檔案檢索:需要把業務問題拆解成子任務,文本分類 -> 文本匹配 -> 等任務 -> Panddle API 完成子任務 -> 子任務再拼起來
介紹
在2017年之前,工業界和學術界對文本處理依賴于序列模型Recurrent Neural Network (RNN).
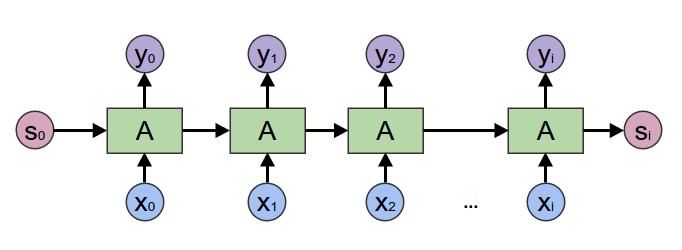
基于BiGRU+CRF的快遞單資訊抽取專案介紹了如何使用序列模型完成快遞單資訊抽取任務,
近年來隨著深度學習的發展,模型引數的數量飛速增長,為了訓練這些引數,需要更大的資料集來避免過擬合,然而,對于大部分NLP任務來說,構建大規模的標注資料集非常困難(成本過高),特別是對于句法和語意相關的任務,相比之下,大規模的未標注語料庫的構建則相對容易,為了利用這些資料,我們可以先從其中學習到一個好的表示,再將這些表示應用到其他任務中,最近的研究表明,基于大規模未標注語料庫的預訓練模型(Pretrained Models, PTM) 在NLP任務上取得了很好的表現,
近年來,大量的研究表明基于大型語料庫的預訓練模型(Pretrained Models, PTM)可以學習通用的語言表示,有利于下游NLP任務,同時能夠避免從零開始訓練模型,隨著計算能力的不斷提高,深度模型的出現(即 Transformer)和訓練技巧的增強使得 PTM 不斷發展,由淺變深,
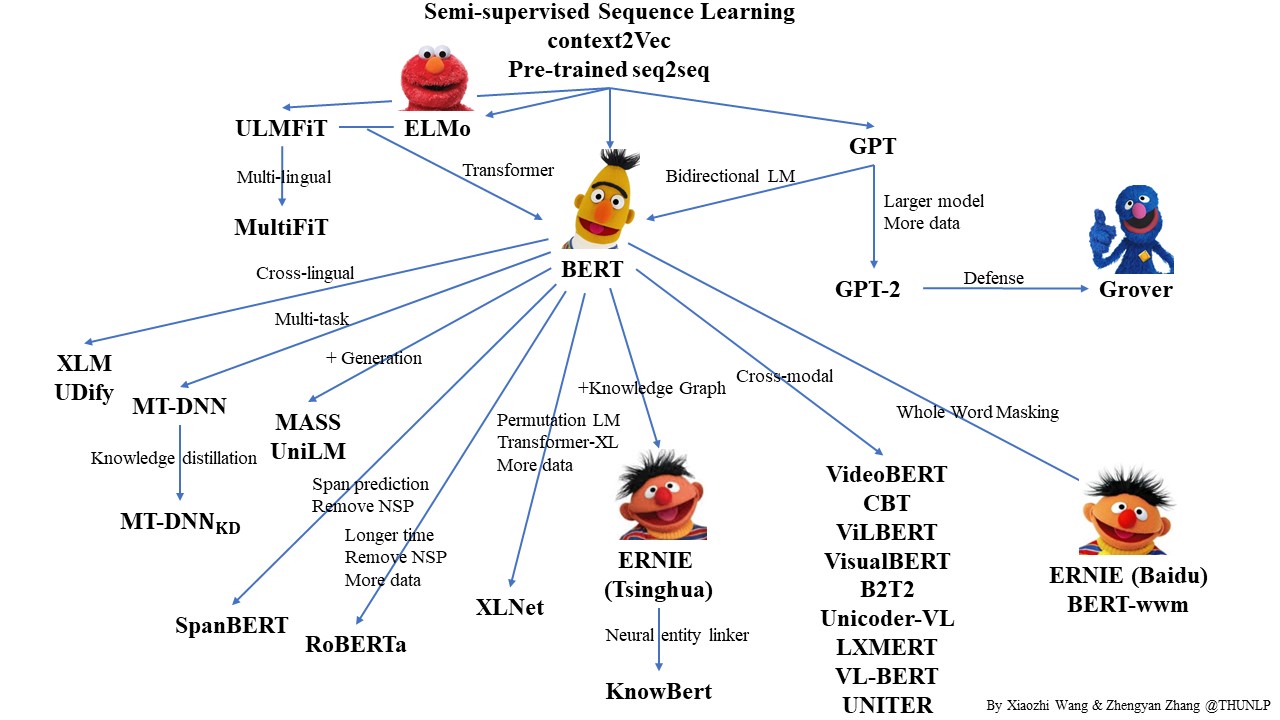
本示例展示了以ERNIE(Enhanced Representation through Knowledge Integration)為代表的預訓練模型如何Finetune完成序列標注任務,
物體定義標注
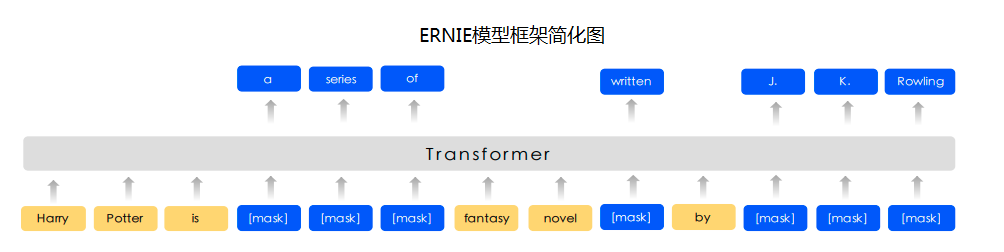
命名物體識別是NLP中一項非常基礎的任務,是資訊提取、問答系統、句法分析、機器翻譯等眾多NLP任務的重要基礎工具,命名物體識別的準確度,決定了下游任務的效果,是NLP中的一個基礎問題,在NER任務提供了兩種解決方案,一類LSTM/GRU + CRF,通過RNN類的模型來抽取底層文本的資訊,而CRF(條件隨機場)模型來學習底層Token之間的聯系;另外一類是通過預訓練模型,例如ERNIE,BERT模型,直接來預測Token的標簽資訊,
本專案將演示如何使用PaddleNLP語意預訓練模型ERNIE完成從快遞單中抽取姓名、電話、省、市、區、詳細地址等內容,形成結構化資訊,輔助物流行業從業者進行有效資訊的提取,從而降低客戶填單的成本,
典型的命名物體識別(Named Entity Recognition,NER)場景,各物體型別及相應符號表示見下表:
張三18625584663廣東省深圳市南山區百度國際大廈
人工定義物體,標注符號
| 抽取物體/欄位 | 符號 | 抽取結果 |
|---|---|---|
| 姓名 | P | 張三 |
| 電話 | N | 13812345678 |
| 省 | A1 | 廣東省 |
| 市 | A2 | 深圳市 |
