摘要:instructPix2Pix文字編輯圖片是一種純文本編輯影像的方法,用戶提供一張圖片和文本編輯指令,告訴模型要做什么,模型根據編輯指令編輯輸入的影像,最終輸出用戶想要的影像,
本文分享自華為云社區《【云駐共創】Stable Diffusion AIGC限時0元!3步成為P圖大師》,作者:香菜聊游戲 ,
1、instructPix2Pix概覽
instructPix2Pix文字編輯圖片是一種純文本編輯影像的方法,用戶提供一張圖片和文本編輯指令,告訴模型要做什么,模型根據編輯指令編輯輸入的影像,最終輸出用戶想要的影像,
它可以讓你通過簡單的語言描述來生成符合要求的圖片,而不需要手動撰寫代碼或進行復雜的操作,這使得影像生成更加高效和便捷,例如,如果你想將一張天空照片轉換為夜晚照片,你只需要輸入指令:“將天空替換為黑暗的夜晚”,然后模型就會自動將天空替換為星星和月亮,并將顏色和光線調整為夜晚的感覺,
視頻地址:https ://bbs.huaweicloud.com/live/cloud_live/20230413.html
2、技術框架
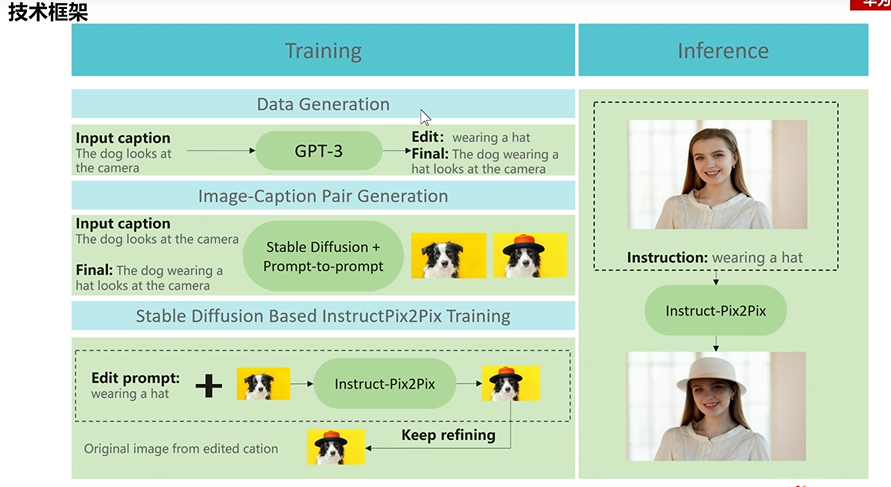
2.1 框架概述
整個框架是使用現有大模型的能力,實作了自己的任務,整個技術堆疊都是現有技術的整合,但是依然做出了一個很好玩的應用
框架總體分為2個部分:模型訓練(Traning)和推理(Inference),
模型訓練分為資料工程和模型訓練,
整個pipeline的目標是通過使用GPT-3生成編輯指令和描述,以及使用Stable Diffusion生成影像對,來訓練Instruct-Pix2Pix模型,使其能夠根據編輯指令生成高質量的編輯后的影像,然后,使用訓練好的Instruct-Pix2Pix模型進行推理,以提供給用戶或實際應用場景所需的編輯后的影像,
2.2 資料生成
2.2.1 編輯指令的生成
這部分完全是文字作業,借助了GPT-3 的能力,給定一個輸入的描述,然后由GPT-3 輸出編輯后的指令和生成的描述
比如圖中輸入:The dog looks at the Camera
GPT3 會輸出:編輯指令 wearing a hat 和最終的描述指令 The dog wearing a hat looks at the camera

