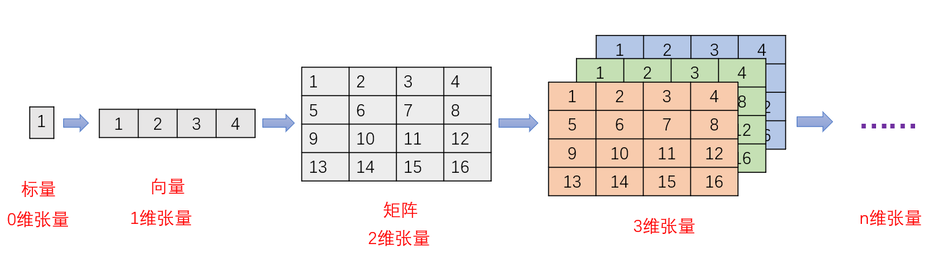
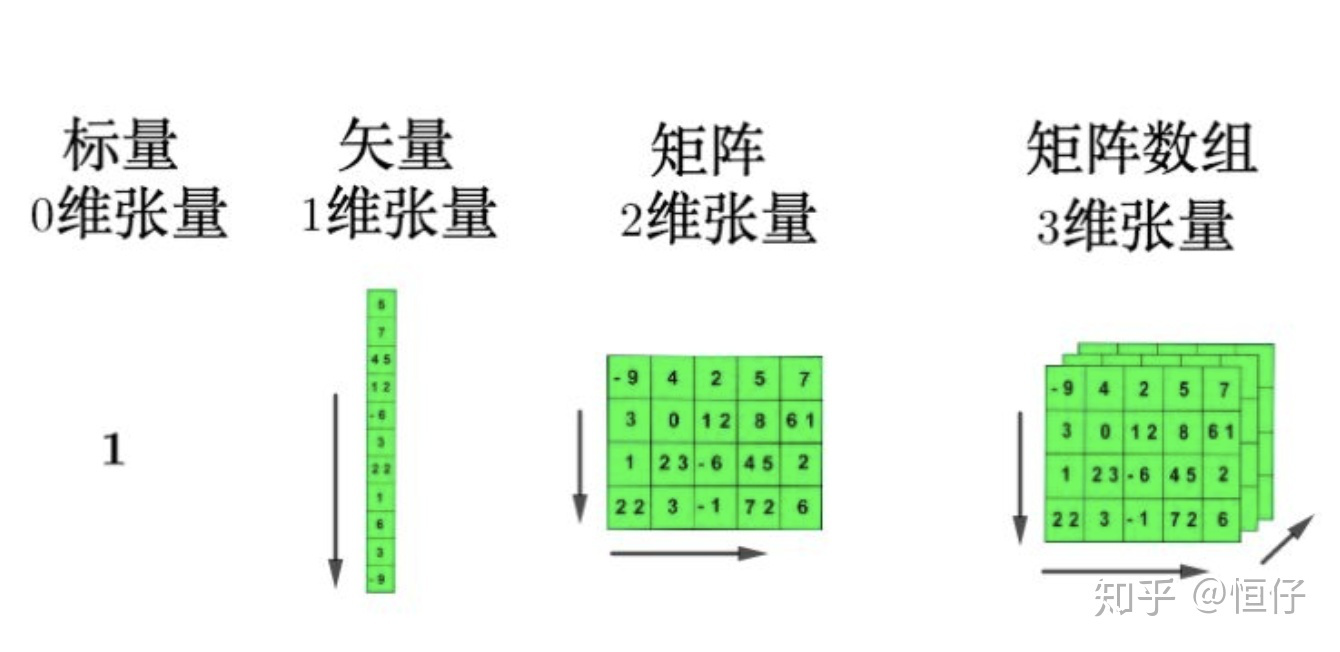
張量(Tensor):Tensor = multi-dimensional array of numbers 張量是一個多維陣列,它是標量,向量,矩陣的高維擴展 ,是一個資料容器,張量是矩陣向任意維度的推廣
注意,張量的維度(dimension)通常叫作軸(axis), 張量軸的個數也叫作階(rank)]
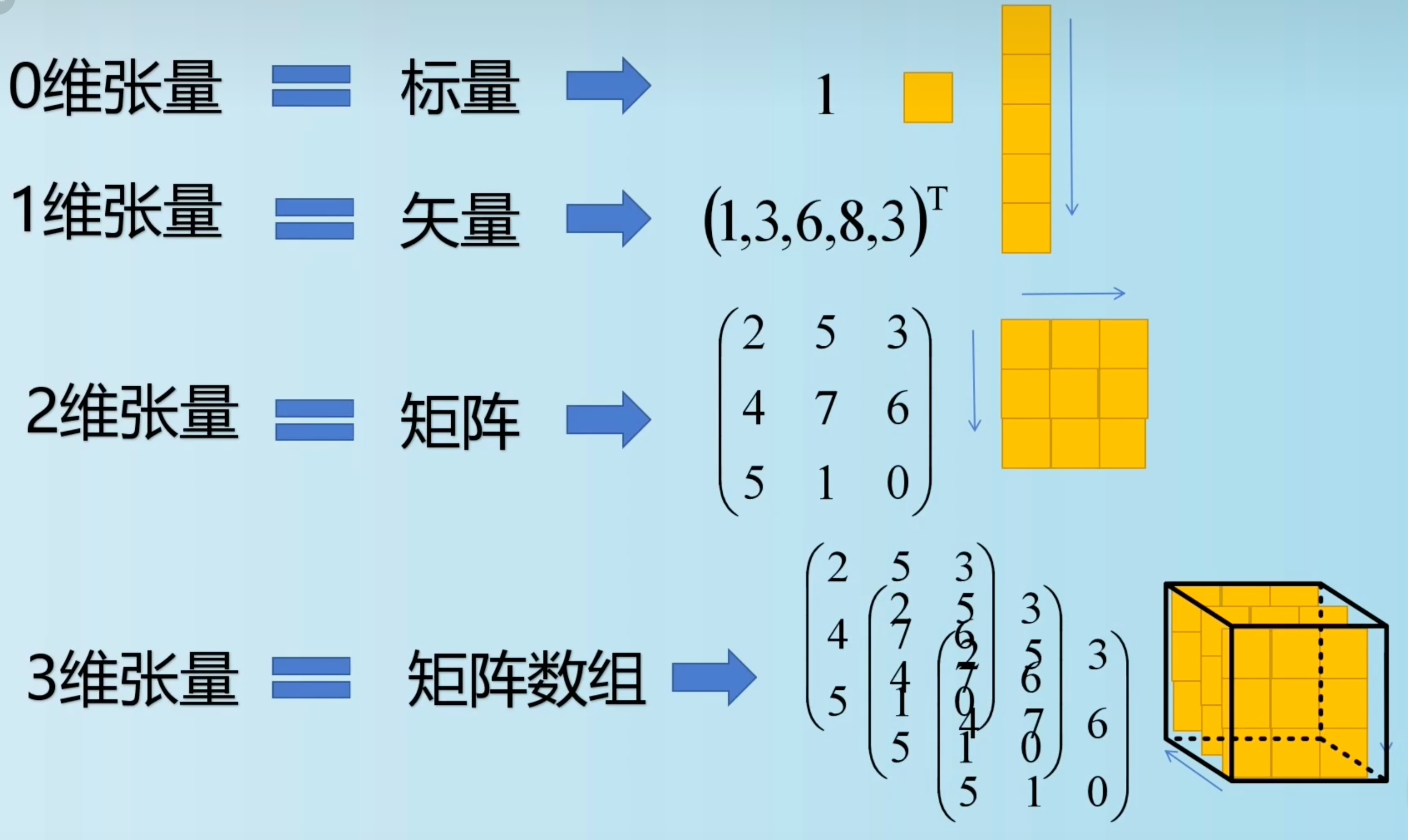
標量(scalar):只有一個數字的張量叫標量(也叫標量張量、零維張量、0D 張量)
x = np.array(12)
print(x.ndim) 可以用 ndim 屬性來查看一個 Numpy 張量的軸的個數,標量張量有 0 個軸( ndim == 0 ),
向量(vector):數字組成的陣列叫作向量(vector)或一維張量(1D 張量),一維張量只有一個軸,下面是一個 Numpy 向量
np.array([12, 3, 6, 14, 7])
這個向量有 5 個元素,所以被稱為 5D 向量,不要把 5D 向量和 5D 張量弄混! 5D 向量只有一個軸,沿著軸有 5 個維度,而 5D 張量有 5 個軸(沿著每個軸可能有任意個維度)
矩陣(matrix):是一個按照長方陣列排列的復數或實數集合,矩陣是二維張量(2D 張量)
