引言
由于最近比較忙活沒時間學習新東西,現在得空想著能不能好好整理出一些有用的東西,讓記憶深刻一點,免得到時候實習找作業面試的時候一問三不知,也希望大家能指正出錯誤和對大家有點幫助,一起進步,加油奧里給!!!
那么廢話不多說直接進入正題,如果覺得可以家人們給個三連??!!!
正文
HTML+CSS
HTML5的新特性、語意化
語意化指對文本內容的結構化(內容語意化),選擇合乎語意的標簽(代碼語意化),便于開發者閱讀,維護和寫出更優雅的代碼的同時,讓瀏覽器的爬蟲和輔助技術更好的決議,通過使用恰當語意的HTML標簽,可以有效提高可訪問性、可檢索性、國際化和互用性,
優點:
- 在沒有 CSS 樣式的情況下頁面的排版結構也很清晰,便于閱讀,
- 可以讓頁面代碼結構更清晰,提高互用性,減少網頁間的差異性,幫助其他開發者了解網頁的結構,方便后期開發和維護,
- 還可以提高可訪問性,幫助輔助技術更好地閱讀和轉譯網頁,利于無障礙閱讀,
- 它們還可以提高國際化,讓各國開發者更容易弄懂網頁的結構,
新特性:
- 語意化標簽:
<header>、<footer>、<nav>、<aside>、<article>和<section> - 本地存盤:localStorage和sessionStorage
- 兼容特性:讓網頁在不同的瀏覽器中都能正常顯示,
- 2D/3D:讓網頁具有更豐富的視覺效果,
- 影片/過渡:讓網頁元素之間的變化更加平滑自然,
- 性能與集成:提高網頁的運行速度和穩定性,
- 多媒體標簽:
<audio>、<video> - CSS3 特性:可以讓網頁樣式更加豐富多彩,
- 新的表單控制元件:required、placeholder、autofocus、autocomplete、multiple
- input型別:color、date、email、month、number、search、tel、time、url、week
CSS3
層疊樣式表(Cascading Style Sheets,縮寫為 CSS)是一種樣式表語言,用來描述 HTML 或 XML(包括如 SVG、MathML 或 XHTML 之類的 XML 分支語言)檔案的呈現,CSS 描述了在螢屏、紙質、音頻等其他媒體上的元素應該如何被渲染的問題,CSS3 是 CSS(層疊樣式表)技術的升級版本,CSS演進的一個主要變化就是W3C決定將CSS3分成一系列模塊,
新特性:
- 選擇器:新的屬性選擇器、偽類選擇器和偽元素選擇器,增強了頁面元素的選擇范圍和對特定元素樣式的控制,
- 盒模型:引入了新的盒模型,使得我們可以通過box-sizing屬性來定義元素的盒模型是"content-box"(默認值)還是"border-box",深度影響了元素的計算寬度和高度值,
- 版式:新的版式屬性包括:多列版式、Flexbox、Grid等,增加了網頁版式的靈活性和復雜性,
- 背景影像:使用 background-size 屬性,CSS3 允許我們調整背景圖片的大小并讓其適應我們的容器,
- 過渡和影片:CSS3支持 創建平滑過渡 和 流暢影片 完成CSS的轉換效果,
- 漸變:我們可以使用CSS3 gradient屬性為元素添加漸變背景,漸變背景可以是線性的或徑向(環形)的,
- 字體:新增加字體嵌入@font-face、屬性font-stretch、text-shadow等,
- 陰影:強大的 CSS3 模糊陰影效果,我們可以使用box-shadow屬性模擬出漂亮的陰影效果,而不需要深入解決重影粒度問題,
- 圓角:CSS3 border-radius 屬性是圓角屬性,可以使我們輕松地實作不同圓角半徑的定制化效果,
- 彈性盒子模型:彈性盒子模型又叫Flexible Box布局模型,可用于徹底改變 Web 頁面的布局方式,
常用選擇器:
- ID選擇器: #id
- 類別選擇器: .class
- 元素選擇器: element
- 偽類選擇器: :link,:visited,:hover,:active,:focus
- 屬性選擇器: [attribute]
- 后代選擇器: A B
- 子元素選擇器:A > B
- 兄弟選擇器:A + B, A ~ B
- 通用選擇器: *
優先級順序:
- !important >
- 行內樣式 >
- ID選擇器 >
- 類選擇器/屬性選擇器/偽類選擇器 >
- 元素選擇器/偽元素選擇器 >
- 關系選擇器/通用選擇器
!important> 行內樣式 > ID選擇器 > 類別選擇器、屬性選擇器、偽類選擇器 > 元素選擇器 > 通配符 > 繼承
示例:
// 1. 使用ID選擇器:
#main-nav {
background-color: blue;
}
// 2. 元素選擇器:
div{
width:100%;
height:100%;
}
// 3. 使用類別選擇器:
.button {
background-color: red;
}
// 4. 使用屬性選擇器:
a[href^="https://"] {
color: green;
}
// 5. 使用偽類選擇器:
a:hover {
color: yellow;
}
// 6. 使用后代選擇器:
.main-nav ul {
padding: 0;
}
// 7. 使用子元素選擇器:
.main-nav > ul {
list-style-type: none;
}
// 8. 使用兄弟選擇器:
h1 + p {
font-size: 16px;
}
// 9. 使用通用選擇器:
* {
box-sizing: border-box;
}
CSS盒子模型和box-sizing屬性
CSS盒子模型(Box Model)是網頁布局的基礎,可以將頁面上所有元素看作一個個矩形的盒子,這些盒子由四個部分組成:內容區(content)、內邊距(padding)、邊框(border)、外邊距(margin),CSS盒子模型分為標準盒子模型和怪異盒子模型,這兩個概念與盒子模型的計算方式有關,
在CSS3中,通過box-sizing屬性可以控制盒子模型的計算方式,CSS3中的 box-sizing 屬性有三個值:content-box,border-box和inherit,
- content-box:默認值,模型的寬度和高度只包括內容,不包括邊框和內邊距,(標準盒子模型)
- border-box:模型的寬度和高度包括內容、內邊距和邊框,但不包括外邊距,(怪異盒子模型)
- inherit:繼承父元素的 box-sizing 值,
總結來說,box-sizing屬性用于控制盒子模型的計算方式,更改CSS盒子模型的大小計算方式,使得需要計算的尺寸更加精確和方便,
標準盒子模型:
標準盒子模型是CSS2.1規范定義的,也被稱為W3C盒子模型,在標準盒子模型下,一個元素的尺寸由其content(內容)的寬度、內邊距padding、邊框border和外邊距margin四個部分組成,其中content的大小可以通過width和height屬性進行設定,padding、border和margin的大小可以通過相應的屬性進行設定,
標準盒子模型的計算公式如下:
總寬度 =
width + padding-left + padding-right + border-left-width + border-right-width + margin-left + margin-right
總高度 =height + padding-top + padding-bottom + border-top-width + border-bottom-width + margin-top + margin-bottom
示例:
// HTML 代碼為:
<div >盒子模型</div>
// CSS 代碼為:
.box {
width: 200px;
height: 100px;
padding: 10px;
border: 5px solid #000;
margin: 0 auto;
}
怪異盒子模型
怪異盒子模型也被稱為IE盒子模型,是IE5~IE6瀏覽器采用的盒子模型,由于該模型與標準盒子模型不同,因此被稱為怪異盒子模型,
標準盒子模型的計算公式如下:
總寬度 = width + margin-left + margin-right
總高度 = height + margin-top + margin-bottom
也就是說,在怪異盒子模型中,內邊距和邊框的大小并沒有算入元素的總尺寸,(既 width 已經包含了 padding 和 border 值)
示例:
// HTML 代碼為:
<div >測驗盒子模型</div>
// CSS 代碼為:
.box {
width: 200px;
height: 100px;
padding: 10px;
border: 5px solid #000;
margin: 0 auto;
box-sizing: border-box; /* 顯示使用IE怪異盒子模型 */
}
解釋:當設定一個元素的box-sizing屬性為 border-box 時,即可使用怪異盒子模型進行盒子尺寸的計算,而采用其他值(如 content-box)則會使用標準盒子模型進行盒子尺寸的計算,
其實在默認的 content-box 模式下,盒子模型就是標準的盒子模型,元素的寬度和高度僅包含內容,不包括內邊距(padding)、邊框(border)和外邊距(margin),而使用設定為 border-box 的 box-sizing 屬性時,元素的寬度和高度包括了內邊距、邊框和內容,但不包括外邊距,
具體而言,在 content-box 模式下,當我們設定寬度為200px時,它并不包括 padding、border 和 margin 的尺寸,因此該元素的實際寬度可能會比我們期望的要大一些,而在 border-box 模式下,設定的寬度200px已經包含了 padding 和 border 的尺寸,因此該元素的實際寬度也就比較準確了,
總之,box-sizing 屬性可以更好地控制元素的尺寸計算方式,讓開發者更加方便地實作頁面布局效果,在實際開發中,應根據實際需求和頁面特點靈活選擇使用哪種盒子模型計算方式,
BFC和IFC
BFC和IFC是CSS布局中的概念,他們分別代表“塊級格式化背景關系”和“行內格式化背景關系”,
區別:
BFC是塊級格式化背景關系,它是一個獨立的布局環境,其中塊級盒子垂直排列,在BFC中,盒子的垂直邊距會發生折疊,浮動元素也會參與高度計算,
IFC是行內格式化背景關系,它是一種水平的格式化背景關系,其中行內級盒子從左到右水平排列,直到一行被填滿,然后換行,在IFC中,盒子的垂直對齊方式由vertical-align屬性決定,行高由包含該行內級盒子中最高的盒子決定,
BFC(塊級格式化背景關系)
BFC(Block Formatting Context),即塊級格式化背景關系,指的是一個獨立的塊級渲染區域(布局環境),它具有一定的隔離特性,內部元素的定位、清除浮動、高度塌陷等計算方式與外部元素保持獨立,
BFC的原理布局規則:
- 內部的Box會在垂直方向一個接著一個地放置,
- Box垂直方向上的距離由margin決定,屬于同一個BFC的兩個相鄰的Box的margin會發生重疊,
- 每個盒子的左外邊框緊挨著包含塊的左邊框,即使浮動元素也是如此,
- BFC的區域不會與float box重疊,
- 元素的型別和display屬性,決定了這個Box的型別,不同型別的Box會參與不同的Formatting Context(一個決定如何渲染檔案的容器),因此Box內的元素會以不同的方式渲染,
- 計算BFC的高度時,浮動子元素也參與計算,
擴展:Box是CSS布局的物件和基本單位,一個頁面是由很多個Box組成的,元素的型別和display屬性決定了這個Box的型別,
BFC的生成規則有如下幾條:
- 根元素即為一個BFC,
- 浮動元素(float不為none),
- 絕對定位元素(position為absolute或fixed),
- display值為inline-block、table-caption、flex、inline-flex、grid、inline-grid的元素,
- overflow值不為visible的塊元素,
示例:
// HTML 代碼為:
<div >
<div ></div>
<div ></div>
</div>
// CSS 代碼為:
.container {
border: 1px solid black;
overflow: hidden;
}
.box {
width: 100px;
height: 100px;
margin: 10px;
float: left;
background-color: lightblue;
}
解釋:在這個示例中,我們創建了一個BFC來包裹兩個浮動元素,通過設定 overflow:hidden,讓它會觸發BFC,在BFC中,BFC自適應高度,浮動元素也會參與高度計算,因此解決了浮動元素引發的高度塌陷問題,
應用場景:
- 解決浮動元素引發的高度塌陷問題,
- 防止垂直外邊距重疊,
- 創建自適應兩欄布局,
- 實作多列文本布局,
擴展:如果頁面布局造成了浮動塌陷,除了使用清除浮動(Clearfix)技術強制容器在浮動元素之后換行,還可以為容器設定一個觸發BFC的樣式,就是上面那個例子中為 container 設定了 overflow: hidde 的樣式,
IFC(行內格式化背景關系)
IFC指的是一個行內元素渲染區域,它是一種水平的格式化背景關系,具有一定的隔離特性,同一個IFC內部的元素在渲染時互相影響,但與外部元素不產生任何影響,在IFC中,盒子從左到右水平排列,直到一行被填滿,然后換行,行內級盒子的垂直對齊方式由 vertical-align 屬性決定,行高由包含該行內級盒子中最高的盒子決定,
IFC中的布局規則包括:
- 行內級盒子從左到右水平排列,
- 盒子的垂直對齊方式由vertical-align屬性決定,
- 行高由包含該行內級盒子中最高的盒子決定,
- 當一行被填滿時,盒子會換行,
IFC的生成規則有如下幾條:
- 根元素即為一個IFC,
- inline-block元素,
- 表格單元格(table-cell),
- display值為inline-flex、inline-grid的元素,
- img元素、input元素、textarea元素,
示例:
// HTML 代碼為:
<div >
<div ></div>
<div ></div>
<div ></div>
</div>
// CSS 代碼為:
.container {
border: 1px solid black;
width: 300px;
}
.box {
display: inline-block;
width: 100px;
height: 100px;
margin: 10px;
background-color: lightblue;
}
解釋:這里沒有用flex布局,有興趣的可以自己試一試噢!在這個例子中,我們有一個包含三個盒子的容器,盒子被設定為display: inline-block,這使它們成為行內塊級元素,由于容器的寬度只有300像素,所以第三個盒子會換行,
應用場景:
- 行內元素的居中對齊,
- 解決行內元素導致的空隙問題,
- 禁止文本被浮動元素覆寫,
- 實作多行文本的兩端對齊布局,
總而言之,BFC和IFC在CSS布局中扮演了至關重要的角色,可以解決很多常見的布局問題,對于理解CSS的渲染流程、排版規則有很大幫助,
頁面布局
在我的第一篇博客文章中有介紹了前端常見的十種布局方式,所以這里就不再詳細介紹了,大家可以去看看,我就簡單提一下就好了:
- 靜態布局:常見于pc端,是給頁面設定固定的寬高且居中布局,web網站開發的單位一般用px,
- 浮動布局:浮動布局是呼叫浮動屬性來使得元素向左或者向右移動從而共享一行,直到碰到包含框或者另一個浮動框,浮動元素是脫離檔案流的,不占據頁面空間,但不脫離文本流,且浮動會將行內元素和行內塊元素轉化為塊元素,
- 定位布局:定位布局是給元素設定 position 屬性從而控制元素顯示在不規則的位置,偏向于單個元素定位操作,
- 柵格布局:柵格布局也被稱為網格布局,它是一種新興的布局方式,常用的有瀑布流等,它的布局很簡單,就是把一個區域劃分為一個個的格子排列好,再把需要的元素填充進去,
- table布局:table 布局是在父元素使用 display:table; 子元素使用 display:table-row或 display:table-cell; 子元素會默認自動平均劃分父元素的空間,
- 彈性(flex)布局:flexible 模型又被稱為 flexbox,它不像柵格布局可以同時處理行跟列,只能處理單行或者當列,是一維的布局模型,
- 圣杯布局:圣杯布局跟雙飛翼的布局區別在于中間是否有包括兩邊的區域,圣杯布局是沒有的,兩邊或者一邊非主要部分填充父元素的 padding;而雙飛翼布局是有的,但多了一層 dom 節點,非主要部分用的是 center 部分的 margin 空間,
- 自適應布局:總結的來說就是創建多個靜態布局,每個布局對應一個螢屏的解析度范圍,每個靜態布局頁面的元素大小不會因為視窗的改變而變化,除非從一個靜態布局變到另外一個布局,不然在同一設備下還是固定的布局,常用的方式有使用 CSS 的 @media 媒體查詢,也有高成本的 JS 進行設計開發,或者使用第三方開源框架 bootstrap,這個能夠很好的支持多個瀏覽器,
- 流式布局:流式布局也叫百分比布局(也有叫非固定像素布局),是頁面中的元素根據螢屏解析度自動進行適配調整,頁面元素大小會發生變化,但是整體布局不會發生變化,始終都是滿屏顯示,它使用的是百分比定義寬,但高一般會被固定住,這種布局在早期是為了適應不同尺寸的PC螢屏,但現在在移動端比較常見,
- 回應式布局:回應式通過檢測視口解析度判斷是pc端、平板還是手機,針對不同的客戶端在客戶端做處理,來展示不同的布局和內容從而達到令人滿意的效果,螢屏大小的變化會導致元素的位置和大小都改變,可以說是流式布局和自適應布局的結合體,一套界面布局即可適應所有不同的尺寸和終端,可想而知設計考慮的比自適應復雜的多,
其他
偽類和偽元素
偽類和偽元素都是CSS選擇器,它們用來選擇檔案樹以外的元素,或者選擇檔案樹中無法用簡單選擇器表示的狀態,但它們之間有一些重要的區別,
偽類用來選擇元素的特殊狀態,例如,:hover偽類用來選擇滑鼠懸停在其上的元素,:focus偽類用來選擇獲得焦點的元素,偽類通常用于添加一些特殊的樣式,以反映元素的狀態,
偽元素用來創建一些不在檔案樹中的元素,并為其添加樣式,例如,::before偽元素用來在一個元素之前插入內容,::after偽元素用來在一個元素之后插入內容,偽元素通常用于添加裝飾性內容,
總之,偽類和偽元素的主要區別在于它們的作用物件不同,偽類作用于已經存在的元素,而偽元素創建新的元素,
長度單位px、em和rem
px、em和rem都是CSS中的長度單位,但它們之間有一些重要的區別,
px(像素)是一個絕對長度單位,它表示螢屏上的一個物理像素,由于不同設備的螢屏解析度不同,所以1px在不同設備上可能表示不同的物理尺寸,
em是一個相對長度單位,它相對于當前元素的字體大小,例如,如果一個元素的字體大小為16px,那么1em就等于16px,em單位常用于設定元素的字體大小、邊距和填充等屬性,
rem(root em)也是一個相對長度單位,它相對于根元素(元素)的字體大小,例如,如果根元素的字體大小為16px,那么1rem就等于16px,rem單位常用于實作回應式布局,
總之,px、em和rem的主要區別在于它們的參考系不同,px是絕對長度單位,而em和rem是相對長度單位,
position屬性
- static:默認值,元素按照正常檔案流進行定位,
- relative:元素按照正常檔案流進行定位,但可以通過top、right、bottom和left屬性相對于其正常位置進行偏移,
- absolute:元素脫離正常檔案流,相對于最近的非static定位祖先元素進行定位,如果沒有非static定位的祖先元素,則相對于初始包含塊進行定位,
- fixed:元素脫離正常檔案流,相對于瀏覽器視窗進行定位,
- sticky:元素在正常檔案流中,但可以根據用戶的滾動固定在指定位置,
想要了解更多或者詳細一點可以看我第一篇文章前端常見的十種布局方式中的定位布局,
讓一個元素水平垂直居中
常見方法:
- 使用flex布局:可以在父元素上設定 display: flex;,并且使用 align-items: center; 和 justify-content: center; 來實作水平垂直居中,
- 使用絕對定位和負邊距:可以在父元素上設定 position: relative;,然后在子元素上設定 position: absolute;,并且使用 top: 50%;、left: 50%; 和負邊距(例如 margin-top: -10px; margin-left: -10px;)來實作水平垂直居中,
- 使用絕對定位和transform:可以在父元素上設定 position: relative;,然后在子元素上設定 position: absolute;,并且使用 top: 50%;、left: 50%; 和 transform: translate(-50%, -50%); 來實作水平垂直居中,
- 使用表格布局:可以在父元素上設定 display: table-cell; vertical-align: middle; text-align:center; 來實作水平垂直居中,
- 使用網格布局:可以在父元素上設定 display: grid;,并且使用 place-items: center; 來實作水平垂直居中,
- 使用行內塊元素和文本對齊:可以在父元素上設定 text-align: center; 和 line-height: 200px;(其中200px是父元素的高度),然后在子元素上設定 display: inline-block; vertical-align: middle; 來實作水平垂直居中,
隱藏頁面中某個元素
常見方法:
- 使用 display: none;:這會將元素從頁面布局中完全移除,就像它從未存在過一樣,
- 使用 visibility: hidden;:這會將元素隱藏,但它仍然占據頁面布局中的空間,
- 使用 opacity: 0;:這會將元素的透明度設定為0,使其完全透明,但它仍然占據頁面布局中的空間,并且仍然可以與用戶互動(例如,可以點擊),
- 使用 position: absolute; 和 left: -9999px;:這會將元素移出螢屏外,使其不可見,
JS、ES6
ES6,全稱 ECMAScript 6.0,是 JavaScript 語言的下一代標準,于 2015 年 6 月正式發布,它為 JavaScript 帶來了許多新的語法特性和功能,使得 JavaScript 語言可以用來撰寫復雜的大型應用程式,成為企業級開發語言,
ES6 的一些主要新語法特性包括:
- 新的原始型別和變數宣告:let 和 const 關鍵字用于宣告塊級作用域的變數和常量,
- 箭頭函式:使用 => 符號定義函式,可以更簡潔地撰寫函式,
- 模板字串:使用反引號(`)定義字串,可以在字串中嵌入運算式,
- 解構賦值:允許從陣列或物件中提取值并賦值給變數,
- 類:使用 class 關鍵字定義類,支持繼承、建構式、靜態方法等面向物件編程特性,
- 模塊化:使用 import 和 export 關鍵字匯入和匯出模塊,
- Promise:用于處理異步操作的結果,
- 迭代器和生成器:支持迭代器和生成器,可以更方便地遍歷資料結構,
- Set 和 Map 資料結構:新增了 Set 和 Map 資料結構,用于存盤唯一值和鍵值對,
迭代器和生成器的簡單示例:
// 簡單的迭代器示例,它實作了一個next()方法,用于遍歷陣列中的元素:
function makeIterator(array) {
let nextIndex = 0;
return {
next: function() {
return nextIndex < array.length ?
