"掃碼認證",
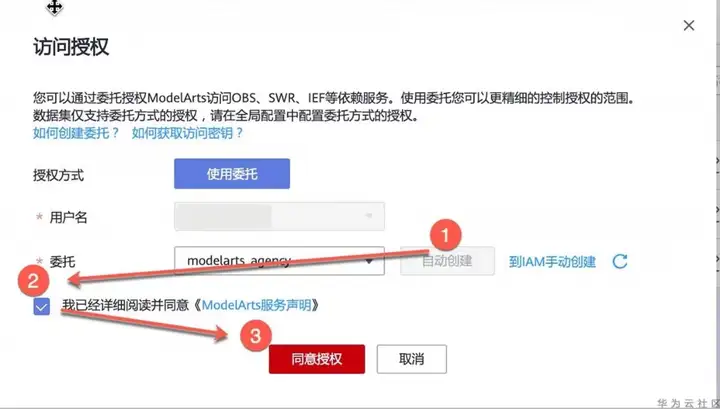
進入ModelArts 控制臺資料管理頁面,上方會提示訪問授權,點擊【服務授權】按鈕,按下圖順序操作:
注意事項
- 本案例需使用 Pytorch-1.8 GPU-P100 及以上規格運行;
- 點擊Run in ModelArts,將會進入到ModelArts CodeLab中,如果您沒有登錄需要進行登錄, 登錄之后,等待片刻,即可進入到CodeLab的運行環境;
- 出現 Out Of Memory ,請檢查是否為您的引數配置過高導致,修改引數配置,重啟kernel或更換更高規格資源進行規避;
- 運行代碼方法:點擊本頁面頂部選單欄的三角運行按鈕或按Ctrl+Enter或cell左側三角按鈕運行每個方塊中的代碼;
- 如果您是第一次使用 JupyterLab,請查看《ModelArts JupyterLab使用指導》了解使用方法;
- 如果您在使用 JupyterLab 程序中碰到報錯,請參考《ModelArts JupyterLab常見問題解決辦法》嘗試解決問題,
1.環境設定
check GPU & 拷貝代碼及資料
為了更快的準備資料和模型,將其轉存在了華為云OBS中,方便大家使用,
!nvidia-smi import os import moxing as mox parent = "/home/ma-user/work/ControlNet" bfp = "/home/ma-user/work/ControlNet/openai/clip-vit-large-patch14/pytorch_model.bin" sfp = "/home/ma-user/work/ControlNet/models/control_sd15_scribble.pth" if not os.path.exists(parent): mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/case_zoo/scribble2img/ControlNet',parent) if os.path.exists(parent): print('Download success') else: raise Exception('Download Failed') elif os.path.exists(bfp)==False or os.path.getsize(bfp)!=1710671599: mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/case_zoo/scribble2img/ControlNet/openai/clip-vit-large-patch14/pytorch_model.bin', bfp) elif os.path.exists(sfp)==False or os.path.getsize(sfp)!=5710757851: mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/case_zoo/scribble2img/ControlNet/models/control_sd15_scribble.pth', sfp) else: print("Model Package already exists!")
安裝庫,大約耗時1min,請耐心等待,
%cd /home/ma-user/work/ControlNet !pip uninstall torch torchtext -y !pip install torch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 !pip install omegaconf==2.1.1 einops==0.3.0 !pip install pytorch-lightning==1.5.0 !pip install transformers==4.19.2 open_clip_torch==2.0.2 !pip install gradio==3.24.1 !pip install translate==3.6.1
2. 加載模型
導包并加載模型,加載約40s,請耐心等待,
import numpy as np from PIL import Image as PilImage import cv2 import einops import matplotlib.pyplot as plt from IPython.display import HTML, Image from base64 import b64decode from translate import Translator import torch from pytorch_lightning import seed_everything import config from cldm.model import create_model, load_state_dict from ldm.models.diffusion.ddim import DDIMSampler from annotator.util import resize_image, HWC3 model = create_model('./models/cldm_v15.yaml') model.load_state_dict(load_state_dict('./models/control_sd15_scribble.pth', location='cuda')) model = model.cuda() ddim_sampler = DDIMSampler(model)
3. 涂鴉生成影像
涂鴉生成影像函式定義
def process(input_image, prompt, a_prompt, n_prompt, num_samples, image_resolution, ddim_steps, strength, scale, seed, eta): trans = Translator(from_lang="ZH",to_lang="EN-US") prompt = trans.translate(prompt) a_prompt = trans.translate(a_prompt) n_prompt = trans.translate(n_prompt) guess_mode = False # 影像預處理 with torch.no_grad(): if type(input_image) is str: input_image = np.array(PilImage.open(input_image)) img = resize_image(HWC3(input_image), image_resolution) else: img = resize_image(HWC3(input_image['mask'][:, :, 0]), image_resolution) # scribble H, W, C = img.shape # 初始化檢測映射 detected_map = np.zeros_like(img, dtype=np.uint8) detected_map[np.min(img, axis=2) > 127] = 255 control = torch.from_numpy(detected_map.copy()).float().cuda() / 255.0 control = torch.stack([control for _ in range(num_samples)], dim=0) control = einops.rearrange(control, 'b h w c -> b c h w').clone() # 設定隨機種子 if seed == -1: seed = random.randint(0, 65535) seed_everything(seed) if config.save_memory: model.low_vram_shift(is_diffusing=False) cond = {"c_concat": [control], "c_crossattn": [model.get_learned_conditioning([prompt + ', ' + a_prompt] * num_samples)]} un_cond = {"c_concat": None if guess_mode else [control], "c_crossattn": [model.get_learned_conditioning([n_prompt] * num_samples)]} shape = (4, H // 8, W // 8) if config.save_memory: model.low_vram_shift(is_diffusing=True) # 采樣 model.control_scales = [strength * (0.825 ** float(12 - i)) for i in range(13)] if guess_mode else ([strength] * 13) # Magic number. samples, intermediates = ddim_sampler.sample(ddim_steps, num_samples, shape, cond, verbose=False, eta=eta, unconditional_guidance_scale=scale, unconditional_conditioning=un_cond) if config.save_memory: model.low_vram_shift(is_diffusing=False) # 后處理 x_samples = model.decode_first_stage(samples) x_samples = (einops.rearrange(x_samples, 'b c h w -> b h w c') * 127.5 + 127.5).cpu().numpy().clip(0, 255).astype(np.uint8) results = [x_samples[i] for i in range(num_samples)] return [255 - detected_map] + results
3.1設定引數,生成影像
在/home/ma-user/work/ControlNet/test_imgs/ 此路徑下,我們預置了一些線稿供您測驗,當然您可以自己上傳您的涂鴉畫至此路徑下,然后更改影像路徑及其他引數后,點擊運行,
引數說明
images:生成影像張數
img_path:輸入影像路徑,黑白稿
prompt:提示詞(建議填寫)
a_prompt:正面提示(可選,要附加到提示的其他文本)
n_prompt: 負面提示(可選)
image_resolution: 對輸入的圖片進行最長邊等比resize
scale:classifier-free引導比例
seed: 隨機種子
ddim_steps: 采樣步數,一般15-30,值越大越精細,耗時越長
eta: 控制在去噪擴散程序中添加到輸入資料的噪聲量,0表示無噪音,1.0表示更多噪音,eta對影像有微妙的、不可預測的影響,所以您需要嘗試一下這如何影響您的專案,
strength: 這是應用 ControlNet 的步驟數,它類似于影像到影像中的去噪強度,如果指導強度為 1,則 ControlNet 應用于 100% 的采樣步驟,如果引導強度為 0.7 并且您正在執行 50 個步驟,則 ControlNet 將應用于前 70% 的采樣步驟,即前 35 個步驟,
#@title Scribble2img img_path = "test_imgs/cat.jpg" #@param {type:"string"} prompt = "小花貓" #@param {type:"string"} num_samples = 1 # Added Prompt a_prompt = "質量最好,非常詳細" #@param {type:"string"} # Negative Prompt n_prompt = "裁剪,質量最差,質量低" #@param {type:"string"} image_resolution = 512 #@param {type:"raw", dropdown} scale = 4.3 #@param {type:"slider", min:0.1, max:30, step:0.1} seed = 1773327477 #@param {type:"slider", min:-1, max:2147483647, step:1} eta = 0.02 #@param {type:"slider", min:-1.00, max:3.00, step:0.01} ddim_steps = 15 #@param {type:"slider", min:1, max:100, step:1} guess_mode = False strength = 1.0 np_imgs = process(img_path, prompt, a_prompt, n_prompt, num_samples, image_resolution, ddim_steps, strength, scale, seed, eta) src = PilImage.fromarray(~np_imgs[0]) dst = PilImage.fromarray(np_imgs[1]) fig = plt.figure(figsize=(25, 10)) ax1 = fig.add_subplot(1, 2, 1) plt.title('Scribble image', fontsize=16) ax1.axis('off') ax1.imshow(src) ax2 = fig.add_subplot(1, 2, 2) plt.title('Generate image', fontsize=16) ax2.axis('off') ax2.imshow(dst) plt.show()