np.array([[5, 78, 2, 34, 0], [6, 79, 3, 35, 1], [7, 80, 4, 36, 2]])
向量組成的陣列叫作矩陣(matrix)或二維張量(2D 張量),矩陣有 2 個軸(通常叫作行和列),你可以將矩陣直觀地理解為數字組成的矩形網格,下面是一個 Numpy 矩陣,
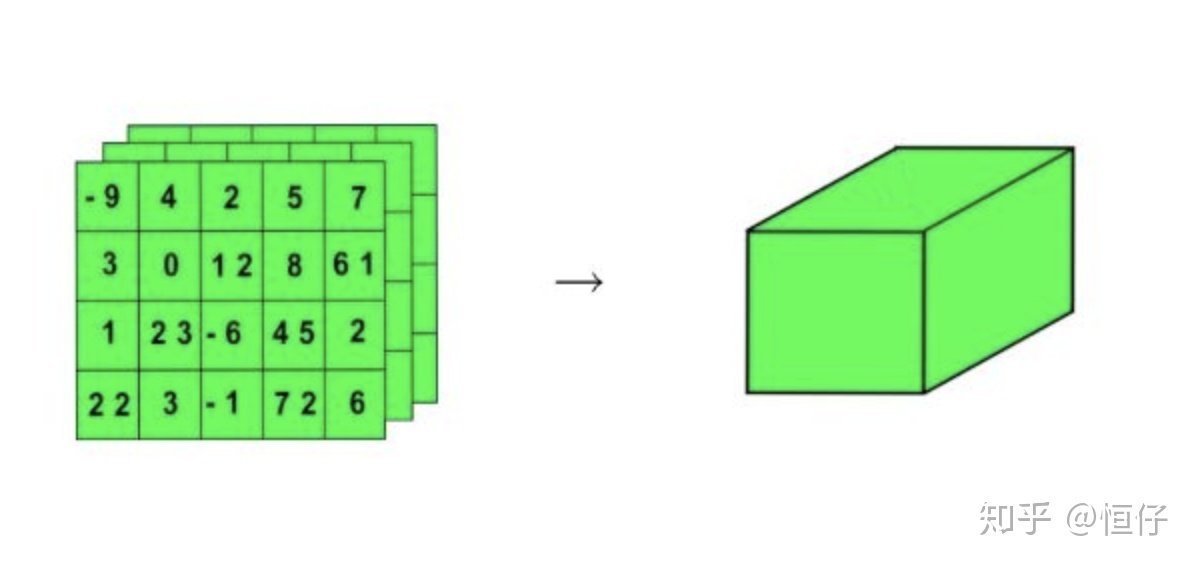
3D 張量與n 維張量
將多個矩陣組合成一個新的陣列,可以得到一個 3D 張量,你可以將其直觀地理解為數字組成的立方體,下面是一個 Numpy 的 3D 張量,
np.array([[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]],
[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]],
[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]]])
將多個 3D 張量組合成一個陣列,可以創建一個 4D 張量,以此類推,深度學習處理的一般是 0D 到 4D 的張量,但處理視頻資料時可能會遇到 5D 張量,
張量屬性
張量是由以下三個關鍵屬性來定義的,
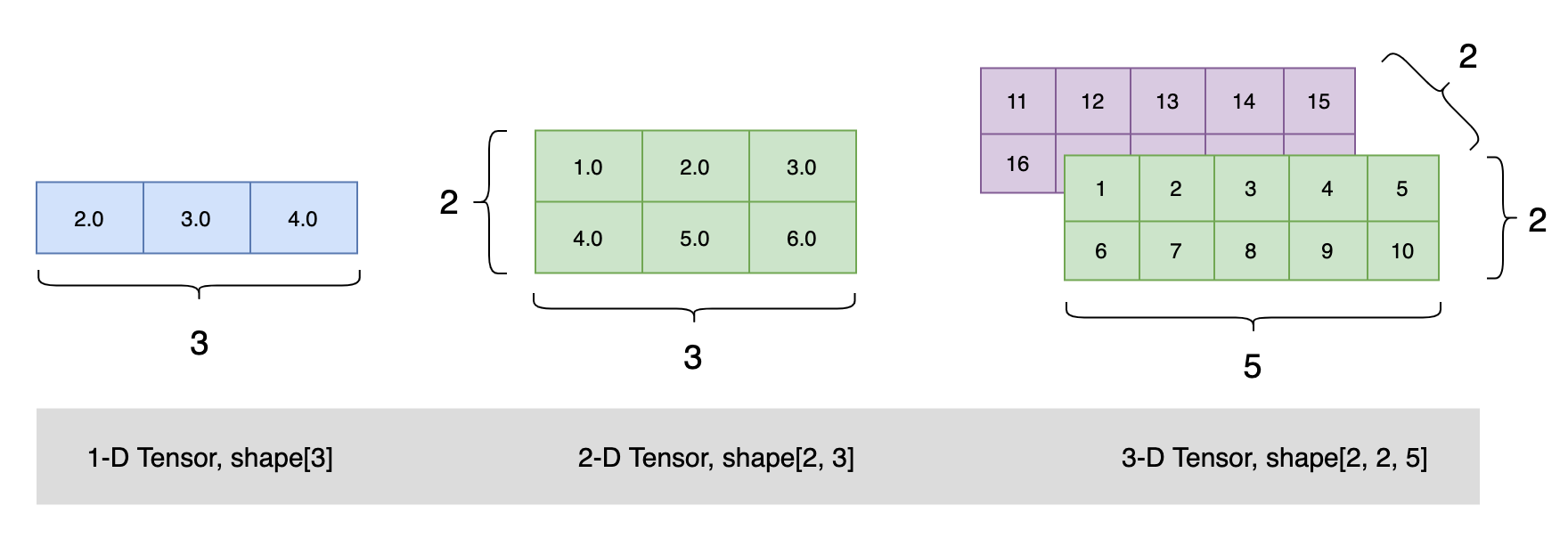
