
AIGC 熱潮正猛烈地席卷開來,可以說 Stable Diffusion 開源發布把 AI 影像生成提高了全新高度,特別是 ControlNet 和 T2I-Adapter 控制模塊的提出進一步提高生成可控性,也在逐漸改變一部分行業的生產模式,驚艷其出色表現,也不禁好奇其背后技術,本文整理了一些學習程序中記錄的技術內容,主要包括 Stable Diffusion 技術運行機制,希望幫助大家知其所以然,
一 背景介紹
AI 繪畫作為 AIGC(人工智能創作內容)的一個應用方向,它絕對是 2022 年以來 AI 領域最熱門的話題之一,AI 繪畫憑借著其獨特創意和便捷創作工具迅速走紅,廣受關注,舉兩個簡單例子,左邊是利用 controlnet 新魔法把一張四個閨蜜在沙灘邊上的普通合影照改成唯美動漫風,右邊是 midjourney v5 最新版本解鎖的逆天神技, 只需輸入文字“舊廠街風格,帶著濃濃 90 年代氛圍感”即可由 AI 一鍵生成超逼真圖片!

Stable Diffusion,是一個 2022 年發布的文本到影像潛在擴散模型,由 CompVis、Stability AI 和 LAION 的研究人員創建的,要提到的是,Stable Diffusion 技術提出者 StabilityAI 公司在 2022 年 10 月完成了 1.01 億美元的融資,估值目前已經超過 10 億美元,本文會在第二部分著重介紹 Stable Diffusion 的技術思路,第三部分深入分析各個重要模塊的運行機制,最后總結下 AI 繪畫,
二 原理簡介
Stable Diffusion 技術,作為 Diffusion 改進版本,通過引入隱向量空間來解決 Diffusion 速度瓶頸,除了可專門用于文生圖任務,還可以用于圖生圖、特定角色刻畫,甚至是超分或者上色任務,作為一篇基礎原理介紹,這里著重決議最常用的“文生圖(text to image)”為主線,介紹 stable diffusion 計算思路以及分析各個重要的組成模塊,
下圖是一個基本的文生圖流程,把中間的 Stable Diffusion 結構看成一個黑盒,那黑盒輸入是一個文本串“paradise(天堂)、cosmic(廣闊的)、beach(海灘)”,利用這項技術,輸出了最右邊符合輸入要求的生成圖片,圖中產生了藍天白云和一望無際的廣闊海灘,

