第三章 常用的表格檢測識別方法
3.2表格結構識別方法
表格結構識別是表格區域檢測之后的任務,其目標是識別出表格的布局結構、層次結構等,將表格視覺資訊轉換成可重建表格的結構描述資訊,這些表格結構描述資訊包括:單元格的具體位置、單元格之間的關系、單元格的行列位置等,
在當前的研究中,表格結構資訊主要包括以下兩類描述形式:1)單元格的串列(包含每個單元格的位置、單元格 的行列資訊、單元格的內容);2)HTML代碼或Latex代碼(包含單元格的位置資訊,有些也會包含單元格的內容),
與表格區域檢測任務類似,在早期的表格結構識別方法中,研究者們通常會根據資料集特點,設計啟發式演算法或者使用機器學習方法來完成表格結構識別任務,
Itonori(1993)根據表格中單元格的二維布局的 規律性,使用連通體分析抽取其中的文本塊,然后 對每個文本塊進行擴展對齊形成單元格,從而得到 每個單元格的物理坐標和行列位置,
Rahgozar等人 (1994)則根據行列來進行表格結構的識別,其先 識別出圖片中的文本塊,然后按照文本塊的位置以及兩個單元格中間的空白區域做行的聚類和列的聚類,之后通過行和列的交叉得到每個單元格的位 置和表格的結構,
Hirayama等人(1995)則從表格線出發,通過平行、垂直等幾何分析得到表格的行和列,并使用動態規劃匹配的方法對各個內容塊進 行邏輯關系識別,來恢復表格的結構,
Zuyev(1997) 使用視覺特征進行表格的識別,使用行線和列線以及空白區域進行單元格分割,該演算法已經應用到FineReader OCR產品之中,
Kieninger等人(1998) 提出了T-Recs(Table RECognition System)系統,以 詞語區域的框作為輸入,并通過聚類和列分解等啟 發式方法,輸出各個文本框對應的資訊,恢復表格 的結構,隨后,其又在此基礎上提出了T-Recs++系 統(Kieninger等,2001),進一步提升了識別效果,
Amano等人(2001)創新性地引入了文本的語意資訊,首先將檔案分解為一組框,并將它們半自動地 分為四種型別:空白、插入、指示和解釋,然后根據 檔案結構語法中定義的語意和幾何知識,分析表示 框與其關聯條目之間的框關系,
Wang等人(2004) 將表格結構定義為一棵樹,提出了一種基于優化方 法設計的表結構理解演算法,該演算法通過對訓練集中 的幾何分布進行學習來優化引數,得到表格的結構, 同樣使用樹結構定義表格結構的還有Ishitani等人 (2005),其使用了DOM(Document Object Model) 樹來表示表格,從表格的輸入影像中提取單元格特 征,然后對每個單元格進行分類,識別出不規則的 表格,并對其進行修改以形成規則的單元格排布,
Hassan(2007)、Shigarov(2016)等人則以PDF檔案為表格識別的載體,從PDF檔案中反解出表格視 覺資訊,后者還提出了一種可配置的啟發式方法框架,
國內的表格結構識別研究起步較晚,因此傳統的啟發式方法和機器學習方法較少,
在早期,Liu等 人(1995)提出了表格框線模板方法,使用表格的 框架線構成框架模板,可以從拓撲上或幾何上反映 表格的結構,然后提出相應的項遍歷演算法來定位和 標記表格中的項,之后Li等人(2012)使用OCR引擎抽取表單中的文本內容和文本位置,使用關鍵詞 來定位表頭,然后將表頭資訊和表的投影資訊結合 起來,得到列分隔符和行分隔符來得到表格結構,