| 區 | A3 | 南山區 |
| 詳細地址 | A4 | 百度國際大廈 |
在序列標注任務中,一般會定義一個標簽集合,來表示所以可能取到的預測結果,上文中針對需要抽取的“姓名、電話、省、市、區、詳細地址”等物體,標簽集合可以定義為:
label={P-B,P-I,T-B,T-I,A1-B,A1-I,A2-B,A2-I,A3-B,A3-I,A4-B,A4-I,0)
| 標簽 | 定義 |
|---|---|
| P-B | 姓名起始位置 |
| P-I | 姓名中間位置或結束位置 |
| T-B | 電話起始位置 |
| T-I | 電話中間位置或結束位置 |
| A1-B | 省份起始位置 |
| A1-I | 省份中間位置或結束位置 |
| A2-B | 城市起始位置 |
| A2-I | 城市中間位置或結束位置 |
| A3-B | 縣區起始位置 |
| A3-I | 縣區中間位置或結束位置 |
| A4-B | 詳細地址起始位置 |
| A4-I | 詳細地址中間位置或結束位置 |
| O | 無關字符 |
注意每個標簽的結果只有 B、I、O 三種,這種標簽的定義方式叫做 BIO 體系,BIO(B-begin,I-inside,O-other) 標簽轉換,
B:表示一個標簽類別的開頭,比如 P-B 指的是姓名的開頭
I:中間或結束,表示一個標簽的延續
O:不想抽取的,無用的物體
對于句子“張三18625584663廣東省深圳市南山區百度國際大廈”,每個漢字及對應標簽為:

注意到“張“,”三”在這里表示成了“P-B” 和 “P-I”,“P-B”和“P-I”合并成“P” 這個標簽,這樣重新組合后可以得到以下資訊抽取結果:
| 張三 | 18625584663 | 廣東省 | 深圳市 | 南山區 | 百度國際大廈 |
|---|---|---|---|---|---|
| P | T | A1 | A2 | A3 | A4 |
準備
# 下載并解壓資料集
from paddle.utils.download import get_path_from_url
URL = "https://paddlenlp.bj.bcebos.com/paddlenlp/datasets/waybill.tar.gz"
get_path_from_url(URL, "./")
# 查看預測的資料
!head -n 5 data/test.txt
text_a label
黑龍江省雙鴨山市尖山區八馬路與東平行路交叉口北40米韋業濤18600009172 A1-BA1-IA1-IA1-IA2-BA2-IA2-IA2-IA3-BA3-IA3-IA4-BA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IP-BP-IP-IT-BT-IT-IT-IT-IT-IT-IT-IT-IT-IT-I
