?
常用的表格檢測識別方法
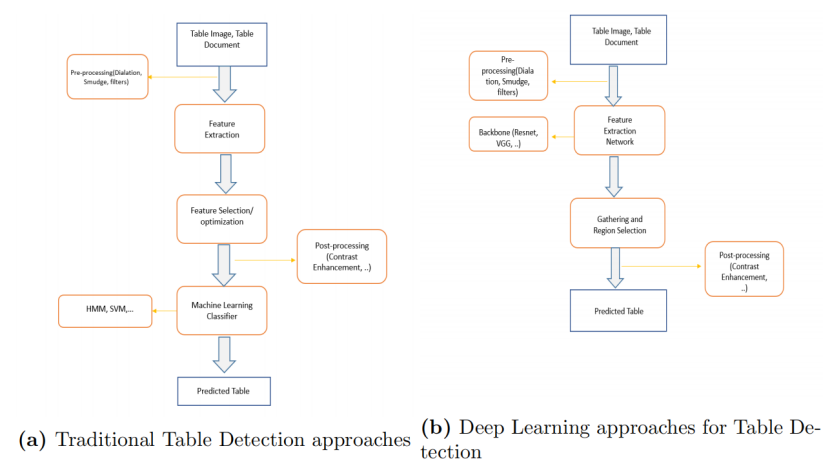
表格檢測識別一般分為三個子任務:表格區域檢測、表格結構識別和表格內容識別,本章將圍繞這三個表格識別子任務,從傳統方法、深度學習方法等方面,綜述該領域國內國外的發展歷史和最新進展,并提供幾個先進的模型方法,
3.1 表格區域檢測方法
表格檢測已經被研究了一段較長的時間,研究人員使用了不同的方法,可以分為如下:
1.基于啟發式的方法
2.基于機器學習的方法
3.基于深度學習的方法
基于啟發式的方法,主要用于20世紀90年代、2000年代和2010年初,他們使用了不同的視覺線索,如線條、關鍵詞、空間特征等,來檢測表格,
Pyreddy等人提出了一種使用字符對齊、孔和間隙來檢測表格 的方法,Wang等人使用了一種統計方法來根據連續單詞之間的距離來檢測表線,將水平連續的單詞與垂直相鄰的線分組起來,提出候選表物體,Jahan等人提出了一種使用單詞間距和線高的區域閾值來檢測表格區域的方法,
Itonori提出了一種基于規則的方法,通過文本塊排列和規則行位置來定位檔案中的表格, Chandran和Kasturi開發了另一種基于垂直和水平線的表格檢測方法,Wonkyo Seo等人使用連接點(水平線和垂直線的交點)檢測進行進一步處理,
Hassan等人通過分析文本塊的空間特征來定位和分割表格,Ruffolo等人介紹了PDF-TREX,這是一種用于單列PDF檔案中的表格識別的啟發式自下而上的方法,它使用頁面元素的空間特征來將它們對齊和分組為段落和表格,Nurminen提出了一套啟發式方法來定位具有公共對齊的后續文本框,并確定它們作為一個表格的概率,
Harit等人提出了一種基于唯一表起始和尾部模式識別的表格檢測技術,Tupaj等人提出了一種基于OCR的表格檢測技術,該系統基于關鍵字搜索類似表格的行序列,上述方法在具有統一布局的檔案上效果比較好,
國內的表格區域檢測研究起步較晚,啟發式方法較少,其中,具有代表性的是Fang等人提出的基于表格結構特征和視覺分隔符的方法,該方法以PDF檔案為輸入,分四步進行表格檢測:PDF決議,頁面布局分析,線條檢測和頁面分隔符檢測,表格檢測,在最后的表格檢測部分中,通過對上一步檢測出的線條和頁面分隔符進行分析得到表格位置,然而,啟發式規則需要推廣到更廣泛的表格種類,并不真正適合通用的解決方案,因此,開始采用機器學習方法來解決表檢測問題,
基于機器學習的方法在2000年代和2010年代很常見,
Kieninger等人通過對單詞片段進行聚類,應用了一種無監督的學習方法,Cesarini等人使用了一種改進的XY樹監督學習方法,Fan等人使用有監督和無監督的方法進行PDF檔案中的表格檢測,Wang和Hu 將決策樹和SVM分類器應用于布局、內容型別和詞組特征,T. Kasar等人使用結點檢測,然后將資訊傳遞給SVM分類器,Silva等人在視覺頁面元素(隱馬爾可夫模型)的順序觀察上應用聯合概率分布,將潛在的表線合并到表中,Klampfl等人比較了兩種來自數字科學專題文章的無監督表識別方法,Docstrum演算法應用KNN將結構聚合成線,然后使用線之間的垂直距離和角度將它們組合成文本塊,該演算法是在1993年設計的,比本節中提到的其他方法要早,
F Shafait 提出了一種有用的表識別方法,該方法在具有相似布局的檔案上表現良好,包括商業報告、新聞故事和雜志頁面,Tesseract OCR引擎提供了該演算法的一個開源實作,
