摘要:本文主要為大家講解基于模型的元學習中的Learning to Learn優化策略和Meta-Learner LSTM,
本文分享自華為云社區《深度學習應用篇-元學習[16]:基于模型的元學習-Learning to Learn優化策略、Meta-Learner LSTM》,作者:汀丶 ,
1.Learning to Learn
Learning to Learn by Gradient Descent by Gradient Descent
提出了一種全新的優化策略,
用 LSTM 替代傳統優化方法學習一個針對特定任務的優化器,
在機器學習中,通常把優化目標 f(θ) 表示成
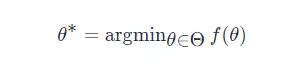
其中,引數 θ 的優化方式為
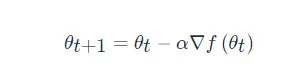
上式是一種針對特定問題類別的、人為設定的更新規則,
常見于深度學習中,主要解決高維、非凸優化問題,
根據 No Free Lunch Theorems for Optimization 理論,
[1] 提出了一種 基于學習的更新策略 代替 人為設定的更新策略,即,用一個可學習的梯度更新規則,替代人為設計的梯度更新規則,
其中,
optimizer 為 g 由 ? 引數化;
optimizee 為 ff 由 θθ 引數化,
此時, optimizee 的引數更新方式為
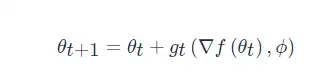
optimizer g 的更新則由 ff, ?f 及 ? 決定,
1.1 學習機制
圖1是 Learning to Learn 中 optimizer 和 optimizee 的作業原理,
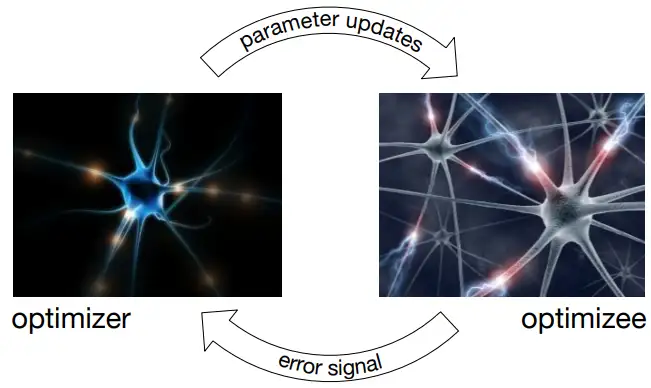
圖1 Learning to Learn 中 optimizer 和 optimizee 作業原理,
optimizer 為 optimizee 提供更新策略,
optimizee 將損失資訊反饋給 optimizer,協助 optimizer 更新,
給定目標函式 ff 的分布,那么經過 TT 次優化的 optimizer 的損失定義為整個優化程序損失的加權和:
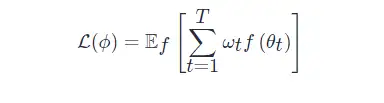
其中,
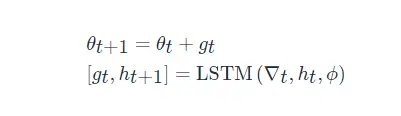
ωt?∈R≥0? 是各個優化時刻的任意權重,
?t?=?θ?f(θt?) ,
圖2是 Learning to Learn 計算圖,
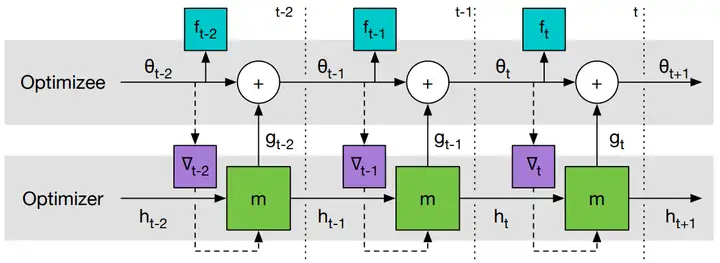
圖1 Learning to Learn 計算圖,
梯度只沿實線傳遞,不沿虛線傳遞(因為 optimizee 的梯度不依賴于 optimizer 的引數,即 ??t?/??=0 ),這樣可以避免計算 ff 的二階導,
[1] 中 optimizer 選用了 LSTM ,
從 LSTM 優化器的設計來看,
幾乎沒有加入任何先驗的人為經驗,
優化器本身的引數 ? 即 LSTM 的引數,
這個優化器的引數代表了更新策略,
1.2 Coordinatewise LSTM optimizer
LSTM 需要優化的引數相對較多,
因此,[1] 設計了一個優化器 mm,它可以對目標函式的每個引數分量進行操作,
具體而言,每次只對 optimizee 的一個引數分量 θi? 進行優化,
這樣只需要維持一個很小的 optimizer 就可以完成作業,
對于每個引數分量 θi? ,
optimizer 的引數 ? 共享,隱層狀態 hihi? 不共享,
由于每個維度上的 optimizer 輸入的 hi? 和 ?f(θi?) 是不同的,
所以即使它們的 ? 相同,它們的輸出也不一樣,
這樣設計的 LSTM 變相實作了優化與維度無關,
