基于預訓練模型 ERNIE-Gram 實作語意匹配
1. 背景介紹
文本語意匹配任務,簡單來說就是給定兩段文本,讓模型來判斷兩段文本是不是語意相似,
在本案例中以權威的語意匹配資料集 LCQMC 為例,LCQMC 資料集是基于百度知道相似問題推薦構造的通問句語意匹配資料集,訓練集中的每兩段文本都會被標記為 1(語意相似) 或者 0(語意不相似),更多資料集可訪問千言獲取哦,
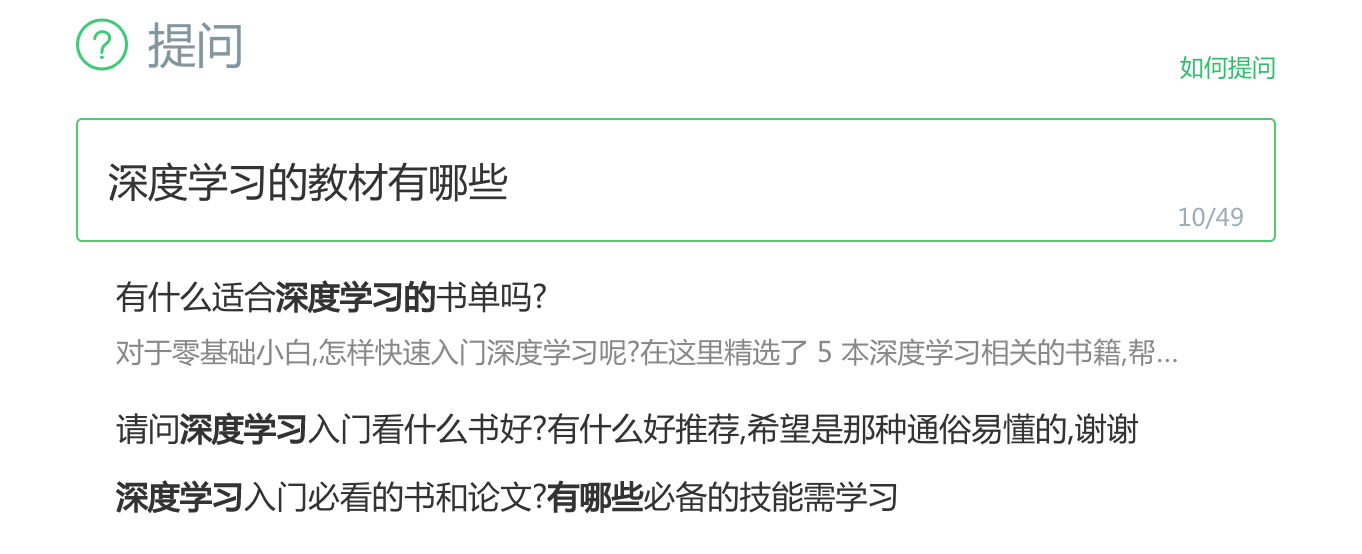
例如百度知道場景下,用戶搜索一個問題,模型會計算這個問題與候選問題是否語意相似,語意匹配模型會找出與問題語意相似的候選問題回傳給用戶,加快用戶提問-獲取答案的效率,例如,當某用戶在搜索引擎中搜索 “深度學習的教材有哪些?”,模型就自動找到了一些語意相似的問題展現給用戶:
2.快速實踐
介紹如何準備資料,基于 ERNIE-Gram 模型搭建匹配網路,然后快速進行語意匹配模型的訓練、評估和預測,
2.1 資料加載
為了訓練匹配模型,一般需要準備三個資料集:訓練集 train.tsv、驗證集dev.tsv、測驗集test.tsv,此案例我們使用 PaddleNLP 內置的語意資料集 LCQMC 來進行訓練、評估、預測,
訓練集: 用來訓練模型引數的資料集,模型直接根據訓練集來調整自身引數以獲得更好的分類效果,
驗證集: 用于在訓練程序中檢驗模型的狀態,收斂情況,驗證集通常用于調整超引數,根據幾組模型驗證集上的表現,決定采用哪組超引數,
測驗集: 用來計算模型的各項評估指標,驗證模型泛化能力,
LCQMC 資料集是公開的語意匹配權威資料集,PaddleNLP 已經內置該資料集,一鍵即可加載,
AI Studio平臺默認安裝了Paddle和PaddleNLP,并定期更新版本, 如需手動更新Paddle,可參考飛槳安裝說明,安裝相應環境下最新版飛槳框架,
使用如下命令確保安裝最新版PaddleNLP:
!pip install --upgrade paddlenlp
import paddlenlp
paddlenlp.__version__
'2.4.2'
一鍵加載 Lcqmc 的訓練集、驗證集
import time
import os
import numpy as np
import paddle
import paddle.nn.functional as F
from paddlenlp.datasets import load_dataset
# 一鍵加載 Lcqmc 的訓練集、驗證集
train_ds, dev_ds = load_dataset("lcqmc", splits=["train", "dev"])
# 輸出訓練集的前 10 條樣本 -- 資料集的構造方式
for idx, example in enumerate(train_ds):
if idx <= 10:
print(example)
{'query': '喜歡打籃球的男生喜歡什么樣的女生', 'title': '愛打籃球的男生喜歡什么樣的女生', 'label': 1}
{'query': '我手機丟了,我想換個手機', 'title': '我想買個新手機,求推薦', 'label': 1}
{'query': '大家覺得她好看嗎', 'title': '大家覺得跑男好看嗎?', 'label': 0}
{'query': '求秋色之空漫畫全集', 'title': '求秋色之空全集漫畫', 'label': 1}
{'query': '晚上睡覺帶著耳機聽音樂有什么害處嗎?', 'title': '孕婦可以戴耳機聽音樂嗎?', 'label': 0}
{'query': '學日語軟體手機上的', 'title': '手機學日語的軟體', 'label': 1}
{'query': '列印機和電腦怎樣連接,該如何設定', 'title': '如何把帶無線的電腦連接到列印機上', 'label': 0}
{'query': '俠盜飛車罪惡都市怎樣改車', 'title': '俠盜飛車罪惡都市怎么改車', 'label': 1}
{'query': '什么花一年四季都開', 'title': '什么花一年四季都是開的', 'label': 1}
{'query': '看圖猜一電影名', 'title': '看圖猜電影!', 'label': 1}
{'query': '這上面寫的是什么?', 'title': '胃上面是什么', 'label': 0}
2.2 資料預處理
資料處理使用CPU,不是GPU
通過 PaddleNLP 加載進來的 LCQMC 資料集是原始的明文資料集,這部分我們來實作組 batch、tokenize 等預處理邏輯,將原始明文資料轉換成網路訓練的輸入資料,
定義樣本轉換函式
# 因為是基于預訓練模型 ERNIE-Gram 來進行,所以需要首先加載 ERNIE-Gram 的 tokenizer,
# 后續樣本轉換函式基于 tokenizer 對文本進行切分
tokenizer = paddlenlp.transformers.ErnieGramTokenizer.from_pretrained('ernie-gram-zh')