廣西壯族自治區桂林市雁山區雁山鎮西龍村老年活動中心17610348888羊卓衛 A1-BA1-IA1-IA1-IA1-IA1-IA1-IA2-BA2-IA2-IA3-BA3-IA3-IA4-BA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IT-BT-IT-IT-IT-IT-IT-IT-IT-IT-IT-IP-BP-IP-I
15652864561河南省開封市順河回族區順河區公園路32號趙本山 T-BT-IT-IT-IT-IT-IT-IT-IT-IT-IT-IA1-BA1-IA1-IA2-BA2-IA2-IA3-BA3-IA3-IA3-IA3-IA4-BA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IP-BP-IP-I
河北省唐山市玉田縣無終大街159號18614253058尚漢生 A1-BA1-IA1-IA2-BA2-IA2-IA3-BA3-IA3-IA4-BA4-IA4-IA4-IA4-IA4-IA4-IA4-IT-BT-IT-IT-IT-IT-IT-IT-IT-IT-IT-IP-BP-IP-I
from functools import partial
import paddle
from paddlenlp.datasets import MapDataset
from paddlenlp.data import Stack, Tuple, Pad
from paddlenlp.transformers import ErnieTokenizer, ErnieForTokenClassification
from paddlenlp.metrics import ChunkEvaluator # 詞與塊的指標 不是 A1-B 對了就算對,A1-B~A1I 全對了才算對
from utils import convert_example, evaluate, predict, load_dict
加載自定義資料集
推薦使用MapDataset()自定義資料集,
def load_dataset_1(datafiles):
def read(data_path):
with open(data_path, 'r', encoding='utf-8') as fp:
next(fp) # Skip header
for line in fp.readlines():
words, labels = line.strip('\n').split('\t')
words = words.split('\002')
labels = labels.split('\002')
yield words, labels
if isinstance(datafiles, str):
return MapDataset(list(read(datafiles)))
elif isinstance(datafiles, list) or isinstance(datafiles, tuple):
return [MapDataset(list(read(datafile))) for datafile in datafiles]
