在大模型發展歷程中,有兩個比較重要點:第一,Transformer 架構,它是模型的底座,但 Transformer 不等于大模型,但大模型的架構可以基于 Transformer;第二,GPT,嚴格意義上講,GPT 可能不算是一個模型,更像是一種預訓練范式,它本身模型架構是基于 Transformer,但 GPT 引入了“預測下一個詞”的任務,即不斷通過前文內容預測下一個詞,之后,在大量的資料上進行學習才達到大模型的效果,
之所以說 Transformer 架構好,是因為 Transformer 能夠解決之前自然語言處理中最常用的 RNN 的一些核心缺陷,具體來看:一是,難以并行化,反向傳播程序中需要計算整個序列;二是,長時依賴關系建模能力不夠強;三是,模型規模難以擴大,
那么,Transformer 具體是如何作業的?
首先,是對輸入進行識別符號化,基于單詞形式,或字母,或字符子串,將輸入文本切分成幾個 token,對應到字典中的 ID 上,并對每個 ID 分配一個可學習的權重作為向量表示,之后就可以針對做訓練,這是一個可學習的權重,
在輸入 Transformer 結構之后,其核心的有自注意力模塊和前向傳播層,而在自注意力模塊中,Transformer 自注意力機制建模能力優于 RNN 序列建模能力,因此,有了 Transformer 架構后,基本上就解決了運行效率和訓練很大模型的問題,
基于 Transformer 架構的主流語言大模型主要有幾種:
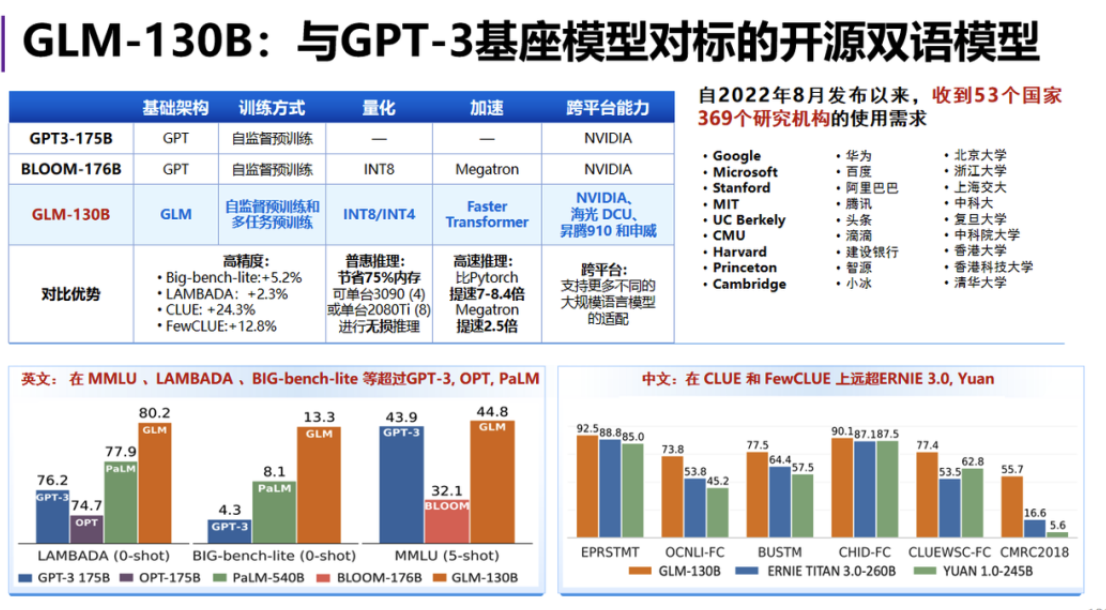