作者使用了700條人工標注的指令,并對GPT-3進行了微調,以便在生成編輯指令和編輯后的指令時能夠更好地滿足要求,
輸入GPT-3的指令格式包括兩部分:prompt和completion,其中,prompt是輸入指令,用于指導GPT-3生成相應的文本輸出;completion是編輯指令和編輯后的指令,用于在GPT-3生成的結果上進行進一步的修改和調整,這樣輸入的好處是編輯指令也是由GPT-3生成的,這樣保證生成的多樣哈,最終GPT會生成超過45萬的編輯指令,上圖高亮的部分都是GPT-3生成,這些指令被用于訓練Instruct-Pix2Pix模型,最終為實際應用場景提供高質量的影像編輯服務,
2.2.2 生成影像對
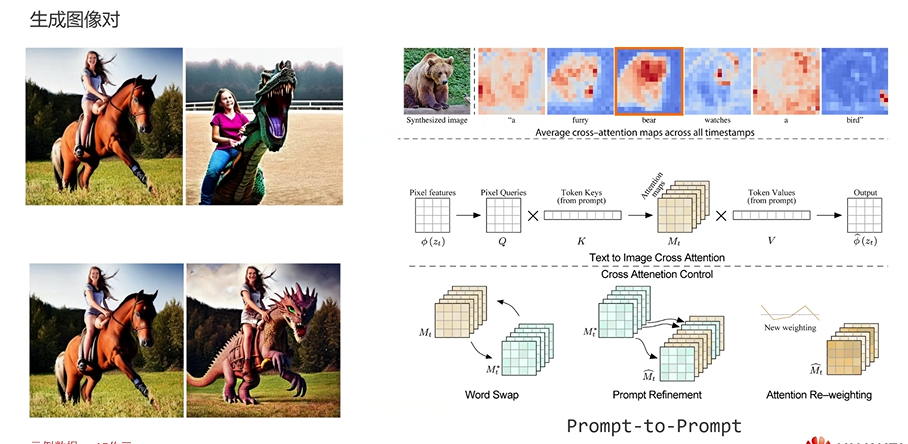
將上一步驟生成的超過45萬的編輯指令和描述指令,輸入通過Stable Diffusion 生成影像對,
在這個程序中存在一個挑戰,做過文生圖的同學都知道,即使你固定亂數,差距很小的prompt通過Stable Diffusion也有可能生成內容完全不同的影像,這是因為Stable Diffusion在生成影像時受到許多因素的影響,例如亂數生成、模型引數、輸入文本的微小變化等等,因此,即使兩個prompt看起來非常相似,Stable Diffusion也可能生成截然不同的影像,
解決辦法:
在文生圖中,使用了Cross Attention機制來建立文本和圖片之間的關聯,Cross Attention是一種注意力機制,其本質是通過篩選來實作資訊的融合,在文生圖中,這種機制被用于找到文本提示(prompt)與圖片之間的關系,
具體而言,當給定一個文本提示時,Cross Attention會對文本中的不同單詞進行激活,并通過注意力的機制,選擇與激活單詞相關聯的圖片區域,通過這種方式,可以根據文本提示中的不同單詞來激活不同的影像區域,從而實作文本與影像的關聯,
以文生圖中的例子為例,如果文本提示中包含單詞"bear",則Cross Attention機制會根據該單詞的激活程度,選擇與之相關聯的圖片區域,在上圖中可以看到,與"bear"相關聯的圖片區域被激活得最多,這意味著該區域與"bear"這個單詞有最強的關聯,
