問題起因
近段時間,在作業中,遇到了一個問題:有一套K8S集群在做可靠性驗證,在重啟上下電之后,發現這個節點上的Pod狀態例外,通過kubectl describe查看Pod情況,都是掛卷出錯,而kubelet日志中也報了某個CSI插件沒有找到,但問題是CSI插件對應的Pod是正常Running狀態,那么為什么CSI會找不到呢?于是帶著這個問題,研究起了k8s的代碼,
代碼分析
CSI沒有找到,那意味著肯定是有地方儲存CSI的資料,相應的有地方去創建/更新CSI的資料,這個咨詢CSI業務的開發了解到,CSI注冊后會更新csiNode資源,同時node資源上也會有csi的拓撲資訊,
另外根據kubelet的日志報錯資訊:Error calling CSI NodeGetInfo()找到了CSI注冊流程的代碼,
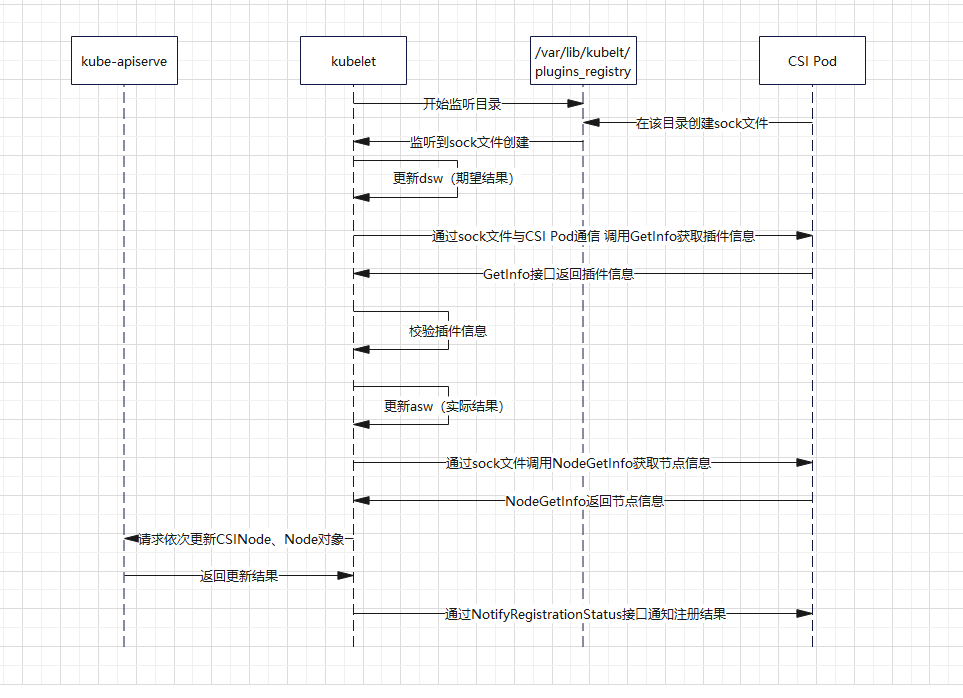
CSI注冊流程的代碼入口在pkg/kubelet/pluginmanager/plugin_manager.go:108 (v1.25.3版本)
首先是Run方法,這里主要處理了兩件事
- 開啟了kubelet對
/var/lib/kubelet/plugins_registry目錄的監聽,如果有檔案更新,會同步更新dsw的快取 - 開啟了reconciler主回圈,對比asw和dsw的差異,然后去觸發CSI的卸載和注冊
reconciler主回圈
- 卸載:遍歷asw快取中的插件資訊,和dsw做比對,如果出現dsw沒有的插件或者資訊不一致的插件,則會將該插件卸載
- 注冊:遍歷dsw快取中的插件資訊,如果asw沒有,則會觸發注冊流程,通過proto檔案定義雙方的介面,kubelet作為客戶端呼叫CSI Pod服務端實作的介面GetInfo、NodeGetInfo獲取插件資訊,然后向apiserver注冊CSINode、Node資訊,并在最后通過NotifyRegistrationStatus通知CSI Pod,
根據個人對代碼的理解,繪制了下面的流程圖,
問題分析
由于kubelet日志中出現了Error calling CSI NodeGetInfo()的報錯日志,那么說明CSI Pod實作的NodeGetInfo方法出現了錯誤,通過CSI開發分析,是由于需要發請求,而節點剛重啟,受網路配置的影響,請求超時了,導致方法報錯,
那么又出了一個問題,為什么沒有恢復呢?
原因在于在kubelet呼叫NodeGetInfo方法時,已經將asw快取更新了,此時dsw和asw快取一致,kubelet不會再觸發卸載、注冊流程,
這不合理呀,這里沒有真正注冊成功啊,
再次走讀代碼,終于識別到了一個點:kubelet是有通知事件發給CSI Pod的,在校驗CSI資訊和注冊程序中,如果出現例外,kubelet會發一個注冊失敗的通知給CSI Pod,而在官方的CSI范例中,CSI是會清理自己在/var/lib/kubelet/plugins_registry目錄創建的檔案,并退出,因為CSI是一個Daemonset型別部署的Pod,那么在主行程退出之后,K8S會再次部署這個Pod,那么CSI Pod會再次進入CSI注冊的主流程,而那個時候,網路就緒了,CSI注冊也就會成功,
根據這個資訊,向CSI開發確認,他們忽略了通知注冊失敗的處理,導致注冊失敗后沒有自動恢復,
OK,問題定位清楚了,也趁著這個機會學習了CSI的注冊流程,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/555469.html
標籤:其他
下一篇:返回列表