摘要:本文將從實踐案例角度為大家解讀強化學習中的梯度策略、添加基線(baseline)、優勢函式、動作分配合適的分數(credit),
本文分享自華為云社區《強化學習從基礎到進階-案例與實踐[5]:梯度策略、添加基線(baseline)、優勢函式、動作分配合適的分數(credit)》,作者: 汀丶,
1 策略梯度演算法
如圖 5.1 所示,強化學習有 3 個組成部分:演員(actor)、環境和獎勵函式,智能體玩視頻游戲時,演員負責操控游戲的搖桿, 比如向左、向右、開火等操作;環境就是游戲的主機,負責控制游戲的畫面、負責控制怪獸的移動等;獎勵函式就是當我們做什么事情、發生什么狀況的時候,可以得到多少分數, 比如打敗一只怪獸得到 20 分等,同樣的概念用在圍棋上也是一樣的,演員就是 Alpha Go,它要決定棋子落在哪一個位置;環境就是對手;獎勵函式就是圍棋的規則,贏就是得一分,輸就是負一分,在強化學習里,環境與獎勵函式不是我們可以控制的,它們是在開始學習之前給定的,我們唯一需要做的就是調整演員里面的策略,使得演員可以得到最大的獎勵,演員里面的策略決定了演員的動作,即給定一個輸入,它會輸出演員現在應該要執行的動作,
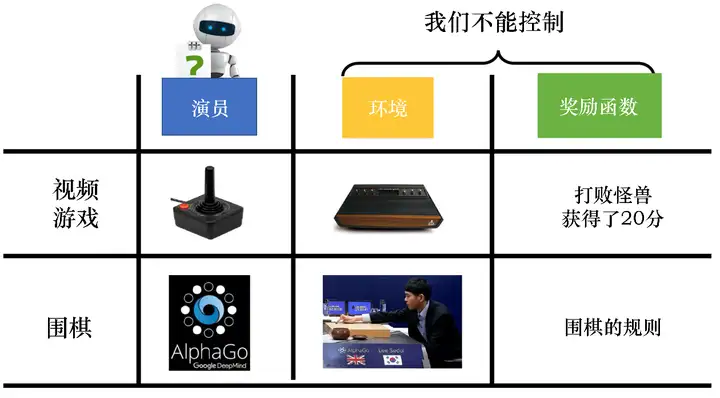
圖 5.1 強化學習的組成部分
策略一般記作 ππ,假設我們使用深度學習來做強化學習,策略就是一個網路,網路里面有一些引數,我們用 θθ 來代表 ππ 的引數,網路的輸入是智能體看到的東西,如果讓智能體玩視頻游戲,智能體看到的東西就是游戲的畫面,智能體看到的東西會影響我們訓練的效果,例如,在玩游戲的時候, 也許我們覺得游戲的畫面是前后相關的,所以應該讓策略去看從游戲開始到當前這個時間點之間所有畫面的總和,因此我們可能會覺得要用到回圈神經網路(recurrent neural network,RNN)來處理它,不過這樣會比較難處理,我們可以用向量或矩陣來表示智能體的觀測,并將觀測輸入策略網路,策略網路就會輸出智能體要采取的動作,圖 5.2 就是具體的例子,策略是一個網路;輸入是游戲的畫面,它通常是由像素組成的;輸出是我們可以執行的動作,有幾個動作,輸出層就有幾個神經元,假設我們現在可以執行的動作有 