隨著神經網路的興趣,研究人員開始將它們應用于檔案布局分析任務中,最初,它們被用于更簡單的任務,如表檢測,后來,隨著更復雜的架構的發展,更多的作業被放到表列和整體結構識別中,
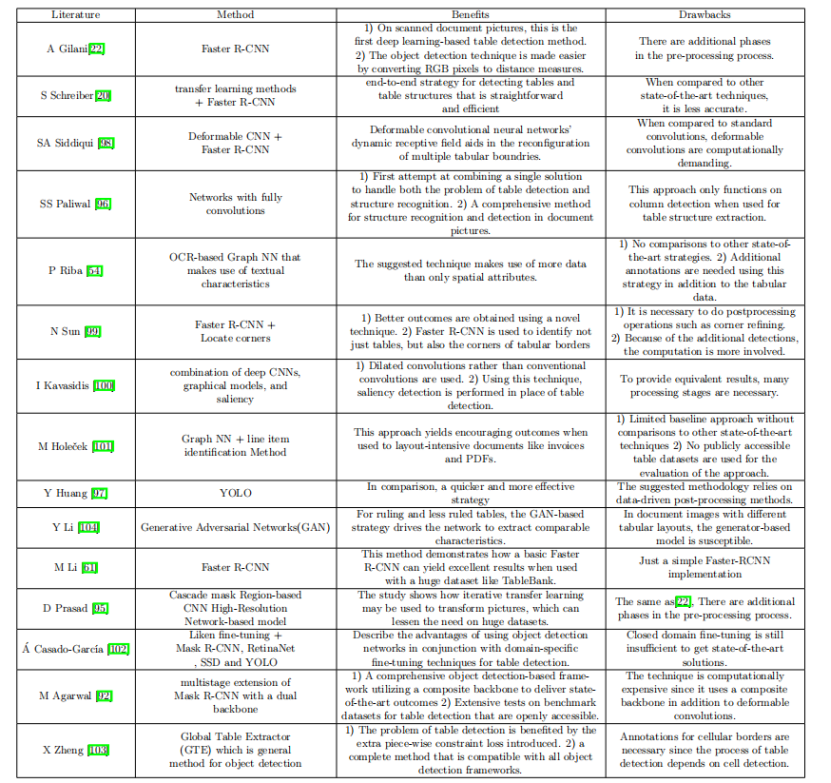
A Gilani [《Table detection using deep learning》]展示了如何使用深度學習來識別表格,檔案圖片最初是按照文中提出的方法進行預處理的,然后,這些照片被發送到一個區域候選網路中進行表格測驗,然后是一個完全連接的神經網路,該方法對各種具有不同布局的檔案圖片非常精確,包括檔案、研究論文和期刊,
D Prasad [《An approach for end to end table detection and structure recognition from image-based documents》]提出了一種解釋檔案圖片中的表格資料的自動表格檢測方法,主要需要解決兩個問題:表格檢測和表格結構識別,使用單一的卷積神經網路(CNN)模型,提供了一個增強的基于深度學習的端到端解決方案,用于處理表檢測和結構識別的挑戰,CascadeTabNet是一個基于級聯掩碼區域的CNN高解析度網路(Cascade mask R-CNN HRNet)的模型,可以同時識別表區域和識別這些表格中的結構單元格,
SS Paliwal [《Tablenet: Deep learning model for end-to-end table detection and tabular data extraction from scanned document images》]提出了一種新的端到端深度學習模型,可用于表格檢測和結構識別,為了劃分表格和列區域,該模型使用了表格檢測和表結構識別這兩個目標之間的依賴關系,然后,從發現的表格子區域中,進行基于語意規則的行提取,
Y Huang [《A yolo-based table detection method》]描述了一種基于YOLO原理的表格檢測演算法,作者對YOLOv3提供了各種自適應改進,包括一種錨定優化技術和兩種后處理方法,以解釋檔案物件和真實物件之間的顯著差異,還使用k-means聚類進行錨點優化,以創建更適合表格而不是自然物件的錨點,使他們的模型更容易找到表格的精確位置,在后處理程序中,將從投影的結果中洗掉額外的空白和有噪聲的頁面物件,
L Hao [《A table detection method for pdf documents based on convolutional neural networks》]提供了一種基于卷積神經網路的PDF檔案中檢測表格的新方法,這是目前最廣泛使用的深度學習模型之一,該方法首先使用一些模糊的約束來選擇一些類似表的區域,然后構建和細化卷積網路,以確定所選擇的區域是否為表格,此外,卷積網路立即提取并使用表格部分的視覺方面特征,同時也考慮了原始PDF檔案中包含的非視覺資訊,以幫助獲得更好的檢測結果,
SA Siddiqui [《Decnt: Deep deformable cnn for table detection》]為檢測檔案中的表格提供了一種新的策略,這里給出的方法利用了資料的潛力來識別任何排列的表,該方法直接適用于影像,使它普遍能適用于任何格式,該方法采用了可變形CNN和faster R-CNN/FPN的獨特混合,由于表格可能以不同的大小和轉換(方向)的形式出現,傳統的CNN有一個固定的感受野,這使得表格識別很困難,可變形卷積將其感受野建立在輸入的基礎上,使其能夠對其感受野進行改造以匹配輸入,由于感受野的定制,網路可以適應任何布局的表格,
