1 導引
1.1 域泛化
域泛化(domain generalization, DG) [1][2]旨在從多個源域中學習一個能夠泛化到未知目標域的模型,形式化地說,給定\(K\)個訓練的源域資料集\(\mathcal{S}=\left\{\mathcal{S}^k \mid k=1, \cdots, K\right\}\),其中第\(k\)個域的資料被表示為\(\mathcal{S}^k = \left\{\left(x_i^k, y_i^k\right)\right\}_{i=1}^{n^k}\),這些源域的資料分布各不相同:\(P_{X Y}^k \neq P_{X Y}^l, 1 \leq k \neq l \leq K\),域泛化的目標是從這\(K\)個源域的資料中學習一個具有強泛化能力的模型:\(f: \mathcal{X}\rightarrow \mathcal{Y}\),使其在一個未知的測驗資料集\(\mathcal{T}\)(即\(\mathcal{T}\)在訓練程序中不可訪問且\(P_{X Y}^{\mathcal{T}} \neq P_{X Y}^i \text { for } i \in\{1, \cdots, K\}\))上具有最小的誤差:
\[\min _{f} \mathbb{E}_{(x, y) \in \mathcal{T}}[\ell(f(x), y)] \]這里\(\mathbb{E}\)和\(\ell(\cdot, \cdot)\)分別為期望和損失函式,域泛化示意圖如下圖所示:
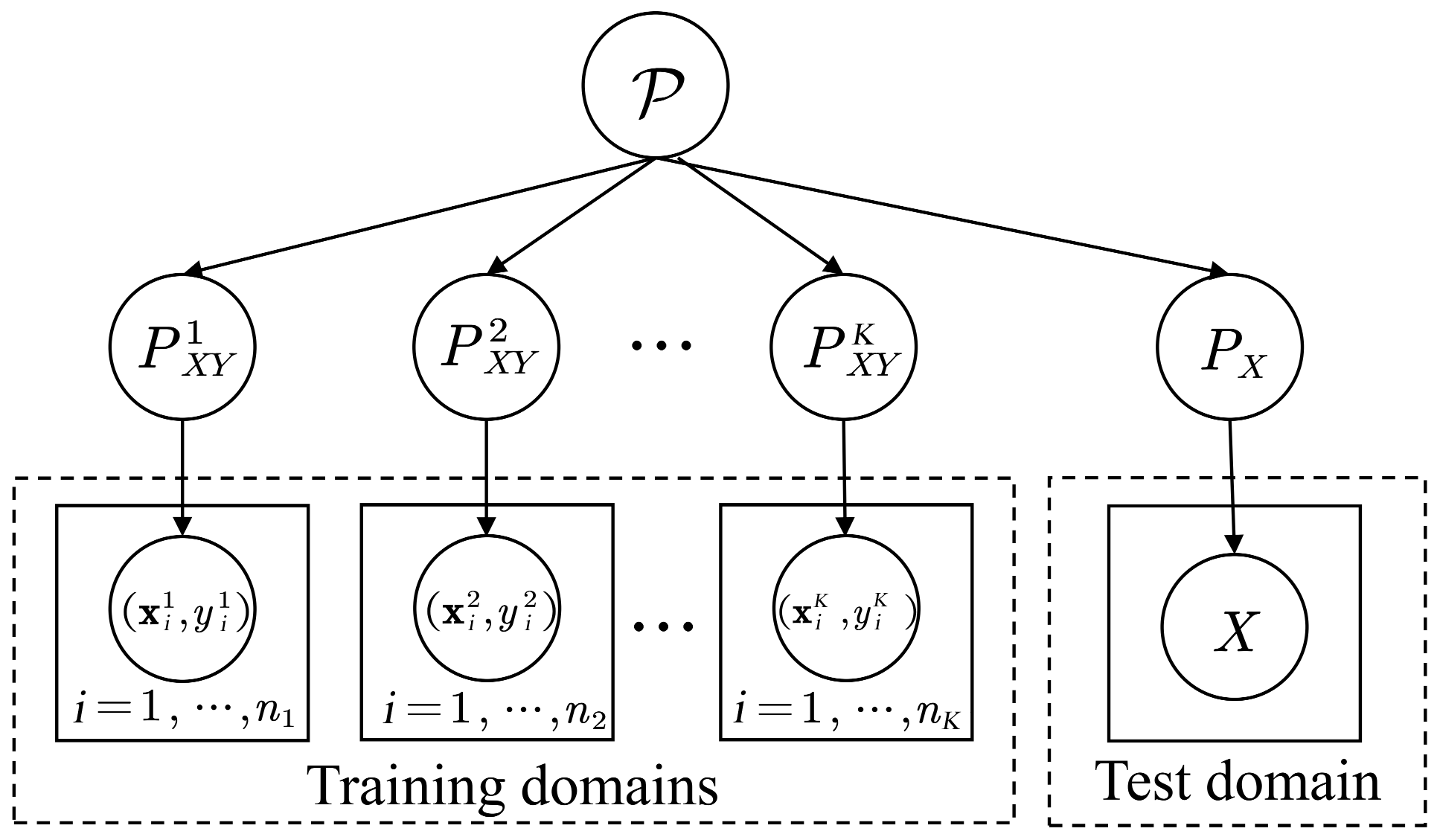
目前為了解決域泛化中的域漂移(domain shift) 問題,已經提出了許多方法,大致以分為下列三類:
-
資料操作(data manipulation) 這種方法旨在通過資料增強(data augmentation)或資料生成(data generation)方法來豐富資料的多樣性,從而輔助學習更有泛化能力的表征,其中資料增強方法常利用資料變換、對抗資料增強(adversarial data augmentation)[3]等手段來增強資料;資料生成方法則通過Mixup(也即對資料進行兩兩線性插值)[4]等手段來生成一些輔助樣本,
-
表征學習(representation learning) 這種方法旨在通過學習領域不變表征(domain-invariant representations),或者對領域共享(domain-shared)和領域特異(domain-specific)的特征進行特征解耦(feature disentangle),從而增強模型的泛化性能,該類方法我們在往期博客《尋找領域不變數:從生成模型到因果表征 》和《跨域推薦:嵌入映射、聯合訓練和解耦表征》中亦有詳細的論述,其中領域不變表征的學習手段包括了對抗學習[5]、顯式表征對齊(如優化分布間的MMD距離)[6]等等,而特征解耦則常常通過優化含有互資訊(資訊瓶頸的思想)或KL散度[7]的損失項來達成,其中大多數會利用VAE等生成模型,
-
學習策略(learning stategy) 這種方法包括了集成學習[8]、元學習[9]等學習范式,其中,以元學習為基礎的方法則利用元學習自發地從構造的任務中學習元知識,這里的構造具體而言是指將源域資料集\(\mathcal{S}\)按照域為單位來拆分成元訓練(meta-train)部分\(\bar{\mathcal{S}}\)和元測驗(meta-test)部分\(\breve{\mathcal{S}}\)以便對分布漂移進行模擬,最終能夠在目標域\(\mathcal{T}\)的final-test中取得良好的泛化表現,
1.2 聯邦域泛化
然而,目前大多數域泛化方法需要將不同領域的資料進行集中收集,然而在現實場景下,由于隱私性的考慮,資料常常是分布式收集的,因此我們需要考慮聯邦域泛化(federated domain generalization, FedDG) 方法,形式化的說,設\(\mathcal{S}=\left\{\mathcal{S}^1, \mathcal{S}^2, \ldots, \mathcal{S}^K\right\}\)表示在聯邦場景下的\(K\)個分布式的源域資料集,每個源域資料集包含資料和標簽對\(\mathcal{S}^k=\left\{\left(x_i^k, y_i^k\right)\right\}_{i=1}^{n^k}\),采樣自域分布\(P_{X Y}^k\),聯邦域泛化的目標是利用\(K\)個分布式的源域學習模型\(f_\theta: \mathcal{X} \rightarrow \mathcal{Y}\),該模型能夠泛化到未知的測驗域\(\mathcal{T}\),聯邦域泛化的架構如下圖所示:
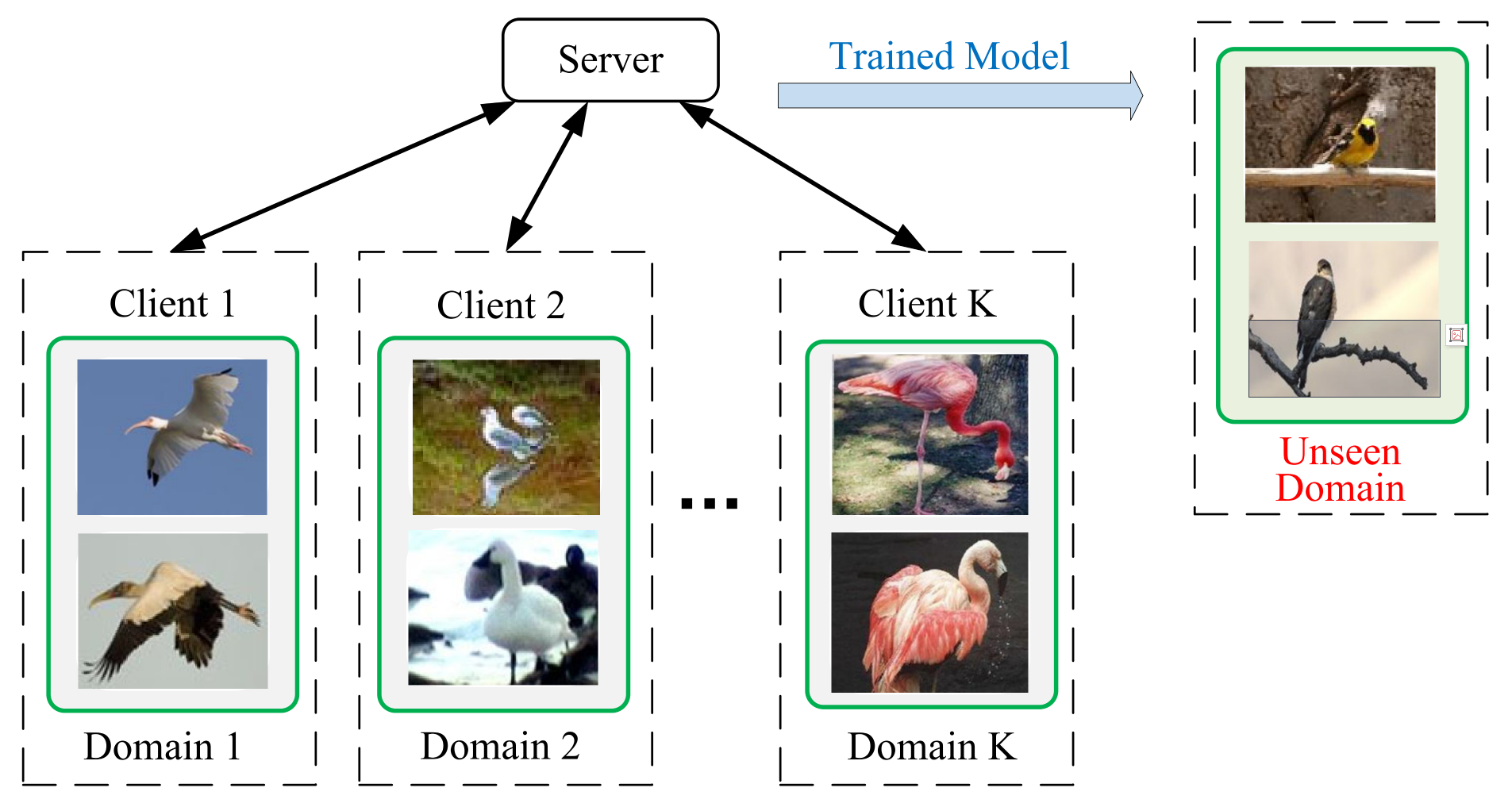
這里需要注意的是,傳統的域泛化方法常常要求直接對齊表征或操作資料,這在聯邦場景下是違反資料隱私性的,此外對于跨域的聯邦學習,由于客戶端異構的資料分布/領域漂移(如不同的影像風格)所導致的模型偏差(bias),直接聚合本地模型的引數也會導致次優(sub-optimal)的全域模型,從而更難泛化到新的目標域,因此,許多傳統域泛化方法在聯邦場景下都不太可行,需要因地制宜進行修改,下面試舉幾例:
-
對于資料操作的方法,我們常常需要用其它領域的資料來對某個領域的資料進行增強(或進行新資料的插值生成),而這顯然違反了資料隱私,目前論文的解決方案是不直接傳資料,而傳資料的統計量來對資料進行增強[10],這里的統計量指圖片的style(即圖片逐通道計算的均值和方差)等等,
-
對于表征學習的方法,也需要在對不同域的表征進行共享/對比的條件下獲得領域不變表征(或對表征進行分解),而傳送表征事實上也違反了資料隱私,目前論文采用的解決方案包括不顯式對齊表征,而是使得所有領域的表征顯式/隱式地對齊一個參考分布(reference distribution)[11][12],這個參考分布可以是高斯,也可以由GAN來自適應地生成,
-
基于學習策略的方法,如元學習也需要利用多個域的資料來構建meta-train和meta-test,并進行元更新(meta-update),而這也違反了資料隱私性,目前論文的解決方案是使用來自其它域的變換后資料來為當前域構造元學習資料集[13],這里的變換后資料指影像的幅度譜等等,
2 論文閱讀
2.1 CVPR21《FedDG: Federated Domain Generalization on Medical Image Segmentation via Episodic Learning in Continuous Frequency Space》[13]
本篇論文是聯邦域泛化的第一篇作業,這篇論文屬于基于學習策略(采用元學習)的域泛化方法,并通過傳影像的幅度譜(amplitude spectrum),而非影像資料本身來構建本地的元學習任務,從而保證聯邦場景下的資料隱私性,本文方法的框架示意圖如下:
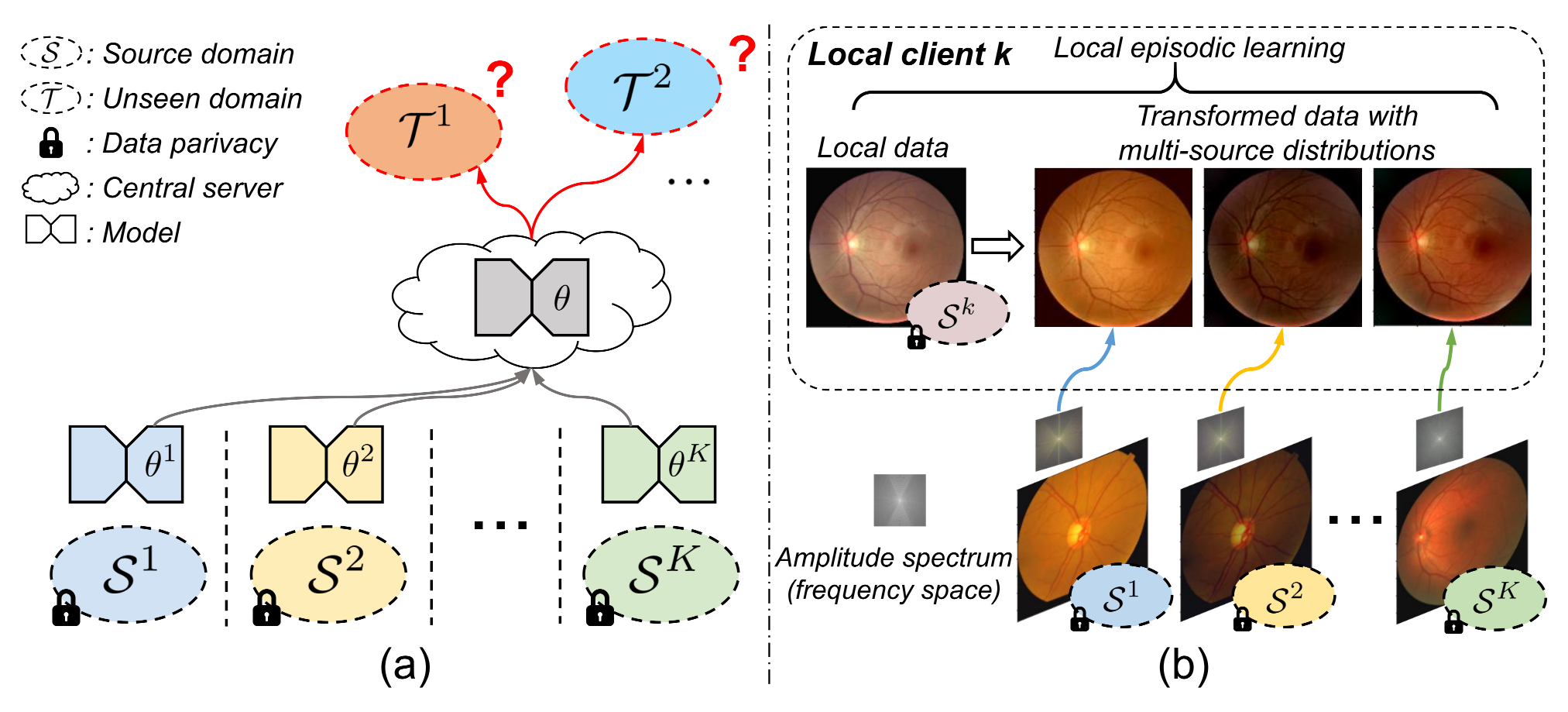
這里\(K\)為領域/客戶端的個數,該方法使影像的低級特征——幅度譜在不同客戶端間共享,而使高級語意特征——相位譜留在本地,這里再不同客戶端間共享的幅度譜就可以作為多領域/多源資料分布供本地元學習訓練使用,
接下來我們看本地的元學習部分,元學習的基本思想是通過模擬訓練/測驗資料集的領域漂移來學得具有泛化性的模型引數,而在本文中,本地客戶端的領域漂移來自不同分布的頻率空間,具體而言,對每輪迭代,我們考慮本地的原輸入圖片\(x_{i}^k\)做為meta-train,它的訓練搭檔\(\mathcal{T}_i^{k}\)則由來自其它客戶端的頻域產生,做為meta-test來表示分布漂移,
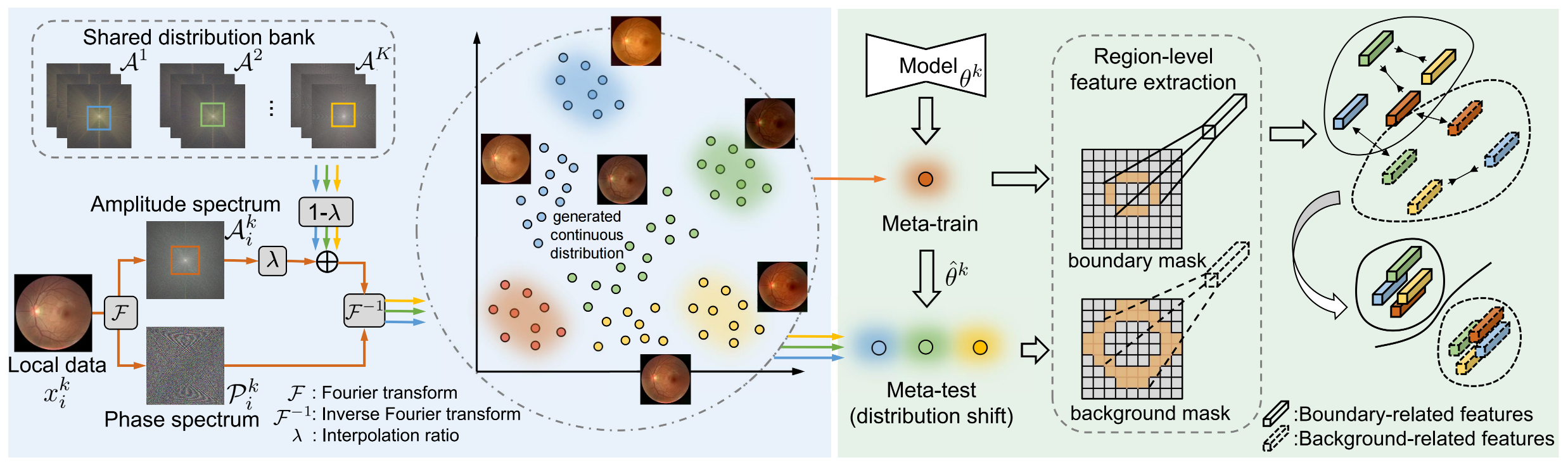
設客戶端\(k\)中的圖片\(x^k_i\)由正向傅里葉變換\(\mathcal{F}\)得到的幅度譜為\(\mathcal{A}_i^k \in \mathbb{R}^{H \times W \times C}\),相位譜為\(\mathcal{P}_i^k \in \mathbb{R}^{H \times W \times C}\)(\(C\)為圖片通道數),本文欲在客戶端之間交換低級分布也即幅度譜資訊,因此需要先構建一個供所有客戶端共享的distribution bank \(\mathcal{A} = [\mathcal{A}^1, \cdots, \mathcal{A}^K]\),這里\(A^k = {\{\mathcal{A}^k_i\}}^{n^k}_{i=1}\)包含了來自第\(k\)個客戶端所有圖片的幅度譜資訊,可視為代表了\(\mathcal{X}^k\)的分布,
之后,作者通過在頻域進行連續插值的手段,將distribution bank中的多源分布資訊送到本地客戶端,如上圖所示,對于第\(k\)個客戶端的圖片幅度譜\(\mathcal{A}_i^{k}\),我們會將其與另外\(K-1\)個客戶端的幅度譜進行插值,其中與第\(l(l\neq k)\)個外部客戶端的圖片幅度譜\(\mathcal{A}_j\)插值的結果表示為:
\[\mathcal{A}_{i}^{k \rightarrow l}=(1-\lambda) \mathcal{A}_i^k *(1-\mathcal{M})+\lambda \mathcal{A}_j^l * \mathcal{M} \]這里\(\mathcal{M}\)是一個控制幅度譜內低頻成分比例的二值掩碼,\(\lambda\)是插值率,然后以此通過反向傅里葉變換生成變換后的圖片:
\[x_{i}^{k \rightarrow l}=\mathcal{F}^{-1}\left(\mathcal{A}_{i}^{k \rightarrow l}, \mathcal{P}_i^k\right) \]就這樣,對于第\(k\)個客戶端的輸入圖片\(x^k_i\),我們就得到了屬于不同分布的\(K-1\)個變換后的圖片資料\(\mathcal{T}^k_i = \{x^{k\rightarrow l}_i\}_{l\neq k}\),這些圖片和\(x^k_i\)共享了相同的語意標簽,
接下來在元學習的每輪迭代中,我們將原始資料\(x^k_i\)做為meta-train,并將其對應的\(K-1\)個由頻域產生的新資料\(\mathcal{T}^k_i\)做為meta-test來表示分布漂移,從而完成在當前客戶端的inner-loop的引數更新,
具體而言,元學習范式可以被分解為兩步:
第一步 模型引數\(\theta^k\)在meta-train上通過segmentaion Dice loss \(\mathcal{L}_{seg}\)來更新:
\[\hat{\theta}^k=\theta^k-\beta \nabla_{\theta^k} \mathcal{L}_{s e g}\left(x_i^k ; \theta^k\right) \]這里引數\(\beta\)表示內層更新的學習率,
第二步 在meta-test資料集\(\mathcal{T}^k_i\)上使用元目標函式(meta objective)\(\mathcal{L}_{meta}\)對已更新的引數\(\hat{\theta}^k\)進行進一步元更新,
\[\mathcal{L}_{meta}=\mathcal{L}_{seg}\left(\mathcal{T}_i^k ; \hat{\theta}^k\right)+\gamma \mathcal{L}_{boundary}\left(x_i^k, \mathcal{T}_i^k ; \hat{\theta}^k\right) \]這里特別重要的是,第二步所要優化的目標函式由在第一部中所更新的引數\(\hat{\theta}^k\)計算,最終的優化結果覆寫掉原來的引數\(\theta^k\),
如果我們將一二步合在一起看,則可以視為通過下面目標函式來一起優化關于引數\(\theta^k\)的內層目標函式和元目標函式:
\[\underset{\theta^k}{\arg \min }\space \mathcal{L}_{seg}\left(x_i^k ; \theta^k\right)+\mathcal{L}_{m e t a}\left(x_i^k, \mathcal{T}_i^k ; \hat{\theta}^k\right) \]最后,一旦本地訓練完成,則來自所有客戶端的本地引數\(\theta^k\)會被服務器聚合并更新全域模型,
2.2 Arxiv21《Federated Learning with Domain Generalization 》[12]
本篇論文屬于基于學習領域不變表征的域泛化方法,并通過使所有客戶端的表征對齊一個由GAN自適應生成的參考分布,而非使客戶端之間的表征互相對齊,來保證聯邦場景下的資料隱私性,本文方法整體的架構如下圖所示:

注意,這里所有客戶端共享一個參考分布,而這通過共享同一個分布生成器(distribution generator)來實作,在訓練程序一邊使每個域(客戶端)的資料分布會和參考分布對齊,一邊最小化分布生成器的損失函式,使其產生的參考分布接近所有源資料分布的“中心”(這也就是”自適應“的體現),一旦判別器很難區分從特征提取器中提取的特征和從分布生成器中所生成的特征,此時所提取的特征就被認為是跨多個源域不變的,這里的特征分布生成器的輸入為噪聲樣本和標簽的one-hot向量,它會按照一定的分布(即參考分布)生成特征,最后,作者還采用了隨機投影層來使得判別器更難區分實際提取的特征和生成器生成的特征,使得對抗網路更穩定,在訓練完成之后,參考分布和所有源域的資料分布會對齊,此時學得的特征表征被認為是通用(universal)的,能夠泛化到未知的領域,