https://bj.bcebos.com/paddlenlp/models/transformers/ernie_gram_zh/vocab.txt
aistudio@jupyter-2631487-6327315:~$ cd /home/aistudio/.paddlenlp/models/ernie-gram-zh/
aistudio@jupyter-2631487-6327315:~/.paddlenlp/models/ernie-gram-zh$ ls
special_tokens_map.json tokenizer_config.json vocab.txt
aistudio@jupyter-2631487-6327315:~/.paddlenlp/models/ernie-gram-zh$ head -200 vocab.txt
[PAD]
[CLS]
[SEP]
[MASK]
,
的
、
一
人
有
是
在
中
為
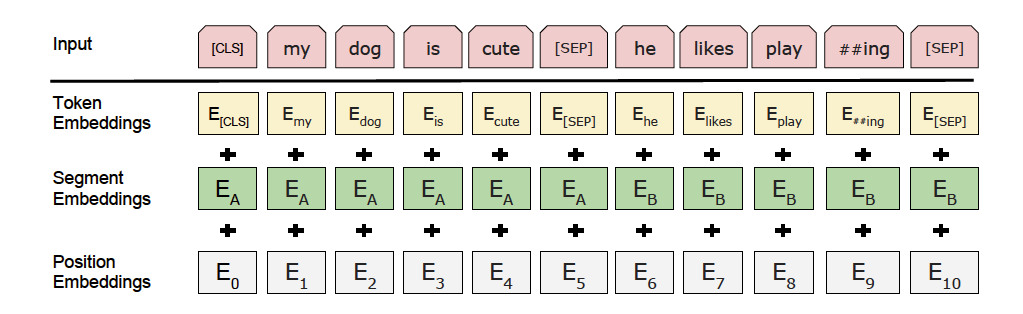
不管是兩句話還是一句話文本,都需要在前面加上 [CLS] 特殊符號,如果是兩句話,會在中間加上 [SEP],尾巴上可加可不加[SEP]
接下來做 Embedding 查找,如果my ID=1,去查 Token Embedding 的詞向量,
同時多了一個 Segment Embeddings,當是兩句話時,會有 \(E_a 、E_b\) ,讓模型學到這是兩句話
Position Embeddings,位置距離是學不到的,所以需要給詞做個編碼,從 0 ~ 512
將Token Embedding、Segment Embedding、Position Embedding 三個資訊進行相加,就可以拿到 Token 輸完,通過ID進行查找,最后的 Embedding 的值,這個 Embedding 值就可以扔到后面的 BERT 模型中,
# 將 1 條明文資料的 query、title 拼接起來,根據預訓練模型的 tokenizer 將明文轉換為 ID 資料
# 回傳 input_ids 和 token_type_ids
def convert_example(example, tokenizer, max_seq_length=512, is_test=False):
query, title = example["query"], example["title"]
# max_seq_length 序列截斷的最大長度
# 得到編碼的最后結果
encoded_inputs = tokenizer(text=query, text_pair=title, max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"] # Token Id
token_type_ids = encoded_inputs["token_type_ids"] # Segment Id
if not is_test:
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
# 在預測或者評估階段,不回傳 label 欄位
else:
return input_ids, token_type_ids
# 對訓練集的第 1 條資料進行轉換
# train_ds[0] => {'query': '喜歡打籃球的男生喜歡什么樣的女生', 'title': '愛打籃球的男生喜歡什么樣的女生', 'label': 1}
input_ids, token_type_ids, label = convert_example(train_ds[0], tokenizer)
# 1 => CLS,692 => 喜,881 => 歡 ... vocab.txt 中的位置 https://bj.bcebos.com/paddlenlp/models/transformers/ernie_gram_zh/vocab.txt
print(input_ids)
[1, 692, 811, 445, 2001, 497, 5, 654, 21, 692, 811, 614, 356, 314, 5, 291, 21, 2, 329, 445, 2001, 497, 5, 654, 21, 692, 811, 614, 356, 314, 5, 291, 21, 2]
# 0 => 第1句話、1 => 第2句話
print(token_type_ids)
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
# 1 => 匹配 0 => 不匹配
print(label)
[1]
# 為了后續方便使用,我們使用python偏函式(partial)給 convert_example 賦予一些默認引數
from functools import partial
# 訓練集和驗證集的樣本轉換函式
trans_func = partial(
