??踩坑指南——onnx系列
目錄- ??踩坑指南——onnx系列
- ??1:轉onnx時protobuf庫報錯
- ??2:訓練時protobuf庫相關錯
- ??3:torch轉onnx:轉整個模型好?還是轉引數好?
- ??4:如何使python呼叫torch和onnx模型的輸出一致?
- ??5:如何使java、python加載onnx模型的輸出一致?
- 注:
??1:轉onnx時protobuf庫報錯
-
描述:當運行torch轉onnx的代碼時,出現
ImportError: cannot import name 'builder' from 'google.protobuf.internal',如下圖:
-
原因:由于使用的
google.protobuf版本太低而引起的,在較新的版本中,builder模塊已經移動到了google.protobuf包中,而不再在google.protobuf.internal中, -
解決辦法:升級protobuf庫
pip install --upgrade protobuf
??2:訓練時protobuf庫相關錯
-
描述:當運行訓練代碼出現如下錯誤:
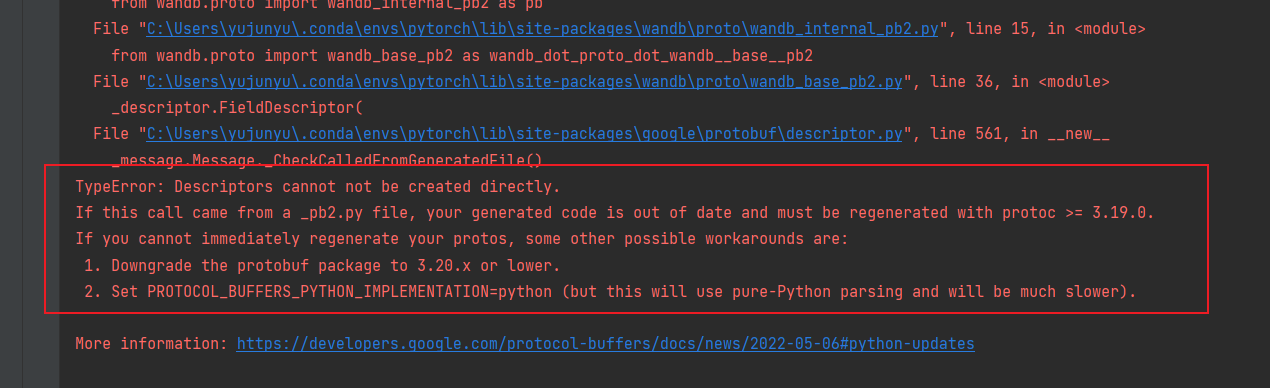
-
原因:由于protobuf
版本太高而引起的,在較新的protobuf版本中,為了改進性能,Descriptor物件的創建方式發生了變化, -
解決辦法:降級protobuf庫
pip install protobuf==3.20.0 -
注:坑1與坑2之間是相互影響的,暫未找到其他更好解決辦法,但目前辦法可以解決相關報錯,只是有些繁瑣,
??3:torch轉onnx:轉整個模型好?還是轉引數好?
-
前提:模型訓練的時候保存的是
torch.save(net, 'model.pth'),還是torch.save(net.state_dict(), 'weight.pth'),前者保存的是整個模型,后者保存的是引數, -
關于torch轉onnx模型,一開始認為轉整個模型比較好是因為考慮了預測時需要重新定義神經網路結構,并且java那邊定義神經網路可能比較復雜,然后就轉整個模型,之后發現不管是轉整個模型還是引數,在python這邊呼叫onnx并預測并不需要重新定義神經網路結構,所以建議訓練的時候只保存引數即可,torch轉onnx時也只轉引數,在轉onnx需加載網路結構,具體torch轉onnx的最小代碼如下:
import torch import torchvision import onnx # 呼叫自定義網路結構 from net import Net # 加載PyTorch模型 model = Net() weight = torch.load('./weight/model.pth') model.load_state_dict(weight) # 設定模型輸入 dummy_input = torch.randn(1, 3, 224, 224) # 匯出ONNX模型 torch.onnx.export(model, dummy_input, 'weight/model.onnx', verbose=True) -
代碼決議:當前代碼轉的是模型引數;
- 第一步:先重新加載定義好的神經網路結構,然后加載model.pth并加載引數;
- 第二步:設定模型輸入,取決于定義的Ne的輸入;
- 第三步:匯出onnx模型,正常情況傳三個引數即可(第一個:模型;第二個:模型輸入;第三個:匯出模型路徑),verbose默認為False,設定為True,會列印模型輸出至onnx的程序,便于確定模型轉成功了,
-
總結:關于torch和onnx后續使用python呼叫并且預測時,轉整個模型還是轉引數是否會導致兩者輸出不一致的結果沒有進行對比驗證,但是基于目前本人踩坑到現在,最終torch和onnx的輸出一致了,使用的正是轉引數,關于torch和onnx的輸出不一致的問題見【??4:如何使python呼叫torch和onnx模型的輸出一致?】,所以總的來說,在torch轉onnx時,還是轉引數就行,畢竟在訓練的時候只保存引數會比保存整個模型更快,何為不好呢?