{value: array[nextIndex++], done: false} :
{done: true};
}
};
}
let it = makeIterator(['a', 'b', 'c']);
console.log(it.next().value); // 'a'
console.log(it.next().value); // 'b'
console.log(it.next().value); // 'c'
console.log(it.next().done); // true
// 簡單的生成器示例,它使用yield運算式來暫停函式執行并回傳一個值:
function* idMaker() {
let index = 0;
while (true)
yield index++;
}
let gen = idMaker();
console.log(gen.next().value); // 0
console.log(gen.next().value); // 1
console.log(gen.next().value); // 2
資料型別
分為兩大類:包括值型別(基本物件型別)和參考型別(復雜物件型別)
值型別:字串(String)、數字(Number)、布爾(Boolean)、空(Null)、未定義(Undefined)、Symbol和BigInt,其中,Symbol是ES6引入的一種新的原始資料型別,表示獨一無二的值,
參考資料型別:物件(Object)、陣列(Array)和函式(Function),還有兩個特殊的物件:正則(RegExp)和日期(Date),
示例:
// 值型別
let myString = 'Hello, World!'; // 字串
let myNumber = 3.14; // 數字
let myBoolean = true; // 布爾
let myNull = null; // 空
let myUndefined = undefined; // 未定義
let mySymbol = Symbol(); // Symbol
let myBigInt = 123n; // BigInt
// 參考資料型別
let myObject = {name: '幼兒園技術家', age: 25}; // 物件
let myArray = [1, 2, 3]; // 陣列
let myFunction = function() {console.log('Hello, World!')}; // 函式
let myRegExp = /hello/i; // 正則運算式
let myDate = new Date(); // 日期
我相信大家很少見過 symbol 和 Bigint 吧,如果面試問到估計只有少部分大佬能聊出來(反正我不行),
先詳細解釋一下吧:
- Symbol是ES6中新增的一種基本資料型別,它表示獨一無二的值,每個通過Symbol()生成的值都是唯一的,Symbol可以用作物件的唯一屬性名,這樣其他人就不會改寫或覆寫你設定的屬性值,
- BigInt是ES10中新增的一種基本資料型別,它提供了一種方法來表示大于2^53-1的整數,BigInt可以表示任意大的整數,
示例:
let mySymbol = Symbol('mySymbol');
let obj = {};
obj[mySymbol] = 'Hello, World!';
console.log(obj[mySymbol]); // 輸出'Hello, World!'
let myBigInt = 1234567890123456789012345678901234567890n;
console.log(myBigInt * 2n); // 輸出2469135780246913578024691357802469135780n
好處:
Symbol的好處在于它能夠創建獨一無二的值,這樣就可以避免屬性名沖突的問題,例如,當你想要給一個物件添加一個新屬性時,你可以使用Symbol來創建一個唯一的屬性名,這樣就不用擔心這個屬性名會與物件中已有的屬性名沖突,
BigInt的好處在于它能夠表示任意大的整數,這樣就可以避免整數溢位的問題,例如,在對大整數進行數學運算時,以任意精度表示整數的能力尤為重要,有了BigInt,整數溢位將不再是一個問題,此外,你可以安全地使用高精度時間戳、大整數ID等,而不必使用任何變通方法,
資料型別常用檢測方法
1. typeof:typeof運算子可以回傳一個字串,表示未經計算的運算元的型別,優點在于它簡單易用,可以快速檢測基本資料型別,但它也有一些缺點,例如它無法區分Object、Array和Null,因為都會回傳"object",
示例:
console.log(typeof 'Hello, World!'); // 輸出'string'
console.log(typeof 3.14); // 輸出'number'
console.log(typeof true); // 輸出'boolean'
console.log(typeof undefined); // 輸出'undefined'
console.log(typeof null); // 輸出'object'
console.log(typeof Symbol()); // 輸出'symbol'
console.log(typeof 123n); // 輸出'bigint'
console.log(typeof {}); // 輸出'object'
console.log(typeof []); // 輸出'object'
console.log(typeof function() {}); // 輸出'function'
2. instanceof:instanceof運算子主要用于檢測參考資料型別,它用于檢測建構式的prototype屬性是否出現在某個實體物件的原型鏈上,因此,它并不適用于檢測所有資料型別,優點在于它可以檢測參考資料型別,判斷一個實體是否屬于某個類,但它也有一些缺點,例如它無法檢測基本資料型別,
示例:
console.log([] instanceof Array); // 輸出true
console.log({} instanceof Object); // 輸出true
console.log(function() {} instanceof Function); // 輸出true
3. Object.prototype.toString.call():這種方法可以用來檢測物件的型別,優點在于它可以準確地檢測所有資料型別,包括基本資料型別和參考資料型別,但它也有一些缺點,例如使用起來比較麻煩,需要呼叫Object.prototype.toString.call()方法,并傳入要檢測的值作為引數,
示例:
console.log(Object.prototype.toString.call('Hello, World!')); // 輸出'[object String]'
console.log(Object.prototype.toString.call(3.14)); // 輸出'[object Number]'
console.log(Object.prototype.toString.call(true)); // 輸出'[object Boolean]'
console.log(Object.prototype.toString.call(undefined)); // 輸出'[object Undefined]'
console.log(Object.prototype.toString.call(null)); // 輸出'[object Null]'
console.log(Object.prototype.toString.call(Symbol())); // 輸出'[object Symbol]'
console.log(Object.prototype.toString.call(123n)); // 輸出'[object BigInt]'
console.log(Object.prototype.toString.call({})); // 輸出'[object Object]'
console.log(Object.prototype.toString.call([])); // 輸出'[object Array]'
console.log(Object.prototype.toString.call(function() {})); // 輸出'[object Function]'
資料型別轉換方法
在JavaScript中,資料型別轉換分為兩種:隱式型別轉換和顯式型別轉換,
隱式型別轉換:指在運算程序中,JavaScript會自動將一種資料型別轉換為另一種資料型別,以便進行運算,例如,在字串和數字相加時,數字會被自動轉換為字串,然后進行字串拼接,
示例:
let x = '3' + 4; // x的值為'34'
let y = '3' - 4; // y的值為-1
顯式型別轉換:指通過呼叫特定的函式或方法來手動進行資料型別轉換,例如,可以使用Number()函式將字串轉換為數字,或使用String()函式將數字轉換為字串,
示例:
// 使用Number()函式將字串轉換為整數
let a = Number('3') + 4; // a的值為7
// 使用String()函式將整數轉換為字串
let b = String(3) + 4; // b的值為'34'
// 使用一元加號運算子將字串轉換為數字
let x = +'3'; // x的值為3
// 使用一元減號運算子將字串轉換為數字
let y = -'3'; // y的值為-3
// 使用parseInt()函式將字串轉換為整數
let a = parseInt('3.14'); // a的值為3
// 使用parseFloat()函式將字串轉換為浮點數
let b = parseFloat('3.14'); // b的值為3.14
// 使用toString()方法將數字轉換為字串
let c = (3).toString(); // c的值為'3'
深拷貝和淺拷貝
深拷貝和淺拷貝是針對參考資料型別(如Object和Array)的概念,淺拷貝只復制指向某個物件的指標,而不復制物件本身,新舊物件還是共享同一塊記憶體,但深拷貝會另外創造一個一模一樣的物件,新物件跟原物件不共享記憶體,修改新物件不會改到原物件,
當我們把一個物件賦值給一個新的變數時,賦的其實是該物件的在堆疊中的地址,而不是堆中的資料,也就是兩個物件指向的是同一個存盤空間,無論哪個物件發生改變,其實都是改變的存盤空間的內容,因此,兩個物件是聯動的,淺拷貝是按位拷貝物件,它會創建一個新物件,這個物件有著原始物件屬性值的一份精確拷貝,如果屬性是基本型別,拷貝的就是基本型別的值;如果屬性是記憶體地址(參考型別),拷貝的就是記憶體地址 ,因此如果其中一個物件改變了這個地址,就會影響到另一個物件,
實作方法
- 淺拷貝可以通過多種方法實作,例如,可以使用Object.assign()方法進行淺拷貝,也可以使用擴展運算子...進行淺拷貝,此外,還可以使用Array.prototype.concat()和Array.prototype.slice()方法對陣列進行淺拷貝,
示例:
// 使用Object.assign()進行淺拷貝:
let obj1 = { a: 1, b: { c: 2 } };
let obj2 = Object.assign({}, obj1);
obj1.b.c = 3;
console.log(obj2.b.c); // 輸出3,因為obj2.b和obj1.b指向同一個物件
// 使用擴展運算子...進行淺拷貝:
let obj1 = { a: 1, b: { c: 2 } };
let obj2 = {...obj1};
obj1.b.c = 3;
console.log(obj2.b.c); // 輸出3,因為obj2.b和obj1.b指向同一個物件
// 使用Array.prototype.concat()對陣列進行淺拷貝:
let arr1 = [1, 2, { a: 3 }];
let arr2 = arr1.concat();
arr1[2].a = 4;
console.log(arr2[2].a); // 輸出4,因為arr2[2]和arr1[2]指向同一個物件
// 使用Array.prototype.slice()對陣列進行淺拷貝:
let arr1 = [1, 2, { a: 3 }];
let arr2 = arr1.slice();
arr1[2].a = 4;
console.log(arr2[2].a); // 輸出4,因為arr2[2]和arr1[2]指向同一個物件
- 深拷貝可以通過多種方法實作,例如,可以使用遞回的方式實作深拷貝,也可以通過JSON物件實作深拷貝,即先使用JSON.stringify()將物件轉換為JSON字串,再使用JSON.parse()將字串決議成新的物件,
示例:
// 使用遞回實作深拷貝:
function deepClone(obj) {
if (typeof obj !== 'object' || obj === null) {
return obj;
}
let result = Array.isArray(obj) ? [] : {};
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
result[key] = deepClone(obj[key]);
}
}
return result;
}
let obj1 = { a: 1, b: { c: 2 } };
let obj2 = deepClone(obj1);
obj1.b.c = 3;
console.log(obj2.b.c); // 輸出2,因為obj2是obj1的深拷貝,它們之間沒有參考關系
// 使用JSON.stringify()和JSON.parse()實作深拷貝:
let obj1 = { a: 1, b: { c: 2 } };
let obj2 = JSON.parse(JSON.stringify(obj1));
obj1.b.c = 3;
console.log(obj2.b.c); // 輸出2,因為obj2是obj1的深拷貝,它們之間沒有參考關系
此外,還可以通過jQuery的extend方法實作深淺拷貝: extend()方法的第一個引數是一個布林值,用來指定是否進行深拷貝,如果該引數為true,則進行深拷貝;否則進行淺拷貝,
示例:
let obj1 = { a: 1, b: { c: 2 } };
let obj2 = jQuery.extend(true, {}, obj1);
obj1.b.c = 3;
console.log(obj2.b.c); // 輸出2,因為obj2是obj1的深拷貝,它們之間沒有參考關系
作用域鏈和閉包
作用域鏈
作用域鏈是指在JavaScript中,變數的查找機制,當代碼在一個環境中執行時,會創建變數物件的一個作用域鏈(scope chain),這個作用域鏈保證了對執行環境有權訪問的所有變數和函式的有序訪問,
作用域鏈的前端是當前執行環境的變數物件,如果這個執行環境是函式,則將其活動物件作為變數物件,活動物件在最開始時只包含一個變數,即arguments物件(這個物件在全域環境中是不存在的),作用域鏈中的下一個變數物件來自包含(外部)環境,再下一個變數物件則來自下一個包含環境,這樣一直延續到全域執行環境;全域執行環境的變數物件始終都是作用域鏈中的最后一個物件,
其實作用域鏈的理解比較簡單,就是當查找變數時,會從作用域鏈的前端開始,逐級向后查找,直到找到為止,如果在整個作用域鏈中都沒有找到該變數,則該變數未定義,
示例1(查找成功):
let x = 1;
function outer() {
let y = 2;
console.log(x + y);
}
outer(); // 輸出 3
示例2(查找失敗):
function outer() {
let y = 2;
console.log(x + y);
}
outer(); // 報錯:ReferenceError: x is not defined
閉包
閉包是指一個函式能夠訪問其定義時的詞法作用域,即使這個函式在其定義時的作用域之外執行,閉包可以讓你從內部函式訪問外部函式作用域,
在JavaScript中,函式在創建時會保存一個指向其定義時的詞法作用域的參考,當這個函式被呼叫時,它會使用這個參考來確定其外部變數的值,這就是閉包,
優點:
- 封裝:閉包可以用來封裝私有變數,防止外部訪問,
- 記憶:閉包可以用來記憶函式的狀態,例如計數器,
- 柯里化:閉包可以用來實作柯里化,即將一個多引數函式轉換為一系列單引數函式,
缺點:
- 記憶體占用:由于閉包會參考外部函式的變數,因此它會占用更多的記憶體,如果不需要使用閉包,應該及時釋放記憶體,
- 性能問題:由于閉包需要在作用域鏈中查找變數,因此它的性能可能不如直接訪問全域變數,
避免閉包導致的記憶體泄漏:
- 及時釋放不再使用的閉包,以便垃圾回收器可以回收它們占用的記憶體,
- 避免在閉包中捕獲不必要的變數,盡量只捕獲必要的變數,
- 注意回圈參考,避免在閉包中捕獲會導致回圈參考的變數,
我們常常使用的定時器、事件處理、Ajax請求等常用于異步操作用了回呼函式,但是回呼函式其實是可以使用閉包也可以不使用閉包的,并不是說回呼一定是在使用閉包,
回呼示例1(使用閉包):
let x = 1;
function doSomething(callback) {
// 執行一些操作
let result = x + 1;
// 呼叫回呼函式
callback(result);
}
doSomething(function(result) {
console.log(result); // 輸出 2
});
<!-- 在這個例子中,我們定義了一個全域變數x和一個函式doSomething,
doSomething函式接受一個回呼函式作為引數,
當我們呼叫doSomething時,它會執行一些操作,然后呼叫回呼函式,并將結果作為引數傳遞給回呼函式, -->
回呼示例2(不使用閉包):
function doSomething(callback) {
// 執行一些操作
let result = 1 + 1;
// 呼叫回呼函式
callback(result);
}
doSomething(function(result) {
console.log(result); // 輸出 2
});
<!-- 在這個例子中,我們定義了一個函式doSomething,它接受一個回呼函式作為引數,
當我們呼叫doSomething時,它會執行一些操作,然后呼叫回呼函式,并將結果作為引數傳遞給回呼函式, -->
那么閉包中定義的變數怎么回收呢?
在JavaScript中,記憶體管理是自動進行的,當一個變數不再被參考時,它所占用的記憶體就會被垃圾回收器回收,
在閉包中定義的變數也是如此,當閉包不再被參考時,它所參考的外部變數也就不再被參考,因此它們所占用的記憶體就會被垃圾回收器回收,
所以有兩種情況:
- 第一是當全域變數作為閉包變數的時候,那么閉包變數就會因為背景關系的存在(一直被參考)而保存到頁面關閉,
- 第二是當區域變數作為閉包變數的時候,其一是參考完畢立即回收(可以賦予null),其二是可以一直參考依然保存在記憶體中直到不再被參考則會回收,
第二種情況示例1(立即回收):
function fn() {
let x = 1;
return function() {
console.log(x);
}
}
for (let i = 0; i < 10; i++) {
fn()(); // 輸出10次1
}
<!-- 在這個例子中,fn是一個函式,它回傳一個匿名函式,
當我們在回圈中呼叫fn()時,它每次都會回傳一個新的匿名函式,并立即執行這個匿名函式,
由于這些匿名函式在執行完畢后就不再被參考,因此它們所占用的記憶體就會被垃圾回收器回收, -->
第二種情況示例2(等到不再參考則回收):
function fn() {
let x = 1;
return function() {
console.log(x++);
}
}
let closure = fn();
for (let i = 0; i < 10; i++) {
closure(); // 輸出 1,2,3,...,10
}
closure = null; // 釋放對閉包的參考
<!-- 在這個例子中,fn是一個函式,它回傳一個匿名函式,當我們呼叫fn()時,它回傳inner函式,并將其賦值給closure變數,
當我們在回圈中呼叫closure()時,它每次都會輸出遞增的值,即fn函式內部定義的變數x的值,
由于x在每次呼叫閉包時都會自增1,因此每次輸出的都是遞增的值,在回圈結束后,我們將closure變數賦值為null,這樣就釋放了對閉包的參考, -->
經典面試題
涉及for回圈和閉包:
var data = https://www.cnblogs.com/zxlh1529/archive/2023/06/06/[];
for (var i = 0; i < 3; i++) {
data[i] = function () {
console.log(i);
};
}
data[0](); // 輸出什么?
data[1](); // 輸出什么?
data[2](); // 輸出什么?
