一、背景
搜索推薦演算法架構為京東集團所有的搜索推薦業務提供服務,實時回傳處理結果給上游,部門各子系統已經實作了基于CPU的自適應限流,但是Client端對Server端的呼叫依然是RR輪詢的方式,沒有考慮下游機器性能差異的情況,無法最大化利用集群整體CPU,存在著Server端CPU不均衡的問題,
京東廣告部門針對其業務場景研發的負載均衡方法很有借鑒意義,他們提出的RALB(Remote Aware Load Balance)演算法能夠提升下游服務集群機器CPU資源效率,避免CPU短板效應,讓性能好的機器能夠處理更多的流量,我們將其核心思想應用到我們的系統中,獲得了不錯的收益,
本文的結構如下:
1.RALB簡介
?簡單介紹了演算法的原理,
2.功能驗證
?將RALB負載均衡技術應用到搜索推薦架構系統中,進行功能上的驗證,
3.吞吐測驗
?主要將RALB和RR兩種負載均衡技術做對比,驗證了在集群不限流和完全限流的情況下,兩者的吞吐沒有明顯差異,在RR部分限流的情況下,兩者吞吐存在著差異,并且存在著最大的吞吐差異點,對于RALB來說,Server端不限流到全限流是一個轉折點,幾乎沒有部分限流的情況,
4.邊界測驗
?通過模擬各種邊界條件,對系統進行測驗,驗證了RALB的穩定性和可靠性,
5.功能上線
?在所有Server端集群全面開啟RALB負載均衡模式,可以看出,上線前后,Server端的QPS逐漸出現分層,Server端的CPU逐漸趨于統一,
二、RALB 簡介
RALB是一種以CPU均衡為目標的高性能負載均衡演算法,
2.1 演算法目標
1.調節Server端的CPU使用率,使得各節點之間CPU相對均衡,避免CPU使用率過高觸發集群限流
2.QPS與CPU使用率成線性關系,調節QPS能實作CPU使用率均衡的目標
2.2 演算法原理
2.2.1 演算法步驟
1.分配流量的時候,按照權重分配(帶權重的隨機演算法,wr)
2.收集CPU使用率:Server端通過RPC反饋CPU使用率(平均1s)給Client端
3.調權:定時(每3s)根據集群及各節點上的CPU使用率(視窗內均值)調節權重,使各節點CPU均衡
2.2.2 指標依賴
| 編號 | 指標 | 作用 | 來源 |
|---|---|---|---|
| 1 | IP | 可用IP串列 | 服務注冊發現和故障屏蔽模塊進行維護 |
| 2 | 實時健康度 | IP可用狀態實時變化,提供演算法的邊界條件 | RPC框架健康檢查功能維護 |
| 3 | 歷史健康度 | 健康度歷史值,用于判斷ip故障及恢復等邊界條件 | 指標2的歷史值 |
| 4 | 動態目標(CPU使用率) | 提供均衡演算法的最直接目標依據 | Server端定時統計,RPC框架通過RPC回傳 |
| 5 | 權重weight | 實時負載分發依據 | 演算法更新 |
2.2.3 調權演算法

2.2.4 邊界處理
邊界1:反饋視窗(3s)內,如果下游ip沒被訪問到,其CPU均值為0,通過調權演算法會認為該節點性能極好,從而調大權重
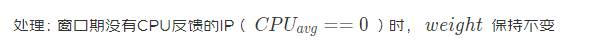