??4:如何使python呼叫torch和onnx模型的輸出一致?
-
描述:在python開發這邊,訓練完模型后,并將torch模型轉onnx模型后,使用python加載torch模型和onnx模型進行預測同一張圖片,列印模型輸出及softmax后的輸出,出現嚴重不一致,按理來說同一個模型不同格式,最終輸出一個保持一致,
-
原因:python預測的時候transforms.Resize()內的插值,與onnx中cv2.resize()內的插值不一致,
-
解決辦法:
-
辦法1:將onnx中resize操作使用transfroms.Resize(),確保torch和onnx模型進行預測中的resize確保一致(還得保證訓練時預處理的resize,三者保持一致),且resize內的interpolation插值型別一致,
-
如圖:onnx中使用transfroms.Resize(),輸出如下:

-
如圖:torch不變,使用transforms.Resize(),輸出如下:

-
-
辦法2:將torch中的resize操作使用cv2.resize(),將torch的transforms.Resize()重寫,把里面的resize改成cv2的resize;(詳見 ??5:如何使java、python加載onnx模型的輸出一致?)
-
總結:確保python中【訓練時預處理的resize】、【torch模型預測時的resize】、【onnx模型預測時的resize】中的插值方法保持一致,
??5:如何使java、python加載onnx模型的輸出一致?
-
描述:在??五中已經解決了python中呼叫torch和onnx模型預測的輸出一致,但是為了和java對接上,需要保證【python呼叫onnx模型預測的輸出】和【Java呼叫onnx模型預測的輸出】保持一致,如何保持一致?一開始java那邊使用的opencv的resize,python這邊使用的是transforms.Resize(),但是運行結果仍不一致,盡管是transforms.Resize()中使用的是的插值法是
Resize(shape,interpolation=InterpolationMode.BILINEAR),java那邊使用的是cv2.INTER_LINEAR,雖然兩者都線性,前者為雙線性,后者為線性,但是最終輸出結果會有出入; -
原因:java的cv2.resize和python的transforms.Resize中的插值方法不一樣;
