LoRA: Low-Rank Adaptation of Large Language Models
動機
大模型的引數量都在100B級別,由于算力的吃緊,在這個基礎上進行所有引數的微調變得不可能,LoRA正是在這個背景下提出的解決方案,
原理
雖然模型的引數眾多,但其實模型主要依賴低秩維度的內容(low intrinsic dimension),由此引出低秩自適應方法lora,通過低秩分解來模擬引數的改變數,從而以極小的引數量來實作大模型的間接訓練,

LoRA的思想也很簡單,在原始PLM旁邊增加一個旁路,做一個降維再升維的操作,來模擬所謂的 intrinsic rank ,
訓練的時候固定PLM的引數,只訓練降維矩陣A與升維矩陣B,而模型的輸入輸出維度不變,輸出時將BA與PLM的引數疊加,
用隨機高斯分布初始化A,用0矩陣初始化B,保證訓練的開始此旁路矩陣依然是0矩陣,

這種思想有點類似于殘差連接,同時使用這個旁路的更新來模擬full finetuning的程序,并且,full finetuning可以被看做是LoRA的特例(當r等于k時)
LoRA詳細程序
- 在原模型旁邊增加一個旁路,通過低秩分解(先降維再升維)來模擬引數的更新量;
- 訓練時,原模型固定,只訓練降維矩陣A和升維矩陣B;
- 推理時,可將BA加到原引數上,不引入額外的推理延遲;
- 初始化,A采用高斯分布初始化,B初始化為全0,保證訓練開始時旁路為0矩陣;
- 可插拔式的切換任務,當前任務W0+B1A1,將lora部分減掉,換成B2A2,即可實作任務切換;
- 秩的選取:對于一般的任務,rank=1,2,4,8足矣,而對于一些領域差距比較大的任務可能需要更大的rank,
總的來說,lora就是凍結預先訓練的模型權重,并將可訓練的秩分解矩陣注入Transformer架構的每一層,
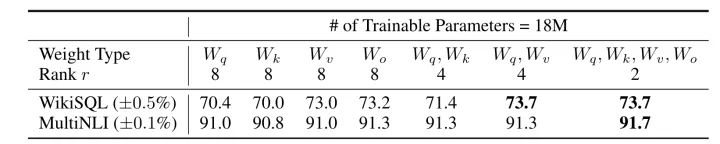
目前對于大多數實驗只在 Wq 和 Wv使用LoRA,可訓練引數的數量由秩r和原始權值的形狀決定,
代碼
原始碼:https://github.com/microsoft/LoRA
LoRALayer層
class LoRALayer():
def __init__(
self,
r: int,
lora_alpha: int,
lora_dropout: float,
merge_weights: bool,
):
self.r = r
self.lora_alpha = lora_alpha
# Optional dropout
if lora_dropout > 0.:
self.lora_dropout = nn.Dropout(p=lora_dropout)
else:
self.lora_dropout = lambda x: x
# Mark the weight as unmerged
self.merged = False
self.merge_weights = merge_weights
Linear層
class Linear(nn.Linear, LoRALayer):
# LoRA implemented in a dense layer
def __init__(
self,
in_features: int,
out_features: int,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.,
fan_in_fan_out: bool = False, # Set this to True if the layer to replace stores weight like (fan_in, fan_out)
merge_weights: bool = True,
**kwargs
):
nn.Linear.__init__(self, in_features, out_features, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout,
merge_weights=merge_weights)
self.fan_in_fan_out = fan_in_fan_out
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Parameter(self.weight.new_zeros((r, in_features)))
self.lora_B = nn.Parameter(self.weight.new_zeros((out_features, r)))
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
self.reset_parameters()
if fan_in_fan_out:
self.weight.data = self.weight.data.transpose(0, 1)
def reset_parameters(self):
nn.Linear.reset_parameters(self)
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def train(self, mode: bool = True):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
nn.Linear.train(self, mode)
if mode:
if self.merge_weights and self.merged:
# Make sure that the weights are not merged
if self.r > 0:
self.weight.data -= T(self.lora_B @ self.lora_A) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0:
self.weight.data += T(self.lora_B @ self.lora_A) * self.scaling
self.merged = True