邊界2:網路故障時,RPC框架將故障節點設為不可用,CPU和權重為0;網路恢復后,RPC框架將IP設定為可用,但是權重為0的節點分不到流量,從而導致該節點將一直處于不可用狀態
處理:權重的更新由定時器觸發,記錄節點的可用狀態,當節點從不可用恢復為可用狀態時,給定一個低權重,逐步恢復
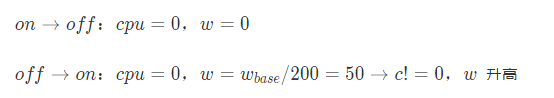
2.3 落地關鍵
既要快又要穩,在任何情況下都要避免陷入僵局和雪崩,尤其要處理好邊界條件
演算法要點:
1.公式中各依賴因子的更新保持獨立的含義和更新機制,以維護演算法的可靠和簡潔
?IP串列的更新由服務注冊發現和RPC框架共同保證
?RPC更新CPU
2.注意邊界值的含義,邊界值的含義需要區分連續值
?CPU = 0,表示未知,不表示CPU性能好
?w = 0,表示不會被分配流量,只有在不可用的情況下才為0;可用情況下,應該至少有一個較小的值,保證仍能觸發RPC,進而可以更新權重
3.演算法更新權重,不要依賴RPC觸發,而應該定時更新
三、功能驗證
3.1 壓測準備
| Module | IP | CPU |
|---|---|---|
| Client端 | 10.173.102.36 | 8 |
| Server端 | 11.17.80.238 | 8 |
| 11.18.159.191 | 8 | |
| 11.17.191.137 | 8 |
3.2 壓測資料
| 指標 | RR負載均衡 | RALB負載均衡 |
|---|---|---|
| QPS | ||
| CPU | **** |
|
| TP99 |
由于機器性能差距不大,所以壓測的CPU效果并不明顯,為了使CPU效果更明顯,給節點”11.17.80.238“施加起始的負載(即無流量時,CPU使用率為12.5%)
| 指標 | LA負載均衡 | RR負載均衡 | RALB負載均衡 |
|---|---|---|---|
| QPS | |||
| CPU | |||
| TP99 |
3.3 壓測結論
經過壓測,RR和LA均存在CPU不均衡的問題,會因為機器資源的性能差異,而導致短板效應,達不到充分利用資源的目的,
RALB是以CPU作為均衡目標的,所以會根據節點的CPU實時調整節點承接的QPS,進而達到CPU均衡的目標,功能上驗證是可用的,CPU表現符合預期,
四、吞吐測驗
4.1 壓測目標
RALB是一種以CPU使用率作為動態指標的負載均衡演算法,能很好地解決CPU不均衡的問題,避免CPU短板效應,讓性能好的機器能夠處理更多的流量,因此,我們期望RALB負載均衡策略相比于RR輪詢策略能夠得到一定程度的吞吐提升,
4.2 壓測準備
Server端100臺機器供測驗,Server端為純CPU自適應限流,限流閾值配置為55%,
4.3 壓測資料
通過壓測在RALB和RR兩種負載均衡模式下,Server端的吞吐隨著流量變化的趨勢,對比兩種負載均衡策略對于集群吞吐的影響,
4.3.1 RALB
4.3.1.1 吞吐資料