// 連續輸出3個3
如果預期輸出1、2、3,使用閉包改善:
var data = https://www.cnblogs.com/zxlh1529/archive/2023/06/06/[];
for (var i = 0; i < 3; i++) {
(function (j) {
data[j] = function () {
console.log(j);
};
})(i);
}
data[0](); // 輸出1
data[1](); // 輸出2
data[2](); // 輸出3
原型和原型鏈
原型(prototype)是一個物件,它是用來創建其他物件的模板,每個函式都有一個 prototype 屬性,它指向該函式的原型物件,
原型鏈是由一系列原型物件組成的鏈條,每個物件都有一個原型物件與之關聯,這個原型物件也是一個普通物件,它也有自己的原型物件,這樣層層遞進,就形成了一個鏈條,這個鏈條就是原型鏈,
原型鏈的作用是實作繼承,當訪問一個物件的屬性時,如果該屬性不存在于該物件中,則會沿著原型鏈向上查找,直到找到該屬性或者到達原型鏈的頂端,
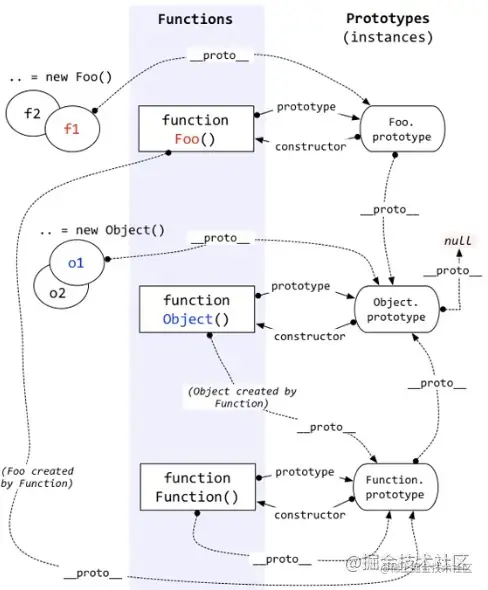
原型關系: 指的是物件與其原型物件之間的關系,每個物件都有一個內部屬性 [[Prototype]],它指向該物件的原型物件,在 JavaScript 中,可以通過 __proto__ 屬性來訪問這個內部屬性,
示例:
// 假設我們有一個建構式 Person 和一個實體物件 p:
function Person(name) {
this.name = name;
}
Person.prototype.sayName = function() {
console.log(this.name);
}
var p = new Person('Tom');
// 在這個例子中,p 的原型物件就是 Person.prototype,我們可以通過 p.__proto__ 來訪問它:
console.log(p.__proto__ === Person.prototype); // true
ES6新語法特性:let && const
ES6之前創建變數用的是var,之后創建變數用的是let/const,當然也會用var,那么區別在哪呢?
var,let和const都是用來宣告變數的,但它們之間有一些區別,var宣告的變數屬于函式作用域,而let和const宣告的變數屬于塊級作用域,此外,var宣告的變數存在變數提升現象,而let和const沒有,在同一塊級作用域中,let變數不能重新宣告,而const常量不能修改,簡單的來說就是,var定義全域變數且可以覆寫,let定義塊級作用域變數且不能再一次進行宣告({}),const定義不允許修改的塊級作用域常量,
示例:
function exampleVar() {
var x = 1;
if (true) {
var x = 2;
console.log(x); // 輸出2
}
console.log(x); // 輸出2
}
function exampleLet() {
let x = 1;
if (true) {
let x = 2;
console.log(x); // 輸出2
}
console.log(x); // 輸出1
}
function exampleConst() {
const x = 1;
if (true) {
const x = 2;
console.log(x); // 輸出2
}
console.log(x); // 輸出1
}
解釋:
在exampleVar函式中,由于var宣告的變數屬于函式作用域,所以在if陳述句塊中重新宣告的變數x會覆寫函式作用域中的變數x,
而在exampleLet和exampleConst函式中,由于let和const宣告的變數屬于塊級作用域,所以在if陳述句塊中宣告的變數x不會影響到外部作用域中的變數x,
this指向問題
在JavaScript中,this關鍵字指向函式執行時的當前物件,this的指向取決于函式呼叫的方式,而不是函式定義的位置,
- 在全域作用域中,this指向全域物件(在瀏覽器中是window物件,在Node.js中是global物件),
- 在函式呼叫中,如果函式不是作為物件的方法被呼叫,那么this指向全域物件,
- 在作為物件方法呼叫時,this指向呼叫該方法的物件,
- 在建構式中,this指向新創建的物件,
- 在事件處理程式中,this指向觸發事件的元素,
此外,可以使用call()、apply()和bind()方法顯式地設定函式呼叫時的this值,
示例:
// 1.在全域作用域中,this指向全域物件:
console.log(this === window); // 輸出true(在瀏覽器中)
// 2.在函式呼叫中,如果函式不是作為物件的方法被呼叫,那么this指向全域物件:
function foo() {
console.log(this === window); // 輸出true(在瀏覽器中)
}
foo();
// 3.在作為物件方法呼叫時,this指向呼叫該方法的物件:
let obj = {
myMethod: function() {
console.log(this === obj); // 輸出true
}
};
obj.myMethod();
// 4.在建構式中,this指向新創建的物件:
function MyConstructor() {
this.myProperty = 'Hello World!';
console.log(this instanceof MyConstructor); // 輸出true
}
let myInstance = new MyConstructor();
// 5.在事件處理程式中,this指向觸發事件的元素:
<button id="myButton">點擊!</button>
<script>
let button = document.getElementById('myButton');
button.onclick = function() {
console.log(this === button); // 輸出true
};
</script>
// 6.使用call()、apply()和bind()方法顯式地設定函式呼叫時的this值:
function foo() {
console.log(this);
}
let obj = { a: 1 };
foo.call(obj); // 輸出{ a: 1 }
foo.apply(obj); // 輸出{ a: 1 }
let bar = foo.bind(obj);
bar(); // 輸出{ a: 1 }
此外還有一些特殊情況會影響this的指向問題:
- 在嚴格模式下,如果函式不是作為物件的方法被呼叫,那么this的值為undefined,
- 在DOM事件處理程式中,如果使用addEventListener()方法添加事件處理程式,那么事件處理程式中的this指向觸發事件的元素,但是,如果使用attachEvent()方法(僅在舊版本的IE中可用),那么事件處理程式中的this指向全域物件,
- 在回呼函式中,this的指向取決于回呼函式被呼叫的方式,例如,在setTimeout()和setInterval()中,回呼函式中的this指向全域物件,在陣列方法(如forEach()、map()、filter()等)中,回呼函式中的this指向全域物件,除非顯式地設定了thisArg引數,
- 在箭頭函式中,this的值取決于箭頭函式定義時所在的背景關系,箭頭函式不會創建自己的this值,而是從外層作用域繼承this值,
- 如果使用了ES6的類語法,那么類中的方法默認是在嚴格模式下執行的,因此類方法中的this指向取決于方法呼叫的方式,
示例:
// 1.在嚴格模式下,函式呼叫中的this指向undefined:
'use strict';
function foo() {
console.log(this);
}
foo(); // 輸出undefined
// 2.在DOM事件處理程式中,使用addEventListener()方法添加事件處理程式,事件處理程式中的this指向觸發事件的元素:
<button id="myButton">Click me!</button>
<script>
let button = document.getElementById('myButton');
button.addEventListener('click', function() {
console.log(this); // 輸出<button id="myButton">Click me!</button>
});
</script>
// 3.在回呼函式中,this的指向取決于回呼函式被呼叫的方式:
// 在setTimeout()中,回呼函式中的this指向全域物件
setTimeout(function() {
console.log(this === window); // 輸出true(在瀏覽器中)
}, 1000);
// 在陣列方法中,回呼函式中的this指向全域物件,除非顯式地設定了thisArg引數
let arr = [1, 2, 3];
arr.forEach(function() {
console.log(this === window); // 輸出true(在瀏覽器中)
});
arr.forEach(function() {
console.log(this === obj);
}, obj); // 輸出true
// 4.在箭頭函式中,this的值取決于箭頭函式定義時所在的背景關系:
let obj = {
myMethod: function() {
let arrowFunction = () => {
console.log(this === obj); // 輸出true
};
arrowFunction();
}
};
obj.myMethod();
// 5.在類方法中,this指向取決于方法呼叫的方式:
class MyClass {
myMethod() {
console.log(this);
}
}
let myInstance = new MyClass();
myInstance.myMethod(); // 輸出MyClass實體
let myMethod = myInstance.myMethod;
myMethod(); // 輸出undefined(在嚴格模式下)或全域物件(在非嚴格模式下)
EventLoop 事件回圈
EventLoop 即 事件回圈,是指瀏覽器或 Node 的一種解決 javaScript 單執行緒運行時不會阻塞的一種機制,也就是我們經常使用異步的原理,
JavaScript 運行時包含了一個待處理訊息的訊息佇列,每一個訊息都關聯著一個用以處理這個訊息的回呼函式,在事件回圈期間的某個時刻,運行時會從最先進入佇列的訊息開始處理佇列中的訊息,被處理的訊息會被移出佇列,并作為輸入引數來呼叫與之關聯的函式,
這個模型與其他語言中的模型截然不同,比如 C 和 Java,它永不阻塞,處理 I/O 通常通過事件和回呼來執行,所以當一個應用正等待一個 IndexedDB 查詢回傳或者一個 XHR 請求回傳時,它仍然可以處理其他事情,比如用戶輸入,
宏任務和微任務
在 JavaScript 引擎中,任務分為兩種型別:微任務(microtask)和宏任務(macrotask),微任務是指在當前任務執行結束后立即執行的任務,它可以看作是在當前任務的“尾巴”添加的任務,常見的微任務包括 Promise 回呼和 process.nextTick,宏任務是指在下一輪事件回圈中執行的任務,常見的宏任務包括 setTimeout、setInterval、setImmediate、requestAnimationFrame 等,
微任務和宏任務是系結的,每個宏任務在執行時,會創建自己的微任務佇列,比如一個宏任務在執行程序中,產生了 100 個微任務,執行每個微任務的時間是 10 毫秒,那么執行這 100 個微任務的時間就是 1000 毫秒,也可以說這 100 個微任務讓宏任務的執行時間延長了 1000 毫秒,
宏任務和微任務與事件回圈有著密切的關系,在事件回圈中,每個宏任務執行完后,都會檢查微任務佇列并執行佇列中的所有微任務,然后再執行下一個宏任務,這個程序會一直重復,直到佇列中沒有訊息為止,
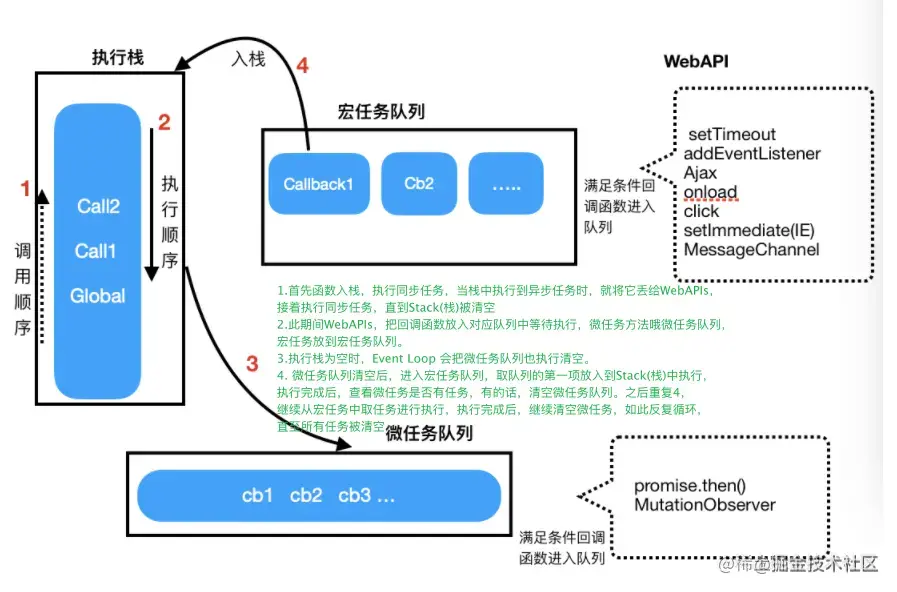
示例:
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
Promise.resolve().then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');
// 輸出結果:
script start
script end
promise1
promise2
setTimeout
解釋:首先,同步代碼 console.log('script start') 和 console.log('script end') 被執行,然后,setTimeout 被添加到宏任務佇列中,接著,Promise.resolve().then 中的回呼被添加到微任務佇列中,當同步代碼執行完后,事件回圈檢查微任務佇列并執行佇列中的所有微任務,即 console.log('promise1') 和 console.log('promise2'),最后,事件回圈執行下一個宏任務,即 setTimeout 中的回呼,
setTimeout Promise Async/Await 的區別
- setTimeout 是 JavaScript 中的一個異步函式,用于在指定的時間間隔后執行一段代碼,它屬于延遲方法,會被放到最后,也就是主執行緒空閑的時候才會觸發,
- Promise 是 JavaScript 中的一種物件,用于處理異步操作的結果,它本身是同步的立即執行函式,當在執行體中執行 resolve() 或者 reject() 的時候,此時是異步操作,會先執行 then/catch 等,等主堆疊完成后,才會去執行 resolve()/reject() 中的方法,
- Async/Await 是 JavaScript 中的一種語法,用于處理異步操作,使代碼看起來像同步代碼一樣,async 用于定義一個異步函式,await 用于等待異步操作的結果,當遇到 await 的時候,會讓出主執行緒,阻塞后面的代碼的執行,async 函式需要等待 await 后的函式執行完成并且有了回傳結果(Promise 物件)之后,才能繼續執行下面的代碼,
優先級:
Promise 的回呼屬于微任務,所以它會在當前宏任務執行完后立即執行,
setTimeout 屬于宏任務,所以它會在下一輪事件回圈中執行,
Async/Await 是基于 Promise 的語法糖,它能實作的效果都能用 then 鏈來實作,當遇到 await 的時候,會讓出主執行緒,阻塞后面的代碼的執行,所以 await 后面的代碼相當于 promise.then() 里面的代碼,
示例:
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
Promise.resolve().then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
async function async1() {
console.log('async1 start');
await async2();
console.log('async1 end');
}
async function async2() {
console.log('async2');
}
async1();
console.log('script end');
// 輸出結果:
script start
async1 start
async2
script end
promise1
promise2
async1 end
setTimeout
解釋: 首先,同步代碼 console.log('script start')、console.log('async1 start')、console.log('async2') 和 console.log('script end') 被執行,然后,setTimeout 被添加到宏任務佇列中,接著,Promise.resolve().then 中的回呼被添加到微任務佇列中,當同步代碼執行完后,事件回圈檢查微任務佇列并執行佇列中的所有微任務,即 console.log('promise1') 和 console.log('promise2'),最后,事件回圈執行下一個宏任務,即 setTimeout 中的回呼,
節流&&觸底加載 防抖&&實時搜索
節流
節流(Throttle)是一種控制函式執行頻率的技術,當事件被頻繁觸發時,節流函式會按照一定的頻率來執行函式,它可以保證在一段時間內,不管事件觸發了多少次,函式都只會執行一次,且是最先被觸發呼叫的那次,
舉個例子,假設你正在滾動一個頁面,每滾動一段距離就會觸發一個事件,如果這個事件被頻繁觸發,可能會導致頁面卡頓,這時候,你可以使用節流來控制事件的執行頻率,讓它每隔一段時間才執行一次,
節流通常用于優化性能,避免因為事件觸發過于頻繁而導致的頁面卡頓或瀏覽器崩潰,
場景:
- 滾動事件:當用戶滾動頁面時,可以使用節流來控制滾動事件的執行頻率,讓它每隔一段時間才執行一次,
- 視窗大小調整:當用戶調整瀏覽器視窗大小時,可以使用節流來控制調整事件的執行頻率,讓它每隔一段時間才執行一次,
- 滑鼠移動:當用戶移動滑鼠時,可以使用節流來控制滑鼠移動事件的執行頻率,讓它每隔一段時間才執行一次,
滾動事件當然是 觸底加載 比較多了,現在用這個作為示例:
// 節流函式
function throttle(fn, delay) {
let timer = null;
return function() {
if (!timer) {
timer = setTimeout(() => {
fn.apply(this, arguments);
timer = null;
}, delay);
}
}
}
// 加載函式
function loadMore() {
// 加載更多內容
console.log('Loading more content...');
}
// 監聽滾動事件
window.addEventListener('scroll', throttle(function() {
// 滾動到頁面底部時觸發加載函式
if (document.documentElement.scrollTop + window.innerHeight === document.documentElement.scrollHeight) {
loadMore();
}
}, 500));
解釋: 在這個例子中,我們定義了一個節流函式 throttle,它接受兩個引數:一個是要執行的函式 fn,另一個是延遲時間 delay,當事件被觸發時,節流函式會按照指定的頻率來執行函式,然后,我們定義了一個加載函式 loadMore,用來加載更多內容,接著,我們監聽了滾動事件,并使用節流函式來控制加載函式的執行頻率,當滾動到頁面底部時,會觸發加載函式,
防抖
防抖(Debounce)是一種控制函式執行頻率的技術,當事件被頻繁觸發時,防抖函式會推遲執行函式,只有當等待一段時間后也沒有再次觸發該事件,那么才會真正執行函式,
舉個例子,假設你正在輸入一個搜索關鍵詞,每輸入一個字符就會觸發一個搜索事件,如果這個事件被頻繁觸發,可能會導致頁面卡頓或瀏覽器崩潰,這時候,你可以使用防抖來控制搜索事件的執行頻率,讓它在用戶停止輸入一段時間后才執行,
防抖通常用于優化性能,避免因為事件觸發過于頻繁而導致的頁面卡頓或瀏覽器崩潰,
場景:
- 輸入框實時搜索:當用戶在輸入框中輸入內容時,可以使用防抖來控制搜索事件的執行頻率,讓它在用戶停止輸入一段時間后才執行,
- 視窗大小調整:當用戶調整瀏覽器視窗大小時,可以使用防抖來控制調整事件的執行頻率,讓它在用戶停止調整一段時間后才執行,
- 按鈕點擊:當用戶點擊一個按鈕時,可以使用防抖來防止用戶連續點擊,避免重復提交表單,
那么就用 實時搜索 作為示例:
// 防抖函式
function debounce(fn, delay) {
let timer = null;
return function() {
clearTimeout(timer);
timer = setTimeout(() => {
fn.apply(this, arguments);
}, delay);
}
}
// 搜索函式
function search(keyword) {
// 執行搜索操作
console.log(`Searching for ${keyword}...`);
}
// 獲取輸入框元素
const input = document.querySelector('input');
// 監聽輸入事件
input.addEventListener('input', debounce(function(event) {
// 獲取輸入框的值
const keyword = event.target.value;
// 執行搜索操作
search(keyword);
}, 500));
解釋: 在這個例子中,我們定義了一個防抖函式 debounce,它接受兩個引數:一個是要執行的函式 fn,另一個是延遲時間 delay,當事件被觸發時,防抖函式會推遲執行函式,如果在等待時間內再次觸發該事件,那么會重新計算等待時間,然后,我們定義了一個搜索函式 search,用來執行搜索操作,接著,我們獲取了輸入框元素,并監聽了輸入事件,當用戶在輸入框中輸入內容時,會觸發輸入事件,我們使用防抖函式來控制搜索函式的執行頻率,讓它在用戶停止輸入一段時間后才執行,
垃圾回識訓制
JavaScript 的垃圾回識訓制是用來防止記憶體泄漏的,記憶體泄漏指的是當已經不需要某塊記憶體時,這塊記憶體還存在著,在專案中,如果存在大量不被釋放的記憶體(堆/堆疊/背景關系),頁面性能會變得很慢,當某些代碼操作不能被合理釋放,就會造成記憶體泄漏,垃圾回識訓制就是間歇性地、不定期地尋找到不再使用的變數,并釋放掉它們所指向的記憶體,
JavaScript 的垃圾回收演算法主要有兩種:參考計數(reference counting)和標記清除(mark-and-sweep),
參考計數演算法通過跟蹤每個值被參考的次數來作業,當宣告了一個變數并將一個參考型別值賦給該變數時,則這個值的參考次數就是 1,如果同一個值又被賦給另一個變數,則該值的參考次數加 1,相反,如果包含對這個值參考的變數又取得了另外一個值,則這個值的參考次數減 1,當這個值的參考次數變成 0 時,則說明沒有辦法再訪問這個值了,因此就可以將其占用的記憶體空間回識訓來,
標記清除演算法將“不再使用的變數”定義為“無法訪問到這個變數”,垃圾收集器在運行的時候會給存盤在記憶體中的所有變數都加上標記(可以使用任何標記方式),然后,它會去掉環境中的變數以及被環境中的變數參考的變數的標記,而在此之后再被加上標記的變數即為準備洗掉的變數,原因是環境中的變數已經無法訪問到這些變數了,最后,垃圾收集器完成記憶體清除作業,銷毀那些帶標記的值并回收它們所占用的記憶體空間,
其他
new
程序:
- 首先,創建一個全新的物件,然后,將這個物件的原型鏈(proto)指向函式的 .prototype,
- 接著,將這個物件系結到函式中的 this,然后執行函式,函式內部可以借助 this 給這個物件添加屬性,
- 最后,如果這個函式沒有回傳其他物件的話,new 運算子就會將上面步驟創建的物件回傳出去,但如果該函式最后回傳了一個其他物件的話,new 運算子就會把這個函式回傳的物件回傳出去,也就是判斷函式的回傳值型別,如果是值型別,回傳創建的物件,如果是參考型別,就回傳這個參考型別的物件,
示例:
function Person(name, age) {
this.name = name;
this.age = age;
}
var person1 = new Person('幼兒園技術家', 25);
console.log(person1.name); // 輸出: 幼兒園技術家
console.log(person1.age); // 輸出: 25
三種常用方法實作繼承
- 使用原型鏈,
示例:
function Animal(name) {
this.name = name;
}
Animal.prototype.sayName = function() {
console.log(this.name);
}
function Dog(name, breed) {
Animal.call(this, name);
this.breed = breed;
}
Dog.prototype = Object.create(Animal.prototype);
Dog.prototype.constructor = Dog;
Dog.prototype.bark = function() {
console.log('Woof!');
}
let dog = new Dog('Max', 'German Shepherd');
dog.sayName(); // Max
dog.bark(); // Woof!
- 使用 class 關鍵字來定義類,并使用 extends 關鍵字來實作繼承,
示例:
class Animal {
constructor(name) {
this.name = name;
}
sayName() {
console.log(this.name);
}
}
class Dog extends Animal {
constructor(name, breed) {
super(name);
this.breed = breed;
}
bark() {
console.log('Woof!');
}
}
let dog = new Dog('Max', 'German Shepherd');
dog.sayName(); // Max
dog.bark(); // Woof!
- 使用混入(Mixin),
示例:
let Animal = {
sayName: function() {
console.log(this.name);
}
}
function Dog(name, breed) {
this.name = name;
this.breed = breed;
}
Object.assign(Dog.prototype, Animal);
Dog.prototype.bark = function() {
console.log('Woof!');
}
let dog = new Dog('Max', 'German Shepherd');
dog.sayName(); // Max
dog.bark(); // Woof!
