摘要:從影像提取人體姿態,用姿態資訊控制生成具有相同姿態的新影像,
本文分享自華為云社區《Pose泰褲辣! 一鍵提取姿態生成新影像》,作者: Emma_Liu ,
人體姿態骨架生成影像 ControlNet-Human Pose in Stable Diffusion
相關鏈接:Notebook案例地址: 人體姿態生成影像 ControlNet-Human Pose in Stable Diffusion
AI gallery:https://developer.huaweicloud.com/develop/aigallery/home.html
也可通過AI Gallery,搜索【人體姿態生成影像】一鍵體驗!
ControlNet
什么是ControlNet?ControlNet最早是在L.Zhang等人的論文《Adding Conditional Control to Text-to-Image Diffusion Model》中提出的,目的是提高預訓練的擴散模型的性能,它引入了一個框架,支持在擴散模型 (如 Stable Diffusion) 上附加額外的多種空間語意條件來控制生成程序,
ControlNet可以復制構圖和人體姿勢,它解決了生成想要的確切姿勢困難的問題,
Human Pose使用OpenPose檢測關鍵點,如頭部、肩膀、手的位置等,它適用于復制人類姿勢,但不適用于其他細節,如服裝、發型和背景,
ControlNet 的作業原理是將可訓練的網路模塊附加到穩定擴散模型的U-Net (噪聲預測器)的各個部分,Stable Diffusion 模型的權重是鎖定的,在訓練程序中它們是不變的,在訓練期間僅修改附加模塊,
研究論文中的模型圖很好地總結了這一點,最初,附加網路模塊的權重全部為零,使新模型能夠利用經過訓練和鎖定的模型,
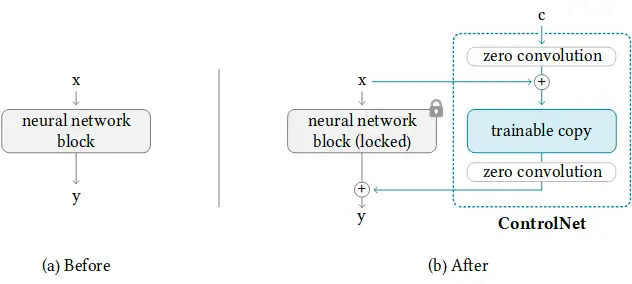
訓練 ControlNet 包括以下步驟:
- 克隆擴散模型的預訓練引數,如Stable Diffusion的潛在UNet,(稱為 “可訓練副本”),同時也單獨保留預訓練的引數(“鎖定副本”),這樣做是為了使鎖定的引數副本能夠保留從大型資料集中學習到的大量知識,而可訓練的副本則用于學習特定的任務方面,
- 引數的可訓練副本和鎖定副本通過 "零卷積 "層連接,該層作為ControlNet框架的一部分被優化,這是一個訓練技巧,在訓練新的條件時,保留凍結模型已經學會的語意,
從圖上看,訓練ControlNet是這樣的:
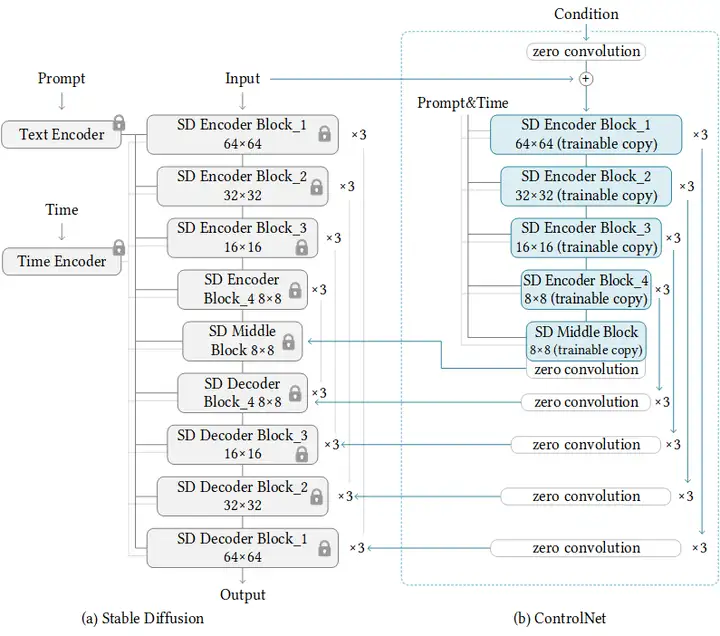
ControlNet提供了八個擴展,每個擴展都可以對擴散模型進行不同的控制,這些擴展是Canny, Depth, HED, M-LSD, Normal, Openpose, Scribble, and Semantic Segmentation,
ControlNet-Pose2imge適配ModelArts
使用方法:
輸入一個影像,并提示模型生成一個影像,Openpose將為你檢測姿勢,從影像提取人體姿態,用姿態資訊控制生成具有相同姿態的新影像,
對兩張影像分別為進行人體骨骼姿態提取,然后根據輸入描述詞生成影像,如下圖所示:

本案例需使用Pytorch-1.8 GPU-P100及以上規格運行
點擊Run in ModelArts,將會進入到ModelArts CodeLab中,這時需要你登錄華為云賬號,如果沒有賬號,則需要注冊一個,且要進行實名認證,參考《ModelArts準備作業_簡易版》 即可完成賬號注冊和實名認證, 登錄之后,等待片刻,即可進入到CodeLab的運行環境
1. 環境準備
為了方便用戶下載使用及快速體驗,本案例已將代碼及control_sd15_openpose預訓練模型轉存至華為云OBS中,注意:為了使用該模型與權重,你必須接受該模型所要求的License,請訪問huggingface的lllyasviel/ControlNet, 仔細閱讀里面的License,模型下載與加載需要幾分鐘時間,
import os import moxing as mox parent = os.path.join(os.getcwd(),'ControlNet') if not os.path.exists(parent): mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/case_zoo/ControlNet/ControlNet',parent) if os.path.exists(parent): print('Code Copy Completed.') else: raise Exception('Failed to Copy the Code.') else: print("Code already exists!") pose_model_path = os.path.join(os.getcwd(),"ControlNet/models/control_sd15_openpose.pth") body_model_path = os.path.join(os.getcwd(),"ControlNet/annotator/ckpts/body_pose_model.pth") hand_model_path = os.path.join(os.getcwd(),"ControlNet/annotator/ckpts/hand_pose_model.pth") if not