下表是Server端的吞吐資料,由測驗發壓Client端,負載均衡模式設定為RALB,在18:17Server端的狀況接近于剛剛限流,整個壓測階段,壓測了不限流、部分限流、完全限流3種情況,
| 時間 | 17:40 | 17:45 | 17:52 | 18:17 | 18:22 |
|---|---|---|---|---|---|
| 總流量 | 2270 | 1715 | 1152 | 1096 | 973 |
| 處理流量 | 982 | 1010 | 1049 | 1061 | 973 |
| 被限流量 | 1288 | 705 | 103 | 35 | 0 |
| 限流比例 | 56.74% | 41% | 8.9% | 3.2% | 0% |
| 平均CPU使用率 | 55% | 55% | 54% | 54% | 49% |
4.3.1.2 指標監控
Server端機器收到的流量按性能分配,CPU保持均衡,
| QPS | CPU |
|---|---|
4.3.2 RR
4.3.2.1 吞吐資料
下表是Server端的吞吐資料,由測驗發壓Client端,負載均衡模式設定為RR,在18:46 Server端的整體流量接近于18:17 Server端的整體流量,后面將重點對比這兩個關鍵時刻的資料,
| 時間 | 18:40 | 18:46 | 19:57 | 20:02 | 20:04 | 20:09 |
|---|---|---|---|---|---|---|
| 總流量 | 967 | 1082 | 1149 | 1172 | 1263 | 1314 |
| 處理流量 | 927 | 991 | 1024 | 1036 | 1048 | 1047 |
| 被限流量 | 40 | 91 | 125 | 136 | 216 | 267 |
| 限流比例 | 4.18% | 8.4% | 10.92% | 11.6% | 17.1% | 20.32% |
| 平均CPU使用率 | 45%(部分限流) | 51%(部分限流) | 53%(部分限流) | 54%(接近全部限流) | 55%(全部限流) | 55%(全部限流) |
4.3.2.2 指標監控
Server端收到的流量均衡,但是CPU有差異,
| QPS | CPU |
|---|---|
4.4 壓測分析
4.4.1 吞吐曲線
根據4.3節的壓測資料,進行Server端吞吐曲線的繪制,對比RALB和RR兩種負載均衡模式下的吞吐變化趨勢,
import matplotlib.pyplot as plt
import numpy as np
x = [0,1,2,3,4,5,6,7,8,9,9.73,10.958,11.52,17.15,22.7]
y = [0,1,2,3,4,5,6,7,8,9,9.73,10.61,10.49,10.10,9.82]
w = [0,1,2,3,4,5,6,7,8,9.674,10.823,11.496,11.723,12.639,13.141,17.15,22.7]
z = [0,1,2,3,4,5,6,7,8,9.27,9.91,10.24,10.36,10.48,10.47,10.10,9.82]