N Sun [《Faster r-cnn based table detection combining corner locating》]提出了一種基于Faster R-CNN的表檢測的尋角方法,首先使用Faster R-CNN網路來實作粗表格識別和角定位,然后,使用坐標匹配來對屬于同一表格的那些角進行分組,不可靠的邊同時被過濾,最后,匹配的角組微調并調整表格邊框,在像素級,該技術提高了表格邊界查找的精度,
I Kavasidis[《A saliency-based convolutional neural network for table and chart detection in digitized documents》]提出了一種檢測表格和圖表的方法,使用深度cnn、圖形模型和 saliency ideas的組合,M Holecek[《Table understanding in structured documents》]提出了在賬單等結構化檔案中利用圖卷積進行表格理解的概念,擴展了圖神經網路的適用性,在研究中也使用了PDF檔案,研究結合行項表格檢測和資訊提取,解決表格檢測問題,任何字符都可以快速識別為行項或不使用行項技術,在字符分類之后,表格區域可以很容易地識別出來,因為與賬單上的其他文本部分相比,表格線能夠相當有效地區分,
A Casado-Garc?a[《The benefits of close-domain fine-tuning for table detection in document images》]使用了目標檢測技術,作者已經表明,在進行了徹底的測驗后發現,從一個更近域進行微調可以提高表格檢測的性能,作者利用了Mask R-CNN、YOLO、SSD和 Retina Net結合目標檢測演算法,該研究選擇了兩個基本資料集, TableBank和PascalVOC,
X Zheng [《Global table extractor (gte): A framework for joint table identification and cell structure recognition using visual context》]提供了全域表格提取器(GTE),這是一種聯合檢測表格和識別單元結構的方法,可以在任何物件檢測模型之上實作,為了利用單元格位置預測來訓練他們的表網路,作者開發了GTE-Table,它引入了一種基于表格固有的單元格約束限制的新懲罰,一種名為GTE-Cell的新型分層單元識別網路利用了表格樣式,此外,為了快速、低成本地構建一個相當大的訓練和測驗資料語料庫,作者開發了一種方法來自動分類現有文本中的表格和單元格結構,
Y Li[《A gan-based feature generator for table detection》]提供了一種新的網路來生成表格文本的布局元素,并提高規則較少的表格的識別性能,生成對抗網路(GAN)與該特征生成器模型是類似的,作者要求特征生成器模型為規則約束嚴格和規則松散的表格提取可比較的特征,
DD Nguyen [《a fully convolutional network for table detection and segmentation in document images》]引入了TableSegNet,一個完全卷積的網路,設計緊湊,可以同時分離和檢測表,TableSegNet使用較淺的路徑來發現高解析度的表格位置,而使用較深的路徑來檢測低解析度的表格區域,將發現的區域分割成單獨的表格,TableSegNet在整個特征提取程序中使用具有廣泛內核大小的卷積塊,并在主輸出中使用一個額外的表格邊界類,以提高檢測和分離能力,
