1. 自動駕駛感知演算法及AidLux相關方案介紹
1.1自動駕駛
自動駕駛汽車,又稱無人駕駛車、電腦駕駛車、無人車、自駕車,是一種需要駕駛員輔助駕駛或者完全不需要操控的車輛,作為自動化載具,自動駕駛汽車可以不需要人類操作即能感知環境及導航,
1.2 自動駕駛系統的組成部分

1.2.1 環境感知系統

1.2.2 決策系統

1.3 安卓端部署平臺AidLux
AidLux平臺可快速部署在ARM64位智能設備上,手機也能變成邊緣計算設備,當服務器使用、做測驗、做練習,后續換設備落實實際專案,直接遷移,不需要重復開發,

2. 基于YOLOP的全景感知系統講解與實戰應用
2.1 YOLOP演算法介紹
YOLOP能同時處理目標檢測、可行駛區域分割、車道線檢測三個感知任務,并速度優異,保持較好精度進行作業,代碼開源,它是華中科技大學--王興剛團隊在全景感知方面提出的模型,
模型結構包括1個encoder+3個分離的decoder,其中encoder包括backbone和neck,3個decoder分別完成車輛檢測、車道線檢測、可行駛區域分割任務
encoder:主干網路(CSPDarknet),和neck結構(SPP+FPN)
decoder:1個檢測頭和2個分割,兩個分割頭都是使用FPN的最底層特征圖(w/8,h/8,256)作為輸入,進行3次最近鄰上采樣,最終輸出(W, H, 2)的特征圖,
2.2 AutoDL云端YOLOP模型訓練
2.2.1 下載BDD100K資料集
2.2.2 將專案和資料集上傳到AutoDL平臺
2.2.3 訓練YOLOP
執行命令:pip install -r requirements.txt安裝依賴包
單GPU訓練:
python tools/train.py
多GPU訓練:
python -m torch.distributed.launch --nproc_per_node=N tools/train.py #N:GPU數量
推理
python tools/demo.py --weights weights/End-to-end.pth --source inference/videos
3. 智能預警在AidLux平臺上的部署與應用
3.1 YOLOP模型onnx轉換部署
1.使用課程代碼轉換為onnx
執行命令:
python export_onnx.py --height 640 --width 640
執行完成后,會在weights檔案夾下生成轉換成功的onnx模型
onnx轉換核心api:
x = torch.onnx.export(model, # 網路模型torch.randn(1, 3, 224, 224), # 用于確定輸入大小和型別,其中的值可以是隨機的,export_onnx_file, # 輸出onnx的名稱verbose=False, # 是否以字串的形式顯示計算圖input_names=["input"], # 輸入節點的名稱,可以是一個listoutput_names=["output"], # 輸出節點的名稱opset_version=10, # onnx支持使用的operator setdo_constant_folding=True, # 是否壓縮變數# 設定動態維度, 此處指明Input節點的第0維度可變,命名為batch_sizedynamic_axes={"input":{0: "batch_size", 2:"h", 3: "w"}, "output": {0: "batch_size"}})
2. AidLux模型轉換工具-AIMO
AI Model Optimizer--AIMO, 是一個簡單、快速、精度損失小的模型轉換平臺,
AIMO旨在幫助用戶能夠在邊緣端芯片上無精度損失的快速遷移、部署和運行各種機器學習模型,
平臺地址:http://117.176.129.180:21115/
體驗賬號:AIMOTC001
賬號密碼:AIMOTC001
3.2 YOLOP模型在AidLux上部署和應用
3.2.1 AidLux簡介
AidLux是一個構建在ARM硬體上,基于創新性跨Android/鴻蒙+Linux融合系統環境的智能物聯網(AIOT應用開發和部署平臺),
AidLux軟體使用非常方便,可以安裝在手機、PAD、ARM開發板等邊緣設備上,而且使用AidLux開發的程序中,既能支持在邊緣設備的本機開發,也支持通過web瀏覽器訪問邊緣端桌面進行開發,
各大應用商城都能下載AidLux,在手機商城搜索、下載安裝AidLux,
3.2.2 連接AidLux
將手機的wifi網路和電腦的網路連接到一起,打開安裝好的手機上的AidLux軟體,點擊第一排第二個Cloud_ip,手機界面上會跳出可以在電腦上登錄的IP地址,在電腦的瀏覽器上,隨便出入一個IP,即可將手機的系統投影到電腦上,連接上后就可以利用手機的算力進行模型推理了,