convert_example, # 一個 batch, 一個 batch 的傳
tokenizer=tokenizer, # 固定的
max_seq_length=512) # 固定的
組裝 Batch 資料 & Padding
上一小節,我們完成了對單條樣本的轉換,本節我們需要將樣本組合成 Batch 資料,對于不等長的資料還需要進行 Padding 操作,便于 GPU 訓練,
PaddleNLP 提供了許多關于 NLP 任務中構建有效的資料 pipeline 的常用 API
| API | 簡介 |
|---|---|
paddlenlp.data.Stack |
堆疊N個具有相同shape的輸入資料來構建一個batch |
paddlenlp.data.Pad |
將長度不同的多個句子padding到統一長度,取N個輸入資料中的最大長度 |
paddlenlp.data.Tuple |
將多個batchify函式包裝在一起 |
更多資料處理操作詳見: https://paddlenlp.readthedocs.io/zh/latest/data_prepare/data_preprocess.html
from paddlenlp.data import Stack, Pad, Tuple
a = [1, 2, 3, 4]
b = [3, 4, 5, 6]
c = [5, 6, 7, 8]
result = Stack()([a, b, c])
print("Stacked Data: \n", result)
print()
a = [1, 2, 3, 4]
b = [5, 6, 7]
c = [8, 9]
result = Pad(pad_val=0)([a, b, c]) # 缺的用 0 補充
print("Padded Data: \n", result)
print()
data = https://www.cnblogs.com/vipsoft/p/[
[[1, 2, 3, 4], [1]],
[[5, 6, 7], [0]],
[[8, 9], [1]],
]
batchify_fn = Tuple(Pad(pad_val=0), Stack())
ids, labels = batchify_fn(data)
print("ids: \n", ids)
print()
print("labels: \n", labels)
print()
Stacked Data:
[[1 2 3 4]
[3 4 5 6]
[5 6 7 8]]
Padded Data:
[[1 2 3 4]
[5 6 7 0]
[8 9 0 0]]
ids:
[[1 2 3 4]
[5 6 7 0]
[8 9 0 0]]
labels:
[[1]
[0]
[1]]
# 我們的訓練資料會回傳 input_ids, token_type_ids, labels 3 個欄位
# 因此針對這 3 個欄位需要分別定義 3 個組 batch 操作
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack(dtype="int64") # label
): [data for data in fn(samples)]
定義 Dataloader
下面我們基于組 batchify_fn 函式和樣本轉換函式 trans_func 來構造訓練集的 DataLoader, 支持多卡訓練
# 定義分布式 Sampler: 自動對訓練資料進行切分,支持多卡并行訓練
# 打亂資料,一般設成 ture,打亂讓資料更均衡些
batch_sampler = paddle.io.DistributedBatchSampler(train_ds, batch_size=32, shuffle=True)
# 基于 train_ds 定義 train_data_loader
# 因為我們使用了分布式的 DistributedBatchSampler, train_data_loader 會自動對訓練資料進行切分
train_data_loader = paddle.io.DataLoader(
dataset=train_ds.map(trans_func), # 傳資料
batch_sampler=batch_sampler, # 支持分布式采集方式
collate_fn=batchify_fn, # 構建 batchify_fn
return_list=True) # 沒什么特殊用處,默認就好
# 針對驗證集資料加載,我們使用單卡進行評估,所以采用 paddle.io.BatchSampler 即可
# 定義 dev_data_loader
batch_sampler = paddle.io.BatchSampler(dev_ds, batch_size=32, shuffle=False)
dev_data_loader = paddle.io.DataLoader(
dataset=dev_ds.map(trans_func),
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