D Zhang [《Yolo-table: disclosure document table detection with involution》]提出了一種 YOLO-table-based的表格檢測方法,為了提高網路學習表格空間排列方面的能力,作者將退化納入了網路的核心,并創建了一個簡單的FPN網路來提高模型的有效性,這項研究還提出了一種基于表格的增強技術,
下圖是幾種基于深度學習的表格檢測方法的優缺點的比較,
3.1.1 先進的表格區域檢測模型
DeCNT
2018年的論文《DeCNT: Deep Deformable CNN for Table Detection》提出了一種新的表格檢測方法,利用深度神經網路的潛力,傳統的表格檢測方法依賴于容易出錯且特定于資料集的啟發式方法,相比之下,本方法利用了資料識別任意布局的表格的潛力,以前的大多數表格檢測方法只適用于pdf,而所提出的方法直接適用于影像,使其普遍適用于任何格式,本方法采用了可變形CNN和faster R-CNN/FPN的獨特混合,由于表格可能以不同的大小和轉換(方向)的形式出現,傳統的CNN有一個固定的感受野,這使得表格識別很困難,可變形卷積將其感受野建立在輸入的基礎上,使其能夠對其感受野進行改造以匹配輸入,由于感受野的定制,網路可以適應任何布局的表格,
DeCNT演算法原理:
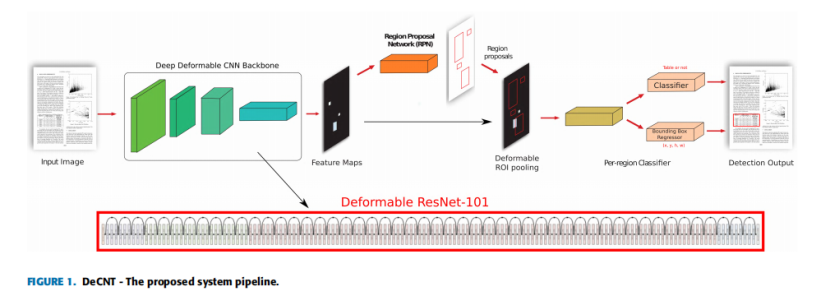
框架由可變形的CNN與faster R-CNN/FPN 的新組合組成,如圖1所示,卷積神經網路是一種自動特征提取器,具有自動發現對手頭任務有用的特征的能力,這種特征的自動提取是基于層的層次結構,其中初始層提取原始特征,如邊緣和梯度,而層次結構頂部的層提取非常抽象的特征,如完整的物件或它的一些突出部分,這種在層次結構中的遍歷導致了在原始輸入影像中一個特定神經元的有效感受野的增加,傳統的二維卷積運算可以用數學方法表示為:
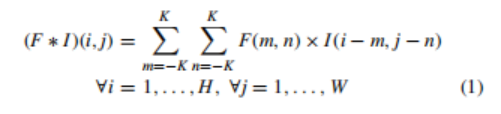
?
其中*為卷積運算,F為濾波器,I為影像,K定義為FilterSize/2,H為影像高度,W為影像寬度,i,j定義執行卷積運算的位置,
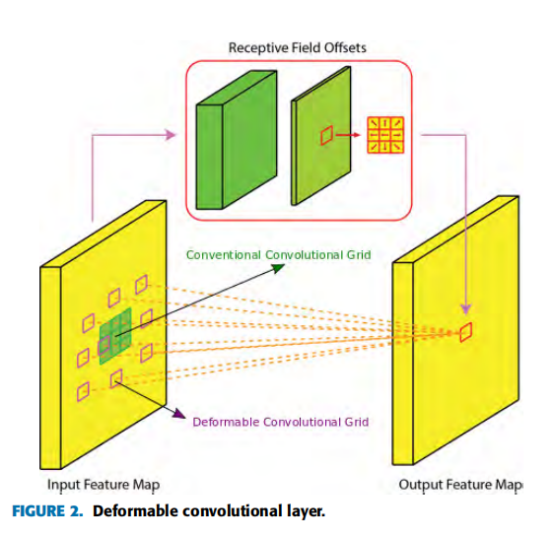
在一個給定的卷積層中,所有神經元的有效感受野是相同的,這個屬性對于位于層次結構頂部的層存在問題,因為在這些層中,不同的物件可能會以任意尺度以及任意轉換出現,這些轉換的存在需要根據神經元的輸入動態地適應神經元的感受野的能力,因此,作者為faster R-CNN/FPN模型配備了一個可變形的CNN,而不是傳統的CNN,其神經元并不局限于一個預定義的感受野,每個神經元可以根據輸入產生顯式偏移來改變其感受野,這些偏移本身依賴于前面的特征圖,這允許卷積層濾波器通過調節輸入本身的感受野來適應不同的尺度和轉換,這個可變形的卷積層如圖2所示,其中添加了一組卷積層來生成影像中每個位置的濾波器偏移量,由于表可以以任意的比例以及任意變換(方向等),可變形卷積運算對于表的檢測任務特別有用,可變形的二維卷積運算包含額外的偏移量,這在數學上可以表示為:
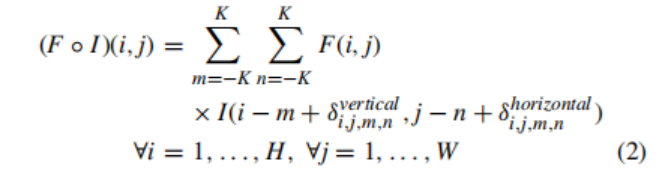
?