一是,自編碼模型,如 BERT,簡單講就是給到一句話,然后把這句話的內容挖空,當問及挖空的內容時,就把內容填回去,這其實是典型地用來做一個自然語言理解的任務,但做生成任務是非常弱的;
二是,自回歸模型,如 GPT,它是通過不斷地預測下一個詞,特點是只能從左到右生成,而看不到后面的內容,GPT-1 最后接了一個 Linear 層做分類或選題題等任務,到了 GPT-2 ,已經將一些選擇任務或者分類任務全部都變成文本任務,統一了生成的范式;
三是,編碼器-解碼器模型,如 T5,它的輸入和輸出是分為比較明顯的兩塊內容,或者是問答式,或者序列到序列的轉換型的任務;
四是,通用語言模型,如 GLM,該模型結合了自回歸和自編碼兩種形式的模型,舉個例子,“123456”是一串輸入的序列,現在把 “3”、“5”、“6” 挖空,讓模型去學習,那么,挖空以后換成一個 “ mask token” 告訴模型這個地方遮掉了一些內容,現在需要去預測出來遮掉的內容,
與 BERT 不同的是,GLM 把自回歸和自編碼方式進行結合后,挖出來的內容直接拼到了文本的后面,然后加上一個 “ start token”,告訴模型現在是開始生成了,開始做填空任務了,然后把標準答案 “5”、“6” 放在 “ star token”后面讓它去預測,直到預測到 “end token”,它就知道這個填空已經結束了,這個程序稱為自回歸填空式的任務,整個計算流程還是自回歸式,但它不斷預測下一個詞,既實作了填空的功能,又能看到背景關系內容,此外,相比于 GPT 模型,GLM 采用了一個雙向注意力的機制,