os.path.exists(pose_model_path): mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/case_zoo/ControlNet/ControlNet_models/control_sd15_openpose.pth',pose_model_path) mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/case_zoo/ControlNet/ControlNet_models/body_pose_model.pth',body_model_path) mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/case_zoo/ControlNet/ControlNet_models/hand_pose_model.pth',hand_model_path) if os.path.exists(pose_model_path): print('Models Download Completed') else: raise Exception('Failed to Copy the Models.') else: print("Model Packages already exists!")
check GPU & 安裝依賴
大約耗時1min
!nvidia-smi %cd ControlNet !pip uninstall torch torchtext -y !pip install torch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 !pip install omegaconf==2.1.1 einops==0.3.0 !pip install pytorch-lightning==1.5.0 !pip install transformers==4.19.2 open_clip_torch==2.0.2 !pip install gradio==3.24.1 !pip install translate==3.6.1 !pip install scikit-image==0.19.3 !pip install basicsr==1.4.2
導包
import config import cv2 import einops import gradio as gr import numpy as np import torch import random from pytorch_lightning import seed_everything from annotator.util import resize_image, HWC3 from annotator.openpose import OpenposeDetector from cldm.model import create_model, load_state_dict from cldm.ddim_hacked import DDIMSampler from translate import Translator from PIL import Image import matplotlib.pyplot as plt
2. 加載模型
apply_openpose = OpenposeDetector() model = create_model('./models/cldm_v15.yaml').cpu() model.load_state_dict(load_state_dict('./models/control_sd15_openpose.pth', location='cuda')) model = model.cuda() ddim_sampler = DDIMSampler(model)
3. 人體姿態生成影像
def infer(input_image, prompt, a_prompt, n_prompt, num_samples, image_resolution, detect_resolution, ddim_steps, guess_mode, strength, scale, seed, eta): trans = Translator(from_lang="ZH",to_lang="EN-US") prompt = trans.translate(prompt) a_prompt = trans.translate(a_prompt) n_prompt = trans.translate(n_prompt) # 影像預處理 with torch.no_grad(): if type(input_image) is str: input_image = np.array(Image.open(input_image)) input_image = HWC3(input_image) detected_map, _ = apply_openpose(resize_image(input_image, detect_resolution)) detected_map = HWC3(detected_map) img = resize_image(input_image, image_resolution) H, W, C = img.shape # 初始化檢測映射 detected_map = cv2.resize(detected_map, (W, H), interpolation=cv2.INTER_NEAREST) control = torch.from_numpy(detected_map.copy()).float().cuda() / 255.0 control = torch.stack([control for _ in range(num_samples)], dim=0) control = einops.rearrange(control, 'b h w c -> b c h w').clone() # 設定隨機種子 if seed == -1: seed = random.randint(0, 65535) seed_everything(seed) if config.save_memory: model.low_vram_shift(is_diffusing=False) cond = {"c_concat": [control], "c_crossattn": [model.get_learned_conditioning([prompt + ', ' + a_prompt] * num_samples)]} un_cond = {"c_concat": None if guess_mode else [control], "c_crossattn": [model.get_learned_conditioning([n_prompt] * num_samples)]} shape = (4, H // 8, W // 8) if config.save_memory: model.low_vram_shift(is_diffusing=True) # 采樣 model.control_scales = [strength * (0.825 ** float(12 - i)) for i in range(13)] if guess_mode else ([strength] * 13) # Magic number. IDK why. Perhaps because 0.825**12<0.01 but 0.826**12>0.01 samples, intermediates = ddim_sampler.sample(ddim_steps, num_samples, shape, cond, verbose=False, eta=eta, unconditional_guidance_scale=scale, unconditional_conditioning=un_cond) if config.save_memory: model.low_vram_shift(is_diffusing=False) # 后處理 x_samples = model.decode_first_stage(samples) x_samples = (einops.rearrange(x_samples, 'b c h w -> b h w c') * 127.5 + 127.5).cpu().numpy().clip(0, 255).astype(np.uint8) results = [x_samples[i] for i in range(num_samples)] return [detected_map] + results
設定引數,生成影像
上傳您的影像至./ControlNet/test_imgs/ 路徑下,然后更改影像路徑及其他引數后,點擊運行,
引數說明:
img_path:輸入影像路徑,黑白稿
prompt:提示詞
a_prompt:次要的提示
n_prompt: 負面提示,不想要的內容
image_resolution: 對輸入的圖片進行最長邊等比resize
detect_resolution: 中間生成條件影像的解析度
scale:文本提示的控制強度,越大越強
guess_mode: 盲猜模式,默認關閉,開啟后生成影像將不受prompt影響,使用更多樣性的結果,生成后得到不那么遵守影像條件的結果
seed: 隨機種子
ddim_steps: 采樣步數,一般15-30,值越大越精細,耗時越長
DDIM eta: 生成程序中的隨機噪聲系數,一般選0或1,1表示有噪聲更多樣,0表示無噪聲,更遵守描述條件
strength: 這是應用 ControlNet 的步驟數,它類似于影像到影像中的去噪強度,如果指導強度為 1,則 ControlNet 應用于 100% 的采樣步驟,如果引導強度為 0.7 并且您正在執行 50 個步驟,則 ControlNet 將應用于前 70% 的采樣步驟,即前 35 個步驟,
#@title ControlNet-OpenPose img_path = "test_imgs/pose1.png" #@param {type:"string"} prompt = "優雅的女士" #@param {type:"string"} seed = 1685862398 #@param {type:"slider", min:-1, max:2147483647, step:1} guess_mode = False #@param {type:"raw", dropdown} a_prompt = '質量最好,非常詳細' n_prompt = '長體,下肢,解剖不好,手不好,手指缺失,手指多,手指少,裁剪,質量最差,質量低' num_samples = 1 image_resolution = 512 detect_resolution = 512 ddim_steps = 20 strength = 1.0 scale = 9.0 eta = 0.0 np_imgs = infer(img_path, prompt, a_prompt, n_prompt, num_samples, image_resolution, detect_resolution, ddim_steps, guess_mode, strength, scale, seed, eta) ori = Image.open(img_path) src = Image.fromarray(np_imgs[0]) dst = Image.fromarray(np_imgs[1]) fig = plt.figure(figsize=(25, 10)) ax1 = fig.add_subplot(1, 3, 1) plt.title('Orginal image', fontsize=16) ax1.axis('off') ax1.imshow(ori) ax2 = fig.add_subplot(1, 3, 2) plt.title('Pose image', fontsize=16) ax2.axis('off') ax2.imshow(src) ax3 = fig.add_subplot(1, 3, 3) plt.title('Generate image', fontsize=16) ax3.axis('off') ax3.imshow(dst) plt.show()