?
?

其中nm,n為bin(m,n)中的像素數,如果有C輸入特征映射,那么來自該層的總體輸出將是k × k × C,它將被提供給分類頭,
可變形的roi池,就像卷積對應的池一樣,為roi池層增加了一個偏移量,以便該層可以適應給定輸入的感受野,這一點可以寫成:
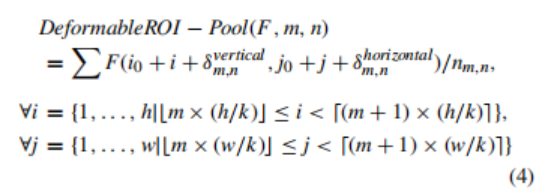

由于在可變形的卷積層中生成顯式偏移來轉換每個神經元的感受野,作者在圖3中可視化了特定可變形卷積層的感受野,紅色的點表示濾波器的中心,而藍色的點是在添加生成的偏移量后得到的,傳統卷積運算的接受場均勻分布在二維網格上,另一方面,在可變形卷積的情況下,從圖中可以明顯看出,每個神經元根據其輸入適應自己的感受野,當接近一個表格區域時(圖3(a),圖3(c))時,感受野擴大到覆寫了完整的表格,但在其他位置仍保持致密(圖3(b),圖3(d)),

可變形結構
論文配備了兩種具有可變形卷積的目標檢測模型,第一個模型是一個可變形faster R-CNN,它由一個可變形的base model組成,并用可變形的roi池化層代替傳統的roi池化層,本文將該模型稱為模型a,第二個模型是采用FPN框架的可變形特征金字塔網路(FPN),在可變形的FPN中,再次使用可變形的base model,并將位置敏感的roi池化層替換為可變形的位置敏感的roi池化層
在所有的實驗中,都使用了ResNet-101的base model,自可變形卷積是一個記憶體密集型操作由于生成的顯式偏移的每個位置特性地圖,論文只是取代了三個更高層次的層ResNet-101模型轉換為可變形的對應層(可變形的感受野主要有助于層的層次結構),這些層分別是res5a_branch2b、res5b_branch2b和res5c_branch2b,對于FPN的情況,作者另外將res3b3_branch2b層和res4b22_branch2b層替換為可變形的對應層,以幫助多尺度特征提取,
由于沒有足夠的資料來從頭開始訓練模型,所以作者利用遷移學習來訓練模型,當使用可變形的ResNet-101時,作者將可變形的卷積層的偏移量初始化為零(零偏移量轉化為固定的接受場,使其等同于傳統的卷積操作),由于網路在新資料集上進行了微調,偏移適應以應對表格結構的規模和轉換,
值得注意的是,論文在目標檢測模型中包含的唯一顯著變化是使用可變形的基模型(可變形的ResNet-101)和使用可變形的roi池,而不是傳統的roi池,這將傳統的物體檢測器轉換為可變形的對應檢測器,為了建立比較,論文還訓練了一個具有傳統卷積操作的ResNet-101模型,將這個非可變形的模型稱為模型C,
超引數
為了訓練模型A(可變形速度faster R-CNN),我們使用了三種不同的錨定比(0.5、1和2)和5種不同的錨定尺度(2、4、8、16和32),為了訓練模型B(可變形的FPN),我們使用了相同的錨定比(0.5、1和2),但只有一個錨定尺度(8),因為FPN另外配備了一個自上而下的路徑用于多尺度檢測,對于前250次迭代,優化模型的初始學習率為0.000125(多gpu訓練時×NumGPUs),然后使用速率為0.00125的學習速率(多gpu訓練時×NumGPUs),在4、16和32個周期使用學習速率衰減步長,該模型經過了50次的優化,最大影像大小被限制為1280×800,超過這個尺寸的影像被調整大小,以保持縱橫比不變,