手寫bind方法
// 可以通過在 Function.prototype 上添加一個新方法來手寫實作 bind 方法
Function.prototype.myBind = function(context) {
var self = this;
var args = Array.prototype.slice.call(arguments, 1);
return function() {
var bindArgs = Array.prototype.slice.call(arguments);
return self.apply(context, args.concat(bindArgs));
}
}
var obj = {
name: '幼兒園技術家'
}
function sayName(age) {
console.log(this.name);
console.log(age);
}
var boundSayName = sayName.myBind(obj, 25);
boundSayName(); // 輸出: 幼兒園技術家 \n 25
解釋:在上面的示例中,我們定義了一個 myBind 方法,它接受一個引數 context,表示系結的背景關系物件,然后我們使用 apply 方法將函式的執行背景關系系結到指定的物件上,并傳入相應的引數,最后我們可以呼叫系結后的函式,
CmmonJS和ESM
CommonJS和ESM是兩種不同的JavaScript模塊化規范,CommonJS主要用于服務器端,比如Node.js,而ESM是ECMAScript 6中引入的模塊化標準,它既可以用于前端,也可以用于后端,
CommonJS和ESM之間有一些主要區別:
首先,它們的語法不同,CommonJS使用 require 和 module.exports 來匯入和匯出模塊,而ESM使用 import 和 export 關鍵字,
其次,CommonJS模塊是運行時加載的,而ESM模塊是編譯時輸出介面的,此外,CommonJS是同步加載模塊的,而ESM支持異步加載,
示例:
// CommonJS
var foo = require('foo');
module.exports = foo;
// ESM
import foo from 'foo';
export default foo;
柯里化
在上面的閉包中我們有提到柯里化,那么這里簡單介紹一下,要思考柯里化是什么?有什么用?怎么實作?
柯里化(Currying)是一種處理多元函式的方法,它是指將一個多引數的函式轉化為單引數函式的方法,它是數學家柯里(Haskell Curry)提出的,
柯里化的主要作用是將一個復雜的函式拆分成多個簡單的函式,使得每個函式只接受一個引數,這樣做可以讓我們更靈活地使用這些函式,比如可以將它們組合起來,或者將它們作為引數傳遞給其他函式,
示例:
function add(x, y) {
return x + y;
}
function curriedAdd(x) {
return function(y) {
return add(x, y);
}
}
var add5 = curriedAdd(5);
console.log(add5(3)); // 輸出: 8
call bind apply
在解決this指向問題中提到了call、apply 和 bind,那么現在來介紹一下,
call、apply 和 bind 都是JavaScript中的函式方法,它們都可以用來改變函式的執行背景關系(即函式內部的 this 指向),
call 和 apply 的作用相似,它們都可以用來立即呼叫一個函式,并指定函式內部的 this 指向,它們的區別在于傳遞引數的方式不同:call 方法接受若干個引數,第一個引數是 this 指向的物件,后面的引數依次傳遞給函式;而 apply 方法接受兩個引數,第一個引數是 this 指向的物件,第二個引數是一個陣列,陣列中的元素依次傳遞給函式,
bind 方法與 call 和 apply 不同,它不會立即呼叫函式,而是回傳一個新的函式,這個新函式與原函式具有相同的行為,但是它內部的 this 指向被系結到了 bind 方法的第一個引數上,除了第一個引數外,bind 方法還可以接受若干個引數,這些引數會被預先傳遞給新函式,
示例:
function sayName(greeting) {
console.log(`${greeting}, my name is ${this.name}`);
}
var obj = {
name: '幼兒園技術家'
}
sayName.call(obj, 'Hello'); // 輸出: Hello, my name is 幼兒園技術家
sayName.apply(obj, ['Hello']); // 輸出: Hello, my name is 幼兒園技術家
var boundSayName = sayName.bind(obj);
boundSayName('Hello'); // 輸出: Hello, my name is 幼兒園技術家
Vue
Vue (發音為 /vju?/,類似 view) 是一款用于構建用戶界面的 JavaScript 框架,它基于標準 HTML、CSS 和 JavaScript 構建,并提供了一套宣告式的、組件化的編程模型,幫助你高效地開發用戶界面,
Vue 是一個典型的 MVVM 模型的框架,MVVM 是 Model-View-ViewModel 的縮寫,它是一種基于前端開發的架構模式,其核心是提供對 View 和 ViewModel 的雙向資料系結,這使得 ViewModel 的狀態改變可以自動傳遞給 View,即所謂的資料雙向系結,
優點:
- 易于學習和使用:Vue提供了一個平滑的學習曲線,使其適用于初學者和專業開發人員,它有著豐富的檔案和教程,并且有著龐大的社區支持,
- 高性能:Vue使用虛擬DOM來提高應用的性能和渲染效率,虛擬DOM是一個輕量級的JavaScript物件,它是真實DOM的抽象表示,當組件的狀態發生變化時,Vue會根據新的狀態創建一個新的虛擬DOM樹,然后,Vue會使用一個高效的演算法來比較新舊虛擬DOM樹,計算出最小的更新操作來更新真實DOM,
- 靈活性:Vue非常靈活,可以與現有專案無縫集成,它提供了許多高級功能,如計算屬性、偵聽器和過渡效果等,可以幫助開發人員更快地構建復雜的應用程式,
缺點:
- 生態系統不夠成熟:相比其他前端框架,Vue的生態系統不夠成熟,它缺少一些高質量的插件和工具,這可能會影響開發人員的作業效率,
- 檔案不足:盡管Vue有著豐富的檔案和教程,但由于其快速發展,有時檔案可能不夠完整或過時,
- 學習曲線陡峭:盡管Vue相對容易學習,但要真正掌握它并開發復雜的應用程式仍然需要一定的時間和精力,
既然提到了 mvvm,那么就簡單說一下 MVC 以及 MVVM 和 MVC 之間的區別:
MVC 和 MVVM 都是一種設計模式,它們都旨在將應用程式分成不同的部分,以便更好地管理和維護,
MVC
MVC 是 Model-View-Controller 的縮寫,它將應用程式分成三個部分:Model 負責存盤資料和業務邏輯,View 負責展示資料,Controller 負責接收用戶輸入并更新 Model 和 View,在 MVC 模式中,View 和 Model 是相互獨立的,它們之間通過 Controller 來進行通信,
優點:
- 耦合度低:MVC 的三個部件(Model、View 和 Controller)是相互獨立的,改變其中一個不會影響其他兩個,
- 重用性高:多個視圖可以使用同一個模型,
- 可維護性高:由于各個部件之間的分離,MVC 模式下的應用程式更容易維護,
缺點:
- 不適合小型專案開發,
- 視圖與控制器聯系過于緊密,妨礙了它們的獨立重用,
MVVM
MVVM 是 Model-View-ViewModel 的縮寫,它也將應用程式分成三個部分:Model 負責存盤資料和業務邏輯,View 負責展示資料,ViewModel 則負責連接 View 和 Model,與 MVC 不同的是,在 MVVM 模式中,View 和 ViewModel 之間有著雙向資料系結的聯系,這意味著當 ViewModel 中的資料發生變化時,View 會自動更新;而當 View 中的資料發生變化時,ViewModel 也會自動更新,
優點:
- 低耦合:視圖(View)可以獨立于 Model 變化和修改,一個 Model 可以系結到不同的 View 上,當 View 變化時,Model 可以不變化;當 Model 變化時,View 也可以不變,
- 可重用性:你可以把一些視圖邏輯放在一個 Model 里面,讓很多 View 重用這段視圖邏輯,
- 獨立開發:雙向資料系結的模式實作了 View 和 Model 的自動同步,因此開發者只需要專注對資料的維護操作即可,而不需要一直操作 DOM,
缺點:
- 增加了代碼復雜度,并且對于簡單的應用來說可能會顯得過于繁瑣,
- 由于 MVVM 模式依賴于雙向資料系結,因此它也可能會帶來一些性能問題,
總之,MVC 和 MVVM 的主要區別在于它們對 View 和 Model 之間通信方式的不同處理,MVC 通過 Controller 來進行通信,而 MVVM 則通過雙向資料系結來實作通信,這兩種模式各有優缺點,具體使用哪種模式取決于具體的應用場景,
底層實作原理
Vue 的底層實作原理主要包括資料雙向系結和虛擬 DOM兩部分,
資料雙向系結是指當資料發生變化時,視圖會自動更新;而當視圖發生變化時,資料也會自動更新,Vue 實作資料雙向系結的方式是通過資料劫持和發布訂閱模式相結合,
- 資料劫持:Vue 會攔截 data 物件中所有屬性的讀取和寫入操作,在 Vue 2.x 版本中,資料劫持是通過 Object.defineProperty() 方法實作的;而在 Vue 3.x 版本中,資料劫持則是通過 Proxy 物件實作的,
- 發布訂閱模式:當我們修改 data 中的某個屬性時,Vue 會通知所有訂閱了該屬性變化的觀察者(Watcher),并執行相應的回呼函式,這些回呼函式通常會更新視圖,以保證視圖與資料保持同步,
虛擬 DOM 是一種用 JavaScript 物件表示 DOM 的技術,它可以讓我們在不直接操作 DOM 的情況下更新視圖,Vue 在更新視圖時會先生成一個新的虛擬 DOM 樹,然后將新舊虛擬 DOM 樹進行對比,找出它們之間的差異,最后,Vue 會根據這些差異來更新真實的 DOM 樹,這個程序被稱為“patching”,
使用虛擬DOM有以下幾個好處:
- 提高渲染性能:直接操作真實DOM通常是非常慢的,因為瀏覽器需要執行很多額外的作業,如樣式計算、布局和重繪,使用虛擬DOM可以減少對真實DOM的操作次數,從而提高渲染性能,
- 跨平臺:虛擬DOM是一個抽象層,它可以運行在任何支持JavaScript的平臺上,這意味著你可以使用Vue來構建跨平臺應用,如桌面應用、移動應用和Web應用,
- 更容易測驗:由于虛擬DOM是一個純粹的資料結構,它更容易進行測驗和除錯,
相對于手動操作真實DOM,使用虛擬DOM通常可以獲得更好的性能,但這并不是絕對的,因為虛擬DOM也有一些開銷,如創建虛擬DOM樹和計算差異,在某些情況下,手動操作真實DOM可能會更快,但總體來說,使用虛擬DOM可以讓我們更容易地構建高性能和跨平臺的應用,
生命周期
Vue 的生命周期指的是 Vue 實體從創建到銷毀的整個程序,在這個程序中,Vue 實體會經歷一系列的生命周期鉤子函式,這些鉤子函式可以讓我們在特定的時刻執行特定的操作,
- beforeCreate:在實體初始化之后,資料觀測和事件配置之前被呼叫,
created:在實體創建完成后被立即呼叫,此時,實體已完成以下配置:資料觀測、屬性和方法的運算、watch/event 事件回呼,但是,掛載階段還沒開始,$el 屬性目前不可見, - beforeMount:在掛載開始之前被呼叫,相關的 render 函式首次被呼叫,
mounted:在 el 被新創建的 vm.$el 替換,并掛載到實體上去之后呼叫,如果根實體掛載了一個檔案內元素,當 mounted 被呼叫時,vm.$el 也在檔案內, - beforeUpdate:在資料更新之前呼叫,發生在虛擬 DOM 打補丁之前,這里適合在更新之前訪問現有的 DOM,
updated:在由于資料更改導致的虛擬 DOM 重新渲染和打補丁之后呼叫,當這個鉤子被呼叫時,組件 DOM 已經更新,所以你現在可以執行依賴于 DOM 的操作, - beforeDestroy:在實體銷毀之前呼叫,此時實體仍然完全可用,
destroyed:在實體銷毀之后呼叫,此時,所有的指令系結都被解除,所有的事件監聽器都被移除,所有的子實體也都被銷毀,
Vuex
Vuex是一個專為Vue.js應用程式開發的狀態管理模式+庫,使用Vuex時,每一個Vuex應用的核心就是store(倉庫),它采用集中式存盤管理應用的所有組件的狀態,并以相應的規則保證狀態以一種可預測的方式發生變化,它可以幫助我們管理共享狀態,解決多組件資料通信問題,
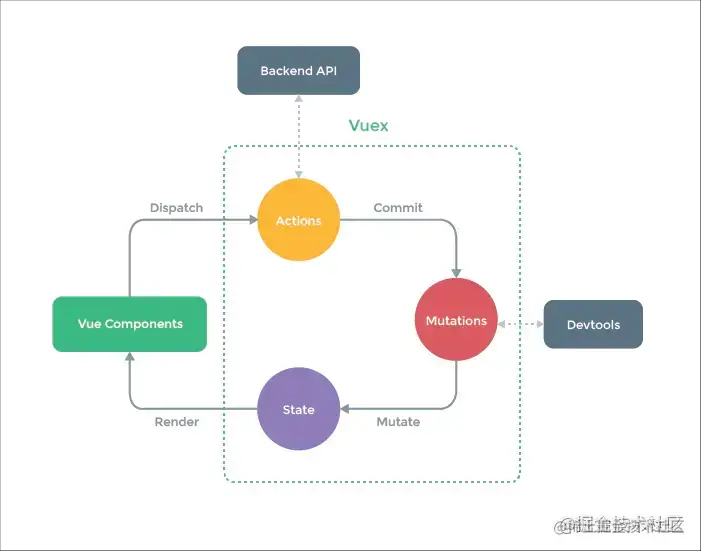
簡單來說,Vuex就像一個容器,它包含了你的應用中大部分的狀態,當Vue組件從store中讀取狀態時,若store中的狀態發生變化,那么相應的組件也會相應地得到高效更新,
你可以通過store.state來獲取狀態物件,并通過store.commit方法觸發狀態變更,在Vue組件中,可以通過this.$store訪問store實體,但不能直接改變store中的狀態,改變store中的狀態的唯一途徑就是顯式地提交mutation,而非直接改變store.state.count,這樣使得我們可以方便地跟蹤每一個狀態的變化,從而讓我們能夠實作一些工具幫助我們更好地了解我們的應用,
Vuex主要包括以下幾個核心模塊:
- State:Vuex使用單一狀態樹,用一個物件就包含了全部的應用層級狀態,每個應用將僅僅包含一個store實體,單一狀態樹讓我們能夠直接定位任一特定的狀態片段,在除錯的程序中也能輕易地取得整個當前應用狀態的快照,
- Getter:有時候我們需要從store中的state中派生出一些狀態,例如對串列進行過濾并計數,Vuex允許我們在store中定義getter(可以認為是store的計算屬性),就像計算屬性一樣,getter的回傳值會根據它的依賴被快取起來,且只有當它的依賴值發生了改變才會被重新計算,
- Mutation:更改Vuex的store中的狀態的唯一方法是提交mutation,Vuex中的mutation非常類似于事件:每個mutation都有一個字串的事件型別(type)和一個回呼函式(handler),這個回呼函式就是我們實際進行狀態更改的地方,并且它會接受state作為第一個引數,
- Action:Action類似于mutation,不同在于:Action提交的是mutation,而不是直接變更狀態;Action可以包含任意異步操作,Action函式接受一個與store實體具有相同方法和屬性的context物件,因此你可以呼叫context.commit提交一個mutation,或者通過context.state和context.getters來獲取state和getters,
- Module:由于使用單一狀態樹,應用的所有狀態會集中到一個比較大的物件,當應用變得非常復雜時,store物件就有可能變得相當臃腫,為了解決這個問題,Vuex允許我們將store分割成模塊(module),每個模塊擁有自己的state、mutation、action、getter、甚至是嵌套子模塊,
一些常見的Vuex使用場景包括:用戶的個人資訊管理模塊、電商專案的購物車模塊、我的訂單模塊(訂單串列中點擊取消訂單,然后更新對應的訂單串列)、在訂單結算頁獲取需要的優惠券并更新訂單優惠資訊等,
示例:
// store.js
import Vue from 'vue'
import Vuex from 'vuex'
Vue.use(Vuex)
export default new Vuex.Store({
state: {
count: 0
},
getters: {
doubleCount: state => state.count * 2
},
mutations: {
increment(state) {
state.count++
}
},
actions: {
increment(context) {
context.commit('increment')
}
}
})
// main.js
import Vue from 'vue'
import App from './App.vue'
import store from './store'
new Vue({
el: '#app',
store,
render: h => h(App)
})
// App.vue
<template>
<div>
<p>{{ count }}</p>
<button @click="increment">Increment</button>
</div>
</template>
<script>
export default {
computed: {
count() {
return this.$store.state.count
}
},
methods: {
increment() {
this.$store.dispatch('increment')
}
}
}
</script>
組件之間的通信方式
除了以上說的 Vuex 進行組件之間的通訊外,常見的組件通訊還有以下幾種方式:
- props / $emit:父組件通過props向子組件傳遞資料,子組件通過$emit向父組件傳遞資料,
示例:
// 父組件
<template>
<div>
<child :msg="msg" @changeMsg="changeMsg"></child>
</div>
</template>
<script>
import Child from './Child.vue'
export default {
components: { Child },
data() {
return {
msg: 'Hello'
}
},
methods: {
changeMsg(newMsg) {
this.msg = newMsg
}
}
}
</script>
// 子組件
<template>
<div>
<p>{{ msg }}</p>
<button @click="changeMsg">Change Msg</button>
</div>
</template>
<script>
export default {
props: ['msg'],
methods: {
changeMsg() {
this.$emit('changeMsg', 'Hi')
}
}
}
</script>
- ref / $refs:父組件可以通過$refs獲取子組件的實體,從而呼叫子組件的方法或訪問子組件的資料,
示例:
// 父組件
<template>
<div>
<child ref="child"></child>
<button @click="getChildMsg">Get Child Msg</button>
</div>
</template>
<script>
import Child from './Child.vue'
export default {
components: { Child },
methods: {
getChildMsg() {
console.log(this.$refs.child.msg)
}
}
}
</script>
// 子組件
<template>
<div>{{ msg }}</div>
</template>
<script>
export default {
data() {
return {
msg: 'Hello'
}
}
}
</script>
- eventBus事件總線($emit / $on):可以創建一個空的Vue實體作為事件總線,在組件中通過$emit觸發事件,在另一個組件中通過$on監聽事件,從而實作組件間通信,
示例:
// eventBus.js
import Vue from 'vue'
export const eventBus = new Vue()
// 組件A
<template>
<div>
<button @click="emitEvent">Emit Event</button>
</div>
</template>
<script>
import { eventBus } from './eventBus.js'
export default {
methods: {
emitEvent() {
eventBus.$emit('myEvent', 'Hello')
}
}
}
</script>
// 組件B
<template>
<div>{{ msg }}</div>
</template>
<script>
import { eventBus } from './eventBus.js'
export default {
data() {
return {
msg: ''
}
},
mounted() {
eventBus.$on('myEvent', (data) => {
this.msg = data
})
}
}
</script>
- $parent / $children:子組件可以通過$parent訪問父組件實體,父組件可以通過$children訪問子組件實體,
示例:
// 父組件
<template>
<div>
<child></child>
<button @click="getChildMsg">Get Child Msg</button>
</div>
</template>
<script>
import Child from './Child.vue'
export default {
components: { Child },
methods: {
getChildMsg() {
console.log(this.$children[0].msg)
}
}
}
</script>
// 子組件
<template>
<div>{{ msg }}</div>
</template>
<script>
export default {
data() {
return {
msg: 'Hello'
}
}
}
</script>
- $attrs/ $listeners:$attrs包含了父組件中不作為prop被識別且獲取的特性系結,$listeners包含了父組件中的v-on事件監聽器,
示例:
// 父組件
<template>
<div id="app">
<middle :msg="msg" @changeMsg="changeMsg"></middle>
</div>
</template>
<script>
import Middle from './Middle.vue'
export default {
components: { Middle },
data() {
return {
msg: 'Hello'
}
},
methods: {
changeMsg(newMsg) {
this.msg = newMsg
}
}
}
</script>
// 中間組件
<template>
<div>
<child v-bind="$attrs" v-on="$listeners"></child>
</div>
</template>
<script>
import Child from './Child.vue'
export default {
components: { Child },
inheritAttrs: false // 不繼承父組件的屬性,避免將屬性系結到根元素上,
}
</script>
// 子組件
<template>
<div>
<p>{{ msg }}</p>
<button @click="changeMsg">Change Msg</button>
</div>
</template>
<script>
export default {
props: ['msg'],
methods: {
changeMsg() {
this.$emit('changeMsg', 'Hi')
}
}
}
</script>
- provide/inject:祖先組件通過provide提供變數,然后在子孫組件中通過inject來注入變數,
示例:
// 祖先組件
<template>
<div>
<child></child>
</div>
</template>
<script>
import Child from './Child.vue'
export default {
components: { Child },
provide() {
return {
msg: 'Hello'
}
}
}
</script>
// 子孫組件
<template>
<div>{{ msg }}</div>
</template>
<script>
export default {
inject: ['msg']
}
</script>
computed與watch
computed和watch都是Vue實體的選項,用來監聽資料變化并執行相應的操作,
computed
computed:計算屬性是基于它們的依賴進行快取的,計算屬性只有在它的相關依賴發生改變時才會重新求值,這就意味著只要相關依賴沒有發生改變,多次訪問計算屬性會立即回傳之前的計算結果,而不必再次執行函式,計算屬性默認只有getter,不過在需要時你也可以提供一個setter,
示例:
new Vue({
el: '#app',
data: {
message: 'Hello'
},
computed: {
reversedMessage: function () {