Stable Diffusion 的核心思想是,由于每張圖片滿足一定規律分布,利用文本中包含的這些分布資訊作為指導,把一張純噪聲的圖片逐步去噪,生成一張跟文本資訊匹配的圖片,它其實是一個比較組合的系統,里面包含了多個模型子模塊,接下來把黑盒進行一步步拆解,stable diffusion 最直接的問題是,如何把人類輸入的文字串轉換成機器能理解的數字資訊,這里就用到了文本編碼器 text encoder(藍色模塊),可以把文字轉換成計算機能理解的某種數學表示,它的輸入是文字串,輸出是一系列具有輸入文字資訊的語意向量,有了這個語意向量,就可以作為后續圖片生成器 image generator(粉黃組合框)的一個控制輸入,這也是 stable diffusion 技術的核心模塊,圖片生成器,可以分成兩個子模塊(粉色模塊+黃色模塊)來介紹,下面介紹下 stable diffusion 運行時用的主要模塊:
(1) 文本編碼器(藍色模塊),功能是把文字轉換成計算機能理解的某種數學表示,在第三部分會介紹文本編碼器是怎么訓練和如何理解文字,暫時只需要了解文本編碼器用的是 CLIP 模型,它的輸入是文字串,輸出是一系列包含文字資訊的語意向量,
(2) 圖片資訊生成器(粉色模塊),是 stable diffusion 和 diffusion 模型的區別所在,也是性能提升的關鍵,有兩點區別:
① 圖片資訊生成器的輸入輸出均為低維圖片向量(不是原始圖片),對應上圖里的粉色 44 方格,同時文本編碼器的語意向量作為圖片資訊生成器的控制條件,把圖片資訊生成器輸出的低維圖片向量進一步輸入到后續的圖片解碼器(黃色)生成圖片,(注:原始圖片的解析度為 512512,有RGB 三通道,可以理解有 RGB 三個元素組成,分別對應紅綠藍;低維圖片向量會降低到 64*64 維度)
② Diffusion 模型一般都是直接生成圖片,不會有中間生成低維向量的程序,需要更大計算量,在計算速度和資源利用上都比不過 stable diffusion;
那低維空間向量是如何生成的?是在圖片資訊生成器里由一個 Unet 網路和一個采樣器演算法共同完成,在 Unet 網路中一步步執行生成程序,采樣器演算法控制圖片生成速度,下面會在第三部分詳細介紹這兩個模塊,Stable Diffusion 采樣推理時,生成迭代大約要重復 30~50 次,低維空間變數在迭代程序中從純噪聲不斷變成包含豐富語意資訊的向量,圖片資訊生成器里的回圈標志也代表著多次迭代程序,
(3) 圖片解碼器(黃色模塊),輸入為圖片資訊生成器的低維空間向量(粉色 4*4 方格),通過升維放大可得到一張完整圖片,由于輸入到圖片資訊生成器時做了降維,因此需要增加升維模塊,這個模塊只在最后階段進行一次推理,也是獲得一張生成圖片的最終步驟,
那擴散程序發生了什么?
-
擴散程序發生在圖片資訊生成器中,把初始純噪聲隱變數輸入到 Unet 網路后結合語意控制向量,重復 30~50 次來不斷去除純噪聲隱變數中的噪聲,并持續向隱向量中注入語意資訊,就可以得到一個具有豐富語意資訊的隱空間向量(右下圖深粉方格),采樣器負責統籌整個去噪程序,按照設計模式在去噪不同階段中動態調整 Unet 去噪強度, -
更直觀看一下,如圖 3 所示,通過把初始純噪聲向量和最終去噪后的隱向量都輸到后面的圖片解碼器,觀察輸出圖片區別,從下圖可以看出,純噪聲向量由于本身沒有任何有效資訊,解碼出來的圖片也是純噪聲;而迭代 50 次去噪后的隱向量已經耦合了語意資訊,解碼出來也是一張包含語意資訊的有效圖片,

到這里,我們大致介紹了 Stable Diffusion 是什么以及各個模塊思路,并且簡單介紹了 stable diffusion 的擴散程序,第三部分我們繼續分析各個重要組成模塊的運行機制,更深入理解 Stable Diffusion 作業原理,
三 模塊分析
第二部分以零基礎角度介紹了 Stable Diffusion 技術思路,這部分會更細致地介紹下 Stable Diffusion 文生圖技術,訓練階段和采樣階段的總體框架如圖 4 所示,可以劃分成 3 個大模塊:PART1-CLIP 模型,PART2-Unet 訓練,PART3-采樣器迭代,

