作者:京東科技 王長春
業務問題
小編作業中負責業務的一個服務端系統,使用了 Elasticsearch 服務做資料存盤,業務運營人員反饋,用戶在使用該產品時發現,用戶后臺統計的訂單筆數和匯出的訂單筆數不一致!
交易訂單筆數不對,出現差錯訂單了?這一聽極為震撼!出現這樣的問題,在金融科技公司里面是絕對不允許發生的,得馬上定位問題并解決!
小編馬上聯系業務和相關人員,通過梳理上游系統的呼叫關系,發現業務系統使用到的是我這邊的 ES 的存盤服務,然后對線上情況進行復現,基本了解問題的現象:
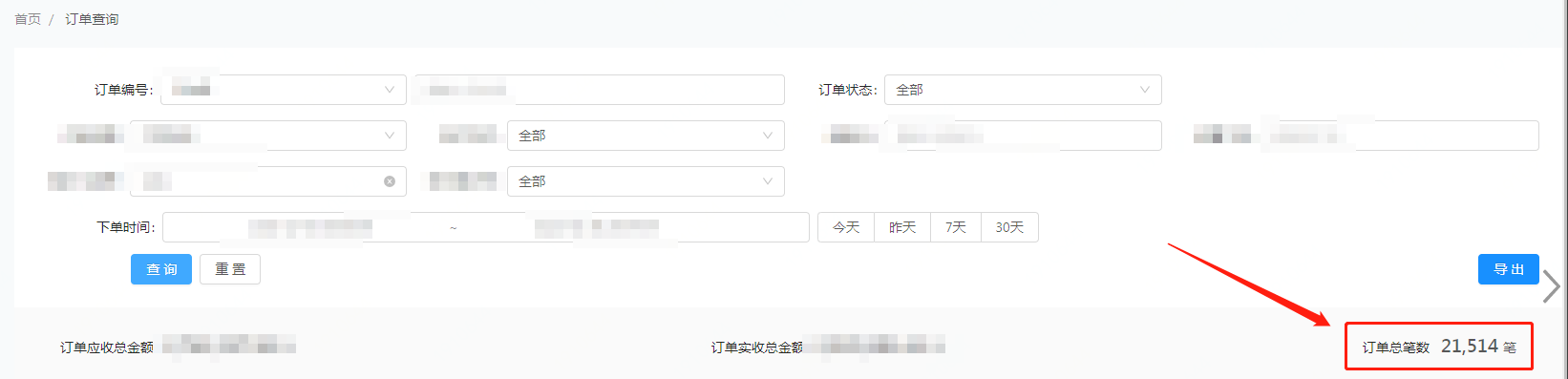
- 用戶操作后臺里的訂單總筆數:商戶頁面的"訂單總筆數","訂單總筆數"使用的是小編 ES 存盤服務中 ES 的統計聚合功能,其中訂單總筆數是使用了 cardinality 操作,并且使用的是 orderId(訂單編號)進行統計去重,
- 匯出功能里的訂單總筆數:匯出功能使用的是 ES 存盤服務中的 ES 條件查詢功能,匯出功能是進行分頁查詢的,
問題定位
這兩個查詢數量不一致,首先看查詢條件是否一致呢?
經過一番排查,業務系統在呼叫查詢訂單總數和匯出訂單總數的這兩個查詢條件是一致的,也就是請求到我這邊 ES 服務時,統計聚合的查詢和分頁匯出的查詢條件是一致的,但是為什么會在 ES 里面查詢的結果是不一致的呢?難道 ES 里面的資料不全?統計聚合或分頁匯出的其中有一個不準了?
