前一章思維鏈基礎和進階玩法我們介紹了如何寫Chain-of-thought Prompt來激活生成逐步推理,并提高模型解決復雜問題的能力,這一章我們追本溯源,討論下COT的哪些元素是提升模型表現的核心?
要進行因果分析,需要把思維鏈中的不同元素拆解開來,然后通過控制變數實驗,來研究不同元素對COT效果的影響,以下兩篇論文的核心差異就在于: COT的變數拆解,以及控制變數的實驗方式,
結合兩篇論文的實驗結論,可能導致思維鏈比常規推理擁有更高準確率的因素有
- 思維鏈的推理程序會重復問題中的核心物體,例如數字,人物,數字等
- 思維鏈正確邏輯推理順序的引入
友情提示:以下論文的實驗依賴反事實因果推斷,這種因果分析方式本身可能存在有偏性進而得到一些錯誤結論,讀論文有風險,迷信論文需謹慎哈哈~
TEXT AND PATTERNS: FOR EFFECTIVE CHAIN OF THOUGHT IT TAKES TWO TO TANGO
- 測驗模型:PaLM-62B,GPT3,CODEX
google這篇論文比較早,按個人閱讀舒適度來劃分個人更推薦第二篇論文喲~
COT元素
論文把影響元素拆分成了Text,Symbol和Pattern三個部分, 如下

論文給出了symbol和pattern的定義,剩下的token全是Text
- symbol:是資料集的核心主體,數學問題就是數字,SPORT資料集就是運動員和運動專案, DATE資料集就是時間,這里的symbol類似物體的概念
- pattern: 可以是symbol的組合,連接符(公式)或者幫助模型理解任務的表述結構,這里允許pattern和symbol重合,也就是整個公式是pattern,但公式中的數字同樣是symbol,但在非數學問題上我個人覺得pattern的定義有點迷幻...
實驗
論文針對以上3個元素分別進行了實驗,通過改變COT few-shot prompt中特定元素的取值,來分析該元素對COT效果的貢獻
觀點1.Symbol的形式和取值本身對COT影響不大
這里論文用了兩種控制變數的方式:symbol隨機采樣和特殊符號替換
- 特殊符號替換(symb_abs)
abstract symbol就是用特殊符號來替換symbol,這里作者同時替換了question,prompt和answer里面的symbol如下

- 隨機替換(symb_ood)
OOD類似隨機替換,不過論文的替換方式有些迷幻,對于GSM8k數學問題,作者用一一對應的數學數字替換了文字數字;對于體育常識問題的替換比較常規作者用隨機的人名和賽事進行替換;對于時間常識問題作者用未來時間替換了當前時間?? 注意這里的替換作者保證了推理邏輯的一致性,包括同一數字用同一symbol替換,替換物體也符合推理邏輯,以及對問題中的答案也進行了替換,所以這里純純只能論證symbol本身的取值和型別(例如數字1和一)是否對COT有影響
abstract symbol就是用特殊符號來替換symbol,這里作者同時替換了question,prompt和answer里面的symbol如下

這種替換方式下的實驗結果如下,除了體育問題中的隨機物體替換,其余symbol的替換對COT的效果影響都非常有限,這讓我想到了一篇關于NER模型的泛化性主要來自模型學會了不同型別的物體會出現在哪些背景關系中,而不僅是對物體本身的形式進行了記憶,他們的實驗方式和作者替換symbol的操作其實很類似,這種替換并不大幅影響下文對上文的Attention,

觀點2. pattern是COT生效的必要不充分條件
對于Pattern作者更換了實驗方式,控制變數采用了只保留pattern,和只剔除pattern這兩種實驗型別,
以數學問題為例,只保留pattern就是推理程序只保留數學公式,只剔除pattern就是整個推理程序只把公式剔除,其余問題型別,考慮在前面的pattern定義階段個人就感覺有些迷幻,... 所以我們直接跳到實驗結論吧
- 只有pattern的COT效果很差,和直接推理差不多,說明只有patten肯定是不夠的,這和上一篇博客提到COT小王子嘗試過的只有數學公式的COT效果不好的結論是一致的,
- 剔除pattern的COT效果受到影響,因此pattern對COT有顯著影響,但很顯然還有別的因素

觀點3. 推理出現問題中的關鍵物體且和問題保持格式一致很重要
最后針對Text部分,作者采用了物體替換和語法替換
- 物體替換(text_diff_entities):把推理中的物體隨機替換成和問題中不一樣的物體,包括數學問題中的數字,常識問題中的時間,地點和任務,個人感覺這應該是symbol的實驗??

- 語法替換(text_yoda_thought): 把常規的英文表達改成了Yoda的說法風格,Yoda是按照名詞-形容詞-動詞順序來說話的,例如常規是This is my home,Yoda會說My home this is,只對thought進行語法替換,question保持正常的英文表達,

效果上,隨機物體替換對所有任務的COT效果影響非常大, 所以在推理階段使用Question中的核心物體很重要,其次推理和question在語法上的不一致會影響COT在部分任務上的表現,