總體來說,表格結構識別的傳統方法可以歸納為以下四種:基于行和列的分割與后處理,基于文本的檢測、擴展與后處理,基于文本塊的分類和后處理,以及幾類方法的融合,
隨著神經網路的興起,研究人員開始將它們應用于檔案布局分析任務中,后來,隨著更復雜的架構的發展,更多的作業被放到表列和整體結構識別中,
A Zucker提出了一種有效的方法CluSTi,是一種用于識別發票掃描影像中的表格結構的聚類方法,CluSTi有三個貢獻,首先,它使用了一種聚類方法來消除表格圖片中的高噪聲,其次,它使用最先進的文本識別技術來提取所有的文本框,最后,CluSTi使用具有最優引數的水平和垂直聚類技術將文本框組織成正確的行和列,Z Zhang提出的分割、嵌入和合并(SEM)是一個準確的表結構識別器,M Namysl提出了一種通用的、模塊化的表提取方法,
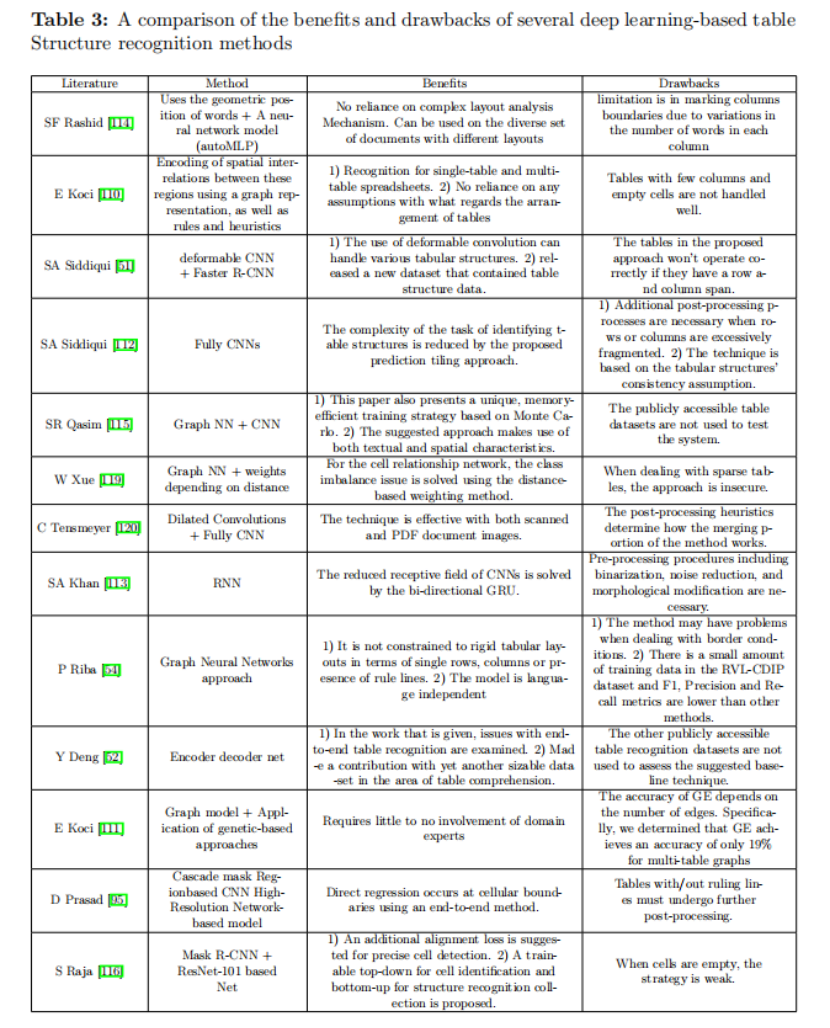
E Koci 提出了一種新的方法來識別電子表格中的表格,并在確定每個單元格的布局角色后構建布局區域,他們使用圖形模型表示這些區域之間的空間相互關系,在此基礎上,他們提出了洗掉和填充演算法(RAC),這是一種基于一組精心選擇的標準的表識別演算法,
SA Siddiqui利用可變形卷積網路的潛力,提出了一種獨特的方法來分析檔案圖片中的表格模式,P Riba提出了一種基于圖的識別檔案圖片中的表格結構的技術,該方法也使用位置、背景關系和內容型別,而不是原始內容(可識別的文本),因此它只是一種結構性感知技術,不依賴于語言或文本閱讀的質量,E Koci使用基于遺傳的技術進行圖劃分,以識別與電子表中的表格匹配的圖的部分,
SA Siddiqui將結構識別問題描述為語意分割問題,為了分割行和列,作者采用了完全卷積網路,假設表結構的一致性的情況下,該方法引入了預測拼接方法,降低了表格結構識別的復雜性,作者從ImageNet匯入預先訓練的模型,并使用FCN編碼器和解碼器的結構模型,當給定影像時,模型創建與原始輸入影像大小相同的特征,
SA Khan提出了一個魯棒的基于深度學習的解決方案,用于從檔案圖片中已識別的表格中提取行和列,表格圖片經過預處理,然后使用門控遞回單元(GRU)和具有softmax激活的全連接層發送到雙向遞回神經網路,SF Rashid提供了一種新的基于學習的方法來識別不同檔案圖片中的表格內容,SR Qasim提出了一種基于圖網路的表識別架構,作為典型神經網路的替代方案,S Raja提出了一種識別表格結構的方法,該方法結合了單元格檢測和互動模塊來定位單元格,并根據行和列預測它們與其他檢測到的單元格的關系,此外,增加了結構限制的損失功能的單元格識別作為額外的差異組件,Y Deng 測驗了現有的端到端表識別的問題,他還強調了在這一領域需要一個更大的資料集,
Y Zou的另一項研究呼吁開發一種利用全卷積網路的基于影像的表格結構識別技術,所示的作業將表格的行、列和單元格劃分,所有表格組件的估計邊界都通過連接組件分析進行了增強,根據行和列分隔符的位置,然后為每個單元格分配行和列號,此外,還利用特殊的演算法優化單元格邊界,