return_list=True)
2.3 模型搭建
自從 2018 年 10 月以來,NLP 個領域的任務都通過 Pretrain + Finetune 的模式相比傳統 DNN 方法在效果上取得了顯著的提升,本節我們以百度開源的預訓練模型 ERNIE-Gram 為基礎模型,在此之上構建 Point-wise 語意匹配網路,
首先我們來定義網路結構:
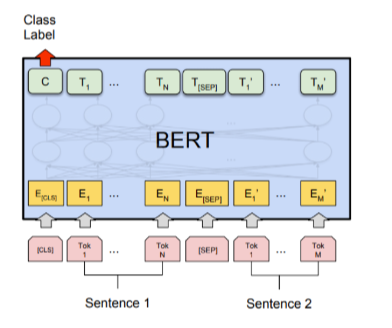
藍色區域理解成呼叫 ERNIE-Gram 模型
單搭:只有一個模型(藍背景),兩句話扔到一個模型里面
雙搭:兩個模型(藍背景),第一個模型輸入第一句話,第二個模型輸入第二句話
[CLS] + Sentence1 + Sentence2 <= 512 句子太長,把不太重要的詞截掉
可以將句子拆分得到多個 CLS,再將它們進行一次操作(相加平均等)
https://gitee.com/paddlepaddle/PaddleNLP/tree/develop/docs/model_zoo
import paddle.nn as nn
# 我們基于 ERNIE-Gram 模型結構搭建 Point-wise 語意匹配網路
# 所以此處先定義 ERNIE-Gram 的 pretrained_model
pretrained_model = paddlenlp.transformers.ErnieGramModel.from_pretrained('ernie-gram-zh')
#pretrained_model = paddlenlp.transformers.ErnieModel.from_pretrained('ernie-1.0')
class PointwiseMatching(nn.Layer):
# 此處的 pretained_model 在本例中會被 ERNIE-Gram 預訓練模型初始化
def __init__(self, pretrained_model, dropout=None):
super().__init__()
self.ptm = pretrained_model
self.dropout = nn.Dropout(dropout if dropout is not None else 0.1)
# 語意匹配任務: 相似、不相似 2 分類任務 , 分類器(輸入 768維向量, 輸出 2分類)
self.classifier = nn.Linear(self.ptm.config["hidden_size"], 2)
# 開始搭模型,如上圖
def forward(self,
input_ids,
token_type_ids=None,
position_ids=None,
attention_mask=None):
# 此處的 Input_ids 由兩條文本的 token ids 拼接而成
# token_type_ids 表示兩段文本的型別編碼
# 回傳的 cls_embedding 就表示這兩段文本經過模型的計算之后而得到的語意表示向量
# position_ids 這邊沒有用
# attention_mask 默認傳None 不用深究,decode 的時候會用到,后面做文本生成的時候需要理解
_, cls_embedding = self.ptm(input_ids, token_type_ids, position_ids,
attention_mask)
# _, 第一個輸出,沒有用,是整個序列的輸出 512個詞的token輸出,512個768維向量
# cls_embedding 第二個輸出
cls_embedding = self.dropout(cls_embedding)
# 基于文本對的語意表示向量進行 2 分類任務,分類器
logits = self.classifier(cls_embedding)
probs = F.softmax(logits)
return probs
# 定義 Point-wise 語意匹配網路
model = PointwiseMatching(pretrained_model)
output
[2023-06-05 15:14:29,980] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/transformers/ernie_gram_zh/ernie_gram_zh.pdparams and saved to /home/aistudio/.paddlenlp/models/ernie-gram-zh
[2023-06-05 15:14:29,983] [ INFO] - Downloading ernie_gram_zh.pdparams from https://bj.bcebos.com/paddlenlp/models/transformers/ernie_gram_zh/ernie_gram_zh.pdparams
20%|██ | 117M/570M [00:10<00:29, 16.3MB/s]
2.4 模型訓練 & 評估