為了具體排查哪個操作可能存在問題,于是通過相同條件下查詢資料庫的總數和 ES 里面的資料進行對比,發現相同條件下,資料庫里面的資料和 ES 條件查詢的總數是一致的, 同時業務的 orerId 欄位是沒有重復,所以可以確定的是:通過 orderId 進行統計聚合去重的操作是有問題的,
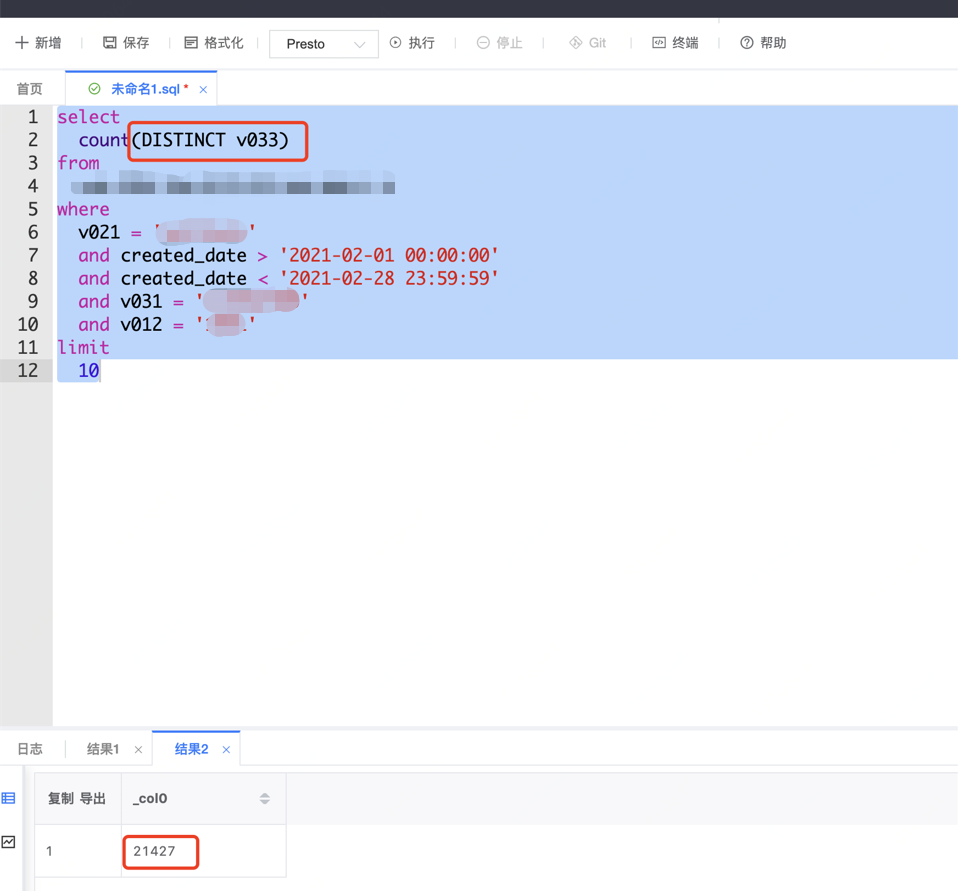
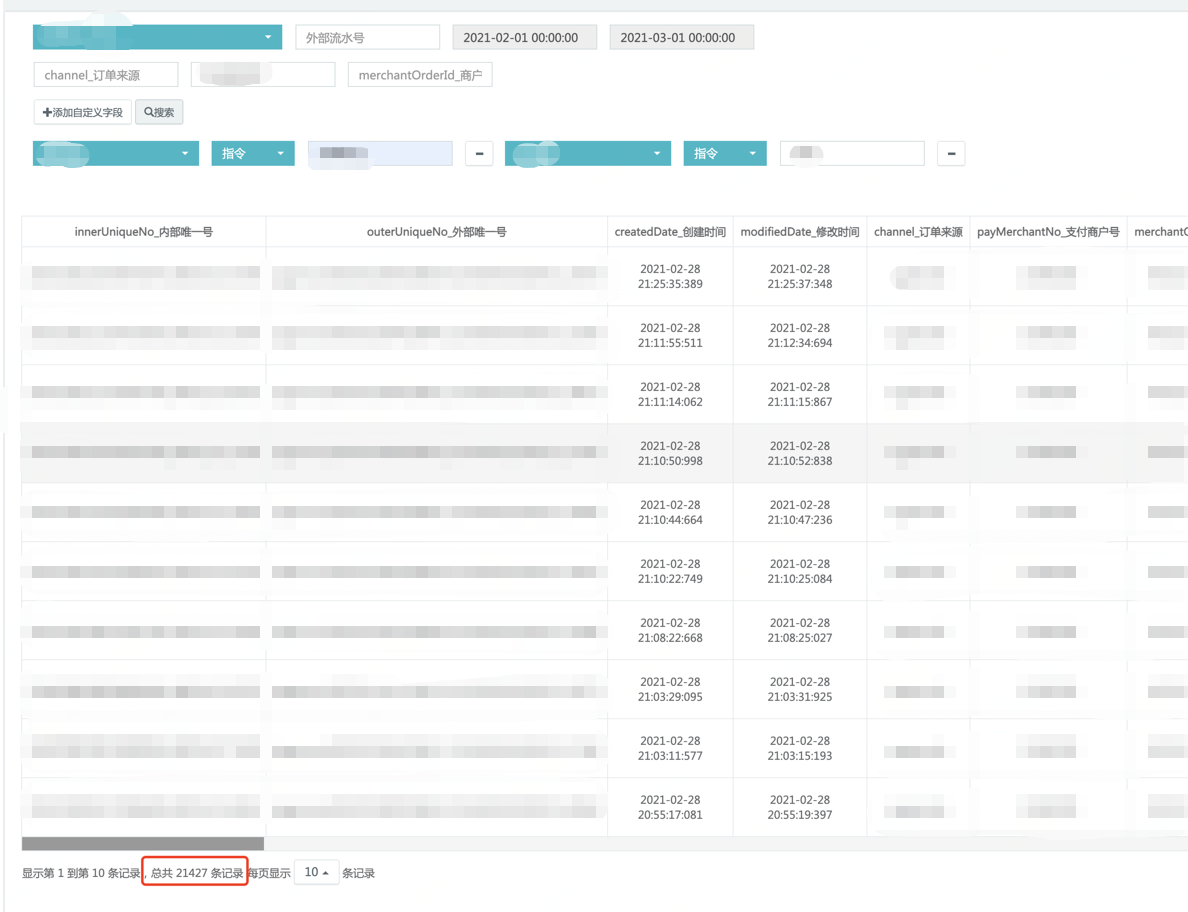
資料庫查詢:資料庫是做分庫分表,此處資料庫查詢使用的是公司內的資料部銀河大表——公司資料部會 T+1日從業務從庫資料庫中抽取 T 日的增量資料放在建立的"大表"中, 方便各業務進行資料使用,
運營后臺查詢:運營后臺查詢是直接查詢 ES 存盤服務,
資料部大表數量 = MySQL 資料庫分庫分表表里數量 = 運營控制臺查詢數量 = ES 存盤檔案數量
問題定位:
ES 存盤服務對外給業務提供的: 通過 orderId 進行統計聚合去重(cardinality)的功能應該是有問題的,
ES 的 cardinality 原理探究
上面說過,小編負責的 ES 存盤服務對外給業務提供了通過指定業務欄位進行統計聚合去重的功能,統計聚合去重使用的是 ES 的 cardinality 功能,通過業務的查詢的條件,使用 ES 的聚合功能 cardinality 操作,映射到 ES 層的操作命令如下代碼所示,
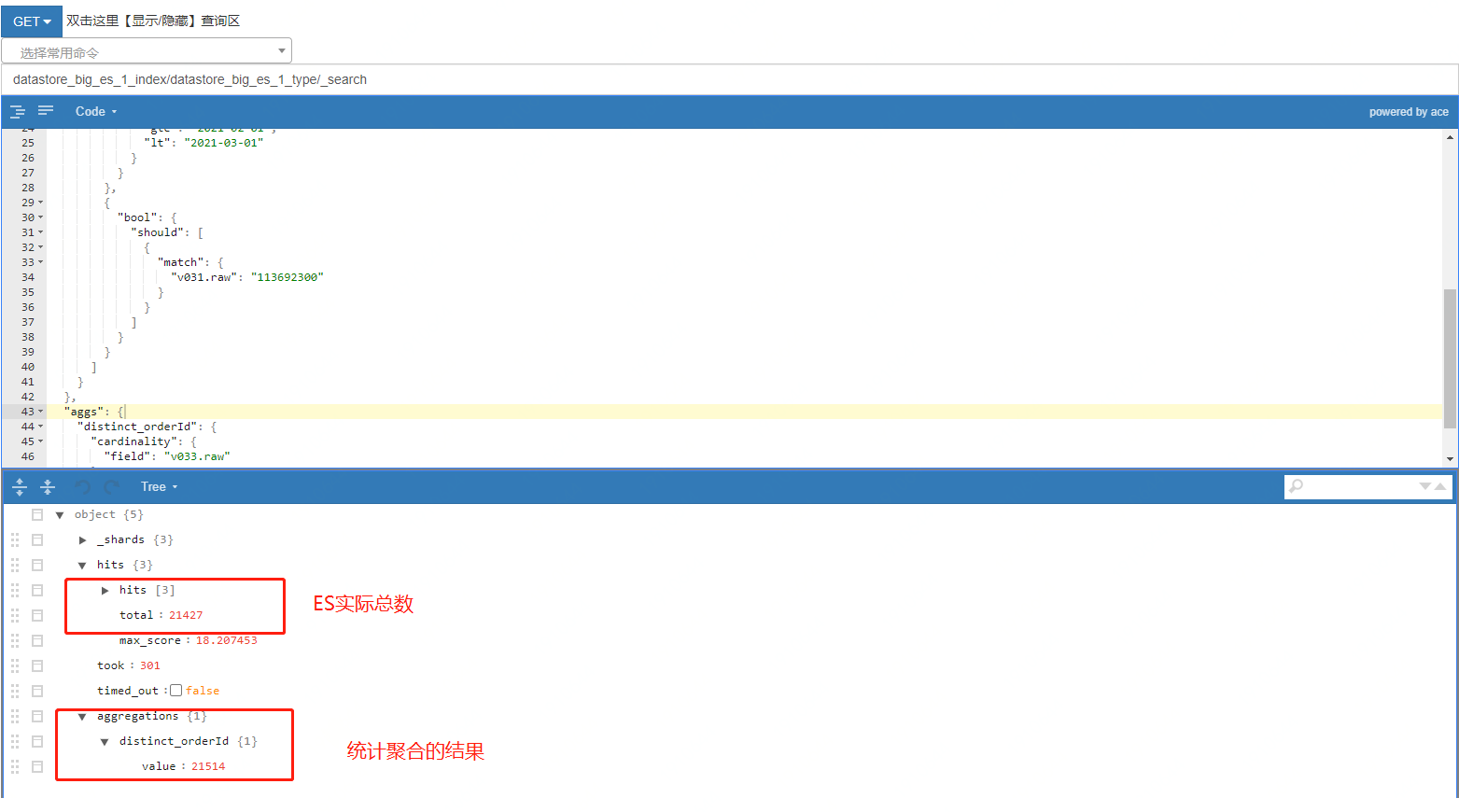
執行業務的查詢條件操作,從 ES 的管理端后臺里面查詢竟然復現了和線上生產一樣的結果,聚合統計的是 21514,條件查詢的是 21427!!!
可以確定的就是這個 cardinality 操作,導致了兩個查詢的資料不一致,如下圖所示:
GET datastore_big_es_1_index/datastore_big_es_1_type/_search
{
"size": 3,
"query": {
"bool": {
"must": [
{
"match": {
"v021.raw": "selfhelp"
}
},
{
"match": {
"v012.raw": "1001"
}
},
{
"match": {
"typeId": "00029"
}
},
{
"range": {
"createdDate": {
"gte": "2021-02-01",
"lt": "2021-03-01"
}
}
},
{
"bool": {
"should": [
{
"match": {
"v031.raw": "113692300"
}
}
]
}
}
]
}
},
"aggs": {
"distinct_orderId": {
"cardinality": {
"field": "v033.raw"
}
}
}
}
為什么 cardinality 操作會出現這樣的結果呢?