3 個,輸出層就有 3 個神經元,每個神經元對應一個可以采取的動作,輸入一個東西后,網路會給每一個可以采取的動作一個分數,我們可以把這個分數當作概率,演員根據概率的分布來決定它要采取的動作,比如 0.7 的概率向左走、0.2 的概率向右走、0.1的概率開火等,概率分布不同,演員采取的動作就會不一樣,
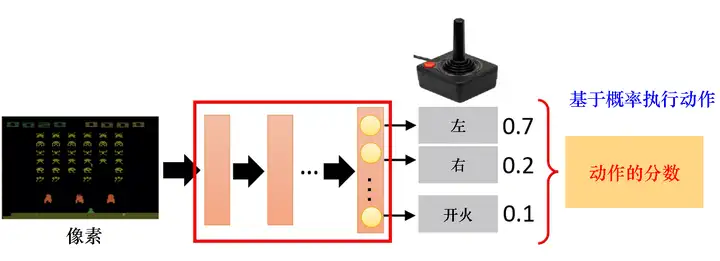
圖 5.2 演員的策略
接下來我們用一個例子來說明演員與環境互動的程序,如圖 5.3 所示,首先演員會看到一個視頻游戲的初始畫面,接下來它會根據內部的網路(內部的策略)來決定一個動作,假設演員現在決定的動作是向右,決定完動作以后,它就會得到一個獎勵,獎勵代表它采取這個動作以后得到的分數,
我們把游戲初始的畫面記作 s1s1?, 把第一次執行的動作記作 a1a1?,把第一次執行動作以后得到的獎勵記作 r1r1?,不同的人有不同的記法,有人覺得在 s1s1? 執行 a1a1? 得到的獎勵應該記為 r2r2?,這兩種記法都可以,演員決定一個動作以后,就會看到一個新的游戲畫面s2s2?,把 s2s2? 輸入給演員,演員決定要開火,它可能打敗了一只怪獸,就得到五分,這個程序反復地持續下去,直到在某一個時間點執行某一個動作,得到獎勵之后,環境決定這個游戲結束,例如,如果在這個游戲里面,我們控制宇宙飛船去擊殺怪獸,如果宇宙飛船被毀或是把所有的怪獸都清空,游戲就結束了,
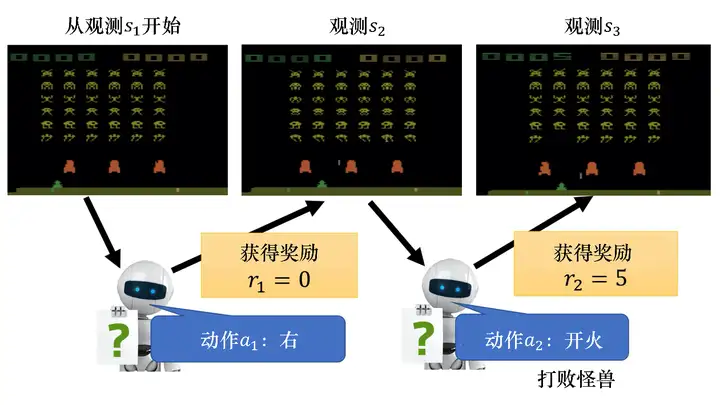
圖 5.3 玩視頻游戲的例子
如圖 5.4 所示,一場游戲稱為一個回合,將這場游戲里面得到的所有獎勵都加起來,就是總獎勵(total reward),也就是回報,我們用RR來表示它,演員要想辦法來最大化它可以得到的獎勵,
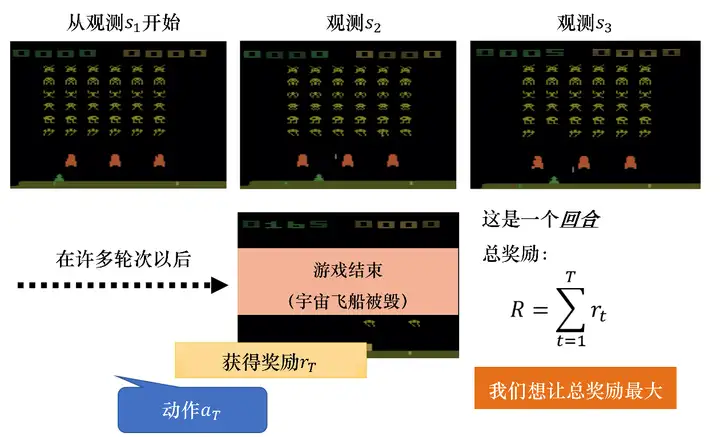
圖 5.4 回報的例子
