一、問題重述
強化學習是機器學習中重要的學習方法之一,與監督學習和非監督學習不同,強化學習并不依賴于資料,并不是資料驅動的學習方法,其旨在與發揮智能體(Agent)的主觀能動性,在當前的狀態(state)下,通過與環境的互動,通過對應的策略,采用對應的行動(action),獲得一定的獎賞(reward),通過獎賞來決定自己下一步的狀態,
強化學習的幾個重要的組分是:
- 環境,即智能體所處的外來環境,環境可以提供給智能體對應的狀態資訊,并且基于智能體一定的獎賞或者乘法,
- 智能體:智能體是強化學習中的學習和決策主體,他可以通過與環境的互動來學習改進其在當前環境下采取的決策策略,
- 狀態:用于描述當前環境與智能體的情況,或者所觀測的具體的變數,
- 行動:智能體基于觀察到的狀態所采取的操作或者決策
- 獎勵:環境根據智能體所采取的行動和當前的狀態給與其的反饋,
強化學習的目標是通過學習,不斷優化自己的決策策略,使得對于任意一個狀態下,智能體所采取的行動,都能夠獲得最大的獎勵,值得注意的是,這種獎勵是長期獎勵,而非眼前獎勵,我們為了實作這一目標,通常會引入價值函式和動作-價值函式來評估行為的好壞,同時使用一定的演算法和方法來不斷迭代價值函式,在優化迭代價值函式同時,我們實際上就是在優化智能體的決策策略,這是因為事實上價值函式就是表示智能體在時刻t處于狀態s時,按照策略π采取行動時所獲得回報的期望,價值函式衡量了某個狀態的好壞程度,反映了智能體從當前狀態轉移到該狀態時能夠為目標完成帶來多大“好處”,我們通過迭代價值函式,就可以不斷的迭代自己的行動策略π,
機器人走迷宮問題是一個經典的強化學習的基本問題,我們可以將機器人看做是智能體,將迷宮看做環境,將機器人所處的地方視為狀態,機器人的行動稱之為動作,機器人根據當前的迷宮周圍的環境所采取的動作稱之為策略,每次移動是否合法,是否到達迷宮終點視為環境給予的獎勵,
二、設計思想
我們考察機器人走迷宮問題,由于迷宮是有限范圍的迷宮,迷宮的狀態是有限的,針對這種情況,我們可以采用深度優先搜素或寬度優先搜索實作對狀態的窮舉,然后探索出一條符合條件的路徑,針對寬度優先搜索,題中已經給出了對應的代碼,構建了一顆搜索樹,然后通過層次遍歷的辦法來搜索,我們在這里考慮使用深度優先搜索,