# 調一個線性衰減,慢慢加熱再衰減
from paddlenlp.transformers import LinearDecayWithWarmup
epochs = 3
num_training_steps = len(train_data_loader) * epochs
# 定義 learning_rate_scheduler,負責在訓練程序中對 lr 進行調度
lr_scheduler = LinearDecayWithWarmup(5E-5, num_training_steps, 0.0)
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"]) # 除了這兩個引數,其它的都需要做衰減
]
# 定義 Optimizer
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=0.0, # 比例可以自己設定
apply_decay_param_fun=lambda x: x in decay_params)
# 采用交叉熵 損失函式
criterion = paddle.nn.loss.CrossEntropyLoss()
# 評估的時候采用準確率指標
metric = paddle.metric.Accuracy()
# 因為訓練程序中同時要在驗證集進行模型評估,因此我們先定義評估函式
@paddle.no_grad()
def evaluate(model, criterion, metric, data_loader, phase="dev"):
model.eval()
metric.reset()
losses = []
for batch in data_loader:
input_ids, token_type_ids, labels = batch
probs = model(input_ids=input_ids, token_type_ids=token_type_ids)
loss = criterion(probs, labels)
losses.append(loss.numpy())
correct = metric.compute(probs, labels)
metric.update(correct)
accu = metric.accumulate()
print("eval {} loss: {:.5}, accu: {:.5}".format(phase,
np.mean(losses), accu))
model.train()
metric.reset()
通過GPU跑訓練模型,CPU基本看不到動的,
# 接下來,開始正式訓練模型,訓練時間較長,可注釋掉這部分
global_step = 0
tic_train = time.time()
# 一個 epoch 保存一次訓練檔案
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch
probs = model(input_ids=input_ids, token_type_ids=token_type_ids)
loss = criterion(probs, labels)
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
# 每間隔 10 step 輸出訓練指標,比如10個 batch size = 32, 320 個資料扔完后就要打個日志看一下
# 過密的打日志會影響訓練的速度,
if global_step % 10 == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %.5f, accu: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, acc,
10 / (time.time() - tic_train)))
tic_train = time.time()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
# 每間隔 100 step 在驗證集和測驗集上進行評估
# 列印日志的 10 倍,做一次驗證,3200條資料后做一次驗證
# 驗證的目的,判斷這個模型是否收斂,過擬合,等表征
if global_step % 100 == 0:
evaluate(model, criterion, metric, dev_data_loader, "dev")
# 訓練結束后,存盤模型引數,一次全量跑完(一個 epoch) 保存一次訓練檔案
# 檔案保存太頻繁,資料很大,aistudio 保存檔案太多,是不支持生成版本的,
save_dir = os.path.join("checkpoint", "model_%d" % global_step)
os.makedirs(save_dir) # log 檔案
save_param_path = os.path.join(save_dir, 'model_state.pdparams')