Towards Understanding Chain-of-Thought Prompting: An Empirical Study of What Matters
- 測驗模型:text-davinci-002, text-davinci-003
整體上第二篇論文的思路更簡單清晰,在拆解元素的同時還定義了關系,
COT元素
論文首先定義了思維鏈中的兩種核心元素
- Bridge Object: 模型解決問題所需的核心和必須元素,例如數學問題中的數字和公式,QA問題中的物體,有點類似把論文1中pattern和symbol和在了一起,感覺定義更清晰了
- Language Template:除去Bridge Object剩余的部分基本都是Language Template
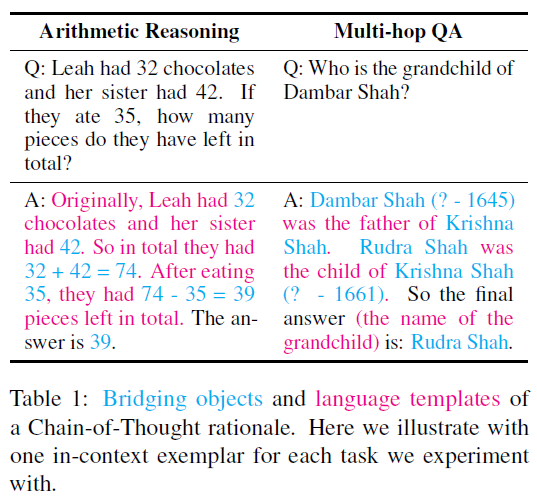
其次定義了思維鏈的兩種核心關系
- 一致性(Coherence): 推理步驟之間的邏輯順序, 先說什么后說什么
- 相關性(Relevance): Question中核心元素是否在推理中出現
實驗
論文的消融實驗通過人工修改few-shot COT中的few-shot樣本,來驗證思維鏈中不同元素的貢獻,這里我們以一個數學問題問題為例,看下實驗的兩個階段
觀點1. 完全正確的COT并非必要
第一步作者證明了完全正確的In-Context樣本并不是必須的,用的什么方法嘞?
如下圖所示,作者手工把正確的In-Context COT樣本改寫成錯誤的,改寫方式是在保留部分推理順序,和部分bridge object的前提下,隨機的把推理改成錯誤的推理邏輯,作者發現魔改后錯誤的few-shot的樣本,對比正確的few-shot-cot保留了80%+的水平,只有小幅的下降,

觀點2.推理順序和核心元素的出現更重要
既然完全正確的COT樣本并非必須,那究竟思維鏈的哪些元素對效果的影響最大呢?針對以上兩種元素和兩種關系,作者用了資料增強的方式來對few-shot樣本進行修改,得到破壞某一種元素/關系后的few-shot樣本
- 破壞相關性: 這里使用了Random Substitution; 針對Bridge Obejct,就是固定文字模板,把數學問題中出現的數字在COT里面(32/42/35)隨機替換成其他數字,這里為了保持背景關系一致性相同的數字會用相同的亂數字來替換; 針對template,就固定Bridge Object,從樣本中隨機采樣其他的COT推理模板來進行替換,
- 破壞一致性: 這里使用了Random Shuffle;針對Bridge Object,就是把COT中不同位置的Bridge Obejct隨機打亂順序;針對Template,就固定Bridge Object,把文字模板的句子隨機改變位置,
整體效果如下圖

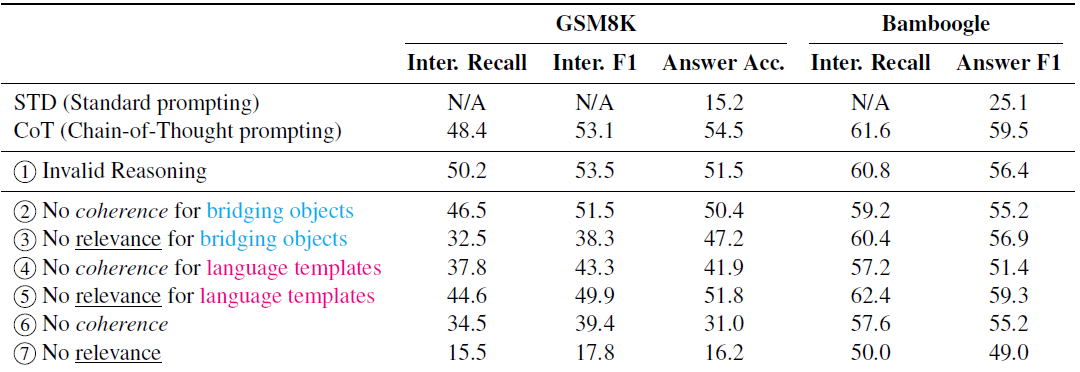
論文正文用的是text-davinci-002,附錄里也補充了text-davinci-003的效果,看起來003的結果單調性更好,二者結論是基本一致的,因此這里我們只看下003的消融實驗效果,可以得到以下幾個核心結論
- 對比COT推理的正確性,相關性和一致性更加重要,尤其是相關性,也就是在推理程序中復述question中的關鍵資訊可以有效提高模型推理準確率,個人猜測是核心元素的復述可以幫助模型更好理解指令識別指令中的關鍵資訊,并提高該資訊對應的知識召回【這一點我們在下游難度較高的多項選擇SFT中也做過驗證,我們在多項選擇的推理模板的最后加入了題干的復述,效果會有一定提升,進一步把選項的結果完形填空放到題干中,效果會有更進一步的提升】
- Language Template的一致性貢獻度較高,也就是正確的邏輯推理順序有助于模型推理效果的提升,這一點更好理解主要和decoder需要依賴上文的解碼方式相關,【還是多項選擇的指令微調,我們對比了把選項答案放在推理的最前面和放在復述題干之前的效果,都顯著差于先推理分析,復述題干并填入選項答案,最后給出選項答案這個推理順序】
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/556469.html
標籤:其他
上一篇:AtCoder Beginner Contest 308
下一篇:返回列表