- 軸的個數(階):例如,3D 張量有 3 個軸,矩陣有 2 個軸,這在 Numpy 等 Python 庫中也叫張量的 ndim ,
- 形狀(shape):這是一個整數元組,表示張量沿每個軸的維度大小(元素個數),例如,前面矩陣示例的形狀為 (3, 5) ,3D 張量示例的形狀為 (3, 3, 5) ,向量的形狀只包含一個元素,比如 (5,) ,而標量的形狀為空,即 () ,(張量的形狀)
- 資料型別(dtype):這是張量中所包含資料的型別,例如,張量的型別可以是 float32 、 uint8 、 float64 等,在極少數情況下,你可能會遇到字符( char )張量,注意:Numpy(以及大多數其他庫)中不存在字串張量,因為張量存盤在預先分配的連續記憶體段中,而字串的長度是可變的,無法用這種方式存盤,
data: Tensor的值;
dtype: Tensor的資料型別;
shape: Tensor的形狀;
device: Tensor所在的設備(CPU/GPU);
requires_grad: 是否需要梯度;
grad: Tensor的梯度;
grad_fn: 創建Tensor的函式;
is_leaf: 是否是葉子節點
資料張量
向量資料:2D 張量,形狀為 (samples, features)
這是最常見的資料,對于這種資料集,每個資料點都被編碼為一個向量,因此一個資料批量就被編碼為 2D 張量(即向量組成的陣列),其中第一個軸是樣本軸,第二個軸是特征軸,
例子:
- 人口統計資料集,其中包括每個人的年齡、郵編和收入,每個人可以表示為包含 3 個值的向量,而整個資料集包含 100 000 個人,因此可以存盤在形狀為 (100000, 3) 的 2D張量中,
- 文本檔案資料集,我們將每個檔案表示為每個單詞在其中出現的次數(字典中包含20 000 個常見單詞),每個檔案可以被編碼為包含 20 000 個值的向量(每個值對應于字典中每個單詞的出現次數),整個資料集包含 500 個檔案,因此可以存盤在形狀為(500, 20000) 的張量中,
時間序列資料或序列資料:3D 張量,形狀為 (samples, timesteps, features)
當時間(或序列順序)對于資料很重要時,應該將資料存盤在帶有時間軸的 3D 張量中,每個樣本可以被編碼為一個向量序列(即 2D 張量),因此一個資料批量就被編碼為一個 3D 張量(見下圖)
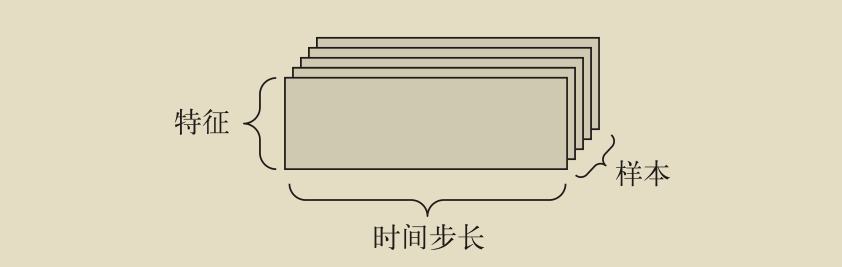
根據慣例,時間軸始終是第 2 個軸(索引為 1 的軸),
我們來看幾個例子,
- 股票價格資料集,每一分鐘,我們將股票的當前價格、前一分鐘的最高價格和前一分鐘的最低價格保存下來,因此每分鐘被編碼為一個 3D 向量,整個交易日被編碼為一個形狀為 (390, 3) 的 2D 張量(一個交易日有 390 分鐘),而 250 天的資料則可以保存在一個形狀為 (250, 390, 3) 的 3D 張量中,這里每個樣本是一天的股票資料,
