1. 概率、熵與碼字長度
1.1. 資料壓縮的目的
1.1.1. 給定一個資料集中的符號,將最短的編碼分配給最可能出現的符號
1.2
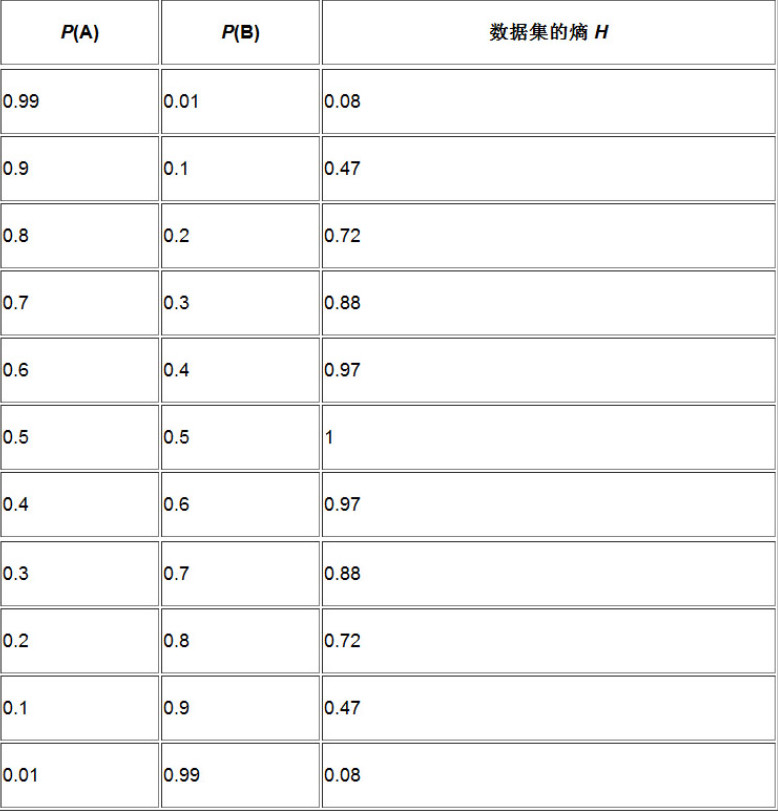
1.2.1. 當P(A)=P(B),也就是兩個符號等可能出現時,資料集對應的熵取最大值LOG2(符號的個數),此時資料集很難壓縮
1.2.2. 其中一個符號出現的可能越大,資料集的熵值就越小,此時資料集也越容易壓縮
1.2.3. 對只包含兩個符號的資料集來說,兩個符號互換概率不影響其熵值
1.3. 啟示
1.3.1. 隨著資料集的冗余度下降,它的熵在變大,其最大值為資料集中不同符號個數的LOG2值
1.3.2. 資料集中一個符號出現的概率越大,整個資料集的熵就越小,資料集也就越容易壓縮
1.3.3. 碼字的長度與符號的出現概率密切相關,而與符號本身沒有太大關系
2. VLC演算法
2.1. 在過去的40多年中,人們創造了數百種VLC演算法
2.2. 在為資料集選擇一種VLC編碼方法的考慮因素
2.2.1. 資料集的整體大小
2.2.2. 資料范圍
2.2.3. 計算各個符號的出現概率
2.2.4. 如果不這樣做,得到的結果可能就是,資料集的大小不但沒有壓縮,有可能反而比原來的資料集還大
2.3. 存在的主要問題
2.3.1. 它們不按位元組 / 字 / 整型對齊
2.3.2. 對于大的數值N,為了方便解碼,其碼字長度的增長速度一般會超過lb(N)個二進制位
2.3.3. 解碼的速度很慢(每次只能讀取一個二進制位)
2.3.4. 只能用于表示壓縮資料流,沒有其他應用
3. 設計VLC集的碼字原則
3.1. 越頻繁出現的符號,其對應的碼字越短
3.2. 碼字需滿足前綴性質
4. 前綴性質
4.1. 如果一個碼字是另一個碼字的前綴,那么用VLC解碼二進制流就會很難
4.2. 某個碼字被分配給一個符號之后,其他的碼字就不能用該碼字作為前綴
4.2.1. 每個符號都能通過其碼字前綴唯一地確定
4.3. 前綴性質是VLC能正常作業所必須具有的性質
4.3.1. 與二進制表示相比,VLC要更長一些
5. 唯一可譯碼
5.1. uniquely decodable codes
6. 非奇異碼
6.1. nonsingular codes
7. 每一種前綴編碼都是唯一可譯的和非奇異的
8. VLC編碼步驟
8.1. 遍歷資料集中的所有符號并計算每個符號的出現概率
8.1.1. 畫出資料集中所有符號的直方圖
8.2. 根據概率為每個符號分配碼字,一個符號出現的概率越大,所分配的碼字就越短
8.2.1. 根據出現的頻數對直方圖進行排序
8.2.2. 給每個符號分配一個VLC,從VLC集中碼字最短的開始
8.3. 再次遍歷資料集,對每一個符號進行編碼,并將對應的碼字輸出到壓縮后的資料流中
9. VLC解碼步驟
9.1. 由于碼字的長度并非是固定的,因此解碼程序還是稍微有些復雜
9.2. 解碼的時候,我們會一二進制位一二進制位地讀取資料,直到讀取的二進制位流與其中的某個碼字相匹配
9.3. 一旦匹配,就會輸出相應的符號,并繼續讀取下一個碼字
10. 摩爾斯碼
10.1. 1836年
10.1.1. 畫家Samuel F. B. Morse
10.1.2. 物理學家Joseph Henry
10.1.3. 機械師Alfred Vail
10.1.4. 發明了第一套電報系統
10.2. 克勞德?香農
10.2.1. 摩爾斯碼方面的專家