深度優先搜索的實作方法是遞回與堆疊,可以看做“一條路走到黑,不見黃河不回頭,不見棺材不落淚”,他會沿著一條路徑一直走,直到走到不合法死胡同為止,我們在當前狀態下,可以通過函式得到可以走的路徑,然后從中選擇一個,進行遞回傳參,然后繼續這個程序,直到走到死胡同或者路徑終點為止,不過值得注意的是,我們需要用到回溯演算法:回溯演算法的本質是,我們這次搜索不希望對于下一次搜索產生影響,所以想要完全消除掉本次搜索對于環境的影響,在這里我們采用了一個vis陣列來判定該狀態是否被遍歷過,采用了一個path陣列來存盤每次采取的動作是什么,我們回溯的思路便是在搜索完或者走到死胡同后往回走,將當前搜索完的path刪掉,同時vis陣列置0,這種演算法的正確性是顯然的,并不會陷入無窮的遍歷程序,因為對于每一個狀態,我們采取的動作都是唯一的,我們在每一個狀態都會遍歷對應的動作,而不會往回遍歷,回溯的目的并不是回溯動作,而是洗掉當前搜索對于未來搜索的影響,這便是我們深度優先搜索的設計思想,
接下來我們考慮實作非搜索演算法,即使用強化學習的方法:強化學習首先需要明確優化的物件即價值函式和動作價值函式:
我們不妨假設環境所給智能體的獎賞為:
maze.set_reward(reward={
"hit_wall": -10.,
"destination": 50.,
"default": -0.1,
})
即撞墻的獎賞為-10,到達重點獎賞為50,正常情況下的獎賞為-0.1,撞墻需要提供一定的懲罰是顯然的,而且懲罰力度要盡可能的大,以鼓勵智能體去探索可行的路徑,
接下來我們考慮優化價值函式和動作價值函式,我們考慮采取Q-learning演算法進行迭代,Q-learning是一個值迭代演算法,而不是策略迭代演算法,下面簡要介紹一下值迭代和策略迭代之間的差異:
值迭代是一種基于迭代更新價值函式的方法,旨在找到最優的價值函式和策略,它通過反復迭代計算每個狀態的值函式,直到值函式收斂到最優值函式,具體而言,值迭代的步驟如下:
- 初始化所有狀態的值函式為任意值,
- 對于每個狀態,根據當前值函式和當前策略,計算其更新后的值函式,
- 重復步驟2,直到值函式收斂到最優值函式,
- 根據最優值函式,得到最優策略,
而策略迭代是一種同時優化價值函式和策略的方法,它交替進行策略評估和策略改進的步驟,直到策略收斂到最優策略,具體而言,策略迭代的步驟如下:
- 初始化策略為任意策略,
- 策略評估:根據當前策略計算每個狀態的值函式,
- 策略改進:根據當前值函式選擇每個狀態的最優行動,更新策略,
- 重復步驟2和步驟3,直到策略收斂到最優策略,
值迭代和策略迭代都可以用于找到最優的策略,但它們在演算法的執行方式和收斂性質上有所不同,值迭代通常需要更多的迭代次數來達到收斂,但每次迭代的計算量較小,策略迭代在每次迭代中都需要進行策略評估和策略改進的步驟,計算量較大,但通常收斂更快,