- 推文資料集,我們將每條推文編碼為 280 個字符組成的序列,而每個字符又來自于 128個字符組成的字母表,在這種情況下,每個字符可以被編碼為大小為 128 的二進制向量(只有在該字符對應的索引位置取值為 1,其他元素都為 0),那么每條推文可以被編碼為一個形狀為 (280, 128) 的 2D 張量,而包含 100 萬條推文的資料集則可以存盤在一個形狀為 (1000000, 280, 128) 的張量中,
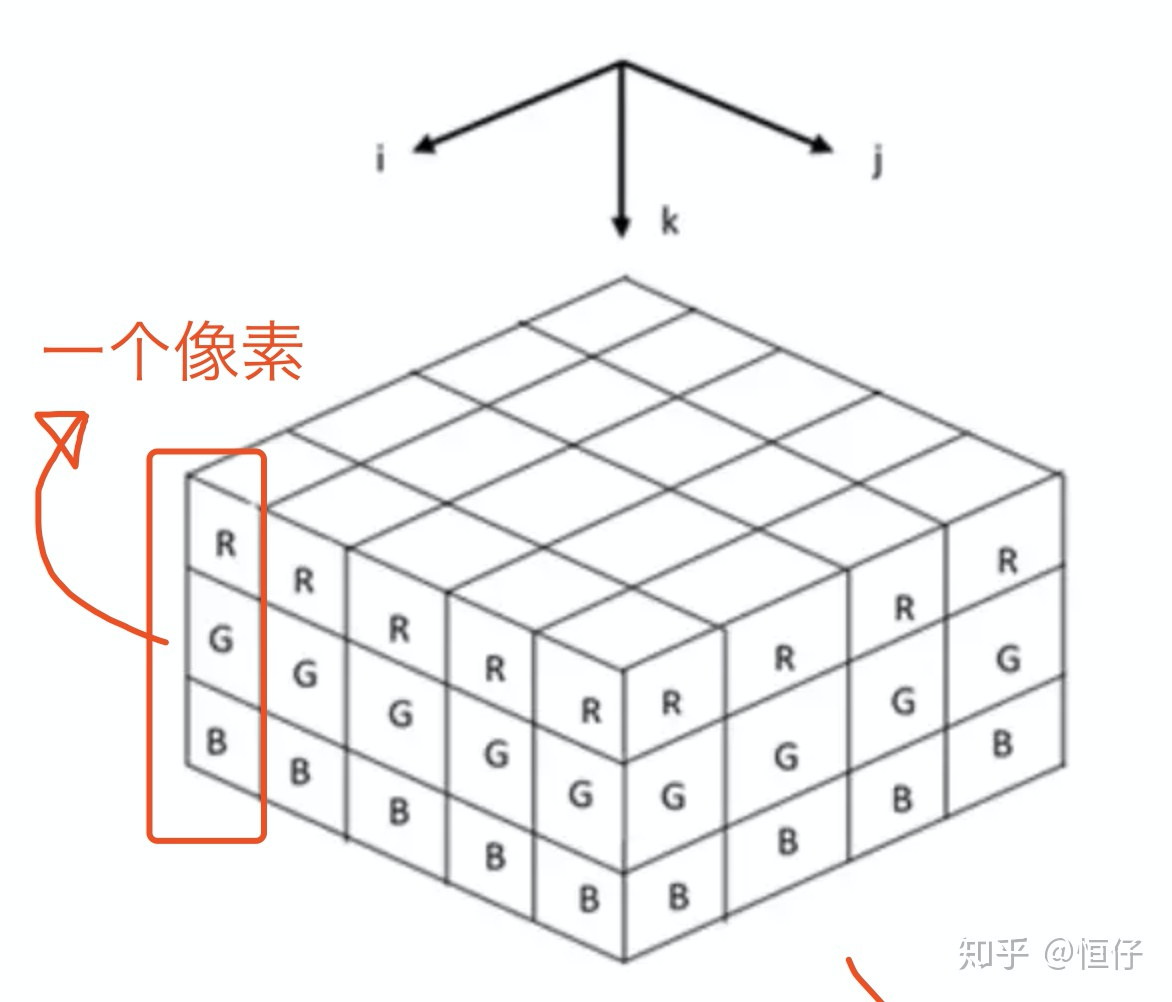
影像:4D張量,形狀為 (samples, height, width, channels) 或 (samples, channels,height, width) ,
影像通常具有三個維度:高度、寬度和顏色深度,雖然灰度影像(比如 MNIST 數字影像)只有一個顏色通道,因此可以保存在 2D 張量中,但按照慣例,影像張量始終都是 3D 張量,灰度影像的彩色通道只有一維,因此,如果影像大小為 256×256,那么 128 張灰度影像組成的批量可以保存在一個形狀為 (128, 256, 256, 1) 的張量中,而 128 張彩色影像組成的批量則可以保存在一個形狀為 (128, 256, 256, 3) 的張量中,