小編開始陷入了想當然的陷阱—— 以為這就是一個簡簡單單的統計去重的功能,ES 做的多好,幫你去重并統計數量了,然后事實并不是,通過 Elasticsearch 對 cardinality 官方檔案解釋,終于找到了原因,
可以參考Elasticsearch 2.x 版本官方檔案對 cardinality的解釋:cardinality
其中對 cardinality 演算法核心解釋是:

可以總結如下:
- cardinality 并不是像關系型資料庫 MySQL 一樣精確去重的,cardinality做的是一個近似值,是 ES 幫你"估算"出的,這個估算使用的HyperLogLog++(HLL)演算法,在速度上非常快,遍歷一次即可統計去重,具體可看檔案中推薦的論文,
- ES 做cardinality估算,是可以設定估算精確度,即設定引數 precision_threshold 引數,但是這個引數在 0-40000, 這個值越大意味著精度越高,同時意味著損失更多的記憶體,是以記憶體空間換精度,
- 在小資料量下,ES 的這個"估算"精度是非常高的,幾乎可以說是等于實際數量,
ES 中 cardinality 引數驗證
下面對 ES 的 cardinality 的precision_threshold引數進行驗證:
1、大資料量下,設定最高精度及其以上,仍然會存在誤差:
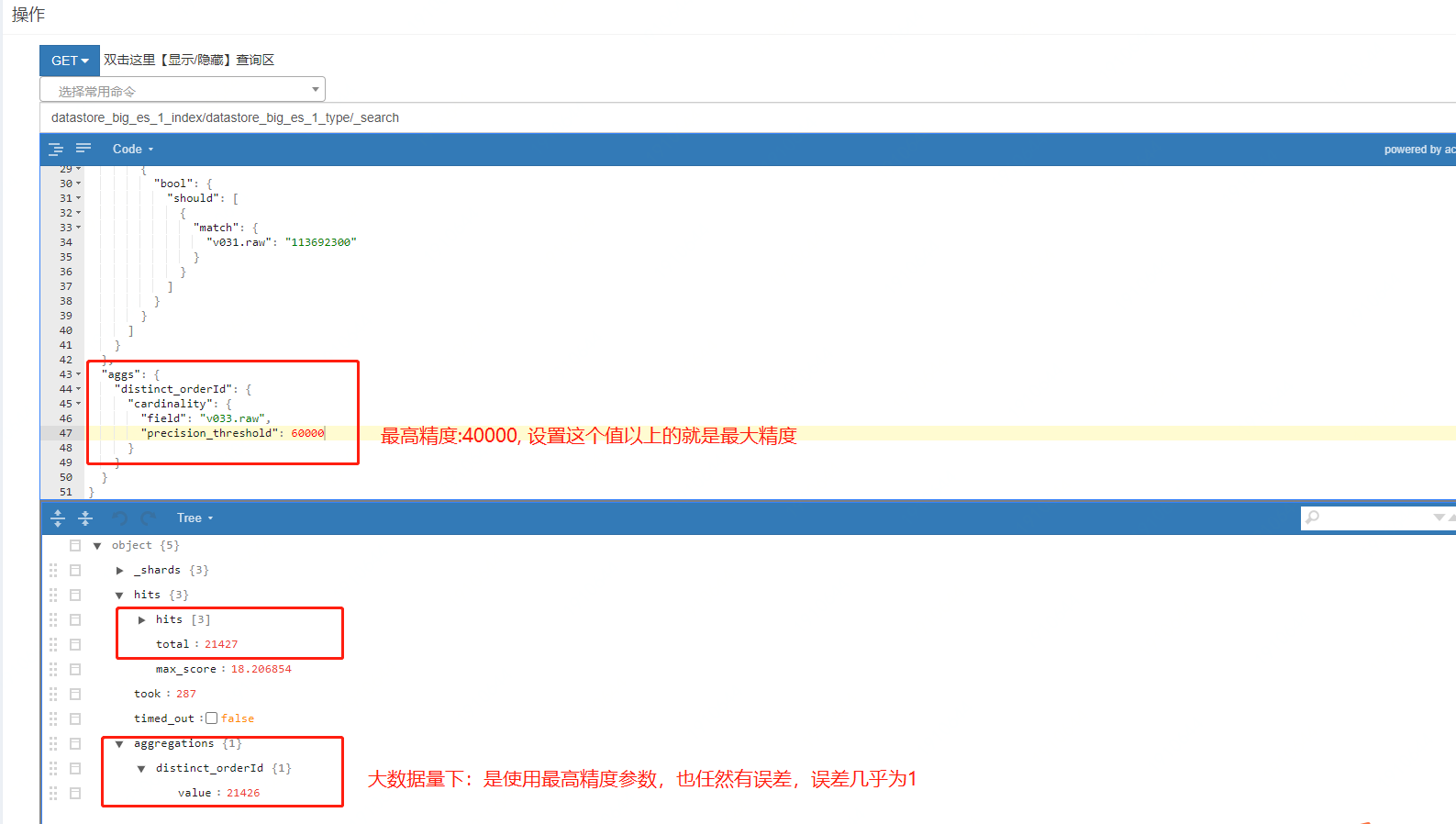
2、小資料量下,設定最高精度,可以和實際數量保持一致:
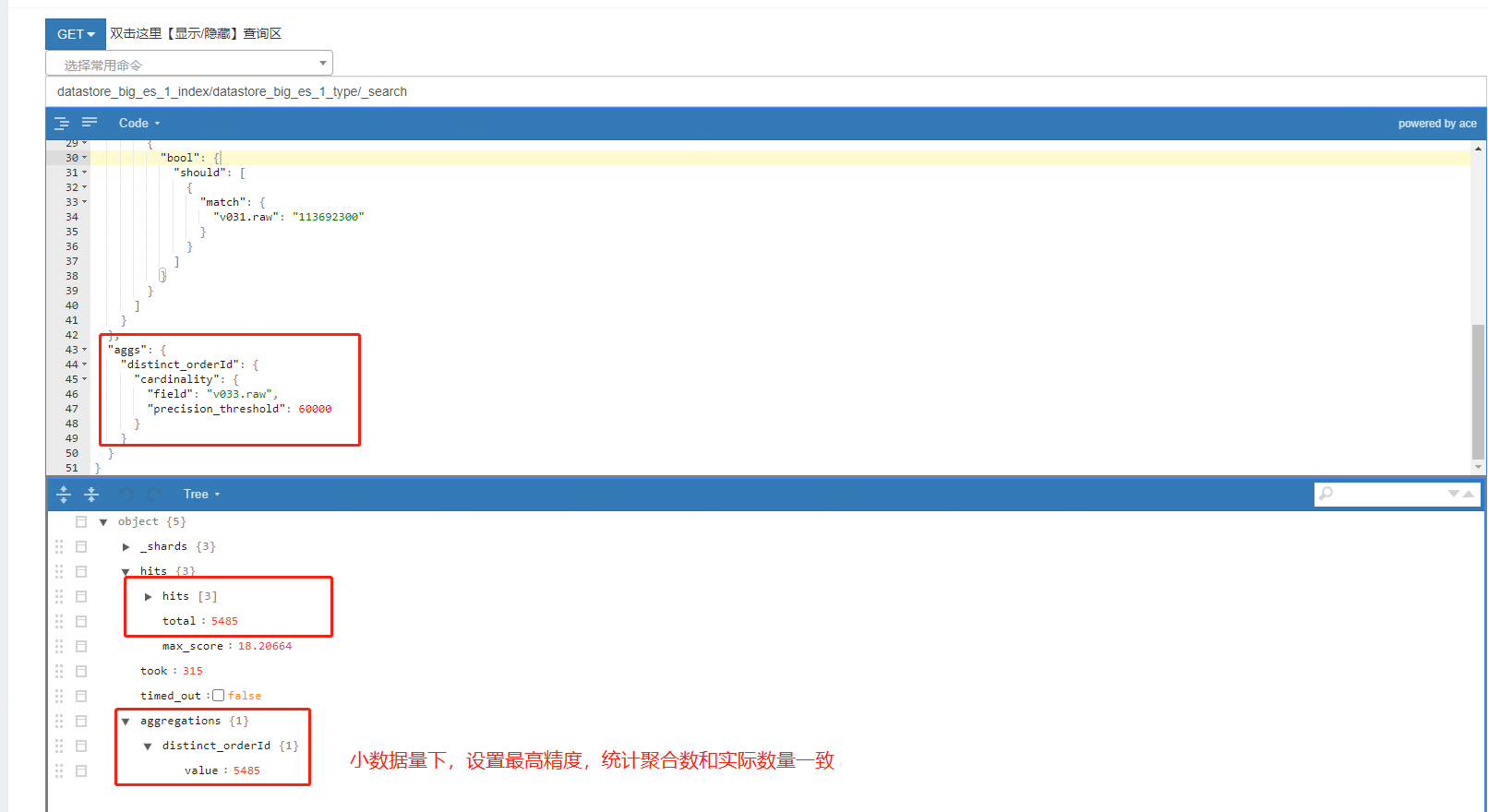
那么線上的為什么聚合統計的是 21514,條件查詢的是 21427?