實驗
資料集:
實驗使用了四個著名的公開的表檢測資料集,資料集的細節,如表1,
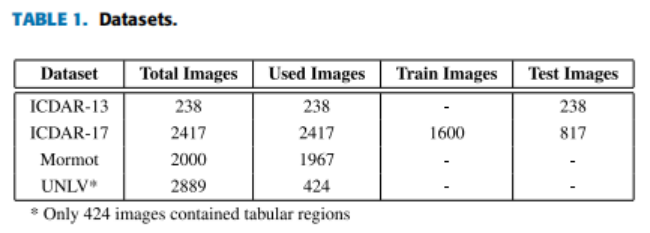
ICDAR-13
ICDAR-2013是最著名的表檢測和結構識別的資料集之一,資料集由PDF檔案組成,論文將其轉換為影像,以便在系統中使用,這是必需的,因為論文的系統只適用于影像,而不是大多數其他依賴于PDF檔案中可用的元資訊的方法,該資料集還包含了表結構識別任務的結構資訊,該資料集總共包含238張影像,由于之前在這個資料集上的大部分作業都使用了0.5的IoU閾值來計算f1,論文也基于這個閾值評估模型,
ICDAR-17
POD最近發布了一個競賽資料集(ICDAR-2017 POD),專注于從影像中檢測表格、圖形和數學方程的任務,該資料集總共由2417張影像組成,訓練集由1600張影像組成,其余的817張影像用于測驗,論文只評估了系統的表格檢測任務,這是作業的重點,由于競賽中所有提交的材料都是針對兩個不同的IoU閾值0.6和0.8進行評估,論文報告了在這兩個閾值上的表現,
MORMOT
由計算機科技研究所(北京大學)發布的Mormot是最大的公開可獲得的表識別資料集,資料集中的影像總數為2000張,兩組影像的正負影像樣本的比例約為1:1,在資料集中有許多不正確的ground truth注釋的實體,因此,使用實驗資料集的清理版本,資料集的清理版本由實驗中使用的1967張影像組成,
UNLV
UNLV資料集由各種檔案組成,包括技術報告、商業信件、報紙和雜志等,該資料集總共包含2889個掃描檔案,其中只有424個檔案包含一個表格區域,在實驗中,論文只使用了一個包含一個表格區域的影像,
實驗結果:
表2比較了該方法與之前在ICDAR-2017 POD和ICDAR-2013資料集上的作業的性能,為了完成,還報告了UNLV和Mormot的結果,但這些資料集不是作業的重點,需要指出的是,依賴于PDF檔案的系統不能與論文的系統進行直接比較,因為它們使用了PDF檔案中包含的元資料,而論文的方法只依賴于原始影像,而沒有額外的元資料,這使得這個問題更加具挑戰性,
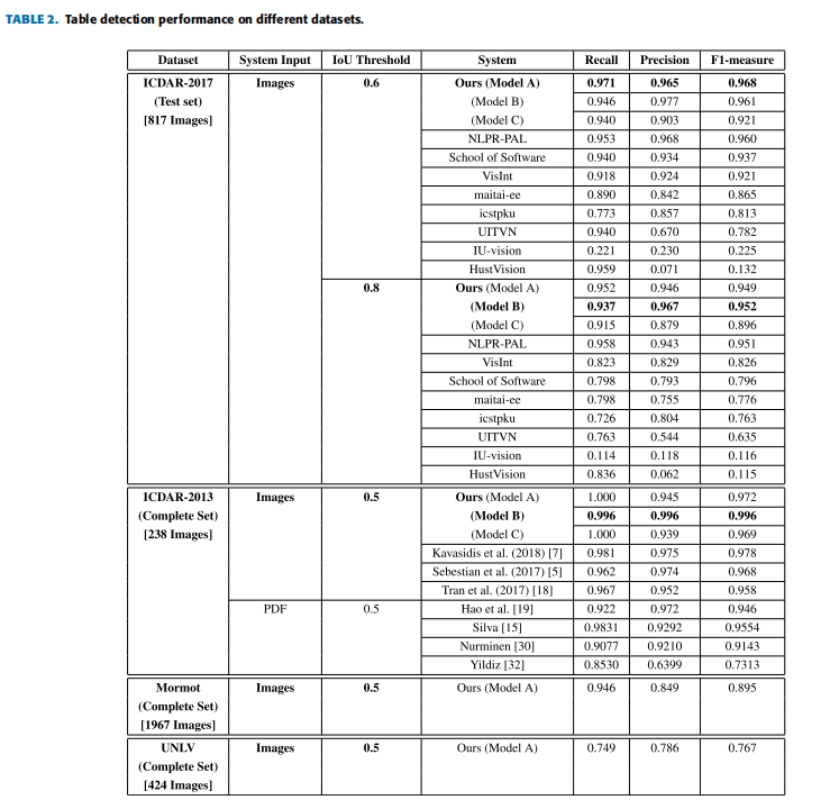
A.ICDAR-13
ICDAR-2013資料集由238張影像組成,包含156張表,實驗使用資料集中的所有影像進行測驗,而沒有在訓練中使用任何一幅影像,該系統只有一個表格區域沒檢測到,取得99.4%召回,類似地,系統只錯誤地將一個區域標記為屬于表(false positive),導致精度為99.4%,圖4給出了來自ICDAR-13資料集的正確和錯誤檢測的代表性例子,包括 true positives, false positives, 和 false negatives,由于f-measure達到99.4%,在ICDAR- 2013資料集上全面優于之前的最先進的方法,
Schreiber等人使用了基于傳統卷積運算的faster R-CNN的方法,由于它們的主干是基于ZFNet 和VGG-16 ,它們的模型沒有直接的可比性,因此,實驗添加了模型C具有相同的ResNet-101主干的實驗結果,結果表明,可變形卷積的綜合性能優于傳統的卷積,

B.ICDAR-17 POD