-
解決辦法:將torch中的resize操作使用cv2.resize(),
-
1)重寫Resize:
import torch import numpy as np from PIL import Image import cv2 from collections.abc import Sequence class CV2_Resize(torch.nn.Module): def __init__(self, size, interpolation=cv2.INTER_LINEAR, max_size=None, antialias=None): super().__init__() if not isinstance(size, (int, Sequence)): raise TypeError(f"Size should be int or sequence. Got {type(size)}") if isinstance(size, Sequence) and len(size) not in (1, 2): raise ValueError("If size is a sequence, it should have 1 or 2 values") self.size = size self.max_size = max_size self.interpolation = interpolation self.antialias = antialias def forward(self, img): if isinstance(img, torch.Tensor): img = img.permute(1, 2, 0).cpu().numpy() img = cv2.resize(img, self.size[::-1], interpolation=self.interpolation) img = torch.from_numpy(img).permute(2, 0, 1) else: img = np.array(img) img = cv2.resize(img, self.size[::-1], interpolation=self.interpolation) img = Image.fromarray(img) if self.max_size is not None: w, h = img.size if w > h: new_w = self.max_size new_h = int(h * (self.max_size / w)) else: new_h = self.max_size new_w = int(w * (self.max_size / h)) img = img.resize((new_w, new_h), resample=Image.BILINEAR) return img def __repr__(self) -> str: detail = f"(size={self.size}, interpolation={self.interpolation}, max_size={self.max_size}, antialias={self.antialias})" return f"{self.__class__.__name__}{detail}" -
2)然后在訓練時預處理使用重寫的Resize,重新訓模型:
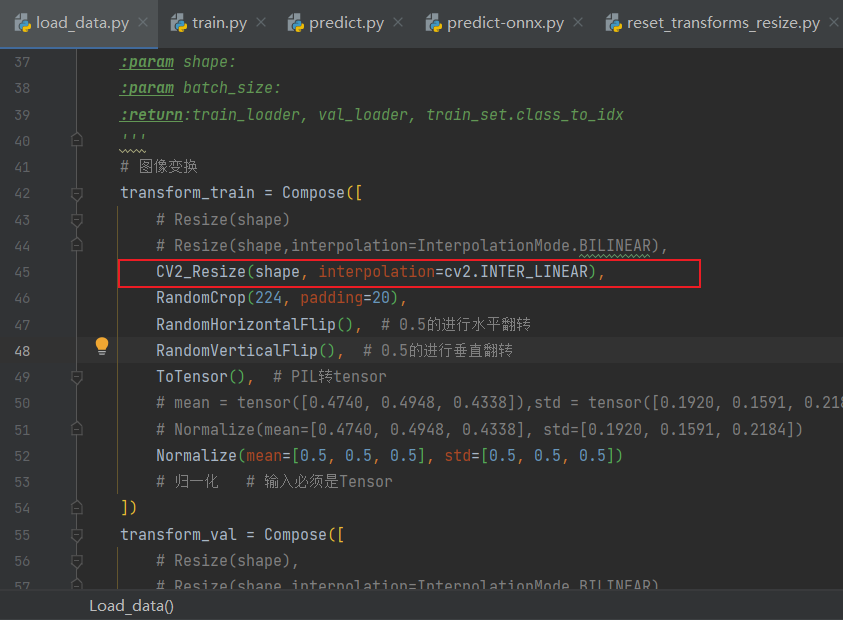
-
3)訓好轉onnx后,使用python加載onnx模型并預測,輸出結果,但下面使用的是重寫的Resize:
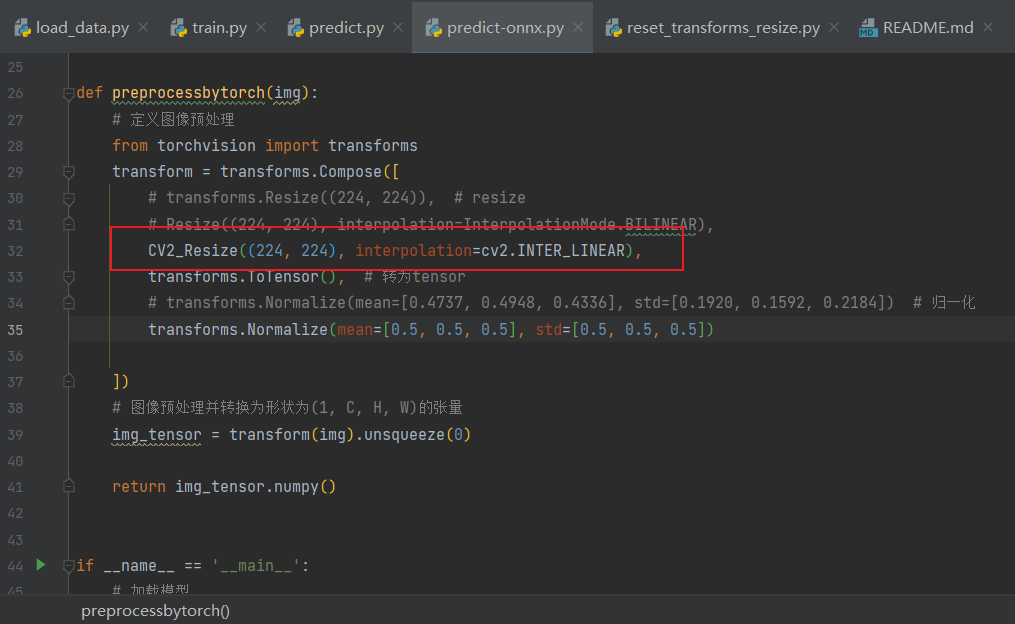

-
4)使用java加載onnx模型并預測,輸出結果:
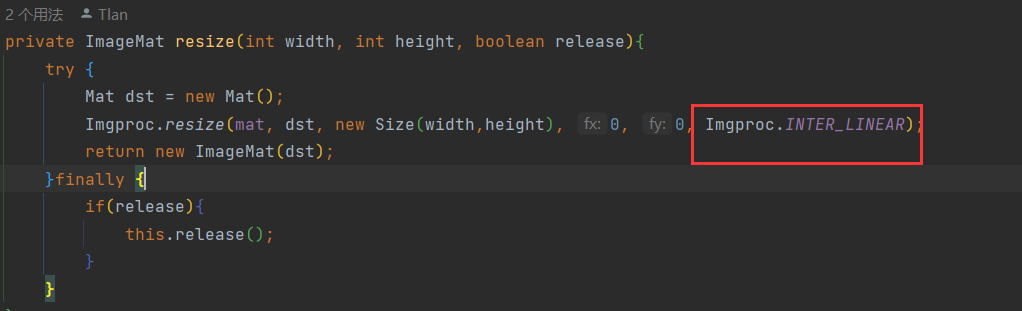

-
但為了我們使用python加載onnx時,resize應該直接使用cv2.resize()
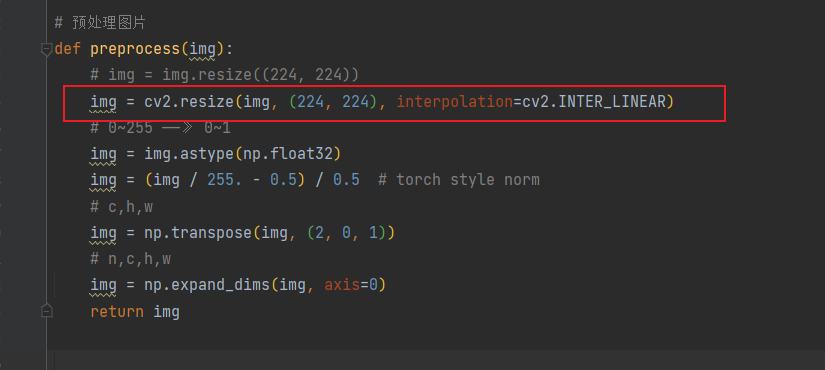

-
總結:通過如下對比,可以發現【使用python加載onnx,使用cv2.resize】和【java加載onnx,使用cv2的resize】(且插值方法保持一致的情況下),兩者輸出保持一致,但【py加載onnx,cv.resize】和【py加載torch,重寫的Resize】或【py加載onnx,重寫的resize】之間的輸出仍有出入,但范圍已經控制在最小范圍了,
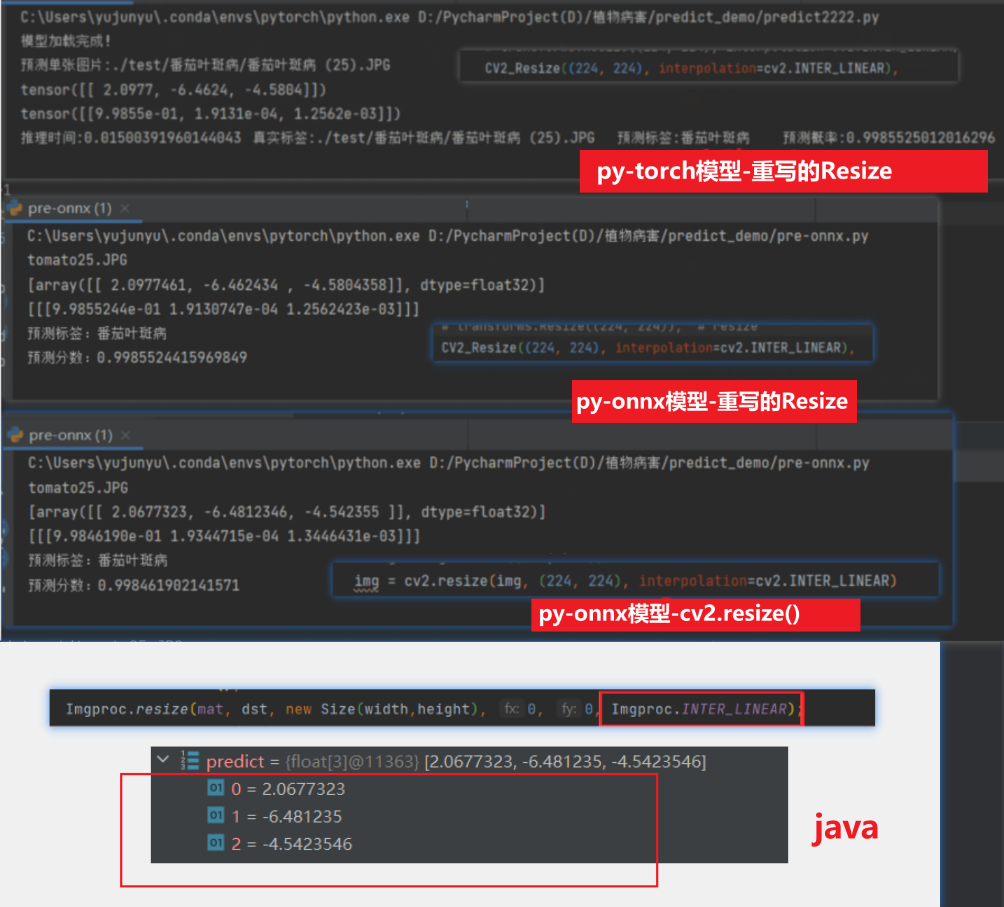
-
注:
若文章內容有誤,歡迎指正!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/552775.html
標籤:其他
上一篇:聲音好聽,顏值能打,基于PaddleGAN給人工智能AI語音模型配上動態畫面(Python3.10)
下一篇:返回列表