接下來我們來看GAN部分具體的細節,設\(F(\cdot)\)為特征提取器,\(G(\cdot)\)為分布生成器,\(D(\cdot)\)為判別器,設由特征提取器所提取的特征\(\mathbf{h} = F(\mathbf{x})\)(資料\(\mathbf{x}\)的生成分布為\(p(\mathbf{h})\)),而由分布生成器所產生的特征為\(\mathbf{h}'= G(\mathbf{z})\)(噪聲\(\mathbf{z}\)的生成分布為\(p(\mathbf{h}')\),我們設特征提取器所提取的特征為負例,生成器所生成的特征為正例,
于是,我們可以將判別器的優化目標定義為使將特征提取器所生成的特征\(\mathbf{h}\)判為正類的概率\(D(\mathbf{h}|\mathbf{y})\)更小,而使將生成器所生成的特征\(\mathbf{h}'\)判為正類的概率\(D(\mathbf{h}'|\mathbf{y})\)更大,
\[\begin{aligned} \mathcal{L}_{a d v \_d}= & -\left(\mathbb{E}_{\mathbf{x} \sim p(\mathbf{h})}\left[\left(1-D(\mathbf{h} \mid \mathbf{y})\right)^2\right]+\mathbb{E}_{\mathbf{z} \sim p\left(\mathbf{h}^{\prime}\right)}\left[D\left(\mathbf{h}^{\prime} \mid \mathbf{y}\right)^2\right]\right) \end{aligned} \]生成器盡量使判別器\(D(\cdot)\)將其生成特征\(\mathbf{h}'\)判別為正類的概率\(D\left(\mathbf{h}^{\prime} \mid \mathbf{y}\right)\)更大,以求以假亂真:
\[\mathcal{L}_{a d v_{-} g}=\mathbb{E}_{\mathbf{z} \sim p\left(\mathbf{h}^{\prime}\right)}\left[\left(1-D\left(\mathbf{h}^{\prime} \mid \mathbf{y}\right)\right)^2\right] \]特征提取器也需要盡量使得其所生成的特征\(\mathbf{h}\)能夠以假亂真:
\[\mathcal{L}_{a d v\_f}=\mathbb{E}_{\mathbf{x} \sim p(\mathbf{h})}\left[(1-D(\mathbf{h} \mid \mathbf{y}))^2\right] \]再加上影像分類本身的交叉熵損失\(\mathcal{L}_{err}\),則總的損失定義為:
\[\mathcal{L}_{F e d A D G}=\mathcal{L}_{a d v\_d}+\mathcal{L}_{a d v\_g}+\lambda_0 \mathcal{L}_{a d v\_f}+\lambda_1 \mathcal{L}_{e r r} \]論文的最后,作者還對一個問題進行了探討:關于這里的參考分布,我們為什么不用一個預先選好的確定的分布,要用一個自適應生成的分布呢?那是因為自適應生成的分布有一個重要的好處,那就是少對齊期間的失真(distortion),作者對多個域/客戶端的分布和參考分布進行了可視化,如下圖所示:

(a)中為參考分布選擇為固定的分布后,與各域特征對比的示意圖,圖(b)為參考分布選擇為自適應生成的分布后,和各域特征對比的示意圖,在這兩幅圖中,紅色五角星表示參考分布的特征,除了五角星之外的每種形狀代表一個域,每種顏色代表一個類別的樣本,可以看到自適應生成的分布和多個源域資料分布的距離,相比固定參考分布和多個源域資料分布的距離更小,因此自適應生成的分布能夠減少對齊期間提取特征表征的失真,而更好的失真也就意味著源域資料的關鍵資訊被最大程度的保留,這讓本文的方法所得到的表征擁有更好的泛化表現,
2.3 NIPS22 《FedSR: A Simple and Effective Domain Generalization Method for Federated Learning》[11]