如圖 5.5 所示,首先,環境是一個函式,我們可以把游戲的主機看成一個函式,雖然它不一定是神經網路,可能是基于規則的(rule-based)模型,但我們可以把它看作一個函式,這個函式一開始先“吐”出一個狀態(游戲畫面 s1s1?),接下來演員看到游戲畫面 s1s1? 以后,它“吐”出動作 a1a1?,環境把動作 a1a1? 當作它的輸入,再“吐”出新的游戲畫面 s2s2?,演員看到新的游戲畫面s2s2?,再采取新的動作 a2a2?,環境看到 a2a2?,再“吐”出 s3s3? …這個程序會一直持續下去,直到環境覺得應該要停止為止,
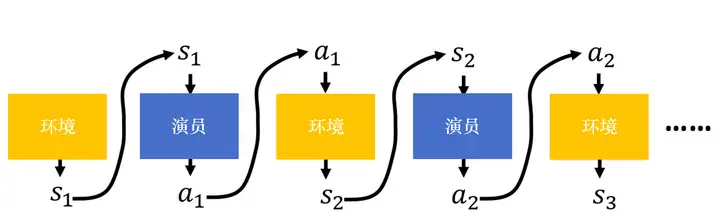
圖 5.5 演員和環境
在一場游戲里面,我們把環境輸出的 ss 與演員輸出的動作 aa 全部組合起來,就是一個軌跡,即
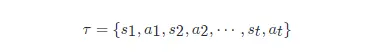
給定演員的引數 θθ,我們可以計算某個軌跡ττ發生的概率為
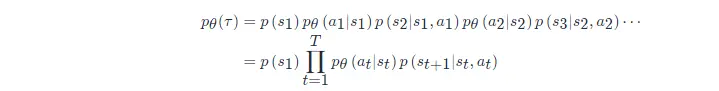

我們要窮舉所有可能的軌跡 ττ, 每一個軌跡 ττ 都有一個概率,
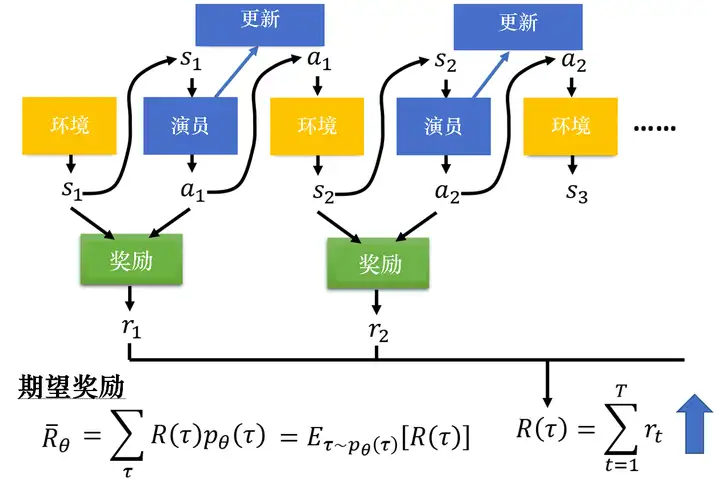
圖 5.6 期望的獎勵
比如 θθ 對應的模型很強,如果有一個回合 θθ 很快就死掉了,因為這種情況很少會發生,所以該回合對應的軌跡 ττ 的概率就很小;如果有一個回合 θθ 一直沒死,因為這種情況很可能發生,所以該回合對應的軌跡 ττ 的概率就很大,我們可以根據 θθ 算出某一個軌跡 ττ 出現的概率,接下來計算 ττ 的總獎勵,總獎勵使用 ττ 出現的概率進行加權,對所有的 ττ 進行求和,就是期望值,給定一個引數,我們可以計算期望值為
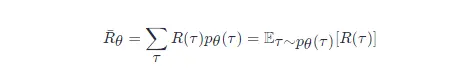



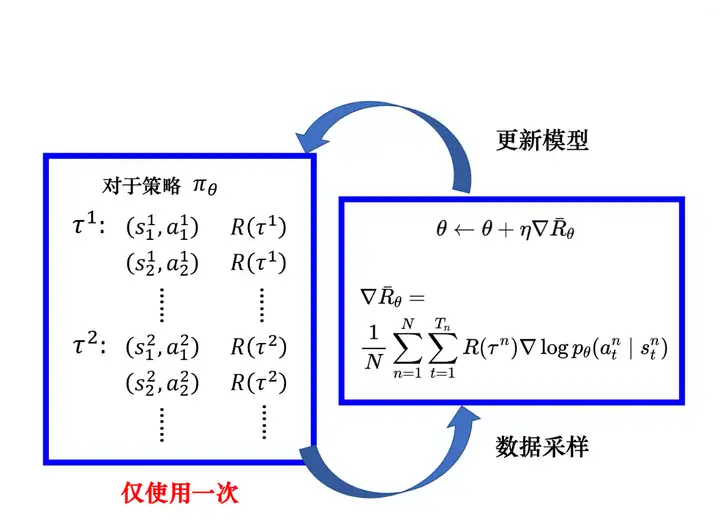
圖 5.7 策略梯度
更新完模型以后,我們要重新采樣資料再更新模型,注意,一般**策略梯度(policy gradient,PG)**采樣的資料只會用一次,我們采樣這些資料,然后用這些資料更新引數,再丟掉這些資料,接著重新采樣資料,才能去更新引數,