4. Gradio可視化部署
Gradio應用啟動后可在下方頁面上傳圖片根據提示生成影像,您也可以分享public url在手機端,PC端進行訪問生成影像,
請注意: 在影像生成需要消耗顯存,您可以在左側操作欄查看您的實時資源使用情況,點擊GPU顯存使用率即可查看,當顯存不足時,您生成影像可能會報錯,此時,您可以通過重啟kernel的方式重置,然后重頭運行即可規避,
block = gr.Blocks().queue() with block: with gr.Row(): gr.Markdown("## 人體姿態生成影像") with gr.Row(): with gr.Column(): gr.Markdown("請上傳一張人像圖,設定好引數后,點擊Run") input_image = gr.Image(source='upload', type="numpy") prompt = gr.Textbox(label="描述") run_button = gr.Button(label="Run") with gr.Accordion("高級選項", open=False): num_samples = gr.Slider(label="Images", minimum=1, maximum=3, value=https://www.cnblogs.com/huaweiyun/archive/2023/05/19/1, step=1) image_resolution = gr.Slider(label="Image Resolution", minimum=256, maximum=768, value=https://www.cnblogs.com/huaweiyun/archive/2023/05/19/512, step=64) strength = gr.Slider(label="Control Strength", minimum=0.0, maximum=2.0, value=https://www.cnblogs.com/huaweiyun/archive/2023/05/19/1.0, step=0.01) guess_mode = gr.Checkbox(label='Guess Mode', value=https://www.cnblogs.com/huaweiyun/archive/2023/05/19/False) detect_resolution = gr.Slider(label="OpenPose Resolution", minimum=128, maximum=1024, value=https://www.cnblogs.com/huaweiyun/archive/2023/05/19/512, step=1) ddim_steps = gr.Slider(label="Steps", minimum=1, maximum=30, value=https://www.cnblogs.com/huaweiyun/archive/2023/05/19/20, step=1) scale = gr.Slider(label="Guidance Scale", minimum=0.1, maximum=30.0, value=https://www.cnblogs.com/huaweiyun/archive/2023/05/19/9.0, step=0.1) seed = gr.Slider(label="Seed", minimum=-1, maximum=2147483647, step=1, randomize=True) eta = gr.Number(label="eta (DDIM)", value=https://www.cnblogs.com/huaweiyun/archive/2023/05/19/0.0) a_prompt = gr.Textbox(label="Added Prompt", value=https://www.cnblogs.com/huaweiyun/archive/2023/05/19/'best quality, extremely detailed') n_prompt = gr.Textbox(label="Negative Prompt", value='longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality') with gr.Column(): result_gallery = gr.Gallery(label='Output', show_label=False, elem_id="gallery").style(grid=2, height='auto') ips = [input_image, prompt, a_prompt, n_prompt, num_samples, image_resolution, detect_resolution, ddim_steps, guess_mode, strength, scale, seed, eta] run_button.click(fn=infer, inputs=ips, outputs=[result_gallery]) block.launch(share=True)
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/552946.html
標籤:其他
上一篇:面試官:作業三年,還來面初級測驗?恐怕你的軟體測驗工程師的頭銜要加雙引號...
下一篇:返回列表