影像張量的形狀有兩種約定:通道在后(channels-last)的約定(在 TensorFlow 中使用)和通道在前(channels-first)的約定(在 Theano 中使用),Google 的 TensorFlow 機器學習框架將顏色深度軸放在最后: (samples, height, width, color_depth) ,與此相反,Theano將影像深度軸放在批量軸之后: (samples, color_depth, height, width) ,如果采用 Theano 約定,前面的兩個例子將變成 (128, 1, 256, 256) 和 (128, 3, 256, 256) ,Keras 框架同時支持這兩種格式,
如下圖所示是一張普通的水果圖片,按照RGB三原色表示,其可以拆分為紅色、綠色和藍色的三張灰度圖片,如果將這種表示方法用張量的形式寫出來,就是圖中最下方的那張表格
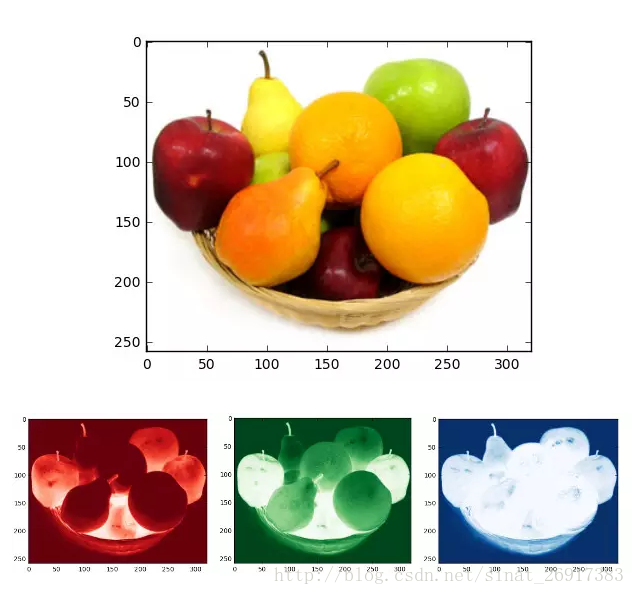
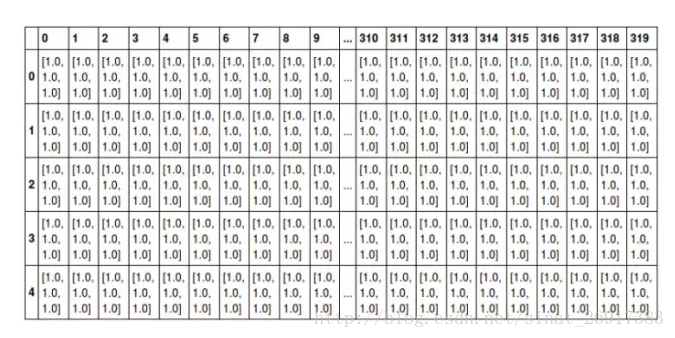
圖中只顯示了前5行、320列的資料,每個方格代表一個像素點,其中的資料[1.0, 1.0, 1.0]即為顏色,假設用[1.0, 0, 0]表示紅色,[0, 1.0, 0]表示綠色,[0, 0, 1.0]表示藍色,那么如圖所示,前面5行的資料則全是白色
用四階張量表示一個包含多張圖片的資料集,其中的四個維度分別是:圖片在資料集中的編號,圖片高度、寬度,以及色彩資料,
視頻:5D張量,形狀為 (samples, frames, height, width, channels) 或 (samples,frames, channels, height, width)
視頻資料是現實生活中需要用到 5D 張量的少數資料型別之一,視頻可以看作一系列幀,每一幀都是一張彩色影像,由于每一幀都可以保存在一個形狀為 (height, width, color_depth) 的 3D 張量中,因此一系列幀可以保存在一個形狀為 (frames, height, width,color_depth) 的 4D 張量中,而不同視頻組成的批量則可以保存在一個 5D 張量中,其形狀為(samples, frames, height, width, color_depth) ,
舉個例子,一個以每秒 4 幀采樣的 60 秒 YouTube 視頻片段,視頻尺寸為 144×256,這個視頻共有 240 幀,4 個這樣的視頻片段組成的批量將保存在形狀為 (4, 240, 144, 256, 3)的張量中,總共有 106 168 320 個值!如果張量的資料型別( dtype )是 float32 ,每個值都是32 位,那么這個張量共有 405MB,好大!你在現實生活中遇到的視頻要小得多,因為它們不以float32 格式存盤,而且通常被大大壓縮,比如 MPEG 格式,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/552139.html
標籤:其他
上一篇:安全應急回應中心SRC
下一篇:返回列表