# Create dataset, tokenizer and dataloader.
train_ds, dev_ds, test_ds = load_dataset_1(datafiles=(
'./data/train.txt', './data/dev.txt', './data/test.txt'))
for i in range(5):
print(train_ds[i])
(['1', '6', '6', '2', '0', '2', '0', '0', '0', '7', '7', '宣', '榮', '嗣', '甘', '肅', '省', '白', '銀', '市', '會', '寧', '縣', '河', '畔', '鎮', '十', '字', '街', '金', '海', '超', '市', '西', '行', '5', '0', '米'], ['T-B', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'P-B', 'P-I', 'P-I', 'A1-B', 'A1-I', 'A1-I', 'A2-B', 'A2-I', 'A2-I', 'A3-B', 'A3-I', 'A3-I', 'A4-B', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I'])
(['1', '3', '5', '5', '2', '6', '6', ...
每條資料包含一句文本和這個文本中每個漢字以及數字對應的label標簽,
之后,還需要對輸入句子進行資料處理,如切詞,映射詞表id等,
資料處理
預訓練模型ERNIE對中文資料的處理是以字為單位,PaddleNLP對于各種預訓練模型已經內置了相應的tokenizer,指定想要使用的模型名字即可加載對應的tokenizer,
tokenizer作用為將原始輸入文本轉化成模型model可以接受的輸入資料形式,
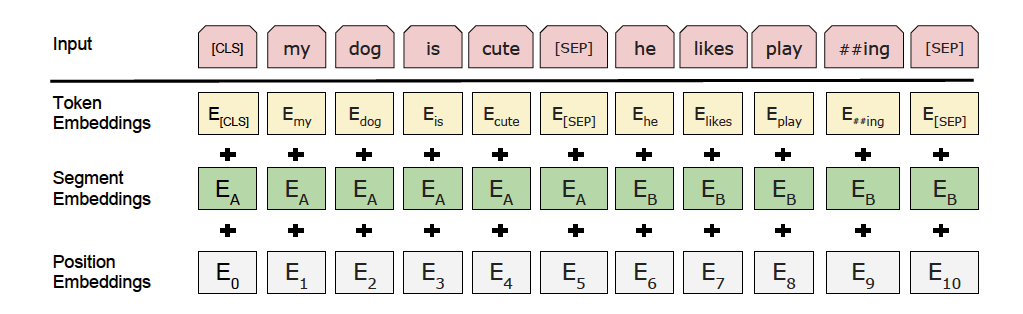
utils.py 工具類
import numpy as np
import paddle
import paddle.nn.functional as F
from paddlenlp.data import Stack, Tuple, Pad
def load_dict(dict_path):
vocab = {}
i = 0
for line in open(dict_path, 'r', encoding='utf-8'):
key = line.strip('\n')
vocab[key] = i
i+=1
return vocab
def convert_example(example, tokenizer, label_vocab):
tokens, labels = example
tokenized_input = tokenizer(
tokens, return_length=True, is_split_into_words=True)
# Token '[CLS]' and '[SEP]' will get label 'O'
labels = ['O'] + labels + ['O']
tokenized_input['labels'] = [label_vocab[x] for x in labels]
return tokenized_input['input_ids'], tokenized_input[
'token_type_ids'], tokenized_input['seq_len'], tokenized_input['labels']
@paddle.no_grad()
def evaluate(model, metric, data_loader):
model.eval()
metric.reset()
for input_ids, seg_ids, lens, labels in data_loader:
logits = model(input_ids, seg_ids)
preds = paddle.argmax(logits, axis=-1)
n_infer, n_label, n_correct = metric.compute(None, lens, preds, labels)
metric.update(n_infer.numpy(), n_label.numpy(), n_correct.numpy())