return this.message.split('').reverse().join('')
}
}
})
watch
watch:當你需要在資料變化時執行異步或開銷較大的操作時,可以使用watch,watch選項允許我們執行異步操作(訪問一個API),限制我們執行該操作的頻率,并在我們得到最終結果前,設定中間狀態,
示例:
new Vue({
el: '#app',
data: {
message: 'Hello'
},
watch: {
message: function (newVal, oldVal) {
console.log('message changed from', oldVal, 'to', newVal)
}
}
})
區別:
- 計算屬性是基于它們的依賴進行快取的,只有在相關依賴發生改變時,計算屬性才會重新求值,這意味著只要相關依賴沒有發生改變,多次訪問計算屬性會立即回傳之前的計算結果,而不必再次執行函式,相比之下,watch選項中的函式每次都會執行,
- 計算屬性通常用來計算一個值,這個值是基于它的依賴進行計算的,當你需要根據資料變化來改變資料時,可以使用計算屬性,相比之下,watch選項通常用來執行異步操作或開銷較大的操作,
- 計算屬性是回應式的,當它們的依賴發生改變時,它們會自動更新,相比之下,watch選項需要手動設定監聽的資料,
總之,當你需要根據資料變化來改變資料時,可以使用計算屬性;當你需要根據資料變化來執行異步操作或開銷較大的操作時,可以使用watch,
其他
v-if和v-for同時使用在一個元素上的問題
不建議在同一元素上同時使用v-for和v-if,當它們同時存在時,v-for的優先級比v-if更高,這意味著v-if將分別重復運行于每個回圈的項上,這可能會導致性能問題,因為在渲染串列時會進行更多的計算,
場景一:如果你想根據條件過濾串列并渲染過濾后的結果,可以將過濾后的結果計算為一個計算屬性,然后在v-for中使用這個計算屬性:
<template>
<ul>
<li v-for="item in filteredItems" :key="item.id">
{{ item.text }}
</li>
</ul>
</template>
<script>
export default {
data() {
return {
items: [
{ id: 1, text: 'Item 1', show: true },
{ id: 2, text: 'Item 2', show: false },
{ id: 3, text: 'Item 3', show: true }
]
}
},
computed: {
filteredItems() {
return this.items.filter(item => item.show)
}
}
}
</script>
場景二:如果你的目的是有條件地跳過回圈的執行,那么可以將v-if放置在外層元素(如<template>)或包裝元素上:
<template>
<ul v-if="shouldShowItems">
<li v-for="item in items" :key="item.id">
{{ item.text }}
</li>
</ul>
</template>
<script>
export default {
data() {
return {
items: [
{ id: 1, text: 'Item 1' },
{ id: 2, text: 'Item 2' },
{ id: 3, text: 'Item 3' }
],
shouldShowItems: true
}
}
}
</script>
Vue.nextTick的原理及實作
Vue.nextTick是一個全域API,用于在下一次DOM更新回圈結束之后延遲執行一個回呼函式,它的實作依賴于JavaScript的事件回圈和微任務佇列,
- 在Vue 2.x中,Vue.nextTick的實作使用了一個異步佇列來存盤所有等待執行的回呼函式,當一個回呼函式被傳遞給Vue.nextTick時,它會被推入這個異步佇列中,然后,Vue會使用一個內部函式來異步重繪這個佇列,以便在下一次DOM更新回圈結束之后執行所有等待的回呼函式,
為了異步重繪佇列,Vue會嘗試使用原生的Promise.then、MutationObserver或setImmediate來實作異步延遲,如果這些方法都不可用,它會退而使用setTimeout(fn, 0),
- 在Vue 3.x中,Vue.nextTick的實作類似于Vue 2.x,但使用了更現代的API來實作異步延遲,它首先嘗試使用原生的Promise.then,如果不可用則退而使用setTimeout(fn, 0),
示例:
<template>
<div>
<p ref="message">{{ message }}</p>
<button @click="updateMessage">Update</button>
</div>
</template>
<script>
export default {
data() {
return {
message: 'Hello'
}
},
methods: {
updateMessage() {
this.message = 'Updated'
console.log(this.$refs.message.textContent) // => 'Hello'
this.$nextTick(() => {
console.log(this.$refs.message.textContent) // => 'Updated'
})
}
}
}
</script>
總之,Vue.nextTick的實作依賴于JavaScript的事件回圈和微任務佇列,它使用一個異步佇列來存盤所有等待執行的回呼函式,并使用原生API或setTimeout來異步重繪這個佇列,
組件中data是一個函式的原因
在Vue組件中,data必須是一個函式,而不是一個物件,這是因為當一個組件被多次使用時,每個實體都應該維護一份被回傳物件的獨立的拷貝,
如果data是一個物件,那么所有組件實體將共享同一個資料物件,這意味著當一個組件實體改變了資料物件時,其他組件實體的資料也會受到影響,
為了避免這個問題,Vue要求組件的data選項必須是一個函式,當一個組件被實體化時,Vue會呼叫這個函式來獲取組件的初始資料,由于每個組件實體都會呼叫這個函式來獲取自己的資料,所以每個組件實體都會維護一份獨立的資料拷貝,
前端路由
前端路由是指在單頁應用(SPA)中,通過改變URL并不向服務器發送請求,而是通過JavaScript來控制頁面內容的切換,這種方式可以讓用戶在不離開當前頁面的情況下,瀏覽不同的內容,
前端路由通常有兩種實作方式:hash模式和history模式,
- hash模式:在這種模式下,URL中的hash(即#符號后面的部分)用來表示路由狀態,當hash發生變化時,瀏覽器不會向服務器發送請求,而是觸發hashchange事件,我們可以監聽這個事件,并根據新的hash值來更新頁面內容,這種方式兼容性好,但URL中會多出一個#符號,可能會影響美觀,
- history模式:在這種模式下,我們使用HTML5的History API來控制URL的變化,當URL發生變化時,瀏覽器不會向服務器發送請求,而是觸發popstate事件,我們可以監聽這個事件,并根據新的URL來更新頁面內容,這種方式可以讓URL看起來更像傳統的URL,但需要服務器端的支持,
Vue diff演算法
Vue的diff演算法是用來比較新舊虛擬DOM樹,計算出最小的更新操作來更新真實DOM的程序,它采用了深度優先遍歷和雙端比較的策略來優化比較程序,是Vue虛擬DOM實作的核心部分,
Vue的diff演算法基于兩個假設:
- 兩個相同標簽的元素會產生類似的DOM結構,
- 同一層級的一組子節點,它們可以通過唯一的id進行區分,
基于這兩個假設,Vue的diff演算法采用了深度優先遍歷和雙端比較的策略來比較新舊虛擬DOM樹,
在比較程序中,Vue會從新舊虛擬DOM樹的根節點開始,逐層進行比較,當遇到不同型別的節點時,Vue會直接替換整個節點及其子節點;當遇到相同型別但屬性不同的節點時,Vue會更新節點的屬性;當遇到相同型別且屬性相同但子節點不同的節點時,Vue會遞回地比較子節點,
在比較子節點時,Vue會使用雙端比較的策略來優化比較程序,它會同時從新舊虛擬DOM樹的兩端開始比較,如果發現兩端的節點相同,則直接移動節點;如果發現兩端的節點不同,則繼續比較中間部分,這種策略可以有效地減少需要比較的節點數量,從而提高diff演算法的性能,
那么我們常常在for回圈中要系結一個key屬性值,有什么作用呢?
其實在Vue中,key是一個特殊的屬性,用于標識串列渲染中每個節點的唯一性,這是因為在串列渲染中,串列資料可能會發生變化,導致串列項的順序、數量或內容發生變化,如果沒有key屬性,Vue將無法準確地確定新舊虛擬DOM樹中的節點是否相同,從而無法快速地更新虛擬DOM樹,所以它可以幫助Vue更快地更新虛擬DOM樹,從而提高應用的性能,
當Vue進行串列渲染時,它需要一種方式來確定新舊虛擬DOM樹中的節點是否相同,如果沒有key屬性,Vue會默認使用“就地更新”的策略,即直接復用舊虛擬DOM樹中的節點來更新新虛擬DOM樹中的節點,這種方式簡單快速,但在某些情況下可能會導致問題,
為了避免這些問題,我們可以使用key屬性來為每個節點指定一個唯一的標識,當Vue進行串列渲染時,它會根據key屬性來確定新舊虛擬DOM樹中的節點是否相同,這樣,Vue就可以更快地更新虛擬DOM樹,從而提高應用的性能,
keep-alive使用及原理,
keep-alive是Vue的一個內置組件,用于保留組件狀態或避免重新渲染,它可以將其包裹的組件快取起來,當組件切換時不會銷毀,而是保留在記憶體中,以便下次切換回來時可以直接使用,
實作原理:是通過一個快取物件來存盤被快取的組件實體,當一個組件被切換出去時,它不會被銷毀,而是被保存在快取物件中;當一個組件被切換回來時,keep-alive會先檢查快取物件中是否有這個組件的實體,如果有,則直接使用快取的實體;如果沒有,則創建一個新的實體,
示例:
<template>
<div>
<button @click="toggle">Toggle</button>
<keep-alive>
<component :is="currentView"></component>
</keep-alive>
</div>
</template>
<script>
import Foo from './Foo.vue'
import Bar from './Bar.vue'
export default {
components: {
Foo,
Bar
},
data() {
return {
currentView: 'Foo'
}
},
methods: {
toggle() {
this.currentView = this.currentView === 'Foo' ? 'Bar' : 'Foo'
}
}
}
</script>
插槽
插槽(Slot)是Vue的一個功能,用于實作組件的內容分發,它允許你在父組件中定義一些內容,然后將這些內容分發到子組件的指定位置,
默認插槽,具名插槽和匿名插槽:
- 默認插槽用于分發沒有指定名稱的內容
- 具名插槽用于分發指定名稱的內容,
- 匿名插槽是指沒有被
元素包裹的內容,
示例:
// 子組件
Vue.component('my-component', {
template: `
<div>
<header>
<slot name="header"></slot>
</header>
<main>
<slot></slot>
</main>
<footer>
<slot name="footer"></slot>
</footer>
</div>
`
})
// 父組件
new Vue({
el: '#app',
template: `
<my-component>
<template v-slot:header>
<h1>Header</h1>
</template>
<p>Content</p>
<template v-slot:footer>
<h1>Footer</h1>
</template>
</my-component>
`
})
React
React是一個由Facebook創建的JavaScript庫,用于構建用戶界面,它是一個用于構建UI組件的工具,
React是一個前端框架,它允許開發人員使用組件化的方式來構建復雜的用戶界面,React組件是獨立的、可復用的代碼塊,它們可以接收輸入并回傳React元素來描述應該在頁面上顯示什么,
React的核心思想是宣告式編程,這意味著開發人員只需要描述應用程式應該呈現什么樣子,而不需要關心如何實作它,React會負責計算出如何高效地更新用戶界面,以便它始終與最新的狀態保持一致,
優點:
- 高性能:React使用虛擬DOM來提高應用的性能和渲染效率,虛擬DOM是一個輕量級的JavaScript物件,它是真實DOM的抽象表示,當組件的狀態發生變化時,React會根據新的狀態創建一個新的虛擬DOM樹,然后,React會使用一個高效的演算法來比較新舊虛擬DOM樹,計算出最小的更新操作來更新真實DOM,
- 組件化架構:React采用了組件化的架構來構建復雜的用戶界面,在React中,一個組件是一個獨立的、可復用的代碼塊,它可以接收輸入并回傳React元素來描述應該在頁面上顯示什么,開發人員可以使用組件來封裝各種UI功能,并將它們組合起來構建復雜的用戶界面,
- 易于學習:相比其他前端框架,React相對容易學習,它有著豐富的檔案和教程,并且有著龐大的社區支持,
缺點:
- 開發速度:由于React不斷更新和改進,開發人員需要不斷學習新知識才能跟上React的發展步伐,
- 檔案不足:盡管React有著豐富的檔案和教程,但由于其快速發展,有時檔案可能不夠完整或過時,
- 學習曲線陡峭:盡管React相對容易學習,但要真正掌握它并開發復雜的應用程式仍然需要一定的時間和精力,
底層實作原理
React是一個JavaScript庫,用于構建用戶界面,它的底層實作原理包括虛擬DOM、組件化架構和回應式更新等,
- 虛擬DOM:React使用虛擬DOM來提高應用的性能和渲染效率,虛擬DOM是一個輕量級的JavaScript物件,它是真實DOM的抽象表示,當組件的狀態發生變化時,React會根據新的狀態創建一個新的虛擬DOM樹,然后,React會使用一個高效的演算法來比較新舊虛擬DOM樹,計算出最小的更新操作來更新真實DOM,這個程序被稱為“reconciliation”,
- 組件化架構:React采用了組件化的架構來構建復雜的用戶界面,在React中,一個組件是一個獨立的、可復用的代碼塊,它可以接收輸入并回傳React元素來描述應該在頁面上顯示什么,開發人員可以使用組件來封裝各種UI功能,并將它們組合起來構建復雜的用戶界面,
- 回應式更新:React采用了回應式的方式來更新用戶界面,當組件的狀態發生變化時,React會自動計算出需要更新的部分,并高效地更新真實DOM,這樣,開發人員只需要關心如何描述應用程式應該呈現什么樣子,而不需要關心如何實作它,
生命周期
React組件的生命周期可分成三個狀態:Mounting(掛載)、Updating(更新)和Unmounting(卸載),
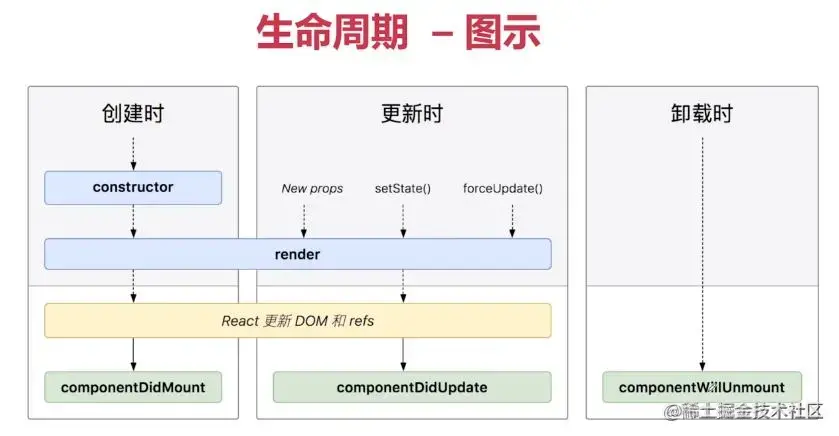
Mounting(掛載):當組件實體被創建并插入 DOM 中時,其生命周期呼叫順序如下:
- constructor(): 在 React 組件掛載之前,會呼叫它的建構式,
- getDerivedStateFromProps(): 在呼叫 render 方法之前呼叫,并且在初始掛載及后續更新時都會被呼叫,
- render(): render() 方法是 class 組件中唯一必須實作的方法,
- componentDidMount(): 在組件掛載后(插入 DOM 樹中)立即呼叫,
Updating(更新):每當組件的 state 或 props 發生變化時,組件就會更新,當組件的 props 或 state 發生變化時會觸發更新,組件更新的生命周期呼叫順序如下:
- getDerivedStateFromProps(): 在呼叫 render 方法之前呼叫,并且在初始掛載及后續更新時都會被呼叫,
- shouldComponentUpdate(): 當 props 或 state 發生變化時,shouldComponentUpdate() 會在渲染執行之前被呼叫,
- render(): render() 方法是 class 組件中唯一必須實作的方法,
- getSnapshotBeforeUpdate(): 在最近一次渲染輸出(提交到 DOM 節點)之前呼叫,
- componentDidUpdate(): 在更新后會被立即呼叫,
Unmounting(卸載):當組件從 DOM 中移除時會呼叫如下方法:
- componentWillUnmount(): 在組件卸載及銷毀之前直接呼叫,
React-fiber
React-fiber是對React核心演算法的一次重新實作,它能讓React中的同步渲染進行中斷,并將渲染的控制權讓回瀏覽器,從而達到不阻塞瀏覽器渲染的目的,Fiber能夠將渲染作業分割成塊并將其分散到多個幀中,同時加入了在新的更新進入時暫停,中止或重復作業的能力和為不同型別的更新分配優先級的能力,
在Fiber誕生之前,React處理一次setState(首次渲染)時會有兩個階段:調度階段(Reconciler)和渲染階段(Renderer),調度階段React用新資料生成新的Virtual DOM,遍歷Virtual DOM,然后通過Diff演算法,快速找出需要更新的元素,放到更新佇列中去,渲染階段React根據所在的渲染環境,遍歷更新佇列,將對應元素更新,在瀏覽器中,就是更新對應的DOM元素,
這種設計看似合理,但是對于復雜組件,需要大量的diff計算,會嚴重影響到頁面的互動性,例如,假設更新一個組件需要1ms,如果有500個組件要更新,那就需要500ms,在這500ms的更新程序中,瀏覽器唯一的主執行緒都在專心運行更新操作,無暇去做任何其他的事情,這就是所謂的界面卡頓,
React-fiber就是為了解決渲染復雜組件時嚴重影響用戶和瀏覽器互動的問題,實作原理可以簡單分為以下幾個步驟:
- 將一次任務拆解成單元,
- 以劃分時間片的方式,按照Fiber的自己的調度方法,根據任務單元優先級,分批處理或吊起任務,
- 將一次更新分散在多次時間片中,
- 在瀏覽器空閑的時候,也可以繼續去執行未完成的任務,
這樣,React Fiber就能夠充分利用瀏覽器每一幀的作業特性,避免渲染復雜組件時嚴重影響用戶和瀏覽器互動的問題,
組件
React組件是組成React應用程式的可重復利用的模塊,它們是用于構建Web和原生互動界面的庫,
React組件可以分為兩種型別:函陣列件和類組件,
- 函陣列件是一個接受props作為引數并回傳一個React元素的函式,它們通常用于簡單的、無狀態的組件,
- 類組件是一個繼承自React.Component的類,它包含一個render方法,該方法回傳一個React元素,類組件通常用于更復雜的、有狀態的組件,
主要的區別:
- 語法不同:函陣列件是一個簡單的JavaScript函式,而類組件是一個繼承自React.Component的類,
- 功能不同:函陣列件通常用于簡單的、無狀態的組件,而類組件通常用于更復雜的、有狀態的組件,
- 狀態管理不同:函陣列件沒有自己的狀態和生命周期方法,而類組件具有自己的狀態和生命周期方法,
- 更新控制不同:類組件可以使用一些特殊的方法來控制組件的更新程序,而函陣列件則無法使用這些方法,
示例:
// 函陣列件
function Greeting(props) {
return <h1>Hello, {props.name}</h1>;
}
const Free = props =>{
return <h1>Hello, {props.name}</h1>;
}
// 類組件
class Counter extends React.Component {
constructor(props) {
super(props);
this.state = { count: 0 };
}
render() {
return (
<div>
<p>Count: {this.state.count}</p>
<button onClick={() => this.setState({ count: this.state.count + 1 })}>
Increment
</button>
</div>
);
}
}
通訊方式
- 父子組件之間:父向子,可以通過props的方式傳遞,子組件可以通過props物件訪問這些資料,子向父,子組件可以通過呼叫父組件傳遞給它的回呼函式來向父組件傳遞資料,
// 父向子傳
function Parent() {
const message = "來自父組件的問候";
return <Child message={message} />;
}
function Child(props) {
return <p>{props.message}</p>;
}
// 子向父傳
class Parent extends React.Component {
constructor(props) {
super(props);
this.state = { message: "" };
this.handleMessage = this.handleMessage.bind(this);
}
handleMessage(newMessage) {
this.setState({ message: newMessage });
}
render() {
return (
<>
<Child onMessage={this.handleMessage} />
<p>{this.state.message}</p>
</>
);
}
}
function Child(props) {
function handleClick() {
props.onMessage("來自幼兒園技術家的問候");
}
return <button onClick={handleClick}>發送訊息</button>;
}
- 兄弟組件之間:兄弟組件之間的資料傳遞,可以利用組件的Props以及Props回呼函式來進行,而這種使用方法通信的前提是:必須要有共同的父組件,父組件可以維護一個狀態,并將狀態作為props傳遞給兄弟組件,同時,父組件還可以定義一個回呼函式,用于更新狀態,并將該回呼函式作為props傳遞給兄弟組件,這樣,兄弟組件就可以通過呼叫回呼函式來更新狀態,從而實作兄弟組件之間的通信,
示例:
class Parent extends React.Component {
constructor(props) {
super(props);
this.state = { message: "" };
this.handleMessage = this.handleMessage.bind(this);
}
handleMessage(newMessage) {
this.setState({ message: newMessage });
}
render() {
return (
<>
<ChildA onMessage={this.handleMessage} />
<ChildB message={this.state.message} />
</>
);
}
}
function ChildA(props) {
function handleClick() {
props.onMessage("Hello from ChildA");
}
return <button onClick={handleClick}>Send Message</button>;
}
function ChildB(props) {
return <p>{props.message}</p>;
}
- 跨組件層級:可以使用Context API來實作跨組件層級的通信,使用
createContext方法創建一個Context物件,然后使用Provider組件包裹根組件,并通過value屬性提供要共享的資料,在任意后代組件中,使用Consumer組件包裹整個組件,就可以獲取到共享的資料,
示例:
const MessageContext = React.createContext();
class Parent extends React.Component {
constructor(props) {
super(props);
this.state = { message: "Hello from Parent" };
}
render() {
return (
<MessageContext.Provider value=https://www.cnblogs.com/zxlh1529/archive/2023/06/06/{this.state.message}>
{(message) => {message}
}
);
}
- 全域狀態管理:對于非嵌套關系的組件通信,可以使用全域狀態管理庫,如Redux或MobX,這些庫可以在應用程式的頂層維護一個全域狀態,并允許組件訂閱狀態變化并更新其自身,這樣,即使組件之間沒有直接的嵌套關系,它們也可以共享狀態并進行通信,
示例:
import { createStore } from "redux";
// Redux store
const initialState = { message: "" };
function reducer(state = initialState, action) {
switch (action.type) {
case "SET_MESSAGE":