接下來我們講一些實作細節,如圖 5.8 所示,我們可以把強化學習想成一個分類問題,這個分類問題就是輸入一個影像,輸出某個類,在解決分類問題時,我們要收集一些訓練資料,資料中要有輸入與輸出的對,在實作的時候,我們把狀態當作分類器的輸入,就像在解決影像分類的問題,只是現在的類不是影像里面的東西,而是看到這張影像我們要采取什么樣的動作,每一個動作就是一個類,比如第一個類是向左,第二個類是向右,第三個類是開火,
在解決分類問題時,我們要有輸入和正確的輸出,要有訓練資料,但在強化學習中,我們通過采樣來獲得訓練資料,假設在采樣的程序中,在某個狀態下,我們采樣到要采取動作 aa, 那么就把動作 aa 當作標準答案(ground truth),比如,我們在某個狀態下,采樣到要向左,因為是采樣,所以向左這個動作不一定概率最高,假設我們采樣到向左,在訓練的時候,讓智能體調整網路的引數, 如果看到某個狀態,我們就向左,在一般的分類問題里面,我們在實作分類的時候,目標函式都會寫成最小化交叉熵(cross entropy),最小化交叉熵就是最大化對數似然(log likelihood),
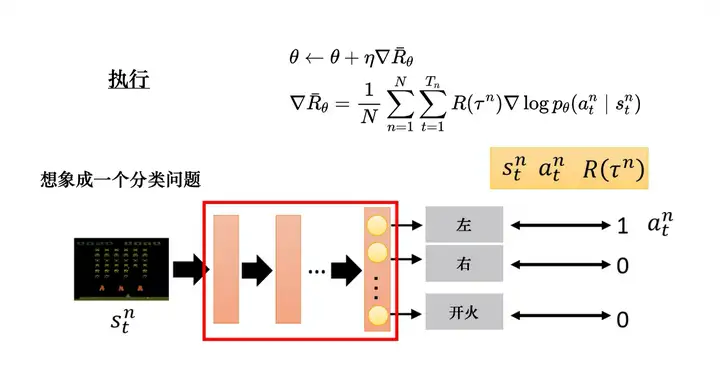
圖 5.8 策略梯度實作細節
我們在解決分類問題的時候,目標函式就是最大化或最小化的物件,因為我們現在是最大化似然(likelihood),所以其實是最大化,我們要最大化
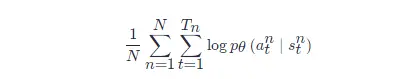
我們可在 PyTorch 里呼叫現成的函式來自動計算損失函式,并且把梯度計算出來,這是一般的分類問題,強化學習與分類問題唯一不同的地方是損失前面乘一個權重————整場游戲得到的總獎勵 R(τ)R(τ),而不是在狀態ss采取動作aa的時候得到的獎勵,即
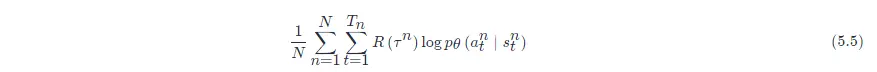
我們要把每一筆訓練資料,都使用 R(τ)R(τ) 進行加權,如圖 5.9 所示,我們使用 PyTorch 或 TensorFlow 之類的深度學習框架計算梯度就結束了,與一般分類問題差不多,
圖 5.9 自動求梯度
2 策略梯度實作技巧
下面我們介紹一些在實作策略梯度時可以使用的技巧,
2.1 技巧 1:添加基線