我們在此處采取Q-learning演算法進行值迭代,Q-learning演算法會將狀態和動作構成一張表來存盤Q值,如下所示:
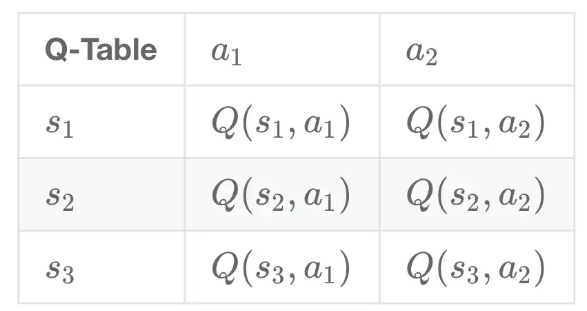
Q值為動作價值函式,具體的計算公式為
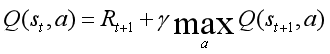
也就是說,當前狀態下,采取動作a的Q值為環境即時的獎賞以及到達下一個狀態后,執行任意行動后所獲得的最大獎賞的γ倍,此處的γ為折扣因子,換句話說,當前狀態的Q值取決于環境的即時獎賞和未來的長期獎勵,其中長期獎勵的定義方法是遞回定義,
我們的Q-learning的本質就是維護一個Q表,在Q表收斂后,根據Q表進行決策,由于強化學習是一個馬爾科夫程序,當前時刻的獎賞與事件無關,只與狀態和采取的行動有關,所以我們可以在某一個狀態下,找到Q表中對應獲得獎賞最大的動作進行行動,然后根據行動后到達的狀態繼續行動,以此類推,直到到達目標點,
如何根據Q表進行決策的程序我們已經說明,接下來我們考慮如何對Q表進行維護:維護Q表是通過不斷更新Q值實作的,具體來說,我們對于每一個時間步的狀態,會選擇一個動作a,值得注意的是,該動作的選擇并不是通過簡單的貪心找最大實作的,我們通常會使用貪心策略,即在某一個狀態下,有的概率選擇其余的部分進行探索,有1-的概率選擇最高的獎賞進行迭代,是超引數,為了平衡利用和探索,類似于MCT中的超引數c,在選擇完動作a后,觀察到獎勵和下一個狀態,根據我們的更新規則對Q表的Q值進行更新,然后跳轉到下一個狀態,以此類推,
值得注意的是,我們更新Q表的Q值,采用較為保守的策略進行更新,引入松弛變數α,具體而言,公式如下:
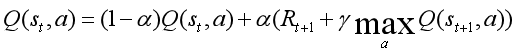
也就是說,我們的值并不完全通過計算的新Q值得到,而是通過新Q值和舊Q值線性加權得到的,
我們考慮基本的Q-learning有一個問題:我們的Q值取決于動作價值函式,動作價值函式就與狀態耦合,如果狀態過多,有些狀態可能始終無法采樣到,因此對這些狀態的q函式進行估計是很困難的,并且,當狀態數量無限時,不可能用一張表(陣列)來記錄q函式的值,我們考慮多層感知機(MLP)是一個通用的函式逼近器,可以以任意精度逼近任意多項式函式,所以我們考慮采用深度神經網路來擬合Q函式,而不是通過值迭代的方法對Q值進行計算,這便是我們的DQN(Deep-Q-Learning)
- 初始化q函式的引數θ
- 回圈
- 初始化s為初始狀態
- 回圈
-
采樣a~??greedy_π(s;θ)