precision, recall, f1_score = metric.accumulate()
print("eval precision: %f - recall: %f - f1: %f" %
(precision, recall, f1_score))
model.train()
def predict(model, data_loader, ds, label_vocab):
pred_list = []
len_list = []
for input_ids, seg_ids, lens, labels in data_loader:
logits = model(input_ids, seg_ids)
pred = paddle.argmax(logits, axis=-1)
pred_list.append(pred.numpy())
len_list.append(lens.numpy())
preds = parse_decodes(ds, pred_list, len_list, label_vocab)
return preds
def parse_decodes(ds, decodes, lens, label_vocab):
decodes = [x for batch in decodes for x in batch]
lens = [x for batch in lens for x in batch]
id_label = dict(zip(label_vocab.values(), label_vocab.keys()))
outputs = []
for idx, end in enumerate(lens):
sent = ds.data[idx][0][:end]
tags = [id_label[x] for x in decodes[idx][1:end]]
sent_out = []
tags_out = []
words = ""
for s, t in zip(sent, tags):
if t.endswith('-B') or t == 'O':
if len(words):
sent_out.append(words)
tags_out.append(t.split('-')[0])
words = s
else:
words += s
if len(sent_out) < len(tags_out):
sent_out.append(words)
outputs.append(''.join(
[str((s, t)) for s, t in zip(sent_out, tags_out)]))
return outputs
def predict(model, data_loader, ds, label_vocab):
pred_list = []
len_list = []
for input_ids, seg_ids, lens, labels in data_loader:
logits = model(input_ids, seg_ids)
pred = paddle.argmax(logits, axis=-1)
pred_list.append(pred.numpy())
len_list.append(lens.numpy())
preds = parse_decodes(ds, pred_list, len_list, label_vocab)
return preds
label_vocab = load_dict('./data/tag.dic')
tokenizer = ErnieTokenizer.from_pretrained('ernie-1.0') # 現在3.0 了
# convert_example => utils.py,先把Id讀出來,加了 CLS
# label_vocab => 13個分類 cat tag.dic
# tokenizer => ERNIE 字典里面對應的位置
trans_func = partial(convert_example, tokenizer=tokenizer, label_vocab=label_vocab)
train_ds.map(trans_func)
dev_ds.map(trans_func)
test_ds.map(trans_func)
print (train_ds[0])
資料讀入
使用paddle.io.DataLoader介面多執行緒異步加載資料,