通過Cross Attention機制,文生圖能夠將文本提示和圖片進行有效地融合,從而產生與文本提示相對應的影像生成結果,這種機制能夠幫助生成更準確和相關的影像,使文本與影像之間的關聯更加緊密和有意義,
這個替換可以可以發生在任意一步,替換的越多則影像更多樣,
2.3 模型訓練,文生圖
instructPix2Pix 是通過有監督的方法實作文本編輯影像,使用條件擴散模型,
輸入的資料為:一張原圖和編輯指令,輸出編輯之后的圖
2.3.1 文生圖原理
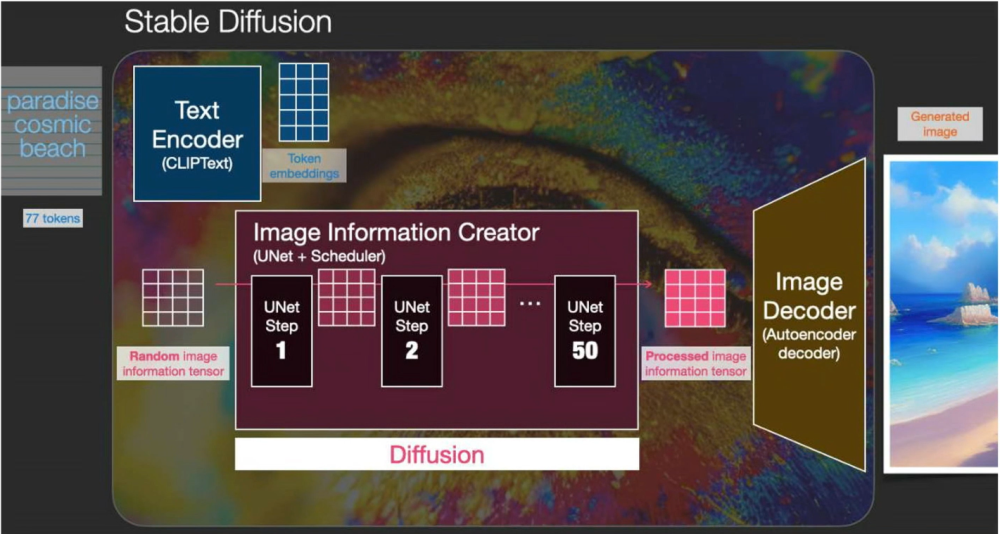
整個任務是輸入prompt,根據prompt輸出一張圖,
1.對輸入的文字進行tokenlization和embedings獲得詞向量,
2.詞向量會在Diffusion中通過Cross Attention的程序中參與到影像生成的程序中
3.模型還會有一個隨機的噪聲圖向量輸入,在擴散的程序中恢復到原圖的生成像素向量
4.最后通過解碼器將像素向量解碼
2.3.2 instructPix2Pix 和Stable Diffusion的不同
1.instructPix2Pix會多出一個影像輸入,在輸入的時候將原圖拼接到噪聲圖,會需要額外的channel,這些額外的channel會被初始化為0,其他的權重會使用預訓練的Stable Diffusion初始化,
2.在訓練中增加了隨機的條件Dropout來平衡模型的生成的樣本的多樣性,
3.推理的程序中加入了引數可以調節原始影像所占的比例,
3、案例介紹
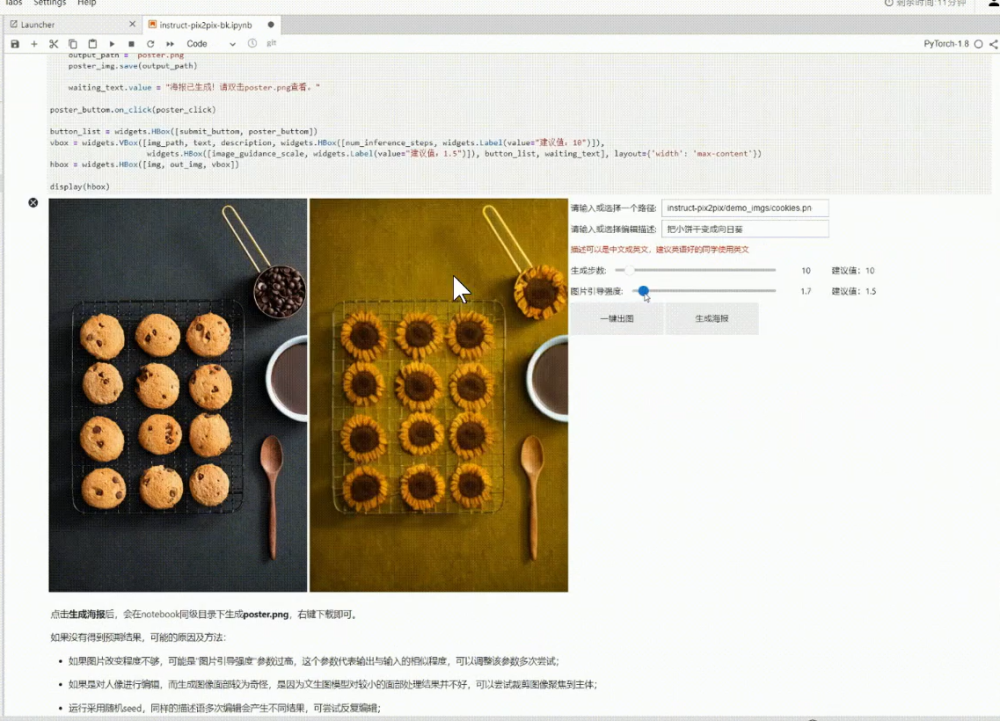
編輯命令支持中文,系統將中文翻譯為prompt,如果遇到生成的圖不好,可能是翻譯的不好,也可以直接輸入英文,同時系統支持生成海報,方便使用,
3.1 教程
體驗地址:https://developer.huaweicloud.com/develop/aigallery/notebook/detail?id=1449263e-83d2-438a-895c-dab8ab9ba5c8&ticket=ST-81479-CIrz2uuQi2uMIRcbTlzdobWR-sso
實名認證教程地址:https://developer.huaweicloud.com/develop/aigallery/article/detail?id=4ce709d6-eb25-4fa4-b214-e2e5d6b7919c