ICDAR-2017 POD挑戰包括817張影像,其中包含317張表格,所有參賽作品均在兩個不同的IoU閾值0.6和0.8上進行評估,以計算相關指標,可變形faster R-CNN(模型A)在0.6時表現良好,達到96.8%,召回率為97.1%,準確率為96.5%,可變形的FPN(模型B)實作了0.8的閾值的最先進的結果,f-measure達到95.3%,召回率為93.1%,精度為97.7%,
圖5顯示了來自ICDAR- 17 POD資料集的正確和錯誤檢測的代表性例子,根據所取得的結果,在IoU閾值分別為0.6和0.8時,本方法在表格檢測任務上都優于所有其他ICDAR- 2017 POD挑戰參與者,
對ICDAR-2017的錯誤結果進行分析發現,大部分錯誤與IoU有關,原因是不同的資料集組合在到表邊界的距離方面有不同的注釋,在極端情況下,有些情況下,表中的空單元格不被認為是表格區域的一部分,
實驗再次將本方法的結果與傳統的卷積對應的結果進行了比較,在這種情況下,可變形的卷積也優于傳統的卷積,

C.MORMOT
MORMOT資料集由1967張影像組成,共包含1348張表,除了Mormot之外,在其他三個資料集中訓練的可變形faster R-CNN能夠正確地檢測到1275個表實體,該系統還產生了226個false positives和73個false negatives,導致召回率為94.6%,準確率為84.9%,這導致了最終的f-measure為89.5%,圖6給出了來自Mormot資料集的正確和錯誤檢測的代表性例子,包括true positives, false positives, 和 false negatives,

D.UNLV
UNLV資料集也同樣由424張影像組成,總共包含558張表,采用相同的留一方案訓練的可變形快速RCNN能夠正確檢測418個表實體,該系統還產生了114個false positives和140個false negatives,導致召回率為74.9%,準確率為78.6%,最終的f-measure為76.7%,圖7顯示了UNLV正確分類的表格區域,而圖8顯示了不正確分類的表格區域,


結論
論文提出了一種基于region-based的可變形卷積神經網路的端到端表格檢測方法,從對所提出方法的廣泛評估中可以明顯看出,為自然場景中目標檢測而開發的深度架構輔以可變形特性可以全面優于非變形的方法,
Semi-Supervised Deformable DETR
2023年的論文《Towards End-to-End Semi-Supervised Table Detection with Deformable Transformer》本文提出了一種新的端到端半監督表格檢測方法,利用可變形transformer來檢測表格物件,本方法在PubLayNet、DocBank、ICADR-19和TableBank資料集上評估了我們的半監督方法,它比以往的方法取得了更好的性能,
演算法原理:
Deformable DETR
可變形的DETR 包含一個Transformer encoder-decoder網路,它將目標檢測視為一個可設定的預測任務,它使用了Hungarian損失,并通過雙向圖匹配避免了對ground truth邊界框的重疊預測,它消除了對人工參與的元素的需要,如錨點和后處理階段,如在基于cnn的物件檢測器中使用的非最大抑制(NMS),可變形的DETR是DETR體系結構的一個擴展,它解決了DETR的一些限制,如訓練收斂速度慢和在小物件上的性能差,可變形的DETR在體系結構中引入了可變形的卷積,這允許更靈活的物件形狀建模和更好地處理不同尺度的物件,這可以提高性能,特別是在小物體上,并在訓練程序中更快地收斂,圖1顯示了可變形transformer所有模塊,包括多尺度特征和編解碼器網路,