第一個技巧:添加基線(baseline),如果給定狀態 ss 采取動作 aa,整場游戲得到正的獎勵,就要增加 (s,a)(s,a) 的概率,如果給定狀態 ss 執行動作 aa,整場游戲得到負的獎勵,就要減小 (s,a)(s,a) 的概率,但在很多游戲里面,獎勵總是正的,最低都是 0,比如打乒乓球游戲, 分數為 0 ~ 21 分,所以R(τ)R(τ)總是正的,假設我們直接使用式(5.5),在訓練的時候告訴模型,不管是什么動作,都應該要把它的概率提升,
雖然R(τ)R(τ)總是正的,但它的值是有大有小的,比如我們在玩乒乓球游戲時,得到的獎勵總是正的,但采取某些動作可能得到 0 分,采取某些動作可能得到 20 分,
如圖 5.10 所示,假設我們在某一個狀態有 3 個動作 a、b、c可以執行,根據式(5.6),我們要把這 3 個動作的概率,對數概率都提高, 但是它們前面的權重R(τ)R(τ)是不一樣的,權重是有大有小的,權重小的,該動作的概率提高的就少;權重大的,該動作的概率提高的就多, 因為對數概率是一個概率,所以動作 a、b、c 的對數概率的和是 0, 所以提高少的,在做完歸一化(normalize)以后,動作 b 的概率就是下降的;提高多的,該動作的概率才會上升,
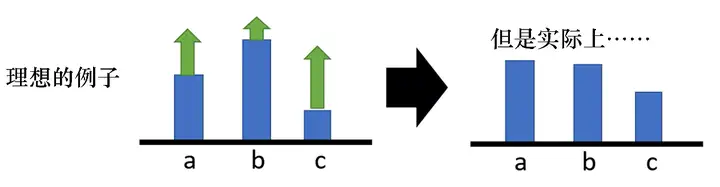
圖 5.10 動作的概率的例子
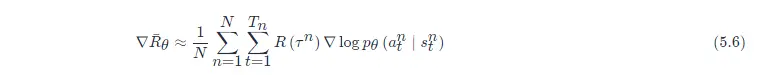
這是一個理想的情況,但是實際上,我們是在做采樣本來這邊應該是一個期望(expectation),對所有可能的ss與aa的對進行求和, 但我們真正在學習的時候,只是采樣了少量的ss與aa的對, 因為我們做的是采樣,所以有一些動作可能從來都沒有被采樣到,如圖 5.11 所示,在某一個狀態,雖然可以執行的動作有 a、b、c,但我們可能只采樣到動作 b 或者 只采樣到動作 c,沒有采樣到動作 a,但現在所有動作的獎勵都是正的,所以根據式(5.6),在這個狀態采取a、b、c的概率都應該要提高,我們會遇到的問題是,因為 a 沒有被采樣到,所以其他動作的概率如果都要提高,a 的概率就要下降, 所以a不一定是一個不好的動作, 它只是沒有被采樣到,但因為 a 沒有被采樣到,它的概率就會下降,這顯然是有問題的,要怎么解決這個問題呢?我們會希望獎勵不總是正的,
