摘要:對于那些希望使用華為云的云原生服務的人來說,這篇文章提供了很好的指導,讓他們了解如何通過容錯來保證他們的服務的可用性和穩定性,
本文分享自華為云社區《構建高可用云原生應用,如何有效進行流量管理?》,作者: breakDawn,
隨著云原生的概念越來越火,服務的架構應該如何發展和演進,成為很多程式員關心的話題,大名鼎鼎的《深入理解java虛擬機》一書作者于21年推出了新作《鳳凰架構》,從這本書中可以看到當前時下很多最新的技識訓者理念,

因此本文以及后續都將持續沉淀發布這本書的學習筆記和思考,也歡迎購買該書進行詳細學習,或者關注后續的學習筆記內容發布,了解精華內容和總結思考,
流量治理
1 服務容錯
1.1 容錯策略
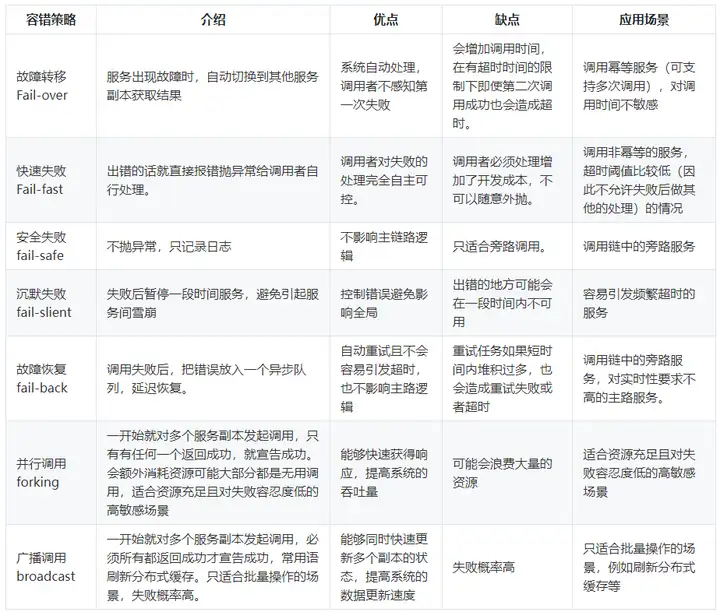
文章中介紹了故障轉移、快速失敗、安全失敗、沉默失敗、故障恢復、并行呼叫、廣播呼叫等幾種容錯策略,我用表格的形式直觀呈現一下這幾種策略的區別,方便理解和選型:
1.2 容錯設計模式
1.斷路器模式
即服務中發請求的地方都通過一個斷路器模塊來轉發發送
當10秒內請求數量達到20,且失敗閾值達到50%以上(這些引數都可以調整), 則認為出現問題, 于是主動進行服務熔斷, 斷路器收到的請求自動回傳錯誤,不再去呼叫遠程服務, 這樣可避免請求執行緒各種阻塞,能及時回傳報錯,
中間會保持有間隔的重試直到恢復后,關閉斷路,
2.艙壁隔離模式
如果一個服務中,可能要同時呼叫A\B\C三個服務,但是卻共用一個執行緒池,
如果呼叫C服務超時,而呼叫C的請求源源不斷打來,會造成C服務的請求執行緒全在阻塞,直接把整體執行緒池給占滿了,影響了對A\B服務的呼叫,
一種隔離措施是對每個呼叫服務分別維護一個執行緒池,缺點是額外增加了排隊、調度、背景關系切換的開銷,據說Hystrix執行緒池如果開啟了服務隔離,會增加3~10ms的延遲,
另一種隔離措施是直接自己定義三個服務的計數器,當服務執行緒數量到達閾值,自動對這個服務呼叫做限流,
3.重試模式
故障轉移和故障恢復這2個策略一般都是借助重試模式來處理的,進行重復呼叫,
重試模式應該滿足以下條件才能使用:
- 僅在主路核心邏輯的關鍵服務上進行同步的重試, 而非關鍵的服務
- 只對瞬時故障進行重試,對于業務故障不進行重試
- 只對冪等型的服務進行重試
重試模式應該有明確的終止條件,例如:
- 超時終止
- 次數終止
重試一定要謹慎開啟, 有時候在網關、負載均衡器里也會配置一些默認的重試, 一旦鏈路很長且都有重試,那么系統中重試的次數將會大大增加,
2 流量控制
流量控制需要解決以下3個問題
- 依據什么指標來限流
- 如何限流
- 超額流量如何處理
2.1 流量統計指標(依據什么指標來限流)
- 每秒事務數TPS: 事務是業務邏輯上具有原子操作的業務操作,對于對買書介面而言, 買書就是一個事務, 背后的其他請求是不感知的,
- 每秒請求數HPS: 就是系統每秒處理的請求數, 如果1事務中只有1個請求, 那么TPS=HPS, 否則HPS>TPS
- 每秒查詢書QPS: 是一臺服務器能夠回應的查詢次數, 對于單節點系統而言,QPS=HPS,對于一個分布式系統而言HPS>TPS
通過限制最大TPS來限流的話,不能夠準確反映出系統的壓力, 因此主流系統傾向使用HPS作為首選的限流指標,
2.2 限流設計模式(如何限流)
流量計數器模式
統計每秒內的請求數是否大于閾值