ignore_label = -1 # 在交叉熵計算時,PAD 位,就不會參與計算,目的:為了減少計算量
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack(), # seq_len
Pad(axis=0, pad_val=ignore_label) # labels
): fn(samples)
train_loader = paddle.io.DataLoader(
dataset=train_ds,
batch_size=36, # 看性能監控,空閑多的話可以調大
return_list=True,
collate_fn=batchify_fn)
dev_loader = paddle.io.DataLoader(
dataset=dev_ds,
batch_size=36,
return_list=True,
collate_fn=batchify_fn)
test_loader = paddle.io.DataLoader(
dataset=test_ds,
batch_size=36,
return_list=True,
collate_fn=batchify_fn)
PaddleNLP一鍵加載預訓練模型
快遞單資訊抽取本質是一個序列標注任務,PaddleNLP對于各種預訓練模型已經內置了對于下游任務文本分類Fine-tune網路,以下教程以ERNIE為預訓練模型完成序列標注任務,
paddlenlp.transformers.ErnieForTokenClassification()一行代碼即可加載預訓練模型ERNIE用于序列標注任務的fine-tune網路,其在ERNIE模型后拼接上一個全連接網路進行分類,
paddlenlp.transformers.ErnieForTokenClassification.from_pretrained()方法只需指定想要使用的模型名稱和文本分類的類別數即可完成定義模型網路,
# Define the model netword and its loss
model = ErnieForTokenClassification.from_pretrained("ernie-1.0", num_classes=len(label_vocab))
PaddleNLP不僅支持ERNIE預訓練模型,還支持BERT、RoBERTa、Electra等預訓練模型,
下表匯總了目前PaddleNLP支持的各類預訓練模型,您可以使用PaddleNLP提供的模型,完成文本分類、序列標注、問答等任務,同時我們提供了眾多預訓練模型的引數權重供用戶使用,其中包含了二十多種中文語言模型的預訓練權重,中文的預訓練模型有bert-base-chinese, bert-wwm-chinese, bert-wwm-ext-chinese, ernie-1.0, ernie-tiny, gpt2-base-cn, roberta-wwm-ext, roberta-wwm-ext-large, rbt3, rbtl3, chinese-electra-base, chinese-electra-small, chinese-xlnet-base, chinese-xlnet-mid, chinese-xlnet-large, unified_transformer-12L-cn, unified_transformer-12L-cn-luge等,
更多預訓練模型參考:PaddleNLP Transformer API,
更多預訓練模型fine-tune下游任務使用方法,請參考:examples,
設定Fine-Tune優化策略,模型配置
適用于ERNIE/BERT這類Transformer模型的遷移優化學習率策略為warmup的動態學習率,
先慢慢加速,再衰減
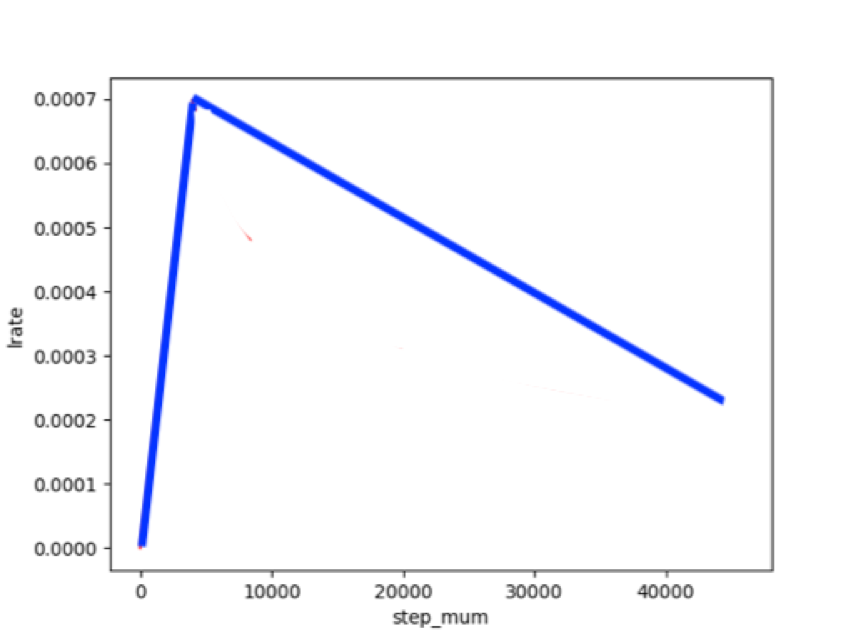
# 定義評測指標
metric = ChunkEvaluator(label_list=label_vocab.keys(), suffix=True)
loss_fn = paddle.nn.loss.CrossEntropyLoss(ignore_index=ignore_label) # 忽略標簽計算,如果都是PAD標簽參與計算,費力不討好 -1 不參與交叉熵計算
optimizer = paddle.optimizer.AdamW(learning_rate=2e-5, parameters=model.parameters())