訓練階段,包含了圖里 PART1 CLIP 模型和 PART2 Unet 訓練,分成三步:
1、用 AutoEncoderKL 自編碼器把輸入圖片從像素空間映射到隱向量空間,把 RGB 圖片轉換到隱式向量表達,其中,在訓練 Unet 時自編碼器引數已經訓練好和固定的,自編碼器把輸入圖片張量進行降維得到隱向量,
2、用 FrozenCLIPEmbedder 文本編碼器來編碼輸入提示詞 Prompt,生成向量表示 context,這里需要規定文本最大編碼長度和向量嵌入大小,
3、對輸入影像的隱式向量施加不同強度噪聲,再把加噪后隱向量輸入到 UNetModel 來輸出預估噪聲,和真實噪聲資訊標簽作比較來計算 KL 散度 loss,并通過反向傳播演算法更新 UNetModel 模型引數;引入文本向量 context 后,UNetModel 在訓練時把其作為 condition,利用注意力機制來更好地引導影像往文本向量方向生成;
采樣階段,包含了圖里 PART1 CLIP 模型和 PART3 采樣器迭代,分成三步:
1、用 FrozenCLIPEmbedder 文本編碼器把輸入提示詞 Prompt 進行編碼,生成維度為[B, K, E]的向量表示 context,與訓練階段的第 2 步一致;
2、利用隨機種子隨機產出固定維度的噪聲隱空間向量,利用訓練好的 UNetModel 模型,結合不同采樣器(如 DDPM/DDIM/PLMS)迭代 T 次不斷去除噪聲,得到具有文本資訊的隱向量表征;
3、用 AutoEncoderKL 自編碼器把上面得到的影像隱向量進行解碼,得到被映射到像素空間的生成影像,
上面對 stable diffusion 總體架構進行了介紹,那接下來進一步分析介紹下每個重要組成模塊,分別是 Unet 網路、采樣器和 CLIP 模型三個主要模塊,
1 Unet 網路
Stable Diffusion 里采用的 UNetModel 模型,采用 Encoder-Decoder 結構來預估噪聲,網路結構如圖 5:
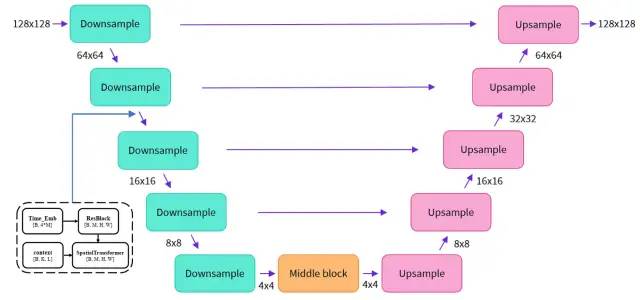
模型輸入包括 3 個部分,(1) 影像表示,用隱空間向量輸入的維度為[B, Z, H/8, W/8];(2) timesteps 值,維度為[B, ];(3) 文本向量表示 context,維度為[B, K, E],其中[B, Z, H, W]分別表示[batch_size 圖片數,C 隱空間通道數,height 長度,weight 寬度],K 和 E 分別表示文本最大編碼長度 max length 和向量嵌入大小,
模型使用 DownSample 和 UpSample 進行樣本的下上采樣,在采樣模塊之間還有黑色虛線框的 ResBlock 和 SpatialTransformer,分別接收 timesteps 資訊和提示詞資訊(這里只畫出一次作為參考),ResBlock 模塊的輸入有 ① 來自上一個模塊的輸入和 ②timesteps 對應的嵌入向量 timestep_emb(維度為[B, 4*M],M 為可配置引數);SpatialTransformer 模塊的輸入有 ① 來自上一個模塊的輸入和 ② 提示詞 Prompt 文本的嵌入表示 context,以 context 為注意力機制里的 condition,學習提示詞 Prompt 和影像的匹配程度,最后,UNetModel 不改變輸入和輸出大小,隱空間向量的輸入輸出維度均為[B, Z, H/8, W/8],
ResBlock 網路
ResBlock 網路,有兩個輸入分別是 ① 來自上一個模塊的輸入和 ②timesteps 對應的嵌入向量 timestep_emb(維度為[B, 4*M],M 為可配置引數),網路結構圖如下所示,
timestep_embedding 的生成方式,用的是“Attention is All you Need”論文的 Transformer 方法,通過 sin 和 cos 函式再經過兩個 Linear 進行變換,

SpatialTransformer 結構
SpatialTransformer 這里,包含模塊比較多,有兩個輸入分別是 ① 來自上一個模塊的輸入和 ② 提示詞 Prompt 文本的嵌入表示 context 作為 condition,兩者使用 cross attention 進行建模,其中,SpatialTransformer 里面的注意力模塊 CrossAttention 結構,把影像向量作為 Query,文本表示 context 作為 Key&Value,利用 Cross Attention 模塊來學習影像和文本對應內容的相關性,
注意力模塊的作用是,當輸入提示詞來生成圖片時,比如輸入 “一匹馬在吃草”,由于模型已經能捕捉圖文相關性以及文本中的重點資訊,當看到 “馬”時,注意力機制會重點突出影像“馬”的生成;當看到“草”時,注意力機制會重點突出影像 “草” 的生成,進而實作和文本匹配的圖片生成,

Unet 如何訓練?
Stable Diffusion 里面 Unet 的學習目標是什么?簡單來說就是去噪,那在為去噪任務設計訓練集時,就可以通過向普通照片添加噪聲來得到訓練樣本,具體來說,對于下面這張照片,用 random 函式生成從強到弱的多個強度噪聲,比如圖 8 里 0~3 有 4 個強度的噪聲,訓練時把噪聲強度和加噪后圖片輸入到 Unet,計算預測噪聲圖和真正噪聲圖之間的誤差損失,通過反向傳播更新 unet 引數,