plt.plot(x, y, 'r-o')
plt.plot(w, z, 'g-o')
plt.show()
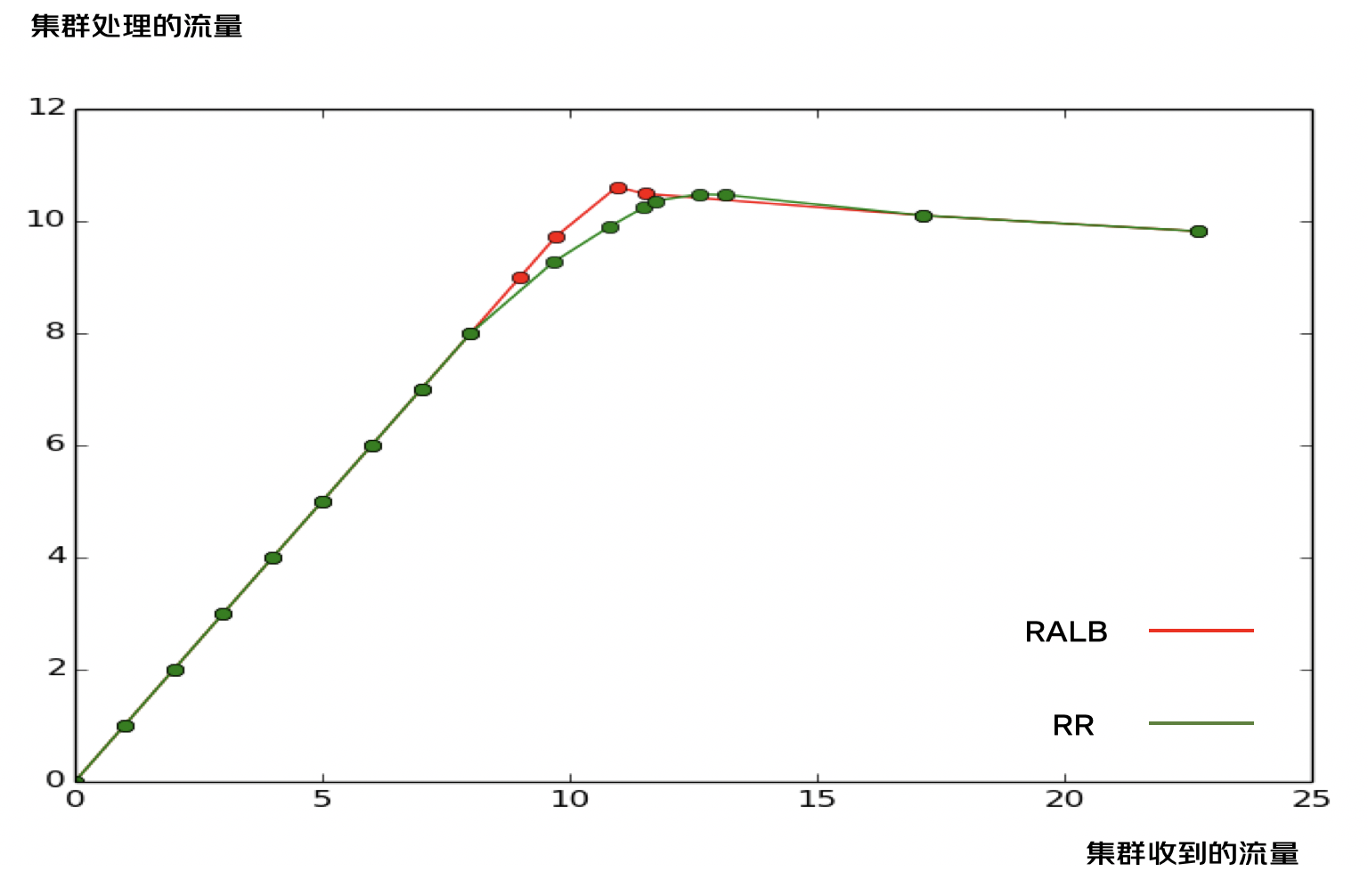
4.4.2 曲線分析
| 負載均衡策略 | RALB | RR |
|---|---|---|
| 階段一:所有機器未限流 | 接收QPS=處理QPS,表現為y =x 的直線 | 接收QPS=處理QPS,表現為y =x 的直線 |
| 階段二:部分機器限流 | 不存在RALB根據下游CPU進行流量分配,下游根據CPU進行限流,理論上來講,下游的CPU永遠保持一致,所有的機器同時達到限流,不存在部分機器限流的情況, 所以在圖中,不限流與全部機器限流是一個轉折點,沒有平滑過渡的階段, | RR策略,下游的機器分配得到的QPS一致,由于下游根據CPU進行限流,所以不同機器限流的時刻有差異, 相對于RALB,RR更早地出現了限流的情況,并且在達到限流之前,RR的吞吐是一直小于RALB的, |
| 階段三:全部機器限流 | 全部機器都達到限流閾值55%之后,理論上,之后無論流量怎樣增加,處理的QPS會維持不變,圖中顯示處理的QPS出現了一定程度的下降,是因為處理限流也需要消耗部分CPU | RR達到全部限流的時間要比RALB更晚,在全部限流之后,兩種模式的處理的QPS是一致的, |
4.5 壓測結論
臨界點:吞吐差異最大的情況,即RALB模式下非限流與全限流的轉折點,
通過上述分析,可以知道,在RALB不限流與全部限流的臨界點處,RR與RALB的吞吐差異最大,
此時,計算得出RALB模式下,Server集群吞吐提升7.06%,
五、邊界測驗
通過模擬各種邊界條件,來判斷系統在邊界條件的情況下,系統的穩定性,
| 邊界條件 | 壓測情形 | 壓測結論 |
|---|---|---|
| 下游節點限流 | CPU限流 | 懲罰因子的調整對于流量的分配有重要影響 |
| QPS限流 | 符合預期 | |
| 下游節點超時 | Server端超時每個請求,固定sleep 1s | 請求持續超時期間分配的流量基本為0 |
| 下游節點例外退出 | Server端行程被殺死直接kill -9 pid | 殺死行程并自動拉起,流量分配快速恢復 |
| 下游節點增減 | Server端手動Jsf上下線 | jsf下線期間不承接流量 |
| Server端重啟stop + start | 正常反注冊、注冊方式操作Server端行程,流量分配符合預期 |
六、功能上線
宿遷機房Client端上線配置,在所有Server端集群全面開啟RALB負載均衡模式,可以看出,上線前后,Server端的QPS逐漸出現分層,Server端的CPU逐漸趨于統一,
| 上線前后Server端QPS分布 | 上線前后Server端的CPU分布 |
|---|---|
參考資料
1.負載均衡技術
2.深入淺出負載均衡
作者:京東零售 胡沛棟
來源:京東云開發者社區
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/554774.html
標籤:其他
下一篇:返回列表