-
執行動作a,觀察獎勵R和下一個狀態s′
-
損失函式
-
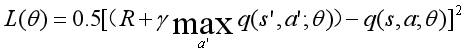
-
根據梯度?L(θ)∕?θ更新引數θ
s←s′
-
- 直到s是終止狀態
- 直到q_π收斂
- 回圈
我們的損失函式一般而言是MSE損失函式,主要刻畫了當前神經網路擬合的Q值與我們計算出的Q值之間的差異,通過不斷優化減少損失函式來更新神經網路的引數,
值得注意的是,我們有一些小tricks例如經驗重現,經驗重現是指我們建立一個經驗緩沖區,用于存盤過去的狀態,所采取的動作,獲得的獎勵和更新后的狀態,這樣做的動機是,如果我們只使用當前的經驗來更新模型引數,容易受到樣本的相關性和序列效應的影響,導致不穩定的學習和收斂困難,
我們考慮使用經驗緩沖區對神經網路進行優化,每次隨機選取一定量的樣本進行更新迭代,這樣做就可以避免樣本的相關性的影響,
接下來我們考慮損失函式,在損失函式中,q函式的值既用來估計目標值,又用來計算當前值,現在這兩處的q函式通過θ有所關聯,可能導致優化時不穩定,我們考慮讓損失函式中的兩個q函式使用不同的引數計算,
- 用于計算估計值的q使用引數θ?計算,這個網路叫做目標網路
- 用于計算當前值的q使用引數θ計算
- 保持θ?的值相對穩定,例如θ每更新多次后才同步兩者的值θ?←θ
三、代碼內容
代碼內容略
四、實驗結果
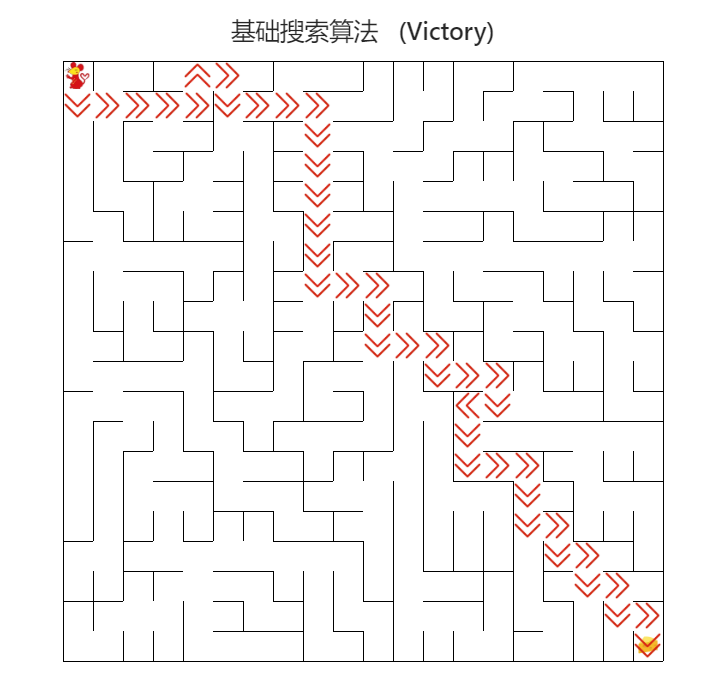
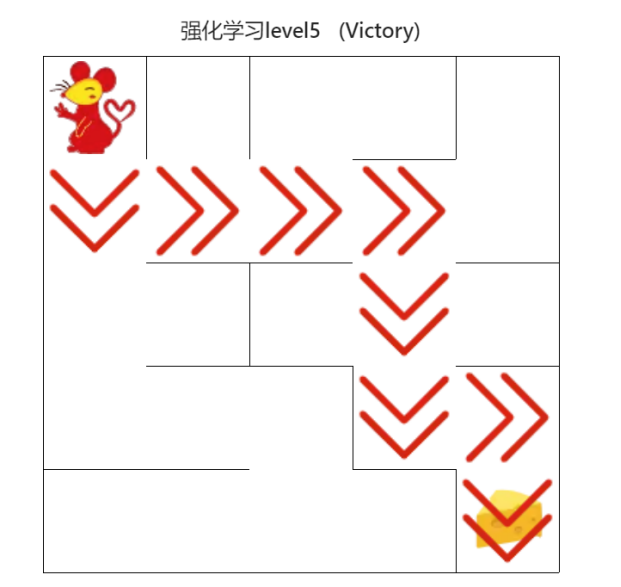
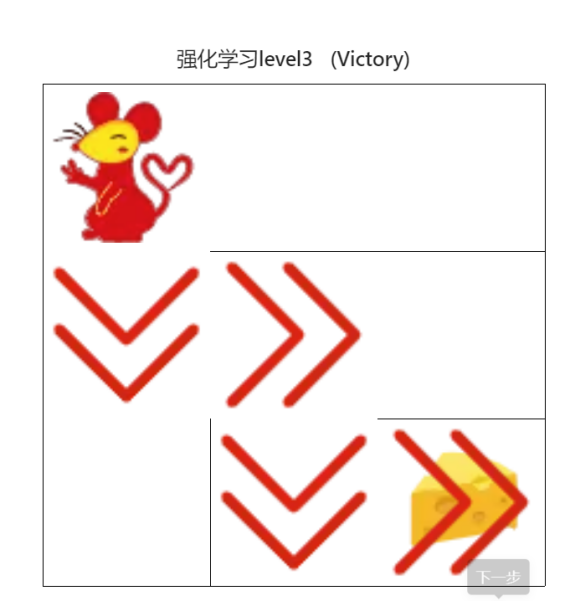
對于實驗結果,可以完全通過網站上的幾個例子,并且程式運行時間特別快

五、總結
總體來看,本次實驗符合預期,DQN的效果特別不錯,在實驗中,遇到的比較大的問題是建立DQN網路和調整相應的超引數,我們調整超引數的策略可以通過在本地運行不同maze大小,看訓練完之后,機器人采取一定行動能否到達最終的目的地,如果不能到達目的地,看機器人的行動軌跡,調整不同的超引數的值來使模型達到最佳的效果,
樸素的搜索演算法本來我寫了一個傳遞location引數的版本,但是評測要求不能傳遞這個引數,所以我們只能將其宣告為全域變數進行使用,總體來看,本次實驗難度適中,特別合理,識訓很大!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/553596.html
標籤:其他
上一篇:索引與分片
下一篇:返回列表