教程中有完成的介紹,這里就不贅述了
注意:
1.切換資源使會有提示,要等資源切換完成后再做操作,不要著急,
2.點擊生成海報后,會在notebook同級目錄下生成poster.png,右鍵下載即可,
3.如果沒有得到預期結果,可能的原因及方法:
? 如果圖片改變程度不夠,可能是"圖片引導強度"引數過高,這個引數代表輸出與輸入的相似程度,可以調整該引數多次嘗試;
? 如果是對人像進行編輯,而生成影像面部較為奇怪,是因為文生圖模型對較小的面部處理結果并不好,可以嘗試裁剪影像聚焦到主體;
? 運行采用隨機seed,同樣的描述語多次編輯會產生不同結果,可嘗試反復編輯;
? 使用同義但不同表述的描述語可能對結果有較大的影響,如"turn him into a dog" vs. "make him a dog" vs. "as a dog".
? 如需生成高解析度圖,請切換更高顯存的資源,同時修改應用cell中的max_size引數,
3.2 案例總結
整個案例的教程還是很清楚,也是免費的資源,開放的代碼,very good
4、總結
1. 在整個視頻講解中,首先詳細介紹了Instruct-Pix2Pix的技術架構,并與目前非常火熱的Stable Diffusion技術方案進行了比較,通過這些講解,我們可以深入了解這些技術的底層原理以及整個應用的實作細節,
2. 視頻中還演示了Model Art的使用,這是一個用于實踐這些技術的工具,在案例講解中,我們可以看到針對不同的情況進行了多個測驗案例,以展示該工具的強大功能,同時,視頻還提到了在使用程序中可能遇到的問題和挑戰,
綜上所述,整個視頻講解提供了對Instruct-Pix2Pix技術架構、Stable Diffusion技術方案以及Model Art工具的全面了解,通過案例講解和對實作細節的介紹,我們可以更好地理解和應用這些技術,同時也了解了可能面臨的挑戰和解決方案,
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/556938.html
標籤:其他
上一篇:云原生周刊:Dapr 完成模糊測驗審計 | 2023.7.10
下一篇:返回列表