本篇論文屬于基于學習領域不變表征的域泛化方法,并通過使所有客戶端的表征對齊一個高斯參考分布,而非使客戶端之間的表征互相對齊,來保證聯邦場景下的資料隱私性,本文的動機源于經典機器學習演算法的思想,旨在學習一個“簡單”(simple)的表征從而獲得更好的泛化性能,
首先,作者以生成模型的視角,將表征\(z\)建模為從\(p(z|x)\)中的采樣,然后在此基礎上定義領域\(k\)的分類目標函式以學得表征:
\[\begin{aligned} \overline{f_k}(w) & =\mathbb{E}_{p_k(x, y)}\left[\mathbb{E}_{p(z \mid x)}[-\log \hat{p}(y \mid z)]\right] \\ & \approx \frac{1}{n_k} \sum_{i=1}^{n_k}-\log \hat{p}\left(y_k^{(i)} \mid z_k^{(i)}\right) \end{aligned} \]這里領域\(k\)的樣本表征\(z_j^{(i)}\)通過編碼器+重引數化從\(p(z|x_k^{(i)})\)中采樣產生,
接下來我們來看怎么使得表征更“簡單”,本文采用了兩個正則項,一個是關于表征的\(L2\)正則項來限制表征中所包含的資訊;一個是在給定\(y\)的條件下,\(x\)與\(z\)的條件互資訊\(I(x, z\mid y)\)(的上界)來使表征只學習重要的資訊,而忽視諸如圖片背景之類的偽相關性(spurious correlations),
關于表征\(z\)的\(L2\)正則項定義如下:
\[\begin{aligned} \mathcal{L}_k^{L 2 R} & =\mathbb{E}_{p_k(x)}\left[\mathbb{E}_{p(z \mid x)}\left[\|z\|_2^2\right]\right] \\ & \approx \frac{1}{n_k} \sum_{i=1}^{n_k}\left\|z_k^{(i)}\right\|_2^2a \end{aligned} \]于是,上式的微妙之處在于可以和領域不變表征聯系起來,事實上我們有\(\mathcal{L}_k^{L 2 R}=\mathbb{E}_{p_k(x)}\left[\mathbb{E}_{p(z \mid x)}\left[\|z\|_2^2\right]\right]=\mathbb{E}_{p_k(x, z)}\left[\|z\|_2^2\right]=\mathbb{E}_{p_k(z)}\left[\|z\|_2^2\right]=2 \sigma^2 \mathbb{E}_{p_k(z)}[-\log q(z)]=2 \sigma^2 H\left(p_k(z), q(z)\right)\),這里\(H\left(p_k(z), q(z)\right)=H\left(p_k(z)\right)+ D_{\text{KL}} \left[p_k(z) \Vert q(z)\right]\),參考分布\(q(z)=\mathcal{N}\left(0, \sigma^2 I\right)\),如果\(H(p_i(z))\)在訓練中并未發生大的改變,那么最小化\(l_k^{L2R}\)也就是在最小化\(D_{\text{KL}}[p_k(z) \Vert q(z)]\),也即在隱式地對齊一個參考的邊緣分布\(q(z)\),而這就使得標準的邊緣分布\(p_k(z)\)是跨域不變的,注意該對齊是不需要顯式地比較不同客戶端分布的,
接下來我們來看條件互資訊項,在資訊瓶頸理論中,常對\(x\)和表征\(z\)之間的互資訊項\(I(x, z)\)進行最小化以對\(z\)中所包含的資訊進行加以正則,但是這樣的約束在實踐中如果系數沒調整好,就很可能過于嚴格了,畢竟它迫使表征不包含資料的資訊,因此,在這篇論文中,作者選擇最小化給定\(y\)時\(x\)和\(z\)之間的條件互資訊,領域\(k\)的條件互資訊被計算為:
\[I_k(x, z \mid y)=\mathbb{E}_{p_k(x, y, z)}\left[\log \frac{p_k(x, z \mid y)}{p_k(x \mid y) p_k(z \mid y)}\right] \]直觀地看,\(\bar{f}_k\)和\(I_k(x, z\mid y)\)共同作用,迫使表征\(z\)僅僅擁有預測標簽\(y\)使所包含的資訊,而沒有關于\(x\)的額外(即和標簽無關的)資訊,