線上代碼運行和ES集群設定都沒有主動設定過 precision_threshold 引數,那么可以知道,這個應該是 ES 集群設定的默認值,線上 ES 集群版本為 5.4x 因此找到 5.4 版本的官方檔案,發現 5.4 版本中設定的是默認值 precision_threshold=3000, 在此條件下查詢的統計聚合出來的值是 21514,
另外 ES 官方對 cardinality 操作中的precision_threshold引數也做了研究,研究了官方檔案中precision_threshold設定和cardinality查詢失敗率、查詢資料量級的關系,可作為我們在業務開發中進行參考,如下圖所示:
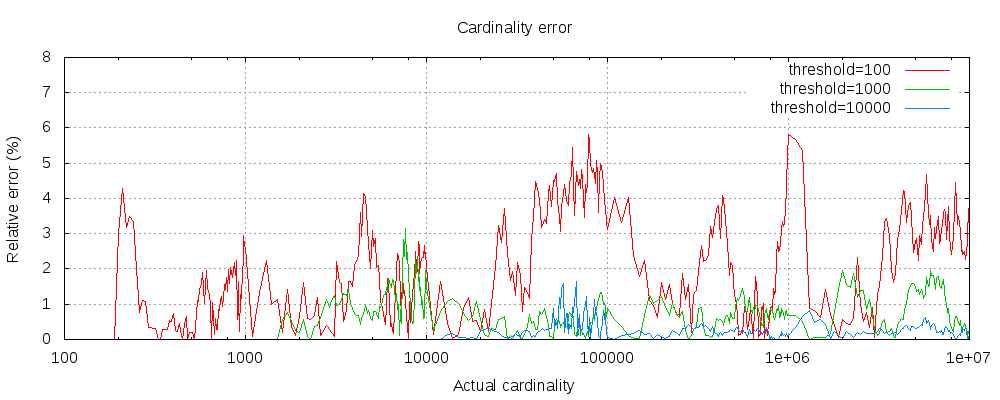
Elasticsearch 5.4版本官方檔案對cardinality中precision_threshold引數的研究檔案:precision_threshold
總結與方案
通過對 cardinality 的原理探究, 需要明白的是 : 我們使用 cardinality 是需要區分使用場景的,
- 對于精確統計的業務場景,是不建議使用的,例如:訂單數的統計(統計結果會引起歧義)的場景下,不建議使用,
- 對于非精確統計的業務場景,那么可以說是很有用了,尤其是在大資料量的場景下,在保持一定的準確性下,同時能提供高性能,例如:監控指標資料,大盤比例計算等場景,在非精確統計下,是有很大用處,
基于小編的這個業務場景,對商戶訂單進行統計,是屬于精確統計場景,那 cardinality 操作就不適合了,又因為業務的 orderId 是不會重復的,理論上在我們 ES 集群中每個記錄的 orderId 都是唯一的,因此可以不用進行去重,而可以直接使用 ES 的 count 操作,將訂單數統計匯總出,對應 Elasticsearch 開發包中 COUNT API 如下:
org.springframework.data.elasticsearch.core.ElasticsearchTemplate
#count(org.springframework.data.elasticsearch.core.query.SearchQuery, java.lang.Class<T>)
public <T> long count(SearchQuery searchQuery, Class<T> clazz) {
QueryBuilder elasticsearchQuery = searchQuery.getQuery();
QueryBuilder elasticsearchFilter = searchQuery.getFilter();
return elasticsearchFilter == null ? this.doCount(this.prepareCount(searchQuery, clazz), elasticsearchQuery) : this.doCount(this.prepareSearch(searchQuery, clazz), elasticsearchQuery, elasticsearchFilter);
}
最后歡迎大家點贊、收藏、評論,轉發!??????
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/551809.html
標籤:其他
上一篇:分布式場景下,如何對外提供易變的服務,打造可靠的注冊中心?
下一篇:返回列表