return { message: action.message };
default:
return state;
}
}
const store = createStore(reducer);
// Parent component
class Parent extends React.Component {
render() {
return (
<>
<ChildA />
<ChildB />
</>
);
}
}
// ChildA component
function ChildA() {
function handleClick() {
store.dispatch({ type: "SET_MESSAGE", message: "Hello from ChildA" });
}
return <button onClick={handleClick}>Send Message</button>;
}
// ChildB component
class ChildB extends React.Component {
constructor(props) {
super(props);
this.state = { message: "" };
}
componentDidMount() {
this.unsubscribe = store.subscribe(() => {
const state = store.getState();
this.setState({ message: state.message });
});
}
componentWillUnmount() {
this.unsubscribe();
}
render() {
return <p>{this.state.message}</p>;
}
}
復用方式
React組件復用可以提高開發效率,減少Bug和程式體積,設計介面時,可以把通用的設計元素(按鈕,表單框,布局組件等)拆成介面良好定義的可復用的組件,這樣,下次開發相同界面程式時就可以寫更少的代碼,
復用方式有以下幾種:
- Props:通過props將資料和回呼函式傳遞給子組件,可以實作組件的復用,
示例:
function Greeting(props) {
return <h1>Hello, {props.name}</h1>;
}
- 高階組件(HOC):高階組件是一種用于復用組件邏輯的高級技巧,它是一個接受組件作為引數并回傳一個新組件的函式,
示例:
function withGreeting(WrappedComponent) {
return function(props) {
return (
<>
<Greeting name={props.name} />
<WrappedComponent {...props} />
</>
);
};
}
- Render Props:Render Props是一種在React組件之間使用一個值為函式的prop共享代碼的簡單技術,
示例:
function Greeting(props) {
return props.children("Hello");
}
function App() {
return (
<Greeting>
{greeting => (
<>
<h1>{greeting}, World</h1>
<h2>{greeting}, React</h2>
</>
)}
</Greeting>
);
}
React Hooks
React Hooks是一種新的API,它允許你在函陣列件中使用狀態和其他React特性,
常用的鉤子有:
- useState(狀態鉤子):
useState是一個允許你在函陣列件中添加狀態的Hook,它回傳一個狀態變數和一個更新該狀態變數的函式,
示例:
import { useState } from "react";
function Example() {
const [count, setCount] = useState(0);
return (
<div>
<p>你點擊了 {count} 次</p>
<button onClick={() => setCount(count + 1)}>點擊</button>
</div>
);
}
- useEffect(副作用鉤子):
useEffect是一個允許你在函陣列件中執行副作用的Hook,它接受一個函式作為引數,該函式將在組件渲染后執行,
示例:
import { useState, useEffect } from "react";
function Example() {
const [count, setCount] = useState(0);
useEffect(() => {
document.title = `你點擊了 ${count} 次`;
});
return (
<div>
<p>你點擊了 {count} 次</p>
<button onClick={() => setCount(count + 1)}>點擊</button>
</div>
);
}
- useContext(共享狀態鉤子):
useContext是一個允許你在函陣列件中訪問背景關系的Hook,它接受一個背景關系物件作為引數,并回傳該背景關系的當前值,
示例:
import { useContext } from "react";
const ThemeContext = React.createContext("light");
function Example() {
const theme = useContext(ThemeContext);
return <p>Current theme: {theme}</p>;
}
- useReducer(action 鉤子):
useReducer是一個允許你在函陣列件中使用類似于Redux的狀態管理模式的Hook,它接受一個reducer函式和初始狀態作為引數,并回傳當前狀態和一個dispatch函式,
示例:
import { useReducer } from "react";
function reducer(state, action) {
switch (action.type) {
case "increment":
return { count: state.count + 1 };
case "decrement":
return { count: state.count - 1 };
default:
throw new Error();
}
}
function Example() {
const [state, dispatch] = useReducer(reducer, { count: 0 });
return (
<>
Count: {state.count}
<button onClick={() => dispatch({ type: "increment" })}>+</button>
<button onClick={() => dispatch({ type: "decrement" })}>-</button>
</>
);
}
其他鉤子函式:useCallback(記憶函式),useMemo(記憶組件)和useRef(保存參考值)等,
其他
React diff演算法
React的diff演算法是一種高效的演算法,它用來計算出Virtual DOM中真正變化的部分,并只針對該部分進行原生DOM操作,而非重新渲染整個頁面,從而提高了頁面渲染效率,簡單來說,diff演算法就是通過最小代價將舊的fiber樹轉換為新的fiber樹,
React的每次更新,都會將新的ReactElement內容與舊的fiber樹作對比,比較出它們的差異后,構建新的fiber樹,將差異點放入更新佇列之中,從而對真實dom進行render,
diff演算法在React中處于主導地位,是React V-dom和渲染的性能保證,這也是React最有魅力、最吸引人的地方,React一個很大一個的設計有點就是將diff和V-dom的完美結合,而高效的diff演算法可以讓用戶更加自由的重繪頁面,讓開發者也能遠離原生dom操作,
setState
setState()是React中用來更新組件狀態的方法,當你呼叫setState()時,React會將你提供的物件與當前狀態合并,例如,你的狀態可能包含幾個獨立的變數:constructor(props) {super(props);this.state = {posts: [], comments: []};} ,
那么 setState 到底是同步還是異步的呢?
React中的setState()并不是真正意義上的異步,而是一個偽異步或者稱為延遲執行,它的執行順序在同步代碼后、異步代碼前,這種現象得益于React的合成事件,React的批處理更新也得益于合成事件,
注意:setState的“異步”并不是說內部由異步代碼實作,其實本身執行的程序和代碼都是同步的,只是合成事件和鉤子函式的呼叫順序在更新之前,導致在合成事件和鉤子函式中沒法立馬拿到更新后的值,形式了所謂的“異步”,當然可以通過第二個引數setState(partialState, callback)中的callback拿到更新后的結果,
而 setState 關于同異步也可以分兩種情況討論:
- 在React事件處理程式和生命周期方法中,setState()是異步的,這意味著在呼叫setState()后,state不會立即更新,
示例:
class Example extends React.Component {
constructor(props) {
super(props);
this.state = { count: 0 };
}
handleClick = () => {
this.setState({ count: this.state.count + 1 });
console.log(this.state.count); // 輸出的是更新前的值
}
render() {
return (
<div>
<p>你點擊了 {this.state.count} 次</p>
<button onClick={this.handleClick}>
Click me
</button>
</div>
);
}
}
- 在setTimeout事件或者自定義的DOM事件中,setState()是同步的,這意味著在呼叫setState()后,state會立即更新,
示例:
class Example extends React.Component {
constructor(props) {
super(props);
this.state = { count: 0 };
}
componentDidMount() {
setTimeout(() => {
this.setState({ count: this.state.count + 1 });
console.log(this.state.count); // 輸出的是更新后的值
}, 0);
}
render() {
return (
<div>
<p>你點擊了 {this.state.count} 次</p>
</div>
);
}
}
事件系結原理
React事件系結的原理與傳統的DOM事件系結有所不同,在傳統的DOM事件中,我們通常會將事件處理程式直接系結到DOM元素上,但是,在React中,事件處理程式并不是直接系結到真實的DOM元素上,而是在document處監聽所有支持的事件,當事件發生并冒泡到document處時,React會將事件內容封裝并交由真正的處理函式運行,
React中的事件都是合成事件,不是把每一個dom的事件系結在dom上,而是把事件統一系結到document中,觸發時通過事件冒泡到document進行觸發合成事件,因為是合成事件,所以我們無法去使用e.stopPropagation去阻止,而是使用e.preventDefault去阻止,
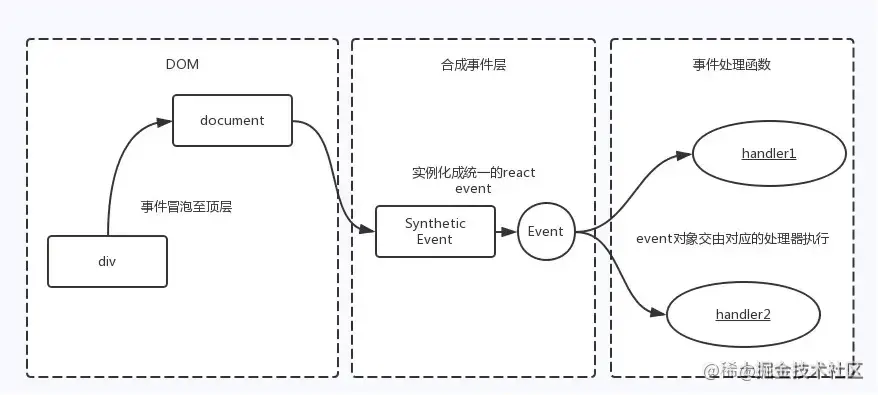
這種設計可以提高性能,因為它避免了在每個DOM元素上都系結事件處理程式,此外,它還使得React能夠更好地控制事件的傳播和處理,
React key的作用
在React中,key是一個特殊的字串屬性,它可以幫助React識別哪些元素發生了變化,當你渲染一個串列時,你應該給每個串列項分配一個穩定的、唯一的key,這樣,當串列項的順序發生變化時,React就能夠正確地更新串列,
key的作用是幫助React確定哪些元素需要被重新渲染,當組件更新時,React會比較新舊兩個Virtual DOM樹,找出它們之間的差異,如果兩個元素具有不同的key,React就會認為它們是不同的元素,并重新渲染它們,
工程化
前端工程化是一種將軟體工程的方法和思想應用于前端開發的程序,它主要指從前端專案開始開發到部署線上再到后期迭代維護的整個程序,從工程的角度管理前端開發,形成前端開發流程的一整套開發規范或解決方案,提高前端開發效率,
前端工程化可以提升開發體驗、提高開發效率和質量、提升應用的訪問性能,一切以提高效率、降低成本、質量保證為目的的手段都屬于工程化,
webpack
構建流程
Webpack的構建流程大致如下:
- 初始化引數:根據命令列和組態檔收集引數,形成最終的配置結果,
- 開始編譯:傳入引數,創建compiler實體,注冊所有配置的插件,插件監聽Webpack構建生命周期的事件節點,做出相應的反應,執行物件的run方法開始執行編譯,
- 確定入口:從組態檔中指定的entry入口,開始決議檔案構建AST語法樹,找出依賴,遞回下去,
- 編譯模塊:遞回中根據檔案型別和loader配置,呼叫所有配置的loader對檔案進行轉換,再找出該模塊依賴的模塊,再遞回本步驟直到所有入口依賴的檔案都經過了本步驟的處理,
- 完成模塊編譯并輸出:遞回完后,得到每個檔案結果,包含每個模塊以及它們之間的依賴關系,根據entry配置生成代碼塊chunk,輸出所有的chunk到檔案系統,
優化Webpack的構建速度
優化Webpack的構建速度有很多方法,可以從以下幾個方面入手:
- 使用新版本:升級到最新版本的Webpack可以帶來性能提升,因為每個版本的Webpack都會進行一些性能優化,
- 使用快取:可以使用快取來加快構建速度,例如使用
babel-loader、ts-loader等loader的快取選項, - 多執行緒編譯:可以使用多執行緒來加快編譯速度,例如使用
thread-loader或happypack, - 速度分析:可以使用
speed-measure-webpack-plugin來分析Webpack構建期間各個階段花費的時間,從而快速定位到可以優化的地方,
優化Webpack的構建速度可以帶來許多好處,隨著專案涉及到的頁面越來越多,功能和業務代碼也會越來越多,相應的Webpack的構建時間也會越來越久,這個時候我們就不得不考慮性能優化的事情了,
因為這個構建時間與我們的日常開發是密切相關,當我們本地開發啟動devServer或者build的時候,如果時間過長,會大大降低我們的作業效率,試想一下,我們突然碰到一個緊急bug,專案啟動需要花費幾分鐘,改完后專案build上線也要幾分鐘,換誰估計都得有暴脾氣了...
優化 Webpack 的打包體積
優化Webpack的打包體積可以帶來許多好處,打包體積越小,應用程式的加載速度就越快,用戶體驗就越好,下面是一些優化Webpack打包體積的方法:
- 提取公共代碼:在多入口情況下,可以使用
CommonsChunkPlugin來提取公共代碼, - 提取常用庫:可以通過
externals配置來提取常用庫, - 預編譯資源模塊:可以利用
DllPlugin和DllReferencePlugin預編譯資源模塊, - 剔除多余代碼:可以使用
Tree-shaking和Scope Hoisting來剔除多余代碼,例如:如果你在開發專案時將整個組件庫都引入了,那么在使用Webpack打包時,可以使用Tree-shaking來自動洗掉沒有參考的組件,從而減小打包體積,
擴展:Tree-shaking
Tree-shaking是一種通過靜態分析代碼,洗掉未參考代碼的技術,它可以幫助開發人員減小打包體積,提高應用程式的加載速度,
Tree-shaking的原理是基于ES6模塊的靜態結構特性,由于ES6模塊的匯入和匯出是在編譯時確定的,而不是在運行時確定的,因此Webpack可以在構建程序中靜態分析代碼,找出未被參考的模塊,并將它們從最終的打包檔案中洗掉,
不過需要注意的是,Tree-shaking只能洗掉未被參考的模塊,而不能洗掉未被執行的代碼,因此,如果你想要使用Tree-shaking來優化打包體積,需要注意代碼組織方式,盡量避免在一個模塊中混合使用被參考和未被參考的代碼,
性能優化
Webpack性能優化有很多方法,可以從以下幾個方面入手:
- 減少模塊決議:可以通過配置
resolve.alias來減少模塊決議的時間, - 優化loader性能:可以通過限制
loader的應用范圍來提高構建速度, - 使用熱替換(HMR):雖然熱替換并不能降低構建時間,但它可以降低代碼改動到效果呈現的時間,
- 手動分包:可以通過手動分包來減少打包時間,
- 使用新版本:使用新版本的Webpack可以帶來性能提升,因為每個版本的Webpack都會進行一些性能優化,
loader && plugin
Webpack的loader和plugin是兩種不同的擴展機制,它們都可以幫助開發人員定制Webpack的構建程序,
- Loader:用于對模塊的源代碼進行轉換,它們可以將非JavaScript檔案(如CSS、圖片等)轉換為Webpack能夠處理的模塊,常用的loader有:
babel-loader(用于將ES6+代碼轉換為ES5代碼)、css-loader(用于加載CSS檔案)、file-loader(用于加載檔案)等, - Plugin:用于擴展Webpack的功能,它們可以在構建程序中執行各種任務,如優化輸出檔案、管理資源等,常用的plugin有:
HtmlWebpackPlugin(用于生成HTML檔案)、MiniCssExtractPlugin(用于提取CSS檔案)、UglifyJsPlugin(用于壓縮JavaScript代碼)等,
git
Git是一種分布式版本控制系統,它可以幫助開發人員管理和協作代碼,Git可以跟蹤代碼的變化歷史,幫助開發人員查看每次修改的內容,并在出現問題時快速恢復到之前的狀態,
Git支持分支和合并,可以幫助開發人員在不同的分支上并行開發功能,然后將它們合并到主分支上,這樣,開發人員可以更好地協作,并更快地完成專案,
常用的git命令:
- git init:初始化本地git倉庫(創建新倉庫)
- git add:添加檔案到暫存區
- git commit:提交暫存區到本地倉庫
- git status:查看當前版本狀態(是否修改)
- git push:將當前分支push到遠程分支
- git pull:獲取遠程分支并merge到當前分支
- git clone:clone遠程倉庫
- git branch:顯示本地分支
- git branch -d:洗掉分支
- git checkout:檢出已存在的分支或檔案
- git checkout -b:創建+切換分支
- git merge:合并分支
不同型別的分支:
- master分支:通常用于線上發布使用,它應該始終保持穩定,并且只接受來自其他分支經過充分測驗和驗證的更改,
- dev分支:用于平常的開發和測驗,它通常包含最新的開發進度,并且可以接受來自功能分支或修復分支的更改,
- Feature branches(功能分支):用于開發新功能,每個功能分支都應該專注于一個特定的功能,并且在功能完成后合并到dev分支,
- Hotfix branches(修復分支):用于修復bug,每個修復分支都應該專注于修復一個特定的bug,并且在修復完成后合并到dev分支,
- Release branches(發布分支):用于準備新版本的發布,它通常從dev分支中創建,并且只接受用于修復bug和準備發布的更改,當新版本準備好發布時,發布分支會被合并到master分支和dev分支,
ESLint
ESLint是一個用于識別和報告ECMAScript/JavaScript代碼中模式的工具,旨在使代碼更加一致并避免錯誤,它是完全可插拔的,每個規則都是一個插件,你可以在運行時添加更多,你還可以添加社區插件、配置和決議器來擴展ESLint的功能,
ESLint可以幫助你快速找到代碼中的問題,它內置于大多數文本編輯器中,你可以將ESLint作為持續集成管道的一部分運行,許多ESLint發現的問題都可以自動修復,ESLint修復是語法感知的,因此你不會遇到傳統查找和替換演算法引入的錯誤,
作用:
- 快速找到代碼中的問題:ESLint靜態分析你的代碼以快速找到問題,
- 自動修復問題:許多ESLint發現的問題都可以自動修復,ESLint修復是語法感知的,因此你不會遇到傳統查找和替換演算法引入的錯誤,
- 遵循編碼規范:你可以配置ESLint來強制執行特定的編碼規范,以確保你的代碼風格一致;如果是團隊協作開發,它可以幫助團隊成員遵循統一的編碼規范,確保代碼風格一致,便于閱讀和理解彼此的代碼,
- 提高代碼質量:通過識別和修復潛在的問題,ESLint可以幫助你提高代碼質量并減少錯誤,
其他
補充說明一些常見的前端工程化工具和技術:
- 模塊化工具:如CommonJS、AMD和ES6模塊等,用于將復雜的前端代碼分解為更易于管理的模塊,
- 構建工具:如Grunt、Gulp和Webpack等,用于自動化執行常見的前端開發任務,如壓縮、合并和轉換代碼等,
- 代碼檢查工具:如ESLint和JSHint等,用于檢查代碼質量并確保遵循編碼規范,
- 單元測驗工具:如Jasmine和Mocha等,用于撰寫和運行單元測驗,以確保代碼的正確性,
專案優化
性能優化
前端頁面性能優化是一個復雜的程序,可以從多個方面進行優化,一些常見的優化方法包括:
- 減少請求數量:通過合并檔案、使用雪碧圖、使用字體圖示等方法來減少HTTP請求數量,
- 減小資源大小:通過壓縮代碼、壓縮圖片、使用Gzip等方法來減小資源大小,
- 優化網路連接:通過使用CDN、DNS預決議、持久連接等方法來優化網路連接,
- 優化資源加載:通過優化資源加載位置、使用異步加載、使用懶加載等方法來優化資源加載,
- 減少重繪回流:通過避免使用CSS運算式、避免使用table布局、避免頻繁操作樣式等方法來減少重繪回流,
- 使用性能更好的API:通過使用requestAnimationFrame、使用Web Workers、使用Service Workers等方法來使用性能更好的API,
重繪回流
回流(reflow)和重繪(repaint)是瀏覽器渲染程序中的兩個步驟,它們都會影響頁面的渲染性能,因此應盡量避免,
- 回流:當頁面中的元素的布局或幾何屬性發生變化時,瀏覽器需要重新計算元素的位置和大小,這個程序稱為回流,回流會影響到頁面中所有元素的位置和大小,因此它是一個非常耗時的程序,
- 重繪:當頁面中的元素的外觀(如顏色、背景等)發生變化,但不影響布局時,瀏覽器會重新繪制這些元素,這個程序稱為重繪,重繪不會影響到頁面中其他元素的布局,因此它比回流更快,
避免回流和重繪的一些方法包括:
- 避免使用CSS運算式:CSS運算式會在每次頁面渲染時重新計算,這會導致大量的回流和重繪,
- 避免使用table布局:table布局會導致大量的回流和重繪,應盡量避免使用,
- 避免頻繁操作樣式:頻繁地修改元素的樣式會導致大量的回流和重繪,可以考慮使用類名來修改樣式,或者將多次修改樣式的操作合并為一次,
- 避免頻繁操作DOM:頻繁地操作DOM會導致大量的回流和重繪,可以考慮使用檔案片段(DocumentFragment)來減少對DOM的操作,
主要方法
- 代碼優化:可以通過壓縮、合并和混淆代碼來減小檔案大小,提高頁面加載速度,例如,可以使用
UglifyJS等工具來壓縮JavaScript代碼,使用CSSNano等工具來壓縮CSS代碼,此外,還可以使用Webpack等構建工具來合并多個檔案為一個檔案,減少HTTP請求數量, - 資源優化:可以通過使用
CDN、啟用Gzip壓縮、使用瀏覽器快取等方法來優化資源加載,提高頁面加載速度,例如,可以將靜態資源部署到CDN上,以加快資源加載速度;可以在服務器端啟用Gzip壓縮,以減小傳輸檔案的大小;可以合理設定HTTP快取頭,以利用瀏覽器快取加快頁面加載速度, - 頁面結構優化:可以通過合理安排頁面結構,避免使用嵌套過深的HTML標簽,減少DOM操作等方法來優化頁面結構,提高頁面渲染速度,例如,可以避免在HTML中使用過多的嵌套標簽;可以
盡量減少對DOM的操作,避免觸發瀏覽器的回流和重繪, - 互動優化:可以通過使用
懶加載、預加載、按需加載等技術來優化用戶互動,提升用戶體驗,例如,可以使用懶加載技術來延遲加載頁面中不可見的圖片;可以使用預加載技術來預先加載頁面中即將需要的資源;可以使用按需加載技術來動態加載頁面中需要的JavaScript模塊, - 可維護性優化:可以通過使用
模塊化、組件化、設計模式等技術來提高代碼的可維護性,降低維護成本,例如,可以使用CommonJS或ES6模塊化語法來組織代碼;可以使用React或Vue等框架來構建可復用的組件;可以使用設計模式來撰寫可擴展、可維護的代碼,
其他一些措施:
- 移除生產環境的控制臺列印:在生產環境中,應該移除所有不必要的控制臺列印,以減少對性能的影響,
- 第三方庫的按需加載:可以使用按需加載技術來動態加載第三方庫中需要的部分,以減小檔案大小和加快頁面加載速度,
- 降低請求成本:可以通過使用HTTP/2、使用Service Workers等技術來降低請求成本,提高頁面加載速度,
- 減少請求數:可以通過合并檔案、使用雪碧圖、使用字體圖示等方法來減少HTTP請求數量,
- 減小傳輸體積:可以通過壓縮代碼、壓縮圖片、啟用Gzip壓縮等方法來減小傳輸檔案的大小,
如果各位大佬還有其他什么方法措施打在評論區吧,我會加上去的!