這與 RMSprop 和 ADAM 的優化方式類似(為每個維度的引數施行同樣的梯度更新規則),
圖3是 LSTM 優化器的一步更新程序,
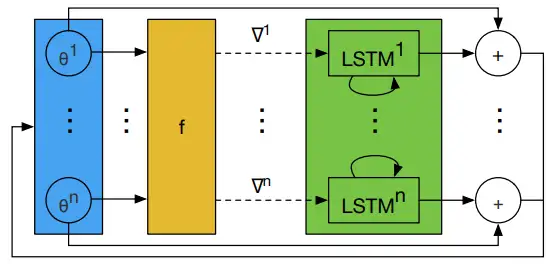
圖3 LSTM 優化器的一步更新程序,所有 LSTM 的 ? 共享,hi? 不共享,
1.3 預處理和后處理
由于 optimizer 的輸入是梯度,梯度的幅值變化相對較大,而神經網路一般只對小范圍的輸入輸出魯棒,因此在實踐中需要對 LSTM 的輸入輸出進行處理,
[1] 采用如下的方式:
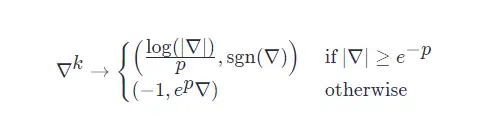
其中, p>0 為任意一個引數([1] 取 p=10),用來裁剪梯度,
如果第一個引數的取值大于 ?1?1 ,
那么它就代表梯度的 log ,第二個引數則是它的符號,
如果第一個引數的取值等于 ?1?1 ,
那么它將作為一個標記指引神經網路尋找第二個引數,此時第二個引數就是對梯度的縮放,
- 參考文獻
[1] Learning to Learn by Gradient Descent by Gradient Descent
2. Meta-Learner LSTM
元學習在處理 few-shot 問題時的學習機制如下:
- 基學習器在元學習器的引導下處理特定任務,發現任務特性;
- 元學習器總結所有任務共性,
基于小樣本的梯度下降存在以下問題:
- 小樣本意味著梯度下降的次數有限,在非凸的情況下,得到的模型必然性能很差;
- 對于每個單獨的資料集,神經網路每次都是隨機初始化,若干次迭代后也很難收斂到最佳性能,
因此,元學習可以為基于小樣本的梯度下降提供一種提高模型泛化性能的策略,
Meta-Learner LSTM 使用單元狀態表示 Learner 引數的更新,
訓練 Meta-Learner 既能發現一個良好的 Learner 初始化引數,
又能將 Learner 的引數更新到一個給定的小訓練集,以完成一些新任務,
2.1 Meta-Learner LSTM
2.1.1 梯度下降更新規則和 LSTM 單元狀態更新規則的等價性
一般的梯度下降更新規則
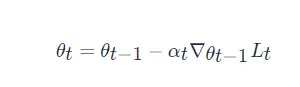
其中,θt? 是第 t 次迭代更新時的引數值,αt? 是第 t 次迭代更新時的學習率,?θt?1??Lt? 是損失函式在 θt?1? 處的梯度值,
LSTM 單元狀態更新規則
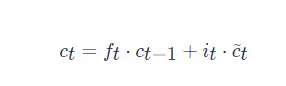
其中,ct? 是 t 時刻的細胞狀態,]ft?∈[0,1] 是遺忘門,it?∈[0,1] 是輸入門,
當 ft?=1, ct?1?=θt?1?, it?=αt?, c~t?=??θt?1??Lt? 時,Eq. (1)=Eq. (2)Eq. (1)=Eq. (2),
經過這樣的替換,利用 LSTM 的狀態更新替換學習器引數 θ,
2.1.2 Meta-Learner LSTM 設計思路
Meta-Learner 的目標是學習 LSTM 的更新規則,并將其應用于更新 Learner 的引數上,
(1) 輸入門
\begin{align} i_{t}=\sigma\left({W}_{I} \cdot\left[\nabla_{\theta_{t-1}} L_{t}, L_{t}, {\theta}_{t-1}, i_{t-1}\right]+{b}_{I}\right) \end{align}
其中,W 是權重矩陣;b 是偏差向量;σ 是 Sigmoid 函式;Eq. (1)=Eq. (2)Eq. (1)=Eq. (2)和 Lt? 由 Learner 輸入 Meta-Learner,
對于輸入門引數 it? ,它的作用相當于學習率 α ,
在此學習率是一個關于?θt?1??Lt? , Lt? ,θt?1? ,it?1? 的函式,
(2) 遺忘門