為了識別表中的行和列,KA Hashmi [118]提出了一種表結構識別的引導技術,根據本研究,通過使用錨點優化方法,可以更好地實作行和列的定位,在他們提出的作業中,使用掩模R-CNN和優化的錨點來檢測行和列的邊界,
另一項分割表格結構的努力是由W Xue撰寫的ReS2TIM論文,它提出了從表格中對句法結構的重建,回歸每個單元格的坐標是這個模型的主要目標,最初使用該新技術構建了一個可以識別表格中每個單元格的鄰居的網路,本研究給出了一個基于距離的加權系統,這將有助于網路克服與訓練相關的類不平衡問題,
C Tensmeyer提出了SPLERGE(Split and Merge),另一種使用擴展卷積的方法,他們的策略需要使用兩種不同的深度學習模型,第一個模型建立了表的網格狀布局,第二個模型決定了是否可能在許多行或列上進行進一步的單元格跨度,
Nassar為表格結構提供了一個新的識別模型,在兩個重要方面增強了PubTabNet端到端深度學習模型中最新的encoder-dual-decoder,首先,作者提供了一種全新的表格單元目標檢測解碼器,這使得它們可以輕松地訪問編程pdf中的表格單元格的內容,而不必訓練任何專有的OCR解碼器,作者稱,這種體系結構的改進使表格內容的提取更加精確,并使它們能夠使用非英語表,第二,基于transformer的解碼器取代了LSTM解碼器,
S Raja提出了一種新的基于目標檢測的深度模型,它被定制用于快速優化并捕獲表格內單元格的自然對齊,即使使用精確的單元格檢測,密集的表格識別也可能仍然存在問題,因為多行/列跨越單元格使得捕獲遠程行/列關系變得困難,因此,作者也尋求通過確定一個獨特的直線的基于圖的公式來增強結構識別,作者從語意的角度強調了表格中空單元格的相關性,作者建議修改一個很受歡迎的評估標準,以考慮到這些單元格,為了促進這個問題的新觀點,然后提供一個中等大的進行了人類認知注釋后的評估資料集,
X Shen提出了兩個模塊,分別稱為行聚合(RA)和列聚合(CA),首先,作者應用了特征切片和平鋪,對行和列進行粗略的預測,并解決高容錯性的問題,其次,計算信道的attention map,進一步獲得行和列資訊,為了完成行分割和列分割,作者利用RA和CA構建了一個語意分割網路,稱為行和列聚合網路(RCANet),
C Ma提出了一種識別表格的結構并從各種不同的檔案圖片中檢測其邊界的新方法,作者建議使用CornerNet作為一種新的區域候選網路,為fasterR-CNN生成更高質量的候選表格,這大大提高了更快的R-CNN對表格識別的定位精度,該方法只利用最小的ResNet-18骨干網路,此外,作者提出了一種全新的split-and-merge方法來識別表格結構,該方法利用一種新的spatial CNN分離線預測模塊將每個檢測表格劃分為一個單元網格,然后使用一個GridCNN單元合并模塊來恢復生成單元格,它們的表格結構識別器可以準確地識別具有顯著空白區域的表格和幾何變形(甚至是彎曲的)表格,因為spatial CNN模塊可以有效地向整個表圖片傳輸背景關系資訊,B Xiao假設一個復雜的表格結構可以用一個圖來表示,其中頂點和邊代表單個單元格以及它們之間的連接,然后,作者設計了一個conditional attention網路,并將表格結構識別問題描述為一個單元格關聯分類問題(CATT-Net),