然而,這個互資訊項是難解(tractable)的,這是由于計算\(p_k(z|y)\)很難計算(由于需要對\(x\)進行積分將其邊緣化消掉),因此,作者匯出了一個上界來對齊進行最小化:
\[\mathcal{L}_k^{C M I} = \mathbb{E}_{p_k(x, y)}[D_{\text{KL}}[p(z \mid x) \Vert r(z \mid y)]] \geq I_k(x, z \mid y) \]這里\(r(z|y)\)可以是一個輸入\(y\)輸出分布\(r(z|y)\)的神經網路,作者將其設定為高斯\(\mathcal{N}\left(z ; \mu_y, \sigma_y^2\right)\),這里\(u_y\),\(\sigma^2_y\)(\(y=1, 2, \cdots, C\))是需要優化的神經網路引數,\(C\)是類別數量,
事實上,該正則項和域泛化中的條件分布對齊亦有著理論上的聯系,這是因為\( \mathcal{L}_k^{C M I}=\mathbb{E}_{p_k(x, y)}[D_{\text{KL}}[p(z \mid x) \Vert r(z \mid y)]] \geq \mathbb{E}_{p_k(y)}\left[D_{\text{KL}}\left[p_k(z \mid y) \Vert r(z \mid y)\right]\right] \),因此,最小化\(\mathcal{L}_k^{CMI}\)我們必然就能夠最小化\(D_{\text{KL}}\left[p_k(z \mid y) \Vert r(z \mid y)\right]\)(因為\(\mathcal{L}^{CMI}_k\)是其上界),使得\(p_k(z|y)\)和\(r(z|y)\)互相接近,即:\(p_k(z|y)\approx r(z|y)\),因此,模型會嘗試迫使\(p_k(z \mid y) \approx p_l(z \mid y)(\approx r(z \mid y))\)(對任意客戶端/領域\(k, l\)),這也就是說,我們是在做給定標簽\(y\)時表征\(z\)的條件分布的隱式對齊,這在傳統的領域泛化中是一種很常見與有效的技術,區別就是這里不需要顯式地比較不同客戶端的分布,
最后,每個客戶端的總體目標函式可以表示為:
\[\mathcal{L}_k = \overline{f_k}+\alpha^{L 2 R} \mathcal{L}_k^{L 2 R}+\alpha^{C M I} \mathcal{L}_k^{C M I} \]總結一下,這里\(L2\)范數正則項\(\mathcal{L}_k^{L2R}\)和給定標簽時資料和表征的條件互資訊\(\mathcal{L}_k^{CMI}\)(的上界)用于限制表征中所包含的資訊,此外,\(\mathcal{L}_k^{L2R}\)將邊緣分布\(p_k(z)\)對齊到一個聚集在0周圍的高斯分布,而\(\mathcal{L}_i^{CMI}\)則將條件分布\(p_k(z|y)\)對齊到一個參考分布(在實驗環節作者亦將其選擇為高斯),
2.4 WACV23 《Federated Domain Generalization for Image Recognition via Cross-客戶端 Style Transfer》[10]
本篇論文屬于基于資料操作的域泛化方法,并通過構造一個style bank供所有客戶端共享(類似CVPR21那篇),以使客戶端在不共享資料的條件下基于風格(style)來進行資料增強,從而保證聯邦場景下的資料隱私性,本文方法整體的架構如下圖所示:
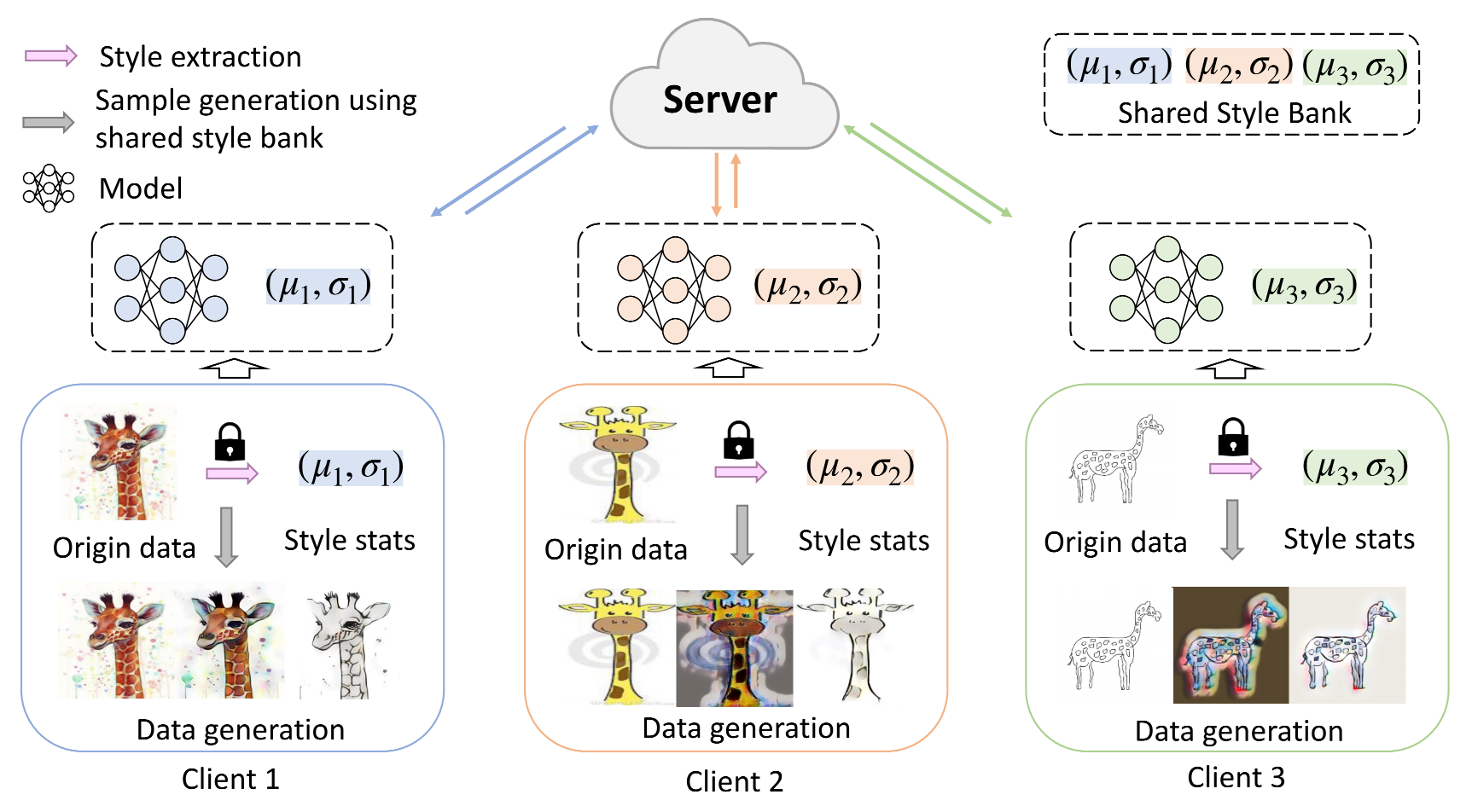
如圖所示,每個client的資料集都有自己的風格,且對于每個客戶端而言,都會接受其余客戶端的風格來進行資料增強,事實上,這樣就可以使得分布式的客戶端在不泄露資料的情況下擁有相似的資料分布 ,在本方法中,所有客戶端的本地模型都擁有一致的學習目標——那就是擬合來自于所有源域的styles,而這種一致性就避免了本地模型之間的模型偏差,從而避免了影響全域模型的效果,此外,本方法可和其它DG的方法結合使用,從而使得其它中心化的DG方法均能得到精度的提升,
關于本文采用的風格遷移模型,有下列要求:1、所有客戶端共享的style不能夠被用來對資料集進行重構,從而保證資料隱私性;2、用于風格遷移的方法需要是一個實時的任意風格遷移模型,以允許高效和直接的風格遷移,本文最終選擇了AdaIN做為本地的風格遷移模型,整個跨客戶端/領域風格遷移流程如下圖所示:

可以看到,整個跨客戶端/領域風格遷移流程分為了三個階段:
1. Local style Computation
每個客戶端需要計算它們的風格并上傳到全域服務器,其中可選擇單張圖片風格(single image style)和整體領域風格(overall domain style )這兩種風格來進行計算,
- 單張圖片風格 單張圖片風格是圖片VGG特征的像素級逐通道(channel-wise)均值和方差,比如我們設在第\(k\)個客戶端上,隨機選取的圖片索引為\(i\),其對應的VGG特征\(F_k^{(i)}=\Phi(I^{(i)}_k)\)(這里的\(I^{(i)}_k\)表示影像內容,\(\Phi\)為VGG的編碼器),單張圖片風格可以被計算為:
如果單張圖片風格被用于風格遷移,那么就需要將該客戶端不同圖片對應的多種風格都上傳到服務器,從而避免單張圖片的偏差并增加多樣性,而這就需要建立本地圖片的style bank \(\mathcal{S}_k^{single}\)并將其上傳到服務器,這里作者隨機選擇\(J\)張影像的style加入了本地style bank:
\[\mathcal{S}_k^{single}=\left\{S_{k}^{(i_1)}, \ldots, S_{k}^{(i_J)}\right\} \]- 整體領域風格 整體領域風格是領域層次的逐通道均值和方差,其中考慮了一個客戶端中的所有圖片,比如我們假設客戶端\(k\)擁有\(N_k\)個訓練圖片和對應的VGG特征\(\{F_k^{(1)}, F_k^{(2)}, \ldots, F_{k}^{(N_k)}\}\),則該客戶端的整體領域風格\(S_k^{overall}\)為:
相比單張圖片風格,整體領域風格的計算代價非常高,不過,由于每個客戶端/領域只有一個領域風格\(S_k^{overall}\),選擇上傳整體領域風格到服務器的通信效率會更高,
2. Style Bank on Server
當服務器接收到來自各個客戶端的風格時,它會將所有風格匯總為一個style bank \(\mathcal{B}\) 并將其廣播回所有客戶端,在兩種不同的風格共享模式下,style bank亦會有所不同,
- 單影像風格的style bank \(\mathcal{B}\)為:
- 整體領域風格的style bank \(\mathcal{B}\)為:
\(\mathcal{B}_{single}\)比\(\mathcal{B}_{overall}\)會消耗更多存盤空間,因此后者會更加通信友好,
3. Local Style Transfer
當客戶端\(k\)收到style bank \(\mathcal{B}\)后,本地資料會通過遷移\(\mathcal{B}\)中的風格來進行增強,而這就將其它領域的風格引入了當前客戶端,作者設定了超引數\(L \in\{1,2, \ldots, K\}\)做為增強級別,意為從style bank \(\mathcal{B}\)中隨機選擇\(L\)個域所對應的風格來對每個圖片進行增強,因此\(L\)表明了增強資料集的多樣性,設第\(k\)個客戶端資料集大小為\(N_k\),則在進行跨客戶端的領域遷移之后,增強后資料集的大小會變為\(N_k \times L\),其中對客戶端\(k\)中的每張圖片\(I^{(i)}_k\),其對應的每個被選中的域都會擁有一個style vector\(S\)被作為影像生成器\(G\)的輸入,這里關于style vector的獲取有個細節需要注意:假設我們選了域\(k\),如果遷移的是整體領域風格,則\(S^{overall}_k\)直接即可做為style vector;如果遷移的是單圖片風格,則還會進一步從選中\(\mathcal{S}^{single}_k\)中隨機選擇一個風格\(S_k^{(i)}\)做為域\(k\)的style vector,對以上兩種風格模式而言,如果一個域被選中,則其對應的風格化圖片就會被直接加入增強后的資料集中,
參考
- [1] Wang J, Lan C, Liu C, et al. Generalizing to unseen domains: A survey on domain generalization[J]. IEEE Transactions on Knowledge and Data Engineering, 2022.
- [2] 王晉東,陳益強. 遷移學習導論(第2版)[M]. 電子工業出版社, 2022.