paddle.save(model.state_dict(), save_param_path)
tokenizer.save_pretrained(save_dir)
通過GPU跑訓練模型,CPU基本看不到動的,
模型訓練程序中會輸出如下日志:
global step 5310, epoch: 3, batch: 1578, loss: 0.31671, accu: 0.95000, speed: 0.63 step/s
global step 5320, epoch: 3, batch: 1588, loss: 0.36240, accu: 0.94063, speed: 6.98 step/s
global step 5330, epoch: 3, batch: 1598, loss: 0.41451, accu: 0.93854, speed: 7.40 step/s
global step 5340, epoch: 3, batch: 1608, loss: 0.31327, accu: 0.94063, speed: 7.01 step/s
global step 5350, epoch: 3, batch: 1618, loss: 0.40664, accu: 0.93563, speed: 7.83 step/s
global step 5360, epoch: 3, batch: 1628, loss: 0.33064, accu: 0.93958, speed: 7.34 step/s
global step 5370, epoch: 3, batch: 1638, loss: 0.38411, accu: 0.93795, speed: 7.72 step/s
global step 5380, epoch: 3, batch: 1648, loss: 0.35376, accu: 0.93906, speed: 7.92 step/s
global step 5390, epoch: 3, batch: 1658, loss: 0.39706, accu: 0.93924, speed: 7.47 step/s
global step 5400, epoch: 3, batch: 1668, loss: 0.41198, accu: 0.93781, speed: 7.41 step/s
eval dev loss: 0.4177, accu: 0.89082
global step 5410, epoch: 3, batch: 1678, loss: 0.34453, accu: 0.93125, speed: 0.63 step/s
global step 5420, epoch: 3, batch: 1688, loss: 0.34569, accu: 0.93906, speed: 7.75 step/s
global step 5430, epoch: 3, batch: 1698, loss: 0.39160, accu: 0.92917, speed: 7.54 step/s
global step 5440, epoch: 3, batch: 1708, loss: 0.46002, accu: 0.93125, speed: 7.05 step/s
global step 5450, epoch: 3, batch: 1718, loss: 0.32302, accu: 0.93188, speed: 7.14 step/s
global step 5460, epoch: 3, batch: 1728, loss: 0.40802, accu: 0.93281, speed: 7.22 step/s
global step 5470, epoch: 3, batch: 1738, loss: 0.34607, accu: 0.93348, speed: 7.44 step/s
global step 5480, epoch: 3, batch: 1748, loss: 0.34709, accu: 0.93398, speed: 7.38 step/s
global step 5490, epoch: 3, batch: 1758, loss: 0.31814, accu: 0.93437, speed: 7.39 step/s
global step 5500, epoch: 3, batch: 1768, loss: 0.42689, accu: 0.93125, speed: 7.74 step/s
eval dev loss: 0.41789, accu: 0.88968
基于默認引數配置進行單卡訓練大概要持續 4 個小時左右,會訓練完成 3 個 Epoch, 模型最終的收斂指標結果如下:
| 資料集 | Accuracy |
|---|---|
| dev.tsv | 89.62 |
可以看到: 我們基于 PaddleNLP ,利用 ERNIE-Gram 預訓練模型使用非常簡潔的代碼,就在權威語意匹配資料集上取得了很不錯的效果.