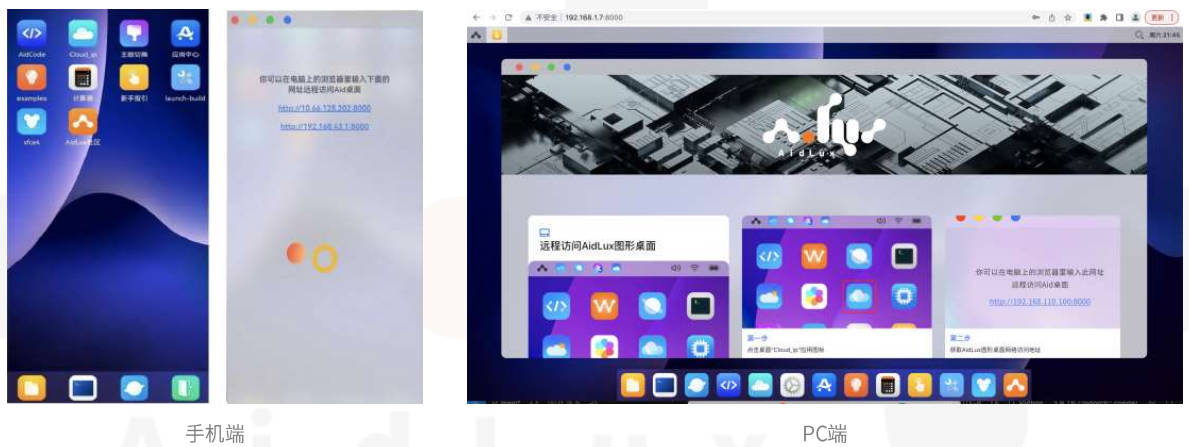
3.2.3 上傳專案代碼到AidLux
1.點擊檔案瀏覽器,打開檔案管理頁面
2.找到home檔案夾,并雙擊進入此檔案夾
3.點擊右上角往上的箭頭;再選擇Folder,將前面YOLOP的檔案夾上傳到home檔案夾內,(也可以直接將檔案夾拖進目錄下,)
3.2.4 安裝環境
1.打開終端,切換到專案目錄
2.執行命令:pip install -r requirements.txt安裝依賴環境
3.安裝pytorch、torchvision、onnxruntime
pip install torch == 1.8.1==0.9.0 -i https://pypi.mirrors.ustc.edu.cn/simple/pip install onnxruntime -i https://pypi.mirrors.ustc.edu.cn.simple/
4 運行demo.py
驗證推理效果,執行命令:
python tools/demo.py --source inference/images
3.3 智能預警系統代碼實戰
智能預警系統包含3個任務:
目標檢測,可行駛區域檢測,車道線檢測
傳感器:前視相機
目標檢測任務:檢測車輛
可行駛區域檢測:主要是hi檢測可以行駛的區域,為自動駕駛提供路徑規劃輔助
車道線檢測:一種環境感知應用,目的是通過車載相機或激光雷達來檢測車道線,
智能預警流程
1.輸入
讀取視頻影像作為輸入,影像尺寸1920*1080
2.預處理
2.1 將輸入尺寸1920*1080 resize + padding到640*640
2.2 歸一化
2.3 640*640*3 --> 1*3*640*640
3. 使用onnx模型進行推理
讀取模型-->準備資料-->推理
得到det_out,da_seg_out, ll_seg_out,shape分別為:(1,n,6) (1,2,640,640) (1,2,640,640)
4.后處理
4.1 將檢測結果,可行駛區域檢測結果,車道線檢測結果,合并到一張影像上,分別用不同的顏色標記出來
4.2 將檢測的幀數,幀率,車輛數等資訊顯示在影像上
5.輸出
獲取最終融合的影像,并保存成視頻,影像尺寸、幀率、編碼是原視頻尺寸、幀率和編碼,
完整的預警代碼
import cv2import timeimport torchimport numpy as npimport onnxruntime as ortfrom PIL import Image, ImageDraw, ImageFontfrom lib.core.general import non_max_suppression
onnx_path = "weights/yolop-640-640.onnx"
def resize_unscale(img, new_shape=(640, 640), color=114):shape = img.shape[:2] # current shape [height, width]if isinstance(new_shape, int):new_shape = (new_shape, new_shape)
canvas = np.zeros((new_shape[0], new_shape[1], 3))canvas.fill(color)# Scale ratio (new / old) new_shape(h,w)r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
# Compute paddingnew_unpad = int(round(shape[1] * r)), int(round(shape[0] * r)) # w,hnew_unpad_w = new_unpad[0]new_unpad_h = new_unpad[1]pad_w, pad_h = new_shape[1] - new_unpad_w, new_shape[0] - new_unpad_h # wh padding
dw = pad_w // 2 # divide padding into 2 sidesdh = pad_h // 2
if shape[::-1] != new_unpad: # resizeimg = cv2.resize(img, new_unpad, interpolation=cv2.INTER_AREA)
canvas[dh:dh + new_unpad_h, dw:dw + new_unpad_w, :] = img
return canvas, r, dw, dh, new_unpad_w, new_unpad_h # (dw,dh)