- [3] Volpi R, Namkoong H, Sener O, et al. Generalizing to unseen domains via adversarial data augmentation[C]. Advances in neural information processing systems, 2018, 31.
- [4] Zhou K, Yang Y, Qiao Y, et al. Domain generalization with mixstyle[C]. ICLR, 2021.
- [5] Li H, Pan S J, Wang S, et al. Domain generalization with adversarial feature learning[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 5400-5409.
- [6] Li Y, Gong M, Tian X, et al. Domain generalization via conditional invariant representations[C]//Proceedings of the AAAI conference on artificial intelligence. 2018, 32(1).
- [7] Ilse M, Tomczak J M, Louizos C, et al. Diva: Domain invariant variational autoencoders[C]//Medical Imaging with Deep Learning. PMLR, 2020: 322-348.
- [8] Qin X, Wang J, Chen Y, et al. Domain Generalization for Activity Recognition via Adaptive Feature Fusion[J]. ACM Transactions on Intelligent Systems and Technology, 2022, 14(1): 1-21.
- [9] Li D, Yang Y, Song Y Z, et al. Learning to generalize: Meta-learning for domain generalization[C]//Proceedings of the AAAI conference on artificial intelligence. 2018, 32(1).
- [10] Chen J, Jiang M, Dou Q, et al. Federated Domain Generalization for Image Recognition via Cross-Client Style Transfer[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2023: 361-370.
- [11] Nguyen A T, Torr P, Lim S N. Fedsr: A simple and effective domain generalization method for federated learning[J]. Advances in Neural Information Processing Systems, 2022, 35: 38831-38843.
- [12] Zhang L, Lei X, Shi Y, et al. Federated learning with domain generalization[J]. arXiv preprint arXiv:2111.10487, 2021.
- [13] Liu Q, Chen C, Qin J, et al. Feddg: Federated domain generalization on medical image segmentation via episodic learning in continuous frequency space[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 1013-1023.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/552378.html
標籤:其他
上一篇:AtCoder Beginner Contest 301
下一篇:返回列表