10.3. 最簡單的編碼文本資訊的方法
10.3.1. 用數字126來編碼AZ的英文字母
10.4. 發送一次資訊所需要的人工操作次數太多
10.4.1. 物理硬體(發報機設備)和人工硬體(也就是操作人員的手腕)的磨損比預期的要快,解決方法則是使用統計來減少作業量
10.5. 對符號分配變長編碼(variable-length codes,VLC)的最初實作之一
10.6. 為英語字母表中的每一個字符都分配了或長或短的脈沖,一個字母用得越頻繁,其編碼也就越短、越簡單
10.6.1. 目的則在于減少傳輸資訊程序中所需要的總作業量
11. 通用編碼
11.1. universal codes
11.2. 一種將整數轉換為VLC的獨特方法
11.3. 一類特殊的前綴編碼
11.4. 為正整數賦上一個長度可變的二進制碼字
11.5. 數值越小,其對應的碼字也越短
11.5.1. 因為假定小整數比大整數出現得更頻繁
12. 二進制編碼
12.1. 不滿足前綴性質
12.2. 用B(n)來表示整數n的標準二進制表示
12.3. beta編碼或二進制編碼
12.4. 給定0~N的任意整數,都能用1+floor(lb(n))個二進制位來表示
12.4.1. 只要提前知道N的值,就能通過固定長度表示法來避開前綴問題
12.4.2. 如果不能提前知道資料集中有多少個不同的整數,就不能用固定長度表示法
13. 一元碼
13.1. 滿足前綴性質
13.2. 任意正整數N,它的一元碼表示都是N-1個1后面跟著1個0
13.2.1. 4的一元碼表示為1110
13.3. 整數N的一元碼長度也是N個二進制位
13.4. 將一元碼應用在那些前一個符號的出現概率是后一個符號2倍的資料集上,效果最佳
13.5. 如果每個整數N的出現概率P(N)服從指數分布2^(-N),即1/2、1/4、1/8、1/16、1/32,其他以此類推,就可以使用一元碼進行編碼
14. Peter Elias
14.1. 1923年11月23日生
14.2. 1955年,他就引入了卷積碼(convolutional codes),作為分組碼(block codes)的一種替代方法
14.3. 建立了二進制洗掉信道(binary erasure channel),并提出了用糾錯碼的串列譯碼(list decoding of error-correcting codes)來代替唯一可譯碼(unique decoding)
14.4. Elias gamma編碼
14.4.1. 用于事先無法確定其上界的整數的編碼
14.4.1.1. 不知道最大的整數會是多大
14.4.2. 對整數n的出現概率P(n)=1/(2n*n)的情形比較適用
14.4.3. 最主要的思想是不再對整數直接編碼,而是用其數量級作為前綴
14.4.3.1. 相應的碼字就由兩部分組成,即與此整數相當的2的次冪再加上余數
14.4.4. 作業原理
14.4.4.1. 找出最大的整數N,使其滿足2N<n<2(N+1),并且將n表示為n=2^N+L這樣的形式
14.4.4.1.1. L=n-2^N
14.4.4.1.2. n=12,23=8,24=16,23<n<24,N=3
14.4.4.1.3. L=12-2^3=4
14.4.4.2. 用一元碼表示N
14.4.4.2.1. N=3,一元碼110
14.4.4.3. 將L表示為長為N的二進制編碼,并加在步驟(2)中得出的一元碼之后