可以看下 GPU,如果占有用低的話,可以將 batch size 調大點,不然空著浪費
2.5 模型預測
接下來我們使用已經訓練好的語意匹配模型對一些預測資料進行預測,待預測資料為每行都是文本對的 tsv 檔案,我們使用 Lcqmc 資料集的測驗集作為我們的預測資料,進行預測并提交預測結果到 千言文本相似度競賽
下載我們已經訓練好的語意匹配模型, 并解壓
# 下載我們基于 Lcqmc 事先訓練好的語意匹配模型并解壓
! wget https://paddlenlp.bj.bcebos.com/models/text_matching/ernie_gram_zh_pointwise_matching_model.tar
! tar -xvf ernie_gram_zh_pointwise_matching_model.tar
--2023-06-05 16:48:43-- https://paddlenlp.bj.bcebos.com/models/text_matching/ernie_gram_zh_pointwise_matching_model.tar
Resolving paddlenlp.bj.bcebos.com (paddlenlp.bj.bcebos.com)... 182.61.200.195, 182.61.200.229, 2409:8c04:1001:1002:0:ff:b001:368a
Connecting to paddlenlp.bj.bcebos.com (paddlenlp.bj.bcebos.com)|182.61.200.195|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 399636480 (381M) [application/x-tar]
Saving to: ‘ernie_gram_zh_pointwise_matching_model.tar’
ernie_gram_zh_point 100%[===================>] 381.12M 39.7MB/s in 14s
2023-06-05 16:48:57 (27.3 MB/s) - ‘ernie_gram_zh_pointwise_matching_model.tar’ saved [399636480/399636480]
model_20000/
model_20000/vocab.txt
model_20000/tokenizer_config.json
model_20000/model_state.pdparams
# 測驗資料由 2 列文本構成 tab 分隔
# Lcqmc 默認下載到如下路徑
! head -n3 "${HOME}/.paddlenlp/datasets/LCQMC/lcqmc/lcqmc/test.tsv"
誰有狂三這張高清的 這張高清圖,誰有
英雄聯盟什么英雄最好 英雄聯盟最好英雄是什么
這是什么意思,被蹭網嗎 我也是醉了,這是什么意思
定義預測函式
def predict(model, data_loader):
batch_probs = []
# 預測階段打開 eval 模式,模型中的 dropout 等操作會關掉
model.eval()
with paddle.no_grad():
for batch_data in data_loader:
input_ids, token_type_ids = batch_data
input_ids = paddle.to_tensor(input_ids)
token_type_ids = paddle.to_tensor(token_type_ids)
# 獲取每個樣本的預測概率: [batch_size, 2] 的矩陣
batch_prob = model(
input_ids=input_ids, token_type_ids=token_type_ids).numpy()
batch_probs.append(batch_prob)
batch_probs = np.concatenate(batch_probs, axis=0)
return batch_probs
定義預測資料的 data_loader
# 預測資料的轉換函式
# predict 資料沒有 label, 因此 convert_exmaple 的 is_test 引數設為 True
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=512,
is_test=True)
# 預測資料的組 batch 操作
# predict 資料只回傳 input_ids 和 token_type_ids,因此只需要 2 個 Pad 物件作為 batchify_fn
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment_ids
): [data for data in fn(samples)]
# 加載預測資料
test_ds = load_dataset("lcqmc", splits=["test"])
batch_sampler = paddle.io.BatchSampler(test_ds, batch_size=32, shuffle=False)
# 生成預測資料 data_loader
predict_data_loader =paddle.io.DataLoader(
dataset=test_ds.map(trans_func),
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
return_list=True)
定義預測模型
pretrained_model = paddlenlp.transformers.ErnieGramModel.from_pretrained('ernie-gram-zh')
model = PointwiseMatching(pretrained_model)
[2023-06-05 16:52:00,876] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie-gram-zh/ernie_gram_zh.pdparams
加載已訓練好的模型引數
