決策樹
? 決策樹是一種機器學習的方法,決策樹的生成演算法有ID3(資訊增益), C4.5(資訊增益率)和CART(Gini系數)等,決策樹是一種樹形結構,其中每個內部節點表示一個屬性上的判斷,每個分支代表一個判斷結果的輸出,最后每個葉節點代表一種分類結果,
? 構造樹的基本想法是隨著樹深度的增加,節點的熵迅速地降低,熵降低地速度越快越好,這樣我們有望得到一顆高度最矮地決策樹,
熵和Gini系數
? 描述樣本純度,熵和Gini系數越大,表示樣本純度越小,即樣本中每一類出現的概率越小,
\[熵 = -\sum_{i=1}^{n}{P_i\ln(P_i)} \]\[Gini系數 = 1 - \sum_{k=1}^{K}{P_i^2} \]資訊增益
? 熵值的變化,希望構建決策樹的程序中,資訊增益越大越好,但如果在確定一個根節點之后,有很多子樣本,每個子樣本非常純,那么就會出現熵約等于1的情況,但這種情況不是我們希望看到的,所以此方法需要改進,
剪枝
預剪枝:在構建決策樹的程序時,提前停止
后剪枝:決策樹構建好后,然后才開始裁剪
評價函式
? 評價決策樹結構的好壞,類似于損失函式,其中Nt為當前葉子節點樣本個數,H(t)則表示當前葉子節點的熵值或Gini值,
\[C(T) = \sum_{t \epsilon leaf}{N_tH(t)} \]葉子節點個數太多,也會影響決策樹結構好壞,加入了剪枝以后,評價函式變為:
\[C_\alpha(T) = C(T) + \alpha|T_{leaf}| \]決策樹Python實作
from sklearn import tree
from sklearn.datasets import load_iris
from sklearn import model_selection
import matplotlib.pyplot as plt
import graphviz
# 加載鳶尾花資料集,X為資料集,y為標簽
dataSet = load_iris()
X = dataSet.data
y = dataSet.target
# 特證名稱
feature_names = dataSet.feature_names
# 類名
target_names = dataSet.target_names
# 劃分資料集
X_train, X_test, Y_train, Y_test = model_selection.train_test_split(X, y)
# 實體化模型物件
# 1.criterion這個引數正是用來決定不純度的計算方法的
# 輸入"entropy",使用資訊熵;輸入“gini”,使用基尼系數
# 對于高維資料或者噪音很多的資料,資訊熵很容易過擬合,基尼系數在這種情況下效果往往會更好
# 2.random_state用來設定分支中的隨機模式的引數,默認為None,在高維度時隨機性會表示的更加明顯
# 3.splitter也是用來控制決策樹中的隨機選項的
# 輸入“best”,決策樹在分支時雖然隨機,但是還是會優先選擇更加重要的特征進行分支;
# 輸入"random",決策樹會在分支時更加隨機,樹會因為含有更多的不必資訊而更深更大,可能會導致過擬合問題
# 4.