Jain建議訓練一個深度網路來識別表格圖片中包含的各種字符對之間的空間關系,以破譯表格的結構,作者提供了一個名為TSR-DSAW的端到端pipeline:TSR,通過深度空間的字符聯系,它以像HTML這樣的結構化格式生成表格圖片的數字表示,該技術首先利用文本檢測網路,如CRAFT,來識別輸入表圖片中的每個字符,接下來,使用動態規劃,創建字符配對,這些字符配對在每個單獨的影像中加下劃線,然后交給DenseNet-121分類器,該分類器被訓練來識別同行、同列、同單元格或無單元格等空間相關性,最后,作者將后處理應用于分類器的輸出,以生成HTML表格結構,
H Li將這個問題表述為一個單元格關系提取的挑戰,并提供了T2,一種前沿的兩階段方法,成功地從數字保存的文本中提取表格結構,T2提供了一個廣泛的概念,即基本連接,準確地代表了單元格之間的直接關系,為了找到復雜的表格結構,它還構建了一個對齊圖,并使用了一個訊息傳遞網路,
實際場景應用中的表格結構識別,不僅要同時完成表格檢測和結構識別,還要對每個單元格的文本進行識別和資訊抽取,其流程比以上的研究領域都更為復雜,
參考文獻:
Gao L C, Li Y B, Du L, Zhang X P, Zhu Z Y, Lu N, Jin L W, Huang Y S, Tang Z . 2022.A survey on table recognition technology. Journal of Image and Graphics, 27(6): 1898-1917.
M Kasem , A Abdallah, A Berendeyev,E Elkady , M Abdalla, M Mahmouda, M Hamada, D Nurseitovd, I Taj-Eddin.Deep learning for table detection and structure recognition: A survey.arXiv:2211.08469v1 [cs.CV] 15 Nov 2022
S A Siddiqui , M I Malik,S Agne , A Dengel and S Ahmed. DeCNT: Deep Deformable CNN for Table Detection. in IEEE Access, vol.6, pp.74151-74161, [DOI: 10.1109/ACCESS.2018.2880211]
T Shehzadi, K A Hashmi, D Stricker, M Liwicki , and M Z Afzal.Towards End-to-End Semi-Supervised Table Detection with Deformable Transformer.arXiv:2305.02769v2 [cs.CV] 7 May 2023
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/553307.html
標籤:其他
下一篇:返回列表