# 剛才下載的模型解壓之后存盤路徑為 ./ernie_gram_zh_pointwise_matching_model/model_state.pdparams
state_dict = paddle.load("./ernie_gram_zh_pointwise_matching_model/model_state.pdparams")
# 剛才下載的模型解壓之后存盤路徑為 ./pointwise_matching_model/ernie1.0_base_pointwise_matching.pdparams
# state_dict = paddle.load("pointwise_matching_model/ernie1.0_base_pointwise_matching.pdparams")
model.set_dict(state_dict)
開始預測
for idx, batch in enumerate(predict_data_loader):
if idx < 1:
print(batch)
[Tensor(shape=[32, 38], dtype=int64, place=Place(cpu), stop_gradient=True,
[[1 , 1022, 9 , ..., 0 , 0 , 0 ],
[1 , 514 , 904 , ..., 0 , 0 , 0 ],
[1 , 47 , 10 , ..., 0 , 0 , 0 ],
...,
[1 , 733 , 404 , ..., 0 , 0 , 0 ],
[1 , 134 , 170 , ..., 0 , 0 , 0 ],
[1 , 379 , 3122, ..., 0 , 0 , 0 ]]), Tensor(shape=[32, 38], dtype=int64, place=Place(cpu), stop_gradient=True,
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]])]
GPU 會快很多
# 執行預測函式
y_probs = predict(model, predict_data_loader)
# 根據預測概率獲取預測 label
y_preds = np.argmax(y_probs, axis=1)
運行時長: 13分鐘33秒504毫秒 結束時間: 2023-06-05 17:11:35
輸出預測結果
# 我們按照千言文本相似度競賽的提交格式將預測結果存盤在 lcqmc.tsv 中,用來后續提交
# 同時將預測結果輸出到終端,便于大家直觀感受模型預測效果
test_ds = load_dataset("lcqmc", splits=["test"])
with open("lcqmc.tsv", 'w', encoding="utf-8") as f:
f.write("index\tprediction\n")
for idx, y_pred in enumerate(y_preds):
f.write("{}\t{}\n".format(idx, y_pred))
text_pair = test_ds[idx]
text_pair["label"] = y_pred
print(text_pair)
{'query': '誰有狂三這張高清的', 'title': '這張高清圖,誰有', 'label': 1}
{'query': '英雄聯盟什么英雄最好', 'title': '英雄聯盟最好英雄是什么', 'label': 1}
{'query': '這是什么意思,被蹭網嗎', 'title': '我也是醉了,這是什么意思', 'label': 1}
{'query': '現在有什么影片片好看呢?', 'title': '現在有什么好看的影片片嗎?', 'label': 1}
{'query': '請問晶達電子廠現在的工資待遇怎么樣要求有哪些', 'title': '三星電子廠工資待遇怎么樣啊', 'label': 0}
{'query': '文章真的愛姚笛嗎', 'title': '姚笛真的被文章干了嗎', 'label': 0}
{'query': '送自己做的閨蜜什么生日禮物好', 'title': '送閨蜜什么生日禮物好', 'label': 1}
{'query': '近期上映的電影', 'title': '近期上映的電影有哪些', 'label': 1}
{'query': '求英雄聯盟大神帶?', 'title': '英雄聯盟,求大神帶~', 'label': 1}
{'query': '如加上什么部首', 'title': '給東加上部首是什么字?', 'label': 0}
{'query': '杭州哪里好玩', 'title': '杭州哪里好玩點', 'label': 1}
{'query': '這是什么烏龜值錢嗎', 'title': '這是什么烏龜!值錢嘛?', 'label': 1}
{'query': '心各有所屬是什么意思?', 'title': '心有所屬是什么意思?', 'label': 1}
{'query': '什么東西越熱爬得越高', 'title': '什么東西越熱爬得很高', 'label': 1}
{'query': '世界杯哪位球員進球最多', 'title': '世界杯單界進球最多是哪位球員', 'label': 1}
{'query': '韭菜多吃什么好處', 'title': '多吃韭菜有什么好處', 'label': 1}
{'query': '云賺錢怎么樣', 'title': '怎么才能賺錢', 'label': 0}
{'query': '何炅結婚了嘛', 'title': '何炅結婚了么', 'label': 1}
{'query': '長的清新是什么意思', 'title': '小清新的意思是什么', 'label': 0}
# 打包預測結果
!zip submit.zip lcqmc.tsv paws-x.tsv bq_corpus.tsv
原文:
https://aistudio.baidu.com/aistudio/projectdetail/6327315?forkThirdPart=1
https://aistudio.baidu.com/aistudio/course/introduce/24177?sharedLesson=1455659&sharedType=2&sharedUserId=2631487&ts=1685955540221
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/555197.html
標籤:其他
上一篇:萬物云原生下的服務進化
下一篇:返回列表