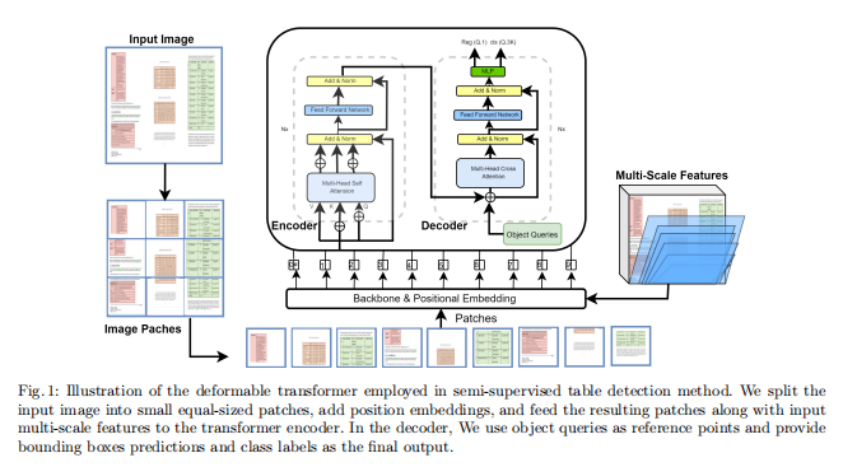

Transformer Decoder
解碼器網路以編碼器特征的輸出和N個物件query作為輸入,它包含兩種注意型別和self-attention和cross-attention,self-attention模塊查找物件query之間的連接,這里的key和query矩陣都包含物件query,cross-attention模塊使用物件query從輸入特征圖中提取特征,這里的key矩陣包含編碼器模塊提供的特征映射,query矩陣是作為解碼器輸入的物件query,在注意模塊之后,添加前饋網路(FFN)和線性投影層作為預測頭,線性投影層預測類標簽,而FFN提供最終的邊界框坐標值,
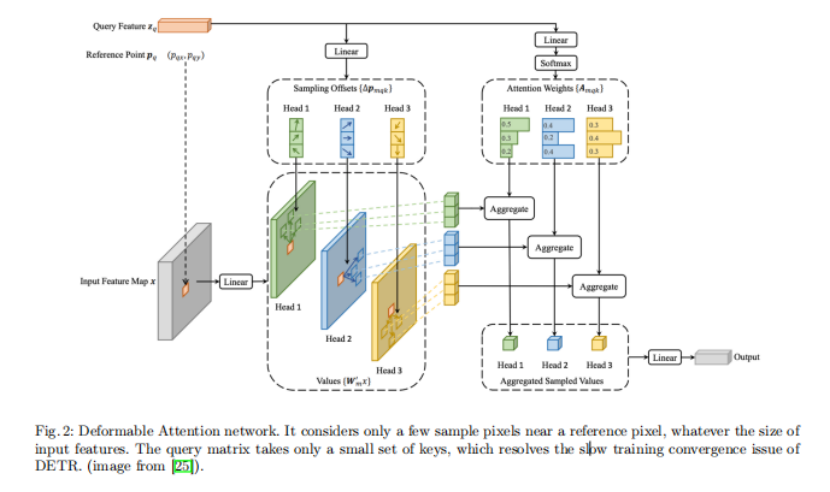
Deformable Attention Module
DETR網路中的Attention模塊考慮了輸入特征圖的所有空間位置,這使得訓練的收斂速度較慢,然而,一個可變形的DETR可以利用基于可變形卷積的Attention網路和多尺度輸入特征來解決這一問題,它只考慮一個參考像素附近的幾個樣本像素,無論輸入特征的大小如何,如圖2所示,Query矩陣只需要一小部分key,解決了DETR訓練收斂速度慢的問題,
Semi-Supervised Deformable DETR
半監督可變形DETR是一種統一的學習方法,它使用完全標記和未標記的資料來進行目標檢測,它包含兩個模塊,一個是學生模塊和一個是教師模塊,訓練資料有兩種資料型別,標簽資料和未標記資料,學生模塊將標記和未標記影像作為輸入,其中對未標記資料應用強增強,而對標簽資料應用(強增強和弱增強),學生模塊通過偽框使用已標記資料和未標記資料的檢測損失進行訓練,未標記的資料包含兩組用于提供類標簽的偽框及其邊界框,教師模塊在應用弱增強后,只將未標記的影像作為輸入,圖3是pipeline的摘要,教師模塊將預測結果提供給偽標記框架,得到偽標簽,然后,學生模塊使用這些偽標簽進行監督訓練,這里,教師模塊使用對未標記資料的弱增強來生成更精確的偽標簽,通過對未標記資料的強增強,使學生模塊具有更具挑戰性的學習,學生模塊還以一小部分具有強增強和弱增強的標記影像作為輸入,對學生模塊sm進行了優化,總損失如下:
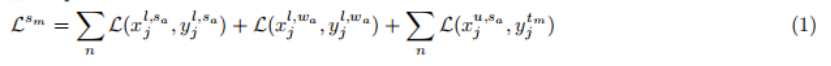


訓期間,學生模塊使用指數移動平均(EMA)策略不斷更新教師模塊,將概率分布視為偽標簽,偽標簽生成是簡單的,相比之下,目標檢測任務更加復雜,因為一個影像可能包含許多物件,而注釋包含物件位置和類標簽,基于cnn的物件檢測器使用錨點作為物件建議,并通過非最大抑制(NMS)等后處理步驟去除冗余的方框,

下篇繼續介紹
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/552843.html
標籤:其他
下一篇:返回列表