14.4.4.3.1. 有了這樣的對稱性,后面才能順利解碼
14.4.4.3.2. L=4,其對應的長度為3的二進制碼為100
14.4.4.3.3. 將前兩個步驟得出的編碼連接,就得到了最終的輸出110100
14.5. Elias delta編碼
14.5.1. 對整數N的出現概率P(N)等于1/[2n(lb(2n)*lb(2n))的資料集來說是理想的選擇
14.5.2. 作業原理
14.5.2.1. 將要編碼的數N用二進制表示
14.5.2.1.1. 將N=12表示為二進制1100
14.5.2.2. 數一下N的二進制位數,并將這個位數轉化為二進制,作為C
14.5.2.2.1. 12的二進制表示共有4位,將4表示為二進制,即C = 100
14.5.2.3. 去掉N的二進制表示的最左邊一位,這個值肯定是1
14.5.2.3.1. 去掉N=12的二進制表示的最左一位,得到100
14.5.2.4. 將C的二進制表示加在去掉最左邊一位后的N的二進制表示之前
14.5.2.4.1. 將C = 100加到上一步驟所得的結果之前,得到100100
14.5.2.5. 在上一步驟所得的結果前加上C的二進制位數減1個0作為最終的編碼
14.5.2.5.1. 將C的二進制位數減1,即3-1 = 2,在上一步驟所得的結果前加上2個0,由此得到12的最終編碼為00100100
15. 谷歌的Varint演算法
15.1. 最基本的概念早在1972年就提出
15.2. 2010年作為“避免壓縮整數”(escaping for compressed integers)而被重新引入
15.3. 是一種表示整數的方法,它用一個或多個位元組來表示一個整數,數值越小用的位元組數越少,數值越大用的位元組數越多
15.3.1. 結合了VLC的靈活性和現代計算機體系結構的高效率,是一種很好的混合方法
15.3.2. 既允許我們表示可變范圍內的整數,同時還對自身的資料進行了對齊以提高解碼的效率,達到了雙贏
15.4. 方法
15.4.1. 將幾個位元組連接起來表示整數
15.4.2. 并用每個位元組的MSB作為布爾標志,來判斷當前的位元組是否為該整數的最后一個位元組
15.4.3. 每個位元組的低7位則用來存盤該數的二進制補碼(two's complement representation)
15.4.4. 整數1可以用一個位元組表示,因此它的MSB不需要設定,可表示為00000001
15.5. 示例
15.5.1. 10101100 00000010
15.5.1.1. 10101100 00000010 → 0101100 0000010
15.5.1.1.1. 刪掉每個位元組的MSB
15.5.1.1.1.1. 它的作用只是判斷當前位元組是否是最后一個位元組
15.5.1.1.1.2. 第一個位元組的MSB已經設定為1,因為用Varint方法來表示,該數需要多個位元組
15.5.1.2. 0101100 0000010
15.5.1.2.1. 將剩下的兩個7二進制位的資料順序顛倒一下
15.5.1.2.1.1. 用Varint方法表示時,低位的位元組在前
15.5.1.3. 0000010 0101100
15.5.1.3.1. 將二進制表示轉換為十進制數,就得到了最終的數值300
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/553875.html
標籤:其他
下一篇:返回列表