def forward(self, x: torch.Tensor):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
if self.r > 0 and not self.merged:
result = F.linear(x, T(self.weight), bias=self.bias)
if self.r > 0:
result += (self.lora_dropout(x) @ self.lora_A.transpose(0, 1) @ self.lora_B.transpose(0, 1)) * self.scaling
return result
else:
return F.linear(x, T(self.weight), bias=self.bias)
Peft實作
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training, TaskType
# Define LoRA Config
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q", "v"],
lora_dropout=0.05,
bias="none",
task_type=TaskType.SEQ_2_SEQ_LM
)
# prepare int-8 model for training
model = prepare_model_for_int8_training(model)
# add LoRA adaptor
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# trainable params: 18874368 || all params: 11154206720 || trainable%: 0.16921300163961817
參考鏈接:
https://zhuanlan.zhihu.com/p/631077870
https://zhuanlan.zhihu.com/p/636759194
https://zhuanlan.zhihu.com/p/514033873
QLoRA:Efficient Finetuning of Quantized LLMs
動機
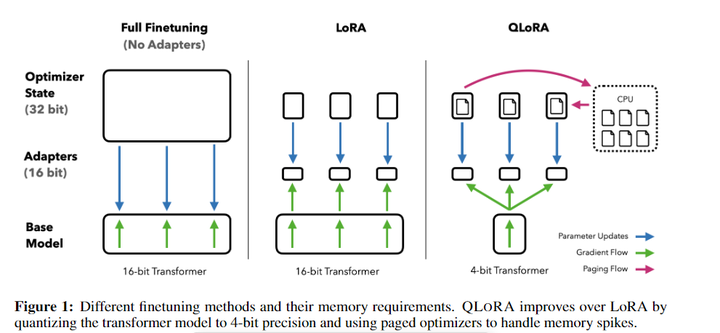
微調非常大的模型的成本過高;對650億引數的LLaMA模型進行進行16位微調需要超過780GB的GPU記憶體,QLORA使用一種新的高精度技術將預訓練模型量化為int4,然后添加一小組可學習的低秩配接器權重,它是通過量化權重反向傳播梯度來調整的,QLORA將65B引數模型進行微調的平均記憶體需求從 >780GB 的 GPU 記憶體減少到 <48GB,而不會降低運行時間或預測性能,這標志著LLM微調可訪問性的顯著轉變:現在最大的公開可用的模型,迄今為止在單個GPU上進行微調,
創新
首先分析下LoRA微調中的痛點:
-
引數空間小:LoRA中參與訓練的引數量較少,解空間較小,效果相比全量微調有一定的差距,
-
微調大模型成本高:對于上百億引數量的模型,LoRA微調的成本還是很高,
-
精度損失:針對第二點,可以采用int8或int4量化,進一步對模型基座的引數進行壓縮,但是又會引發精度損失的問題,降低模型性能,
今天的主角QLoRA優點:
-
4-bit NormalFloat:提出一種理論最優的4-bit的量化資料型別,優于當前普遍使用的FP4與Int4,對于正態分布權重而言,一種資訊理論上最優的新資料型別,該資料型別對正態分布資料產生比 4 bit整數和 4bit 浮點數更好的實證結果,QLORA包含一種低精度存盤資料型別(通常為4-bit)和一種計算資料型別(通常為BFloat16),在實踐中,QLORA權重張量使用時,需要將將張量去量化為BFloat16,然后在16位計算精度下進行矩陣乘法運算,模型本身用4bit加載,訓練時把數值反量化到bf16后進行訓練,
-
Double Quantization:對第一次量化后的那些常量再進行一次量化,減少存盤空間,相比于當前的模型量化方法,更加節省顯存空間,每個引數平均節省0.37bit,對于65B的LLaMA模型,大約能節省3GB顯存空間,
-
Paged Optimizers:使用NVIDIA統一記憶體特性,該特性可以在在GPU偶爾OOM的情況下,進行CPU和GPU之間自動分頁到分頁的傳輸,以實作無錯誤的 GPU 處理,該功能的作業方式類似于 CPU 記憶體和磁盤之間的常規記憶體分頁,使用此功能為優化器狀態(Optimizer)分配分頁記憶體,然后在 GPU 記憶體不足時將其自動卸載到 CPU 記憶體,并在優化器更新步驟需要時將其加載回 GPU 記憶體,
-
增加Adapter:4-bit的NormalFloat與Double Quantization,節省了很多空間,但帶來了性能損失,作者通過插入更多adapter來彌補這種性能損失,在LoRA中,一般會選擇在query和value的全連接層處插入adapter,而QLoRA則在所有全連接層處都插入了adapter,增加了訓練引數,彌補精度帶來的性能損失,
參考:
https://zhuanlan.zhihu.com/p/632164305
https://zhuanlan.zhihu.com/p/636215898
https://zhuanlan.zhihu.com/p/634256206
https://zhuanlan.zhihu.com/p/632229856
https://blog.csdn.net/qq_39970492/article/details/131048994
總結
QLORA 可以使用 4 位基礎模型和低秩配接器 (LoRA) 復制 16 位完全微調性能,QLORA將微調65B引數模型的平均記憶體需求從>780GB的GPU記憶體降低到<48GB,與完全微調的16位基準相比,既不降低運行時間也不降低預測性能,這意味著可以在單個GPU上微調迄今為止最大的公開可用模型,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/556037.html
標籤:其他
下一篇:返回列表