模型訓練與評估
模型訓練的程序通常有以下步驟:
- 從dataloader中取出一個batch data
- 將batch data喂給model,做前向計算
- 將前向計算結果傳給損失函式,計算loss,將前向計算結果傳給評價方法,計算評價指標,
- loss反向回傳,更新梯度,重復以上步驟,
每訓練一個epoch時,程式將會評估一次,評估當前模型訓練的效果,
step = 0
for epoch in range(10):
for idx, (input_ids, token_type_ids, length, labels) in enumerate(train_loader):
logits = model(input_ids, token_type_ids)
loss = paddle.mean(loss_fn(logits, labels))
loss.backward()
optimizer.step()
optimizer.clear_grad()
step += 1
print("epoch:%d - step:%d - loss: %f" % (epoch, step, loss))
evaluate(model, metric, dev_loader)
paddle.save(model.state_dict(),
'./ernie_result/model_%d.pdparams' % step)
# model.save_pretrained('./checkpoint')
# tokenizer.save_pretrained('./checkpoint')
wc -l /data/train.txt # 1601 條訓練集
epoch:0 - step:1 - loss: 2.623411
epoch:0 - step:2 - loss: 2.393340
epoch:0 - step:3 - loss: 2.246286
epoch:0 - step:4 - loss: 2.080738
epoch:0 - step:5 - loss: 1.959701
epoch:0 - step:6 - loss: 1.842479
epoch:0 - step:7 - loss: 1.765124
epoch:0 - step:8 - loss: 1.621435
epoch:0 - step:9 - loss: 1.590034
epoch:0 - step:10 - loss: 1.503715
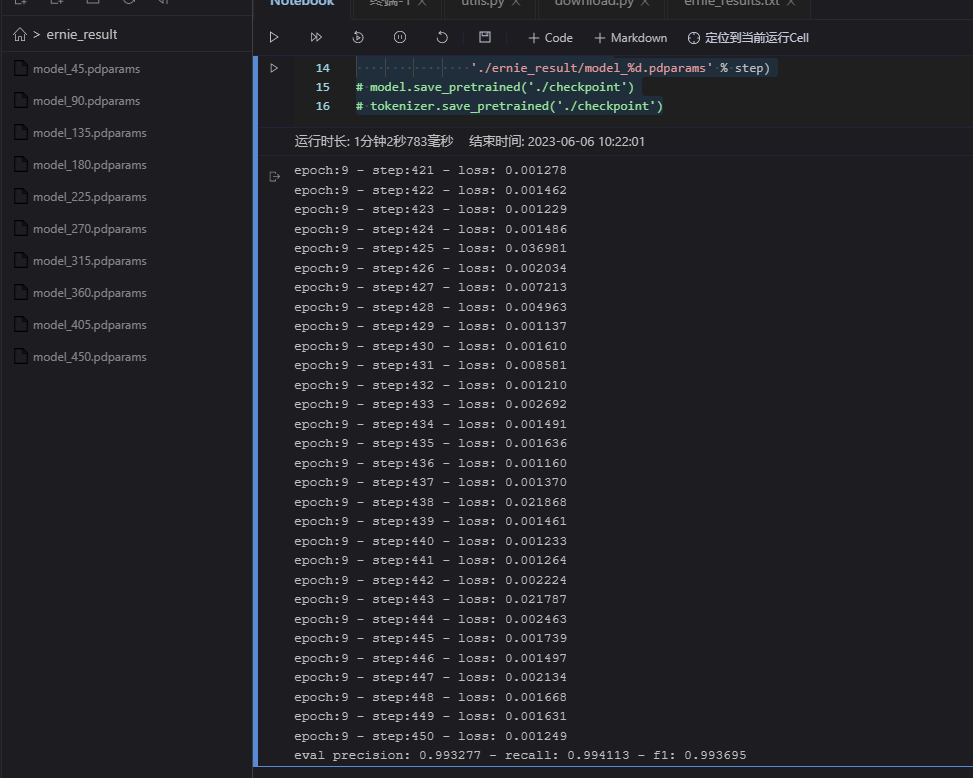
模型預測
訓練保存好的模型,即可用于預測,如以下示例代碼自定義預測資料,呼叫predict()函式即可一鍵預測,
preds = predict(model, test_loader, test_ds, label_vocab)
file_path = "ernie_results.txt"
with open(file_path, "w", encoding="utf8") as fout:
fout.write("\n".join(preds))
# Print some examples
print(
"The results have been saved in the file: %s, some examples are shown below: "
% file_path)
print("\n".join(preds[:10]))
想要更準一點,可以加上 PaddleNLP提供了CRF Layer
摘要生成:中文用 GPT-2、英文用 ERNIE-GEN 模型
原文:
視頻:https://aistudio.baidu.com/aistudio/course/introduce/24177?sharedLesson=1459080&sharedType=2&sharedUserId=2631487&ts=1686018319058
專案:https://aistudio.baidu.com/aistudio/projectdetail/6333693?forkThirdPart=1&sUid=2631487&shared=1&ts=1686018298519
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/555579.html
標籤:其他
上一篇:Liunx nginx服務
下一篇:返回列表