剪枝操作
# (1)max_depth:限制樹的最大深度,超過設定深度的樹枝全部剪掉
# (2)min_samples_leaf:一個節點在分支后的每個子節點都必須包含至少min_samples_leaf個訓練樣本,否則分支就不會發生
# (3)min_samples_split:一個節點必須要包含至少min_samples_split個訓練樣本,這個節點才允許被分支,否則分支就不會發生
# (4)max_features:限制分枝時考慮的特征個數,超過限制個數的特征都會被舍棄,和max_depth相似
# (5)min_impurity_decreases:限制資訊增益的大小,資訊增益小于設定數值的分枝不會發生,
clf = tree.DecisionTreeClassifier(criterion='entropy')
# 通過模型介面訓練模型
clf = clf.fit(X_train, Y_train)
# 模型預測
predict_y = clf.predict(X_test)
print("對測驗集樣本的預測結果:\n", predict_y)
predict_y1 = clf.predict_proba(X_test)
print("預測樣本為某個標簽的概率:\n", predict_y1)
# 通過測驗集對模型評分(0-1)
Test_score = clf.score(X_test, Y_test)
print("模型在測驗集上進行評分:\n", Test_score)
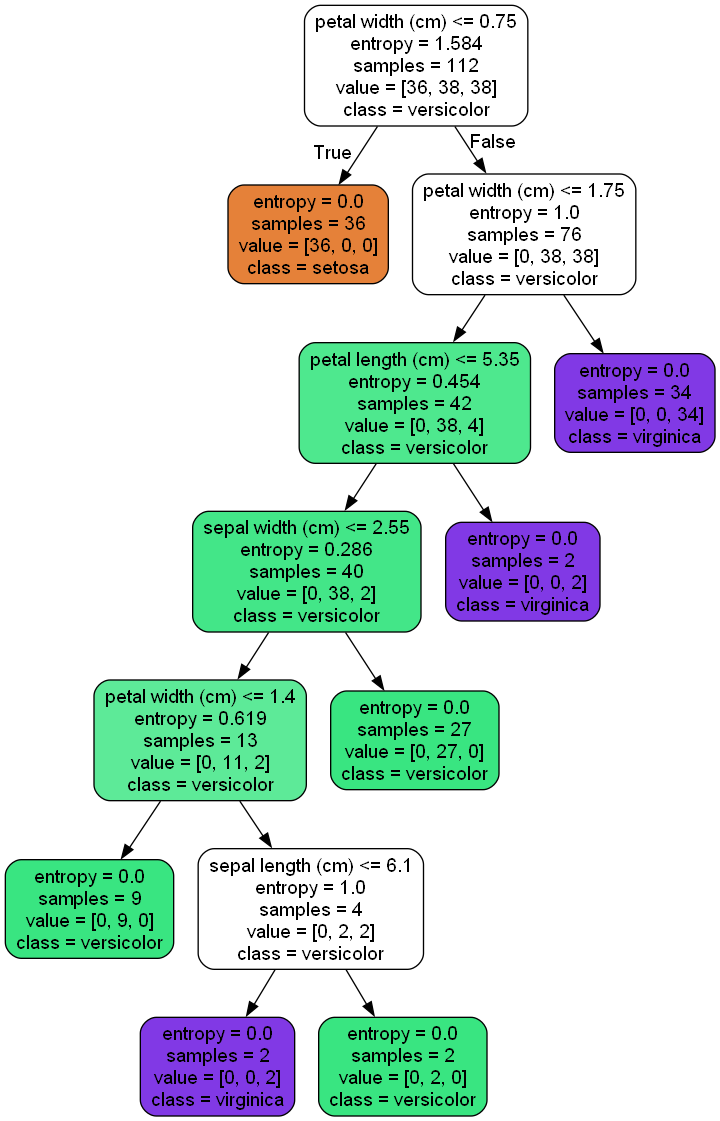
# 使用grapviz繪制決策樹
clf_dot = tree.export_graphviz(clf,
out_file=None,
feature_names=feature_names,
class_names=target_names,
filled=True,
rounded=True)
graph = graphviz.Source(clf_dot,
filename="iris_decisionTree",
format="png")
graph.view()
print("\n特征重要程度為:")
info = [*zip(feature_names, clf.feature_importances_)]
for cell in info:
print(cell)
# 確認最優的剪枝引數,橫坐標是超引數,縱坐標是模型度量,這里是Test_score
test = []
for i in range(10):
clf = tree.DecisionTreeClassifier(max_depth=i + 1
, criterion="entropy"
, random_state=30
, splitter="random"
)
clf = clf.fit(X_train, Y_train)
score = clf.score(X_test, Y_test)
test.append(score)
plt.plot(range(1, 11), test, color="red", label="max_depth")
plt.legend()
plt.show()
基于鳶尾花資料集的決策樹形狀
參考鏈接
機器學習第二階段:機器學習經典演算法(2)——決策樹與隨機森林
決策樹演算法python實作
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/553986.html
標籤:其他
上一篇:K8s Pod狀態與容器探針
下一篇:返回列表