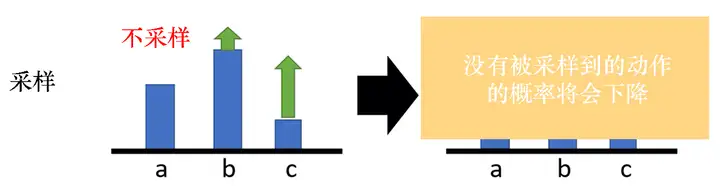
圖 5.11 采樣動作的問題
為了解決獎勵總是正的的問題,我們可以把獎勵減 bb,即

2.2 技巧 2:分配合適的分數
第二個技巧:給每一個動作分配合適的分數(credit),如式(5.7)所示,只要在同一個回合里面,在同一場游戲里面,所有的狀態-動作對就使用同樣的獎勵項進行加權,
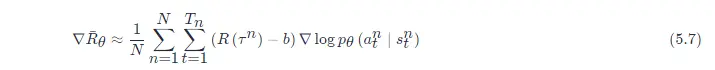

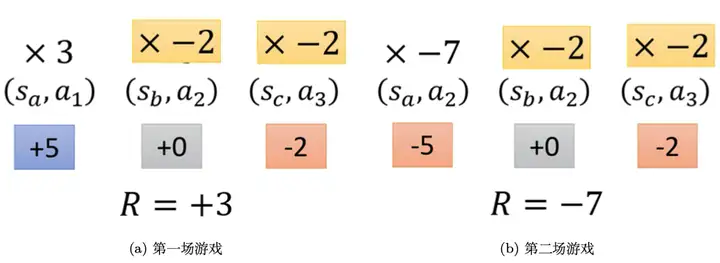
圖 5.12 分配合適的分數
分配合適的分數這一技巧可以表達為
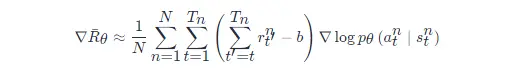
原來的權重是整場游戲的獎勵的總和,現在改成從某個時刻 tt 開始,假設這個動作是在 tt 開始執行的,從 tt 一直到游戲結束所有獎勵的總和才能代表這個動作的好壞,
接下來更進一步,我們把未來的獎勵做一個折扣,即
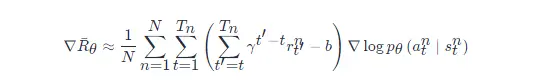

3 REINFORCE:蒙特卡洛策略梯度
如圖 5.13 所示,蒙特卡洛方法可以理解為演算法完成一個回合之后,再利用這個回合的資料去學習,做一次更新,因為我們已經獲得了整個回合的資料,所以也能夠獲得每一個步驟的獎勵,我們可以很方便地計算每個步驟的未來總獎勵,即回報 GtGt? ,GtGt? 是未來總獎勵,代表從這個步驟開始,我們能獲得的獎勵之和,$G_1 代表我們從第一步開始,往后能夠獲得的總獎勵,代表我們從第一步開始,往后能夠獲得的總獎勵,G_2$ 代表從第二步開始,往后能夠獲得的總獎勵,
相比蒙特卡洛方法一個回合更新一次,時序差分方法是每個步驟更新一次,即每走一步,更新一次,時序差分方法的更新頻率更高,時序差分方法使用Q函式來近似地表示未來總獎勵 GtGt?,
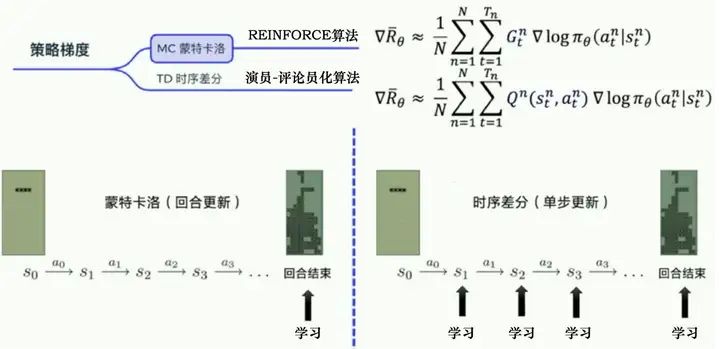
圖 5.13 蒙特卡洛方法與時序差分方法


圖 5.14 REINFORCE演算法