訓練好 Unet 后,如圖 9 所示,從加噪圖片中推斷出噪聲后,就可以用加噪圖減掉噪聲來恢復原圖;重復這個程序,第一步預測噪聲圖后再減去噪聲圖,用更新后的加噪圖進行第二步去噪,最終就能得到一張很清晰的生成圖片,由于使用了高斯分布的 KL 散度損失,Unet 生成圖片實際上是接近訓練集分布的,和訓練集有著相同像素規律,也就是說,使用真實場景的寫實訓練集去訓練模型,它的結果就會具有寫實風格,盡量符合真實世界規律,

2 采樣器迭代
這部分介紹下采樣階段中擴散模型如何多次迭代去除噪聲,進而得到生成圖片的潛在空間表示,提到采樣器,要從最基礎的采樣器 DDPM(Denoising Diffusion Probabilistic Models)進行介紹[4],DDPM 推導有點復雜,這里就用樸素一點的大白話結合幾個關鍵公式來理清推導思路,
1 擴散模型的思路是,訓練時先在圖片上不斷加噪來破壞圖片,推理時對加噪后的圖片去噪來恢復出原始圖片,訓練程序的 T 次迭代中,可推匯出一個重要特性:任意時刻的 Xt 可以由 X0 和 β 表示,任意時刻的 X0 也可以由 Xt 和噪聲 z 求得,
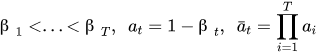
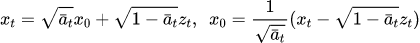
其中,第一行里 a 和 β 可以描述噪聲強度;第二行,X0 為初始的干凈圖片,增加噪聲 z 后生成加噪圖片 Xt,后個公式由前個公式變換而來,表示加噪圖片減去一定強度噪聲,得到圖片 X0,
2 問題變成,如何求逆向階段的分布,即給定了一張加噪后圖片,如何才能求得前一時刻沒有被破壞得那么嚴重的略清晰圖片,經過論文里的一頓推導,又得出兩個重要結論:
① 逆向程序也服從高斯分布;② 在知道原始清晰圖片時,能通過貝葉斯公式把逆向程序轉換成前向程序,進而算出逆向程序分布,在公式上體現如下:
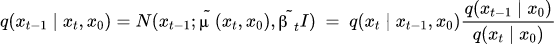
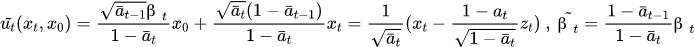
其中,第一行指的是給定 X0 情況下,逆向程序也服從高斯分布,并且利用貝葉斯公式把逆向程序轉換成前向程序,前向程序是不斷加噪的程序,可以被計算;第二行指的是,Xt 和 X0 由于可以相互轉換,從公式上看,均值也可以從 Xt 減去不同噪聲得到,
3 算出逆向程序分布后,就可以訓練一個模型盡量擬合這個分布,而且模型預估結果也應該服從高斯分布:
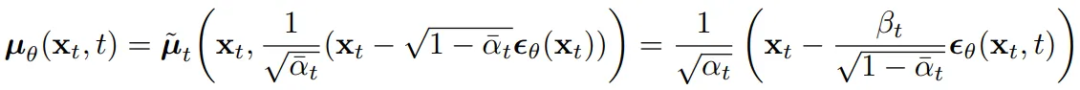
其中,求均值公式里只包含 Xt 和噪聲,由于 Xt 在訓練時已知,那只需要得到模型輸出的預估噪聲,該值可由模型用 Xt 和 t 預估得到,
4 把逆向程序分布(也就是 Label 值)和模型的預估分布做比較,由于 ①KL 散度可以用來描述兩個分布之間的差異和 ② 多元高斯分布的 KL 散度有閉式解,經過一番推導發現損失函式變成計算兩個高斯分布的 KL 散度,
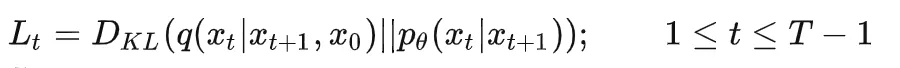
其中,q 分布是逆向程序分布,p 是模型預估分布,訓練損失是求兩個高斯分布的 KL 散度,即兩個分布之間的差距,
5 DDPM 訓練程序和采樣程序的偽代碼如下圖所示,由于 DDPM 的高質量生成依賴于較大的 T(一般為 1000 以上),導致 Diffusion 前向程序特別緩慢,因此后續進一步有了 DDIM、PLMS 和 Euler A 等一些優化版采樣器,