國產AI輔助編程工具CodeGeeX,
CodeGeeX也是一個使用AI大模型為基座的輔助編程工具,幫助開發人員更快的撰寫代碼,可以自動完成整個函式的撰寫,只需要根據注釋或Tab按鍵即可,它已經在Java、JavaScript和Python等二十多種語言上進行了訓練,并基于大量公開的開源代碼、官方檔案和公共論壇上的代碼來優化自己的演算法,CodeGeeX作為一款中國原創的AI輔助編程工具,現在免費提供給所有開發者使用,同時完全開源,程式員使用普遍認為撰寫代碼的效率提升2倍以上,
最近功能上新非常快,比如剛剛更新的“Ask CodeGeeX”功能,是將智能問答模式,融合到實際開發場景中,讓開發者更專注和沉浸于編程,不用離開當前 IDE 的編程環境,就可以邊寫代碼邊和 AI 對話,實作針對編程問題的智能問答,無需waitlist,立刻就能嘗鮮這個新功能!
那么就先給大家快速看看,在CodeGeeX上的體驗是怎樣的:
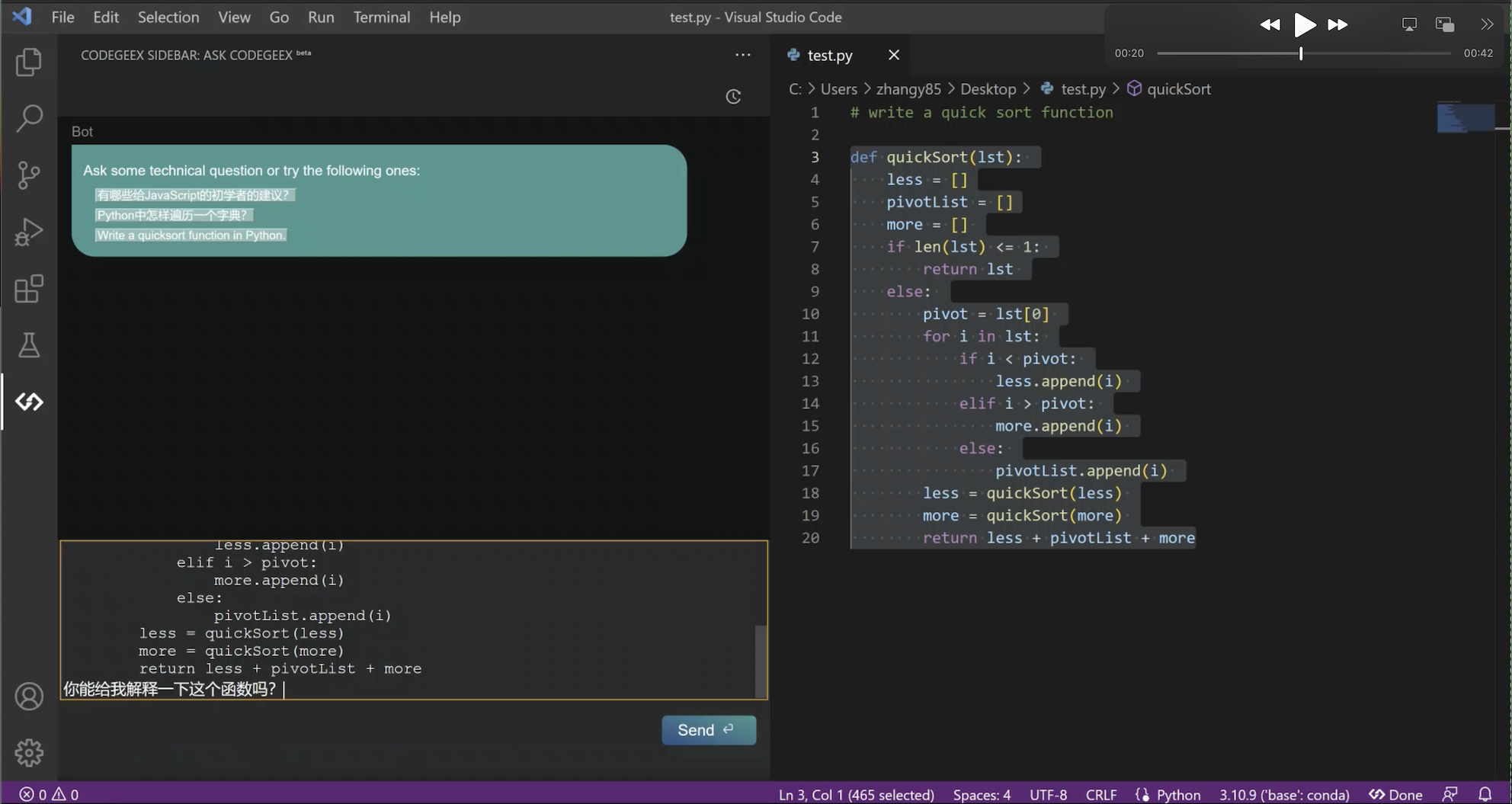
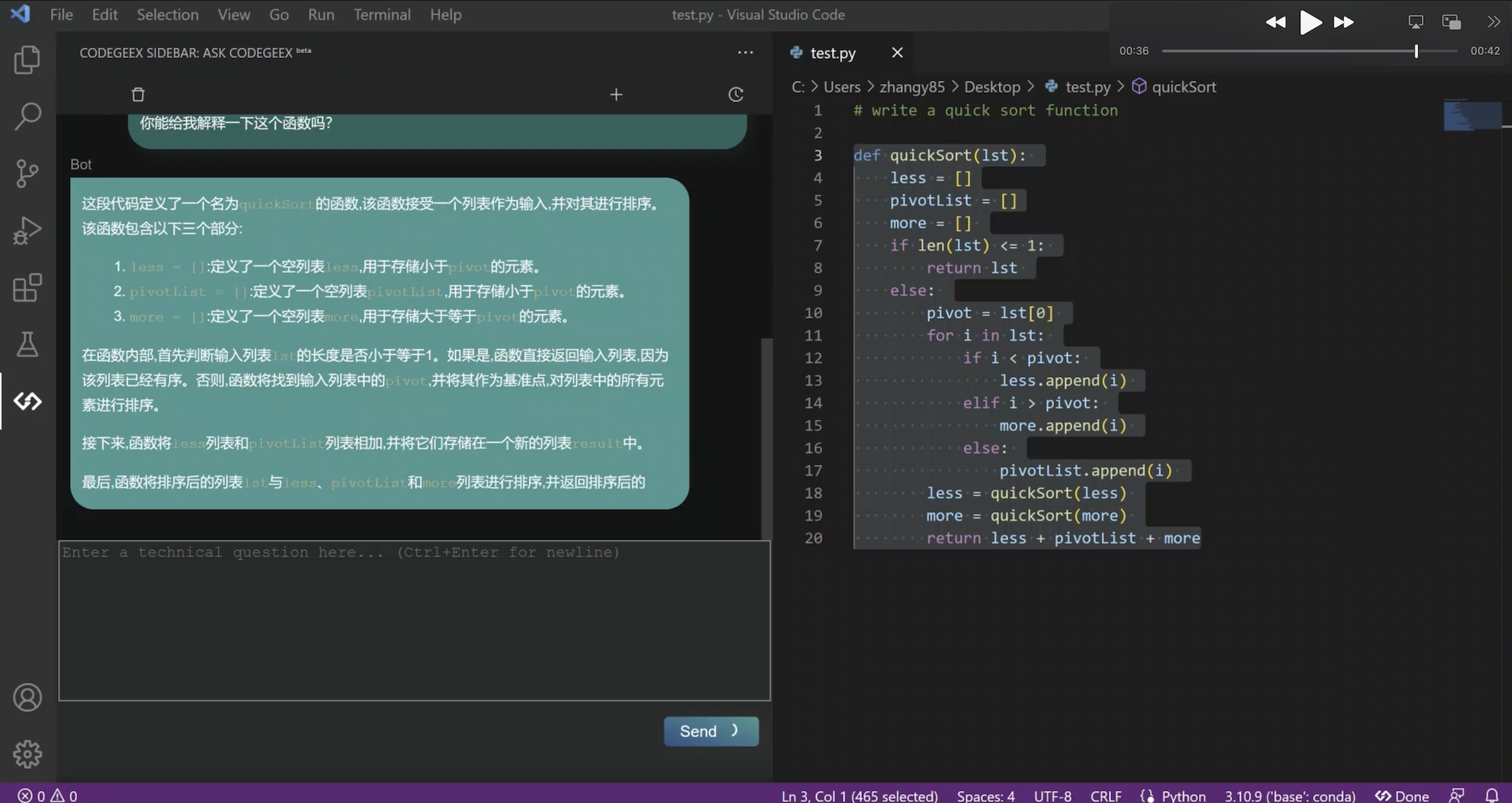
在大模型時代,編程推薦各位下載使用AI輔助編程工具CodeGeeX,
本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/554375.html
標籤:其他
上一篇:云原生周刊:開發人員使用 GPT-4 的 30 種重要方法 | 2023-6-5
下一篇:返回列表