獨熱編碼(one-hot encoding)通常用于處理類別間不具有大小關系的特征, 例如血型,一共有4個取值(A型、B型、AB型、O型),獨熱編碼會把血型變成一個4維稀疏向量,A型血表示為(1,0,0,0),B型血表示為(0,1,0,0),AB型血表示為(0,0,1,0),O型血表示為(0,0,0,1),
如圖 5.15 所示,手寫數字識別是一個經典的多分類問題,輸入是一張手寫數字的圖片,經過神經網路處理后,輸出的是各個類別的概率,我們希望輸出的概率分布盡可能地貼近真實值的概率分布,因為真實值只有一個數字 9,所以如果我們用獨熱向量的形式給它編碼,也可以把真實值理解為一個概率分布,9 的概率就是1,其他數字的概率就是 0,神經網路的輸出一開始可能會比較平均,通過不斷地迭代、訓練優化之后,我們會希望輸出9 的概率可以遠高于輸出其他數字的概率,
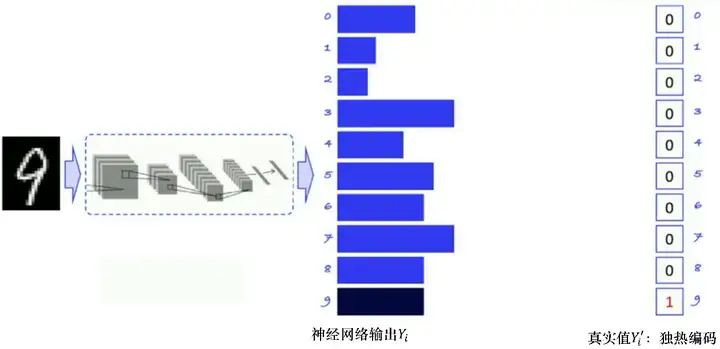
圖 5.15 監督學習例子:手寫數字識別
如圖 5.16 所示,我們所要做的就是提高輸出 9 的概率,降低輸出其他數字的概率,讓神經網路輸出的概率分布能夠更貼近真實值的概率分布,我們可以用交叉熵來表示兩個概率分布之間的差距,

圖 5.16 提高數字9的概率
我們看一下監督學習的優化流程,即怎么讓輸出逼近真實值,如圖 5.17 所示,監督學習的優化流程就是將圖片作為輸入傳給神經網路,神經網路會判斷圖片中的數字屬于哪一類數字,輸出所有數字可能的概率,再計算交叉熵,即神經網路的輸出 YiYi? 和真實的標簽值 Yi′Yi′? 之間的距離 ?∑Yi′?log?(Yi)?∑Yi′??log(Yi?),我們希望盡可能地縮小這兩個概率分布之間的差距,計算出的交叉熵可以作為損失函式傳給神經網路里面的優化器進行優化,以自動進行神經網路的引數更新,
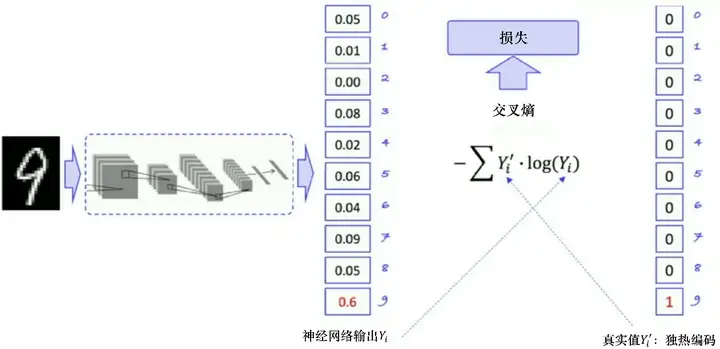
圖 5.17 優化流程
類似地,如圖 5.18 所示,策略梯度預測每一個狀態下應該要輸出的動作的概率,即輸入狀態 stst?,輸出動作atat?的概率,比如 0.02、0.08、0.9,實際上輸出給環境的動作是隨機選擇一個動作,比如我們選擇向右這個動作,它的獨熱向量就是(0,0,1),我們把神經網路的輸出和實際動作代入交叉熵的公式就可以求出輸出動作的概率和實際動作的概率之間的差距,但實際的動作 atat? 