其他
瀏覽器渲染一幀都做了什么?
瀏覽器渲染一幀的程序包括以下幾個步驟:
- 處理用戶輸入:瀏覽器會處理用戶的輸入事件,如滑鼠點擊、鍵盤輸入等,
- JavaScript執行:瀏覽器會執行頁面中的JavaScript代碼,
- 請求影片幀回呼:瀏覽器會執行requestAnimationFrame回呼函式,
- 樣式計算:瀏覽器會計算元素的最終樣式,
- 布局:瀏覽器會根據元素的樣式和大小計算它們在頁面中的位置,
- 繪制:瀏覽器會根據元素的樣式和位置繪制它們,
- 合成:瀏覽器會將多個圖層合并為一張影像,并顯示在螢屏上,
這些步驟是瀏覽器渲染一幀的基本程序,不同的瀏覽器可能會有一些細微的差別,但總體流程是相同的,
計算機基礎與網路通信
HTTP和HTTPS的基本概念
HTTP(超文本傳輸協議)和HTTPS(超文本傳輸安全協議)都是用于在Web瀏覽器和網站服務器之間傳輸資訊的協議,它們的主要區別在于安全性,
-
HTTP是一種明文傳輸協議,它不提供任何加密機制,這意味著,如果攻擊者截獲了HTTP傳輸的資料,他們可以直接讀取其中的內容,因此,HTTP不適合用于傳輸敏感資訊,如信用卡號、密碼等,
- 優點:
- 簡單快速:HTTP協議簡單,通信速度快,
- 靈活:HTTP允許傳輸任意型別的資料物件,傳輸型別由Content-Type加以標記,
- 缺點:
- 不安全:HTTP是明文傳輸,資料都是未加密的,容易被竊聽截取,
- 資料完整性未校驗:HTTP傳輸的資料完整性未校驗,容易被篡改,
作業原理:
- 客戶端發起HTTP請求:客戶端在瀏覽器中輸入一個HTTP網址,然后連接到服務器的80埠,
- 服務器處理請求:服務器收到客戶端的請求后,會根據請求的內容進行處理,
- 服務器回傳回應:服務器處理完客戶端的請求后,會回傳一個回應,包括狀態碼、回應頭和回應正文,
- 客戶端處理回應:客戶端收到服務器的回應后,會根據狀態碼和回應頭進行相應的處理,如果狀態碼為200,表示請求成功,客戶端會渲染回應正文中的內容,
- 優點:
-
HTTPS則是HTTP的安全版本,它在HTTP的基礎上使用了SSL/TLS協議來加密資料,HTTPS 開發的主要目的是提供對網站服務器的身份認證,保護交換資料的隱私與完整性,整個程序中,客戶端和服務器之間傳輸的資料都是經過加密的,這意味著即使攻擊者截獲了HTTPS傳輸的資料,他們也無法讀取其中的內容,除非能夠破解加密演算法,
- 優點:
- 安全:HTTPS通過SSL/TLS協議對資料進行加密,保護了資料的安全性,
- 身份認證:HTTPS提供了對網站服務器的身份認證,防止了“中間人攻擊”,
- 缺點:
- 相對較慢:由于HTTPS需要進行加密和解密操作,因此它比HTTP相對較慢,
- 需要證書:使用HTTPS協議需要申請數字證書,可能需要一定的費用,
作業原理:
- 客戶端發起HTTPS請求:客戶端在瀏覽器中輸入一個HTTPS網址,然后連接到服務器的443埠,
- 服務器發送證書:服務器收到客戶端的請求后,會將網站支持的證書資訊(包括公鑰)發送給客戶端,
- 客戶端驗證證書:客戶端收到證書后,會驗證證書的有效性,如果證書有效,客戶端會生成一個隨機值,并使用公鑰對該隨機值進行加密,
- 客戶端發送加密資訊:客戶端將加密后的隨機值發送給服務器,以便服務器獲取該隨機值,
- 服務器解密資訊:服務器使用私鑰解密客戶端發送的加密資訊,從而獲得客戶端生成的隨機值,
- 服務器發送加密資料:服務器使用該隨機值對資料進行對稱加密,并將加密后的資料發送給客戶端,
- 客戶端解密資料:客戶端使用之前生成的隨機值對服務器發送的加密資料進行解密,從而獲得原始資料,
怎么保證安全性的?
HTTPS 通過使用對稱加密、非對稱加密、簽名演算法和證書機制來保證資料安全,在 HTTPS 請求程序中,客戶端首先會請求服務端的數字證書,并生成一個亂數 R1,將亂數和自己支持的加密演算法告訴服務端,服務端接收到客戶端的請求后,會將自己的數字證書發送給客戶端,并生成一個亂數 R2,然后根據客戶端支持的加密演算法選擇一種加密演算法,并將 R2 和加密演算法告訴客戶端,客戶端接收到服務端的回應后,會驗證服務端的數字證書是否有效,如果有效,則根據 R1、R2 和服務端選擇的加密演算法生成一個對稱加密的密鑰,并使用該密鑰對后續通信進行加密,這樣,HTTPS 協議就能夠保證所有資訊都是加密傳播,第三方無法竊聽;具有校驗機制,一旦被篡改,通信雙方會立刻發現;配備身份證書,防止身份被冒充1,
- 優點:
另外,HTTP和HTTPS還有一些其他區別,例如,它們使用的埠不同:HTTP默認使用80埠,而HTTPS默認使用443埠,且由于HTTPS需要進行加密和解密操作,因此它比HTTP更耗費服務器資源,
TCP
TCP(傳輸控制協議)是一種面向連接的協議,它使用三次握手來建立連接,并使用四次揮手來斷開連接,
三次握手
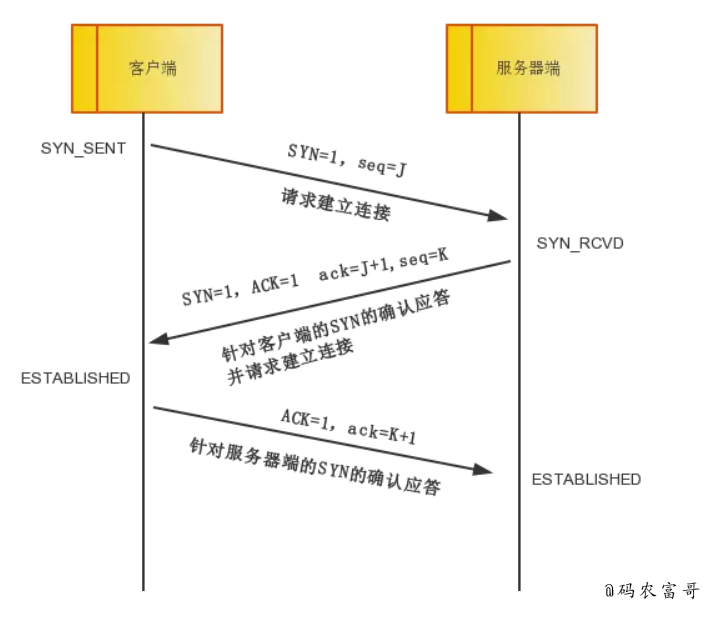
程序:
- 第一次握手:客戶端向服務器發送一個SYN報文,請求建立連接,報文中包含客戶端的初始序列號,
- 第二次握手:服務器收到SYN報文后,如果同意建立連接,則向客戶端發送一個SYN+ACK報文,表示確認客戶端的SYN報文,報文中包含服務器的初始序列號和對客戶端初始序列號的確認,
- 第三次握手:客戶端收到SYN+ACK報文后,向服務器發送一個ACK報文,表示確認服務器的SYN+ACK報文,此時,TCP連接建立完成,
四次揮手
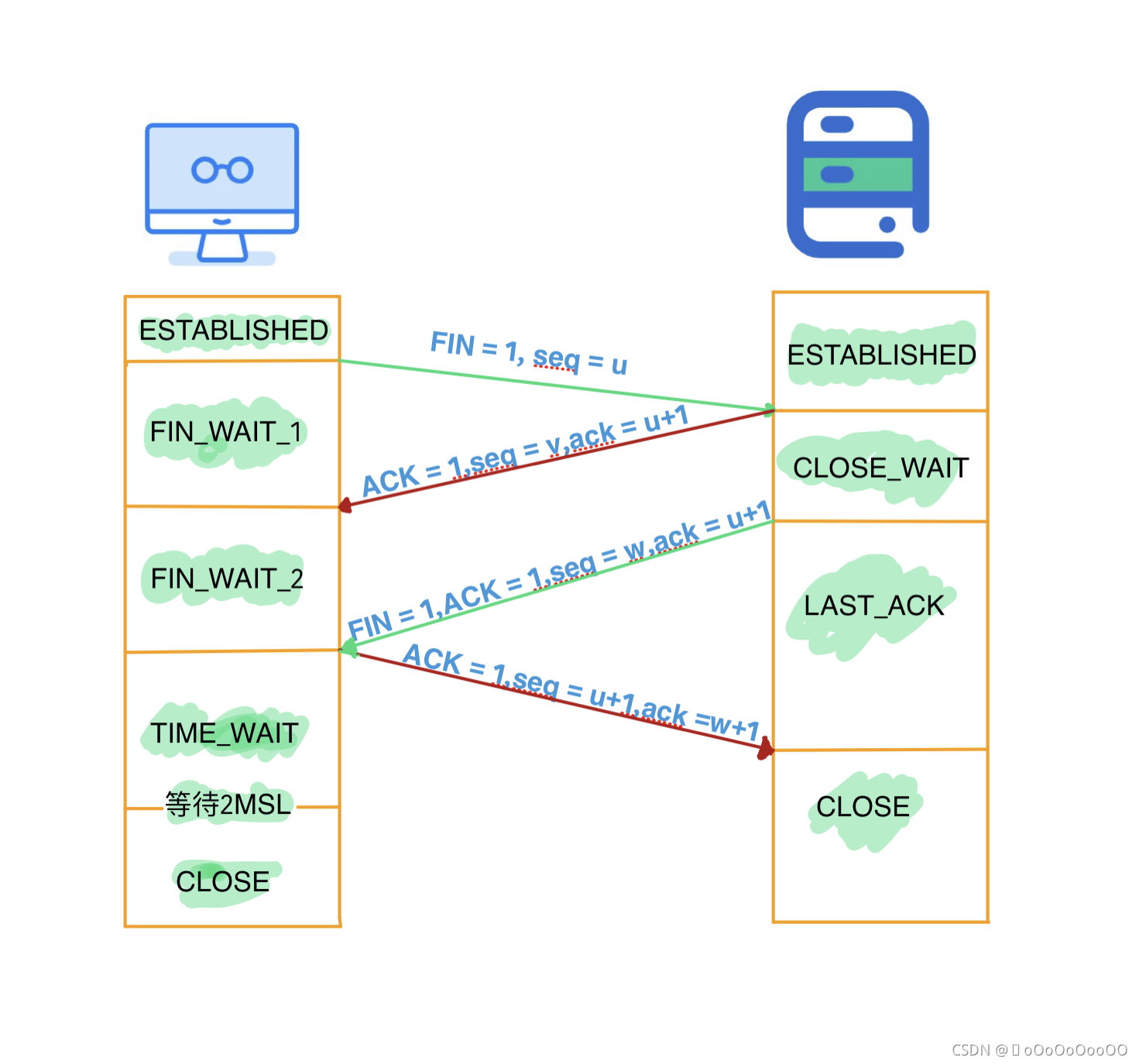
程序:
- 第一次揮手:當客戶端沒有更多資料要發送時,它會向服務器發送一個FIN報文,請求斷開連接,
- 第二次揮手:服務器收到FIN報文后,向客戶端發送一個ACK報文,表示確認客戶端的FIN報文,
- 第三次揮手:當服務器沒有更多資料要發送時,它會向客戶端發送一個FIN報文,請求斷開連接,
- 第四次揮手:客戶端收到FIN報文后,向服務器發送一個ACK報文,表示確認服務器的FIN報文,此時,TCP連接斷開完成,
那么為什么要進行三次握手和四次揮手呢?
- 三次握手的目的是為了防止失效的連接請求報文突然又傳送到了服務器,從而產生錯誤,通過三次握手,可以確保雙方都準備好建立連接,
- 四次揮手的目的是為了確保雙方都能夠完整地發送和接收資料,由于TCP是
全雙工通信協議,因此每個方向都需要單獨進行關閉,這就需要四次揮手來完成,
TCP/IP 怎么保證資料包傳輸的有序可靠?