在右側有互動式控制元件,可以簡單調整引數,然后運行即可,等待生成,

3.2模型局限性以及可能的偏差
- Prompt只支持中英文輸入,
- 所提供的影像或簡筆畫過于簡單或意義不明確時,模型可能生成與上傳影像相關度低的物體或是一些無意義的前景物體,可以修改上傳影像重新嘗試,
- 在一些場景下,描述Prompt不夠明確時,模型可能生成錯誤的前景物體,可以更改Prompt并生成多次,取效果較好的結果,
當所提供的影像或簡筆畫與描述Prompt相關度低或無關時,模型可能生成偏向影像或偏向Prompt的內容,也可能生成無意義的內容;因此建議描述Prompt與所上傳的影像緊密相關并且盡可能詳細,
4. Gradio可視化部署
如果想進行可視化部署,可以繼續以下步驟: Gradio應用啟動后可在下方頁面進行涂鴉生成影像,您也可以分享public url在手機端,PC端進行訪問生成影像,
4.1 ControlNet擴展說明
- 影像畫布:您可以拖動設定畫布寬度和畫布高度,然后點擊 開啟畫布! 來創建一張空白畫布,
- 調整筆刷進行繪畫
- 輸入描述詞(推薦),點擊 Run
- 高級選項(可選),您可點擊此選項卡,打開折疊部分,按照上述引數說明進行設定,設定完成后點擊 Run
import gradio as gr # 畫布生成函式 def create_canvas(w, h): img = np.zeros(shape=(h-2, w-2, 3), dtype=np.uint8) + 255 im = cv2.copyMakeBorder(img,1,1,1,1,cv2.BORDER_CONSTANT) return im block = gr.Blocks().queue() with block: with gr.Row(): gr.Markdown("## 涂鴉生成影像 ") with gr.Row(): with gr.Column(): canvas_width = gr.Slider(label="畫布寬度", minimum=256, maximum=1024, value=https://www.cnblogs.com/huaweiyun/p/512, step=1) canvas_height = gr.Slider(label="畫布高度", minimum=256, maximum=1024, value=https://www.cnblogs.com/huaweiyun/p/512, step=1) create_button = gr.Button(label="Start", value=https://www.cnblogs.com/huaweiyun/p/'開啟畫布!') gr.Markdown(value='點擊下面右上角小鉛筆圖示,改變你的刷子寬度,讓它變的更細 (Gradio不允許開發人員設定畫筆寬度,因此需要手動設定) ') input_image = gr.Image(source='upload', type='numpy', tool='sketch') create_button.click(fn=create_canvas, inputs=[canvas_width, canvas_height], outputs=[input_image]) prompt = gr.Textbox(label="Prompt") run_button = gr.Button(label="運行") with gr.Accordion("高級選項", open=False): num_samples = gr.Slider(label="Images", minimum=1, maximum=12, value=https://www.cnblogs.com/huaweiyun/p/1, step=1) image_resolution = gr.Slider(label="Image Resolution", minimum=256, maximum=768, value=https://www.cnblogs.com/huaweiyun/p/512, step=64) strength = gr.Slider(label="Control Strength", minimum=0.0, maximum=2.0, value=https://www.cnblogs.com/huaweiyun/p/1.0, step=0.01) ddim_steps = gr.Slider(label="Steps", minimum=1, maximum=100, value=https://www.cnblogs.com/huaweiyun/p/20, step=1) scale = gr.Slider(label="Guidance Scale", minimum=0.1, maximum=30.0, value=https://www.cnblogs.com/huaweiyun/p/9.0, step=0.1) seed = gr.Slider(label="Seed", minimum=-1, maximum=2147483647, step=1, randomize=True) eta = gr.Number(label="eta (DDIM)", value=https://www.cnblogs.com/huaweiyun/p/0.0) a_prompt = gr.Textbox(label="Added Prompt", value=https://www.cnblogs.com/huaweiyun/p/'質量最好,非常詳細') n_prompt = gr.Textbox(label="Negative Prompt", value='裁剪,質量最差,質量低') with gr.Column(): result_gallery = gr.Gallery(label='Output', show_label=False, elem_id="gallery").style(grid=2, height='auto') ips = [input_image, prompt, a_prompt, n_prompt, num_samples, image_resolution, ddim_steps, strength, scale, seed, eta] run_button.click(fn=process, inputs=ips, outputs=[result_gallery]) block.launch(share=True)
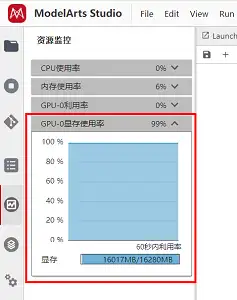
請注意: 影像生成消耗顯存,您可以在左側操作欄查看您的實時資源使用情況,點擊GPU顯存使用率即可查看,當顯存不足時,您生成影像可能會報錯,此時,您可以通過重啟kernel的方式重置,然后重頭運行即可規避,或更換更高規格的資源
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/551731.html
標籤:其他
下一篇:返回列表