只是我們輸出的真實的動作,它不一定是正確的動作,它不能像手寫數字識別一樣作為一個正確的標簽來指導神經網路朝著正確的方向更新,所以我們需要乘一個獎勵回報 GtGt?,GtGt?相當于對真實動作的評價,如果 GtGt? 越大,未來總獎勵越大,那就說明當前輸出的真實的動作就越好,損失就越需要重視,如果 GtGt? 越小,那就說明動作 atat? 不是很好,損失的權重就要小一點兒,優化力度也要小一點兒,通過與手寫數字識別的一個對比,我們就知道為什么策略梯度損失會構造成這樣,
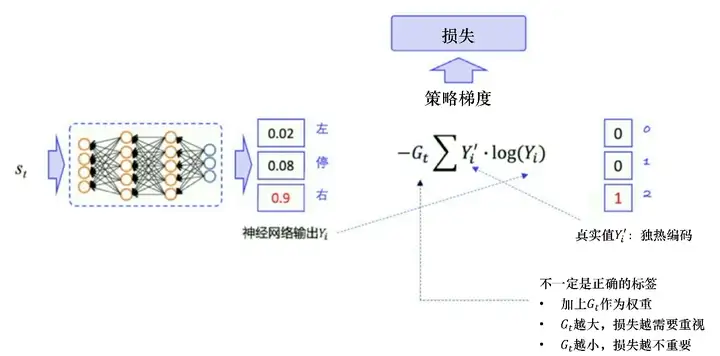
圖 5.18 策略梯度損失
如圖 5.19 所示,實際上我們在計算策略梯度損失的時候,要先對實際執行的動作取獨熱向量,再獲取神經網路預測的動作概率,將它們相乘,我們就可以得到 log?π(at∣st,θ)logπ(at?∣st?,θ),這就是我們要構造的損失,因為我們可以獲取整個回合的所有的軌跡,所以我們可以對這一條軌跡里面的每個動作都去計算一個損失,把所有的損失加起來,我們再將其“扔”給 Adam 的優化器去自動更新引數就好了,
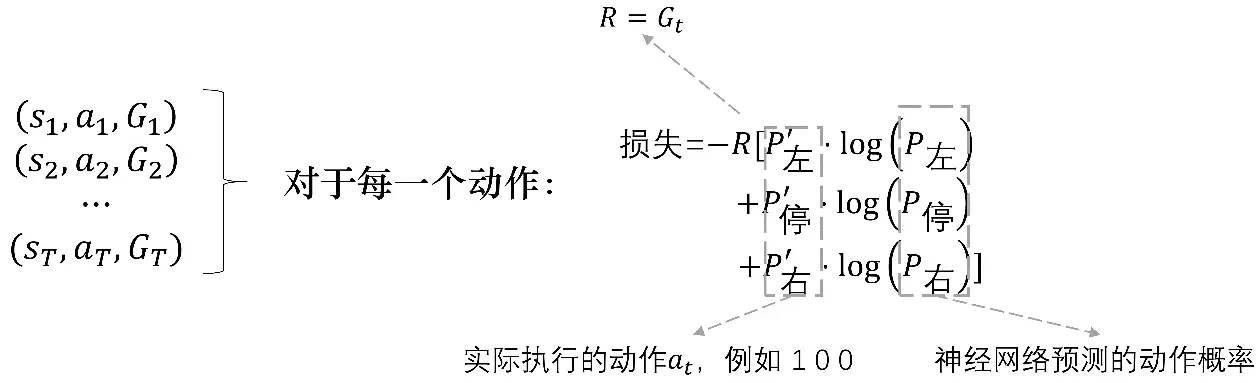
圖 5.19 損失計算
圖 5.20 所示為REINFORCE 演算法示意,首先我們需要一個策略模型來輸出動作概率,輸出動作概率后,通過 sample() 函式得到一個具體的動作,與環境互動后,我們可以得到整個回合的資料,得到回合資料之后,我們再去執行 learn() 函式,在 learn() 函式里面,我們就可以用這些資料去構造損失函式,“扔”給優化器優化,更新我們的策略模型,
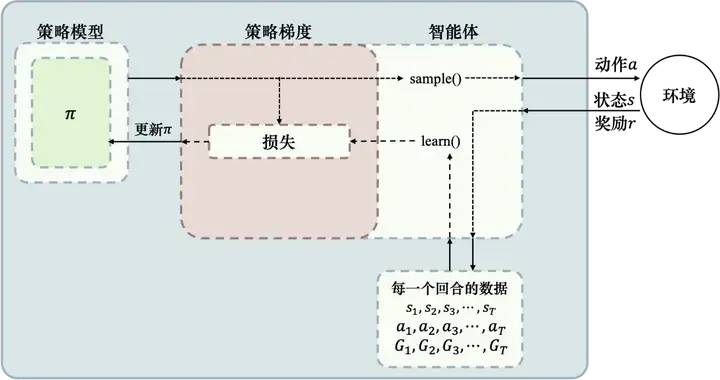
圖 5.20 REINFORCE演算法示意
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/556127.html
標籤:其他
上一篇:3 分鐘為英語學習神器 Anki 部署一個專屬同步服務器
下一篇:返回列表