其中,訓練階段實際上是求真實噪聲和模型預估噪聲的 MSE 誤差,再對 Loss 求導反向傳播來訓練模型;采樣階段,求得均值和方差后,采用重引數技巧來生成樣本,
總結下,擴散模型采樣階段是對加噪后圖片去噪來恢復出原始圖片,基于 ① 任意時刻的圖片均可以由原始圖片和噪聲表示;② 逆向程序的圖片引數符合高斯分布,優化目標轉化為計算逆向分布和預估分布的 KL 散度差異,并在采樣階段使用重引數技巧來生成圖片,
3 CLIP 模型
在前面有提到,提示詞 Prompt 文本利用文本模型轉換成嵌入表示 context,作為 Unet 網路的 condition 條件,那問題來了,語意資訊和圖片資訊屬于兩種模態,怎么用 attention 耦合到一起呢?這里介紹下用于提取語意資訊的 CLIP 模型,
語意資訊的好壞直接影響到了最終生成圖片的多樣性和可控性,那像 CLIP 這樣的語言模型是如何訓練出來的?是如何結合文本串和計算機視覺的呢?首先,要有一個具有文本串和計算機視覺配對的資料集,CLIP 模型所使用的訓練集達到了 4 億張,通過從網路上爬取圖片及相應的標簽或者注釋,

CLIP 模型結構包含一個圖片 encoder 和一個文字 encoder,類似于推薦場景常用到的經典雙塔模型,
-
訓練時,從訓練集隨機取出一些樣本(圖片和標簽配對的話就是正樣本,不匹配的話就是負樣本),CLIP 模型的訓練目標是預測圖文是否匹配; -
取出文字和圖片后,用圖片 encoder 和文字 encoder 分別轉換成兩個 embedding 向量,稱作圖片 embedding 和文字 embedding; -
用余弦相似度來比較兩個 embedding 向量相似性,并根據標簽和預測結果的匹配程度計算損失函式,用來反向更新兩個 encoder 引數, -
在 CLIP 模型完成訓練后,輸入配對的圖片和文字,這兩個 encoder 就可以輸出相似的 embedding 向量,輸入不匹配的圖片和文字,兩個 encoder 輸出向量的余弦相似度就會接近于 0,
推理時,輸入文字可以通過一個 text encoder 轉換成 text embedding,也可以把圖片用 image encoder 轉換成 image embedding,兩者就可以相互作用,在生成圖片的采樣階段,把文字輸入利用 text encoder 轉換成嵌入表示 text embedding,作為 Unet 網路的 condition 條件,

四 本文小結
AI 繪畫各種應用不斷涌現,目前有關 Stable Diffusion 的文章主要偏向應用介紹,對于 Stable Diffusion 技術邏輯的介紹還是比較少,這篇文章主要介紹了 Stable Diffusion 技術結構和各個重要組成模塊的基本原理,希望能夠讓大家了解 Stable Diffusion 是如何運行的,才能更好地控制 AI 繪畫生成,AI 繪畫雖然還面臨一些技術挑戰,但隨著技術不斷迭代和發展,相信 AI 能夠在更多領域發揮出驚喜生產力,
(本文參考了 stable diffusion 官方倉庫以及一些解讀 Blog,結合個人在其他 ML 領域經驗的一些解讀,如有不合理的地方,歡迎在評論區指出,)
參考鏈接
1 GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model
2 The Illustrated Stable Diffusion:The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time.
3 由淺入深了解 Diffusion Model
4 Denoising Diffusion Probabilistic Models
作者:symon
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/Principle-of-Stable-Diffusion-Operation.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/552333.html
標籤:其他
上一篇:民謠女神唱流行,基于AI人工智能so-vits庫訓練自己的音色模型(葉蓓/Python3.10)
下一篇:返回列表