\begin{align} f_{t}=\sigma\left(W_{F} \cdot\left[\nabla_{\theta_{t-1}} L_{t}, L_{t}, \theta_{t-1}, f_{t-1}\right]+b_{F}\right) \end{align}
對于遺忘門引數 ft? ,它代表著 θt?1? 所占的權重,這里將其固定為 1 ,但 1 不一定是它的最優值,
(3) 將學習單元初始狀態 c0? 視為 Meta-Learner 的一個引數,
正對應于 learner 的引數初始值,
這樣當來一個新任務時, Meta-Learner 能給出一個較好的初始化值,從而進行快速學習,
(4) 引數共享
為了避免 Meta-Learner 發生引數爆炸,在 Learner 梯度的每一個 coordinate 上進行引數共享,
每一個 coordinate 都有自己的單元狀態,但是所有 coordinate 在 LSTM 上的引數都是一樣的,
每一個 coordinate 就相當于 Learner 中的每一層,
即對于相同一層的引數 θi? ,
它們的更新規則是一樣的,即WI? ,bI? ,WI? ,bI? 是相同的,
2.2 Meta-Learner LSTM 單元狀態更新程序
將 LSTM 單元狀態更新程序作為隨機梯度下降法的近似,實作 Meta-Learner 對 Leraner 引數更新的指導,
(1) 候選單元狀態: c~t?=??θt?1??Lt?,是 Meta-Learner 從 Leraner 得到的損失函式梯度值,直接輸入 Meta-Learner ,作為 t 時刻的候選單元狀態,
(2) 上一時刻的單元狀態:ct?1?=θt?1?,是 Learner 用第 t?1 個批次訓練資料更新后的引數,每個批次的資料訓練完后,Leraner 將損失函式值和損失函式梯度值輸入 Meta-Learner,Meta-Learner 更新一次引數,將更新后的引數回饋給 Leraner,Leraner 繼續處理下一個批次的訓練資料,
(3) 更新的單元狀態:ct?=θt?,是 Learner 用第 t 個批次訓練資料更新后的引數,
(4) 輸出門:不考慮,
(5) 初始單元狀態:c0?=θ,是 Learner 最早的引數初始值,LSTM 模型需要找到最好的初始細胞狀態,使得每輪更新后的引數初始值更好地反映任務的共性,在 Learner 上只需要少量更新,就可以達到不錯的精度,
2.3 Meta-Learner LSTM 演算法流程
Meta-Learner LSTM 前向傳遞計算如圖1所示,其中,
基學習器 MM,包含可訓練引數 θ;元學習器 RR,包含可訓練引數 ΘΘ,
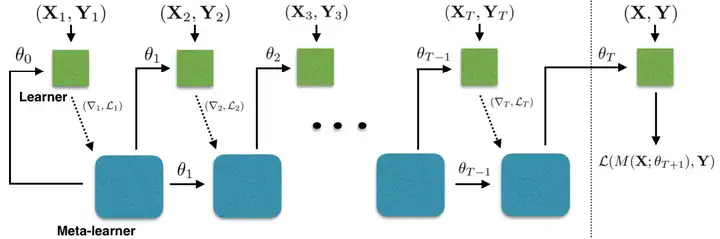
圖1 Meta-Learner LSTM 前向傳遞計算圖, Learner 計算損失函式值和損失函式梯度值, Meta-Learner 使用 Learner 提供的資訊,更新 Learner 中的引數和自身引數, 在任務中,每個批次的訓練資料處理完成后,Meta-Learner 為 Learner 更新一次引數, 任務中所有批次的訓練資料處理完成后,Meta-Learner 進行一次更新,
Meta-Learner LSTM 演算法流程
- Θ0Θ0? ←← random initialization
- for d=1,...,nd=1,...,n do:
- DtrainDtrain?, DtestDtest? ←← random dataset from Dmeta?trainDmeta?train?
- intialize learner parameters: θ0←c0θ0?←c0?
- for t=1,...,Tt=1,...,T do:
- XtXt?, YtYt? ←← random batch from DtrainDtrain?