缺點:
- 每秒是基于1.0s-2.0這樣的區間統計, 但如果是0.5-1.5 和1.5-2.5分別超出閾值,但是1.0-2.0沒有超過閾值,則會出現問題,
- 每秒的請求超過閾值,也不代表系統就真的承受不住,導致五殺
滑動時間窗模式
滑動時間窗專門解決了流量計數器模式的缺點,準備一個長度為10的陣列,每秒觸發1次的定時器,
- 將陣列最后一位的元素丟棄,并把所有元素都后移一位,然后在陣列的第一位插入一個新的空元素;
- 將計數器中所有的統計資訊寫入第一位的空元素;
- 對陣列中所有元素做統計,清空計數器資料,可以保證在任意時間片段內,只通過簡單的呼叫計數比較, 控制請求次數不超過閾值
缺點在于只能用于否決式限流, 必須強制失敗或者降級,無法進行阻塞等待的處理,
漏桶模式
漏桶和令牌桶可以適用于阻塞等待的限流,漏桶就是一個以請求物件作為元素的先入先出隊, 佇列程度等于漏桶大小,當佇列已滿拒絕信的請求進入,比較困難的原因在于很難確定通的大小和水的流出速度,調參難度很大,
令牌桶模式
每隔一定時間,往桶里放入令牌,最多可以放X個,每次請求消耗掉一個,
可以不依賴定時器實作令牌的放入,而是根據時間戳,在取令牌的時候當發現時間戳滿足條件則在那個時候放入令牌即可
2.3 分布式限流
前面的4個限流模式都只是單機限流,經常放在網關入口處,不適用于整個服務集群的復雜情況,例如有的服務消耗多有的服務消耗少,都放在入口處限流情況其實很多,
可以基于令牌桶的基礎上,在入口網關處給不同服務加不同的消耗令牌權重,達到分布式集群限流的目的
總結
流量治理技術對云原生場景的重要性
以上主要介紹了服務容錯和容錯設計模式,涉及到不同的容錯策略和容錯設計模式,如故障轉移、快速失敗、安全失敗、沉默失敗、故障恢復、并行呼叫和廣播呼叫,
這2個設計可以保證系統的穩定性和健壯性,這篇文章涉及的話題與云原生服務息息相關,因為云原生應用程式之間會頻繁通過進行請求和互動,需要通過容錯和彈性來保證高可用性,
因此,對于那些希望使用華為云的云原生服務的人來說,這篇文章提供了很好的指導,讓他們了解如何通過容錯來保證他們的服務的可用性和穩定性,
華為云如何在流量治理中體現作用
如果能通過將服務API注冊到華為云提供的APIG網關上,似乎能夠很方便地達成上述2個設計,
比如APIG支持斷路器策略,是API網關在后端服務出現性能問題時保護系統的內置機制,當API的后端服務出現連續N次超時或者時延較高的情況下,會觸發斷路器的降級機制,向API呼叫方回傳固定錯誤或者將請求轉發到指定的降級后端,當后端服務恢復正常后,斷路器關閉,請求恢復正常,APIG-斷路器策略
同時APIG還提供了流量控制策略,支持從用戶、憑據和時間段等不同的維度限制對API的呼叫次數,保護后端服務,支持按分/按秒粒度級別的流量控制,閱讀了上文中提到的幾個流量策略,再去看APIG里配置的流量策略值,則會很容易理解,APIG-流量控制策略
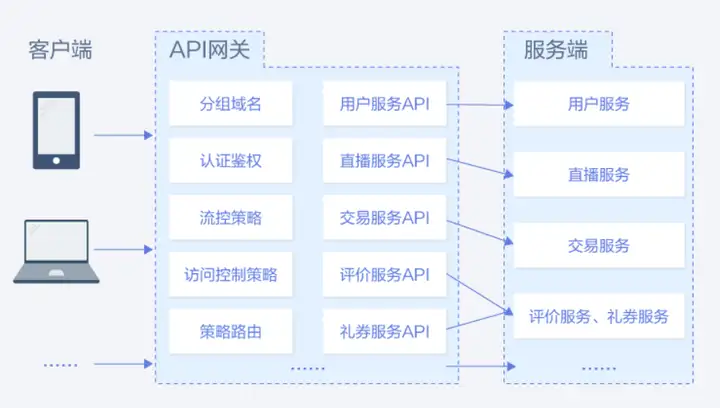
可以看到對于這些常見的經典服務設計策略,無需再重復造輪子,使用已有云服務,可以很快地實作相關功能,提升產品的上線速度和迭代效率,
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/553438.html
標籤:其他
上一篇:Selenium自動化測驗面試必備:高頻面試題及答案整理
下一篇:返回列表