首先,TCP使用序列號和確認應答機制來保證資料包的有序傳輸,每個發送的資料包都會被分配一個序列號,接收方收到資料包后會發送一個確認應答報文,其中包含對發送方序列號的確認,這樣,發送方就能夠知道哪些資料包已經被接收,哪些資料包需要重傳,
其次,TCP使用檢驗和來保證資料包的完整性,發送方在發送資料包時會計算一個檢驗和,并將其附加到資料包中,接收方收到資料包后會重新計算檢驗和并與發送方的檢驗和進行比較,如果兩者不一致,則說明資料包在傳輸程序中發生了錯誤,接收方會丟棄該資料包并請求重傳,
此外,TCP還使用超時重傳機制來保證資料包的可靠傳輸,當發送方發送一個資料包后,它會啟動一個定時器,如果在定時器超時之前沒有收到接收方的確認應答報文,則認為該資料包丟失,并進行重傳,
最后,TCP還使用流量控制和擁塞控制機制來保證網路的穩定性,流量控制通過調整發送視窗的大小來控制發送方的發送速率,防止接收方緩沖區溢位,擁塞控制則通過調整擁塞視窗的大小來控制網路擁塞程度,防止網路擁塞,
TCP和UDP的區別
- TCP是一種面向連接的協議,它在傳輸資料之前需要建立連接,
- UDP是一種無連接的協議,它不需要建立連接就可以直接發送資料,
- TCP提供了可靠的資料傳輸,它通過序列號、確認應答、重傳等機制來保證資料包的有序可靠傳輸,而UDP不提供可靠性保證,它只負責將資料包發送出去,不保證資料包能夠到達目的地,
- TCP提供了流量控制和擁塞控制機制來保證網路的穩定性,而UDP沒有這些控制機制,
總之,TCP和UDP各有優缺點,TCP提供了可靠的資料傳輸,但速度相對較慢;而UDP速度快,但不提供可靠性保證,選擇哪種協議取決于應用程式的需求,
解決跨域問題
跨域是指瀏覽器為了安全起見,限制了腳本內發起的跨源HTTP請求,這種限制被稱為同源策略,同源策略規定,只有當協議、域名和埠都相同時,兩個頁面才被認為是同源的,如果兩個頁面不同源,那么它們之間就不能進行跨域請求,
例如,運行在 https://api.example-a.com 的 JavaScript 代碼使用 XMLHttpRequest 來發起一個到 https://api.example-b.com/data.json 的請求,這由于域名的不同所以不同源,這就是一個跨域請求,
但是,有時候我們需要在不同源之間進行通信,為了解決這個問題,出現了一些解決跨域問題的方法,如JSONP、CORS、代理和postMessage等,這些方法都是通過繞過瀏覽器的同源策略限制來實作跨域請求的,
-
JSONP:JSONP是一種通過動態創建
<script>標簽來實作跨域請求的方法,它利用了<script>標簽的src屬性不受同源策略限制的特點,可以獲取到其他域下的資料,
原理:- 首先,在頁面中定義一個回呼函式,用來處理獲取到的資料,
- 然后,動態創建一個
<script>標簽,將其src屬性指向目標服務器上的一個介面,并在URL中添加一個callback引數,用來指定回呼函式的名稱, - 當
<script>標簽被插入頁面后,瀏覽器會自動發起一個GET請求,獲取目標服務器上的資料,目標服務器在接收到請求后,會將資料包裝在回呼函式中回傳, - 當資料回傳到頁面后,瀏覽器會自動執行回呼函式,并將資料作為引數傳入,這樣,我們就可以在回呼函式中處理獲取到的資料了,
示例:
<!DOCTYPE html> <html> <head> <title>JSONP Example</title> </head> <body> <h1>JSONP Example</h1> <p id="output"></p> <script> // 定義回呼函式 function handleResponse(data) { // 在回呼函式中處理獲取到的資料 document.getElementById('output').innerHTML = data.message; } // 動態創建<script>標簽 var script = document.createElement('script'); // 設定src屬性,指定回呼函式的名稱 script.src = 'https://api.example.com/getData?callback=handleResponse'; // 將<script>標簽插入頁面 document.body.appendChild(script); </script> </body> </html>缺點:
- 有安全風險,如果目標服務器回傳資料中包含了惡意代碼,那么這些代碼將被執行,
- JSONP只支持GET請求,不支持POST、PUT、DELETE等其他型別的HTTP請求,
- JSONP 需要后端配合回傳指定格式的資料,
- 需要服務器端兼容這種跨域請求,
- 不容易除錯,如果回傳錯誤瀏覽器不會回傳具體的錯誤,只能在控制臺中查看,
-
CORS:CORS(Cross-Origin Resource Sharing,跨源資源共享)是一種基于HTTP頭的機制,它允許服務器標識除了它自己以外的其他源(域、協議或埠),使得瀏覽器允許這些源訪問加載自己的資源,服務器可以通過設定回應頭中的Access-Control-Allow-Origin欄位來指定哪些源可以訪問它的資源,
-
代理:可以在服務器端設定一個代理,將前端發出的請求轉發到目標服務器上,然后再將目標服務器回傳的資料轉發回前端,這樣,前端就可以繞過瀏覽器的同源策略限制,實作跨域請求,
-
postMessage:postMessage是HTML5中新增的一個API,它允許不同源之間的視窗進行通信,可以通過監聽message事件來接收其他視窗發送過來的訊息,
瀏覽器
從輸入url到頁面展示出來的整個程序
- 瀏覽器會檢查快取,如果請求的資源在快取中并且新鮮,就會直接使用快取中的資源,如果資源未快取或快取不夠新鮮,瀏覽器會發起新請求,
- 瀏覽器會決議URL,獲取協議、主機、埠和路徑,
- 瀏覽器會通過DNS查詢獲取主機的IP地址,
- 瀏覽器會與目標IP地址和埠建立TCP連接,
- TCP連接建立后,瀏覽器會發送HTTP請求,
- 服務器接收到請求并進行處理,然后回傳HTTP回應,
- 瀏覽器接收到HTTP回應,并根據情況選擇關閉TCP連接或保留重用,
- 瀏覽器檢查回應狀態碼,并根據資源型別決定如何處理,如果資源是HTML檔案,瀏覽器會決議HTML檔案,構建DOM樹,下載資源,構建CSSOM樹,執行js腳本等操作,
瀏覽器快取機制
瀏覽器提供了多種快取機制,包括HTTP快取、Cookie、Web Storage(包括localStorage和sessionStorage)和IndexedDB等,
- HTTP快取:HTTP快取是一種通過重復使用之前獲取的資源來提高網站性能的機制,它通過設定HTTP回應頭中的快取控制欄位來實作,
- Cookie:Cookie是一種用于在客戶端存盤少量資料的機制,它通常用于保存用戶的登錄狀態、偏好設定等資訊,Cookie的大小有限制,通常不能超過4KB,
- Web Storage:Web Storage包括localStorage和sessionStorage兩種型別,它們都提供了一種在客戶端存盤鍵值對資料的機制,localStorage和sessionStorage的區別在于,localStorage中存盤的資料會持久保存在客戶端,即使瀏覽器關閉也不會丟失;而sessionStorage中存盤的資料只在當前會話期間有效,當瀏覽器關閉時會被清除,
- IndexedDB:IndexedDB是一種在客戶端存盤大量結構化資料的機制,它提供了豐富的查詢功能,并支持事務,
- 此外,還有一種名為session的機制,它用于在服務器端存盤
用戶會話資訊,session與上述幾種快取機制不同,它不是在瀏覽器中實作的,而是在服務器端實作的,
Cookie、sessionStorage、localStorage 的區別
- 生命周期:Cookie的生命周期可以通過設定過期時間來控制,過期后會被自動洗掉,sessionStorage中存盤的資料只在當前會話期間有效,當瀏覽器關閉時會被清除,localStorage中存盤的資料會持久保存在客戶端,即使瀏覽器關閉也不會丟失,
- 存盤容量:Cookie的大小有限制,通常不能超過4KB,sessionStorage和localStorage的存盤容量要大得多,一般可以達到5MB或更多,
- 作用域:Cookie在同一個域名下是共享的,可以在不同頁面之間共享資料,sessionStorage和localStorage的作用域是以視窗或標簽頁為單位的,它們只能在同一個視窗或標簽頁中共享資料,
- 資料傳輸:Cookie會隨著每次HTTP請求一起發送到服務器端,這會增加額外的網路流量,而sessionStorage和localStorage中存盤的資料只存在于客戶端,不會被發送到服務器端,
瀏覽器快取
瀏覽器快取(Browser Caching)是為了節約網路的資源加速瀏覽,瀏覽器在用戶磁盤上對最近請求過的檔案進行存盤,當訪問者再次請求這個頁面時,瀏覽器就可以從本地磁盤顯示檔案,這樣就可以加速頁面的閱覽,
通常瀏覽器快取策略分為兩種:強快取(Expires,cache-control)和協商快取(Last-modified ,Etag),并且快取策略都是通過設定 HTTP Header 來實作的,
- 強快取是指在快取期間不需要請求,state code為200,它可以通過Expires和Cache-Control來實作,Expires是HTTP/1.0的產物,表示資源的過期時間,受限于本地時間,如果修改了本地時間,可能會造成快取失效,Cache-Control是HTTP/1.1的產物,用來控制資源在本地快取的有效期,它的max-age屬性可以指定資源的最大生命周期,
- 協商快取是指在強快取失效后,瀏覽器攜帶快取標識向服務器發起請求,由服務器根據快取標識決定是否使用快取的程序,其中協商快取的標識也是在回應報文的HTTP頭中和請求結果一起回傳給瀏覽器的,它可以通過Last-Modified/If-Modified-Since和Etag/If-None-Match來實作,
當瀏覽器請求資源時,首先會檢查資源的Expires和Cache-Control,如果命中強快取,狀態仍然回傳200,但不會請求資料,在瀏覽器中能明顯看到from cache字樣,如果強快取失效,則會攜帶快取標識向服務器發起請求,由服務器根據快取標識決定是否使用快取,如果命中協商快取,則回傳304狀態碼,并且不會回傳資料,
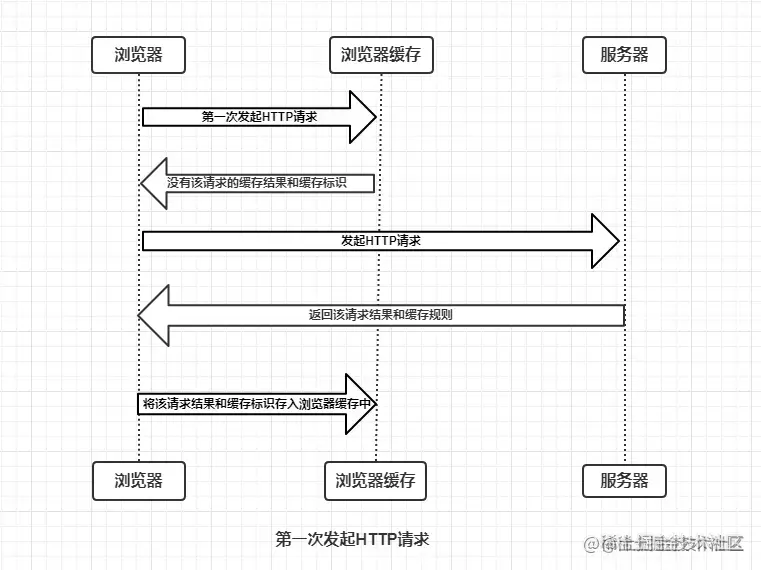
304協商快取
協商快取是一種服務端的快取策略,即通過服務端來判斷某件事情是不是可以被快取,服務端判斷客戶端的資源,是否和服務端資源一致,如果一致則回傳304,反之回傳200和最新的資源,
當網頁不是首次加載時,如果設定了強快取,資料則會從快取中讀取,不請求服務端,如果強快取時間過期,則會請求服務端,服務端判斷是否命中協商快取,如果協商快取時間或者哈希沒變,則回傳304,如果協商快取時間對比不一樣或資源變化,則資料重新被獲取,回傳200,
行程、執行緒、協程
行程、執行緒和協程是計算機程式執行的三種不同方式,
- 行程是作業系統分配資源和調度的基本單位,它擁有獨立的記憶體空間和系統資源,一個行程可以包含多個執行緒,執行緒共享行程的資源,
- 執行緒是作業系統能夠進行運算調度的最小單位,它被包含在行程之中,是行程中的實際運作單位,執行緒共享行程的記憶體空間和系統資源,但擁有獨立的運行堆疊和程式計數器,
- 協程是一種輕量級的執行緒,它避免了無意義的調度,由此可以提高性能,但也因此,程式員必須自己承擔調度的責任,協程也失去了標準執行緒使用多CPU的能力,
行程和執行緒的區別與聯系
行程和執行緒是兩個密切相關但又不同的概念,
行程和執行緒之間的區別主要在于它們是不同的作業系統資源管理方式,
- 行程有獨立的地址空間,一個行程崩潰后,在保護模式下不會對其它行程產生影響,
- 而執行緒只是一個行程中的不同執行路徑,執行緒有自己的堆疊和區域變數,但執行緒之間沒有單獨的地址空間,
- 同一行程的所有執行緒共享該行程的所有資源,一個執行緒死掉就等于整個行程死掉,
- 一個執行緒只能屬于一個行程,而一個行程可以有多個執行緒,且至少有一個執行緒,
網路攻擊
網路攻擊是指損害網路系統安全屬性的危害行為,危害行為導致網路系統的機密性、完整性、可控性、真實性、抗抵賴性等受到不同程度的破壞,
常見的網路攻擊型別包括:
- 惡意軟體:一種可以執行各種惡意任務的應用程式,
- 網路釣魚攻擊:攻擊者試圖誘騙毫無戒心的受害者交出有價值的資訊,例如密碼、信用卡詳細資訊、知識產權等,
- 中間人攻擊(MITM):攻擊者攔截兩方之間的通信以試圖監視受害者、竊取個人資訊或憑據,或者可能以某種方式改變對話,
- 分布式拒絕服務(DDoS)攻擊:攻擊者實質上用大量流量淹沒目標服務器,以試圖破壞甚至關閉目標,
- SQL注入攻擊:一種特定于 SQL 資料庫的攻擊型別,SQL 資料庫使用 SQL 陳述句來查詢資料,這些陳述句通常通過網頁上的 HTML 表單執行,如果未正確設定資料庫權限,攻擊者可能會利用 HTML 表單執行查詢,從而創建、讀取、修改或洗掉存盤在資料庫中的資料,
- 零日漏洞利用:網路犯罪分子獲悉在某些廣泛使用的軟體應用程式和作業系統中發現的漏洞,然后將使用該軟體的組織作為目標,以便在修復程式可用之前利用該漏洞,
- 還有其他的例如:DNS隧道攻擊、商業電子郵件攻擊 (BEC) 和加密劫持等,
部分攻擊的防御措施:
- 防御網路攻擊的方法有很多,具體取決于所面臨的威脅型別,例如,防止惡意軟體攻擊需要安裝最新最好的反惡意軟體/垃圾郵件保護軟體,確保員工接受過識別惡意電子郵件和網站的培訓,擁有強大的密碼策略,并盡可能使用多因素身份驗證,為所有軟體打補丁并保持最新,僅在絕對必要時才使用管理員賬戶,控制對系統和資料的訪問,并嚴格遵守最小權限模型,監控網路是否存在惡意活動,包括可疑檔案加密、入站/出站網路流量、性能問題等,
- 防止網路釣魚攻擊需要員工接受過充分的培訓,能夠識別可疑的電子郵件、鏈接和網站,并且知道不要輸入資訊或從他們不信任的網站下載檔案,下載任何可以幫助識別惡意網站的附加組件也是一個好主意,
- 防止 MITM 攻擊需要使用 VPN(虛擬專用網路),尤其是當從公共 Wi-Fi 熱點連接時,當心虛假網站、侵入性彈出視窗和無效證書,并在每個 URL 的開頭查找“HTTPS”,
- 防止 DDoS 攻擊需要使用下一代防火墻或入侵防御系統 (IPS) 將實時了解任何流量不一致、網路性能問題、間歇性網路崩潰等,將服務器放在不同的資料中心也是一個好主意,因為如果當前服務器發生故障,可以切換到另一臺服務器,在許多方面,保護網路免受 DDoS 攻擊的最佳方法是制定一個久經考驗的回應計劃,這將能夠盡快讓系統恢復在線并維持業務運營,
- 防止 SQL 注入攻擊,可以采用引數化陳述句并加強對用戶輸入的驗證等,
其他
get和post的區別
GET和POST是兩種HTTP請求方法,它們之間有一些區別,
- GET方法用于從指定的資源請求資料,它將引數顯示在URL上,例如:/test/demo_form.php?name1=value1&name2=value2,GET方法提交的資料量有限制,因為它是通過URL添加資料來發送的,而URL的長度是受限制的,GET方法只允許ASCII字符,此外,GET請求可被快取、保留在瀏覽器歷史記錄中、收藏為書簽,但是,GET請求不應在處理敏感資料時使用,
- POST方法用于向指定的資源提交要被處理的資料,它通過表單提交不會顯示在URL上,因此POST方法更具隱蔽性,POST方法可以傳輸大量的資料,對資料長度沒有要求,POST方法沒有限制,也允許二進制資料,此外,POST請求不會被快取、不會保留在瀏覽器歷史記錄中、不能被收藏為書簽,
http常見狀態碼
HTTP狀態碼用來表明特定HTTP請求是否成功完成,回應被歸為以下五大類:
- 資訊回應 (100–199)
- 成功回應 (200–299)
- 重定向訊息 (300–399)
- 客戶端錯誤回應 (400–499)
- 服務端錯誤回應 (500–599)
一些常見的HTTP狀態碼包括:
- 200 OK:請求成功,
- 301 Moved Permanently:請求的資源的URL已永久更改,
- 302 Found:請求的資源的URI已暫時更改,
- 304 Not Modified:所請求的資源未修改,客戶端可以繼續使用相同的快取版本的回應,
- 400 Bad Request:客戶端請求的語法錯誤,服務器無法理解,
- 401 Unauthorized:請求要求用戶的身份認證,
- 403 Forbidden:客戶端沒有訪問內容的權限,
- 404 Not Found:服務器找不到請求的資源,
- 500 Internal Server Error:服務器內部錯誤,無法完成請求,
CDN
CDN是Content Delivery Network的縮寫,即內容分發網路,它的基本思路是盡可能避開互聯網上有可能影響資料傳輸速度和穩定性的瓶頸和環節,使內容傳輸的更快、更穩定,
CDN的作業原理就是將源站的資源快取到CDN各個節點上,當請求命中了某個節點的資源快取時,立即回傳客戶端,避免每個請求的資源都通過源站獲取,避免網路擁塞、緩解源站壓力,保證用戶訪問資源的速度和體驗,
簡單來說,CDN通過在全球范圍內部署大量節點服務器,將網站內容快取在這些節點服務器上,當用戶訪問網站時,CDN會根據用戶的地理位置和網路狀況等因素,智能調度用戶訪問離其最近的節點服務器,從而加快網站訪問速度、提高網站可用性,
主要作用:
- 加快網站訪問速度:通過將網站內容快取在全球范圍內的節點服務器上,CDN能夠讓用戶就近訪問所需內容,從而加快網站訪問速度,
- 提高網站可用性:CDN能夠通過智能調度、負載均衡等技術,保證用戶能夠快速、穩定地訪問網站,提高網站的可用性,
- 緩解源站壓力:CDN能夠將大量用戶請求分流到各個節點服務器上,從而減輕源站的壓力,保證源站能夠穩定運行,
- 節省帶寬成本:CDN能夠通過快取技術、資料壓縮技術等手段,有效減少資料傳輸量,從而節省源站的帶寬成本,
演算法
時間復雜度和空間復雜度:衡量演算法的優劣, 時間復雜度和空間復雜度是用來衡量演算法的優劣的兩個指標,時間復雜度表示演算法執行時間與資料規模之間的關系,常用大O表示法來表示,空間復雜度表示演算法在運行程序中臨時占用存盤空間大小的量度,也常用大O表示法來表示,
常見的演算法型別包括:
- 排序演算法:快速排序、歸并排序、計數排序,
- 搜索演算法:回溯、遞回、剪枝技巧,
- 圖論:最短路、最小生成樹、網路流建模,
- 動態規劃:背包問題、最長子序列、計數問題,
- 基礎技巧:分治、倍增、二分、貪心,
常見的考察內容包括:
- 陣列與鏈表:單/雙向鏈表、跳舞鏈,
- 堆疊與佇列,
- 樹與圖:最近公共祖先、并查集,
- 哈希表,
- 堆:大/小根堆、可并堆,
- 字串:字典樹、后綴樹,
例子:
- 爬樓梯:每次可以選擇爬1個或2個臺階,問有多少種爬樓梯的方法,
var climbStairs = function(n) {
if (n === 1) {
return 1;
}
let dp = new Array(n + 1);
dp[1] = 1;
dp[2] = 2;
for (let i = 3; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
};
- 有效的括號:判斷括號是否正確閉合,
var isValid = function(s) {
let stack = [];
let map = {
'(': ')',
'[': ']',
'{': '}'
}
for (let i = 0; i < s.length; i++) {
if (map[s[i]]) {
stack.push(s[i]);
} else if (s[i] !== map[stack.pop()]) {
return false;
}
}
return stack.length === 0;
};
- 整數轉化英文表示:將整數轉化為英文表示,
const singles = ["", "One", "Two", "Three", "Four", "Five", "Six", "Seven", "Eight", "Nine"];
const teens = ["Ten", "Eleven", "Twelve", "Thirteen", "Fourteen", "Fifteen", "Sixteen", "Seventeen", "Eighteen", "Nineteen"];
const tens = ["", "Ten", "Twenty", "Thirty", "Forty", "Fifty", "Sixty", "Seventy", "Eighty", "Ninety"];
const thousands = ["", "Thousand", "Million", "Billion"];
var numberToWords = function(num) {
if (num === 0) {
return 'Zero';
}
let sb = '';
let unit = 1000000000;
for (let i = 3; i >= 0; i--) {
let curNum = Math.floor(num / unit);
if (curNum !== 0) {
num -= curNum * unit;
sb += toEnglish(curNum) + thousands[i] + ' ';
}
unit /= 1000;
}
return sb.trim();
};
function toEnglish(num) {
let curr = '';
let hundred = Math.floor(num / 100);
num %= 100;
if (hundred !== 0 && num !== 0) {
curr += singles[hundred] + ' Hundred ';
} else if (hundred !== 0 && num === 0) {
curr += singles[hundred] + ' Hundred';
}
let ten = Math.floor(num / 10);
if (ten >= 2 && num % 10 !== 0) {
curr += tens[ten] + ' ';
num %= 10;
} else if (ten >= 2 && num % 10 === 0) {
curr += tens[ten];
num %= 10;
}
if (num < 10 && num > 0) {
curr += singles[num] + ' ';
} else if (num >=10 && num <20) {
curr += teens[num -10] + ' ';
}
return curr;
}
- Z 字形變換:將字串按照Z字形排列后輸出,
var convert = function(s, numRows) {
if (numRows === 1 || s.length < numRows) return s;
let rows = [];
let converted = '';
let reverse = false;
let count = 0;
for (let i=0; i<numRows; i++) rows[i] = [];
for (let i=0; i<s.length; i++) {
rows[count].push(s[i]);
if (count === numRows-1 || count === 0) reverse=!reverse;
reverse ? count++ : count--;
}
for(let row of rows){
converted+=row.join('');
}
return converted;
};
- 兩數之和:在陣列中找出和為目標值的兩個數,
var twoSum = function(nums, target) {
let map = new Map();
for (let i = 0; i < nums.length; i++) {
let complement = target - nums[i];
if (map.has(complement)) {
return [map.get(complement), i];
}
map.set(nums[i], i);
}
};
- 最長回文子串:找出字串中最長的回文子串,
var longestPalindrome = function(s) {
if (s.length < 2) return s;
let start = 0;
let maxLength = 1;
function expandAroundCenter(left, right) {
while (left >= 0 && right < s.length && s[left] === s[right]) {
if (right - left + 1 > maxLength) {
maxLength = right - left + 1;
start = left;
}
left--;
right++;
}
}
for (let i = 0; i < s.length; i++) {
expandAroundCenter(i - 1, i + 1);
expandAroundCenter(i, i + 1);
}
return s.substring(start, start + maxLength);
};
?更多演算法題
總結
除了一些基礎的,還有一些不常見但是也很重要的前端技術,例如:WebAssembly、Service Worker、Progressive Web App(PWA)、Web Components 和 GraphQL等,
以上就是目前所學的知識進行收集和整理的一些前端八股文,如若有錯誤請大佬們指正我會馬上進行更改,若有欠缺請兄弟們補充一下我都會加上去!
最好的學習還是要把所學的知識進行整理理解,其實我也是小白,以上還有很多不大懂的地方需要進行理解學習再融會貫通,希望與各位一起進步,加油!!!
參考文獻
https://juejin.cn/post/6994617237793406990
https://juejin.cn/post/7016593221815910408
https://cn.vuejs.org/guide/introduction.html
https://react.docschina.org/learn
創作不易,若需轉載請備注出處!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/554464.html
標籤:其他
上一篇:9.4. 分布式與微服務架構
下一篇:返回列表