- get loss of learner on train batch: Lt←L(M(Xt;θt?1),Yt)Lt?←L(M(Xt?;θt?1?),Yt?)
- get output of meta-learner using Eq. (2): ct←R((?θt?1Lt,Lt);Θd?1)ct?←R((?θt?1??Lt?,Lt?);Θd?1?)
- update learner parameters: θt←ctθt?←ct?
- end for
- X,Y←DtestX,Y←Dtest?
- get loss of learner on test batch: Ltest←L(M(X;θT),Y)Ltest?←L(M(X;θT?),Y)
- update ΘdΘd? using ?Θd?1Ltest?Θd?1??Ltest?
- end for
- 對于第 dd 個任務,在訓練集中隨機抽取 TT 個批次的資料,記為 (X1,Y1),??,(XT,YT)(X1?,Y1?),?,(XT?,YT?),
- 對于第 tt 個批次的資料 (Xt,Yt)(Xt?,Yt?),計算 learner 的損失函式值 Lt=L[M(Xt;θt?1),Yt]Lt?=L[M(Xt?;θt?1?),Yt?] 和損失函式梯度值 ?θt?1Lt?θt?1??Lt?,將損失函式和損失函式梯度輸入 meta-learner ,更新細胞狀態:ct=R[(?θt?1Lt,Lt);Θd?1]ct?=R[(?θt?1??Lt?,Lt?);Θd?1?],更新的引數值等于更新的細胞狀態 θt=ctθt?=ct?,
- 處理完第 dd 個任務中所有 TT 個批次的訓練資料后,使用第 dd 個任務的驗證集 (X,Y)(X,Y), 計算驗證集上的損失函式值 Ltest=L[M(X;θT),Y]Ltest?=L[M(X;θT?),Y] 和損失函式梯度值 ?θd?1Ltest?θd?1??Ltest? ,更新 meta-learner 引數 ΘdΘd? ,
2.4 Meta-Learner LSTM 模型結構
Meta-Learner LSTM 是一個兩層的 LSTM 網路,第一層是正常的 LSTM 模型,第二層是近似隨機梯度的 LSTM 模型,
所有的損失函式值和損失函式梯度值經過預處理,輸入第一層 LSTM 中,
計算學習率和遺忘門等引數,損失函式梯度值還要輸入第二層 LSTM 中用于引數更新,
2.5 Meta-Learner LSTM 和 MAML 的區別
- 在 MAML 中,元學習器給基學習器提供引數初始值,基學習器給元學習器提供損失函式值;
在 Meta-Learner LSTM 中,元學習器給基學習器提供更新的引數,基學習器給元學習器提供每個批次資料上的損失函式值和損失函式梯度值, - 在 MAML 中,基學習器的引數更新在基學習器中進行,元學習器的引數更新在元學習器中進行;
在 Meta-Learner LSTM 中,基學習器和元學習器的引數更新都在元學習器中進行, - 在 MAML 中,元學習器使用 SGD 更新引數初始值,使得損失函式中存在高階導數;
在 Meta-Learner LSTM 中,元學習器給基學習器提供修改的 LSTM 更新引數,元學習器自身的引數并不是基學習器中的引數初始值,元學習器自身的引數使用 SGD 進行更新,并不會出現損失函式高階導數的計算, - 在 MAML 中,元學習器和基學習器只在每個任務訓練完成后才進行資訊交流;
在 Meta-Learner LSTM 中,元學習器和基學習器在每個任務的每個批次訓練資料完成后就進行資訊交流, - MAML 適用于任意模型結構;
Meta-Learner LSTM 中的元學習器只能是 LSTM 結構,基學習器可以適用于任意模型結構,
2.6 Meta-Learner LSTM 分類結果
表1 Meta-Learner LSTM 在 miniImageNet 上的分類結果,
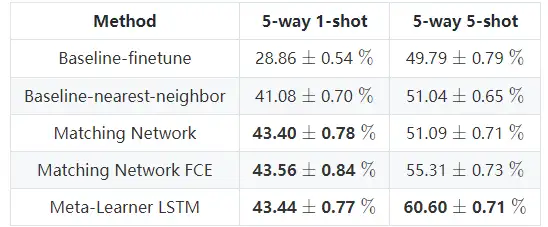
- 參考文獻
[1] Optimization as a Model for Few-Shot Learning
[2] 長短時記憶網路 LSTM
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/555376.html
標籤:其他
上一篇:[Week 21] 每日一題(C++,數學,二分,字串,STL)
下一篇:返回列表