def cv2AddChineseText(img, text, position, textColor=(0, 0, 255), textSize=10):if (isinstance(img, np.ndarray)): # 判斷是否OpenCV圖片型別img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))# 創建一個可以在給定影像上繪圖的物件draw = ImageDraw.Draw(img)# 字體的格式fontStyle = ImageFont.truetype("simsun.ttc", textSize, encoding="utf-8")# 繪制文本draw.text(position, text, textColor, font=fontStyle)# 轉換回OpenCV格式return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
def infer(ori_img, img, r, dw, dh, new_unpad_w, new_unpad_h):ort_session = ort.InferenceSession(onnx_path)t0 = time.time()# inference: (1,n,6) (1,2,640,640) (1,2,640,640)det_out, da_seg_out, ll_seg_out = ort_session.run(['det_out', 'drive_area_seg', 'lane_line_seg'],input_feed={"images": img})seconds = time.time() - t0fps = "%.2f fps" %(1 / seconds) # 幀率
det_out = torch.from_numpy(det_out).float()boxes = non_max_suppression(det_out)[0] # [n,6] [x1,y1,x2,y2,conf,cls]boxes = boxes.cpu().numpy().astype(np.float32)if boxes.shape[0] == 0:print("no bounding boxes detected.")return None# scale coords to original size.boxes[:, 0] -= dwboxes[:, 1] -= dhboxes[:, 2] -= dwboxes[:, 3] -= dhboxes[:, :4] /= rprint(f"detect {boxes.shape[0]} bounding boxes.")
img_det = ori_img[:, :, ::-1].copy()for i in range(boxes.shape[0]):x1, y1, x2, y2, conf, label = boxes[i]x1, y1, x2, y2, label = int(x1), int(y1), int(x2), int(y2), int(label)img_det = cv2.rectangle(img_det, (x1, y1), (x2, y2), (0, 255, 0), 2, 2)
# select da & ll segment area.da_seg_out = da_seg_out[:, :, dh:dh + new_unpad_h, dw:dw + new_unpad_w]ll_seg_out = ll_seg_out[:, :, dh:dh + new_unpad_h, dw:dw + new_unpad_w]
da_seg_mask = np.argmax(da_seg_out, axis=1)[0]ll_seg_mask = np.argmax(ll_seg_out, axis=1)[0]
color_area = np.zeros((new_unpad_h, new_unpad_w, 3), dtype=np.uint8)color_area[da_seg_mask == 1] = [0, 255, 0]color_area[ll_seg_mask == 1] = [0, 0, 255]color_seg = color_area
return img_det, boxes, color_seg, fps
def main(source, save_path):cap = cv2.VideoCapture(source)width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) # 獲取視頻的寬度height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) # 獲取視頻的高度fps = cap.get(cv2.CAP_PROP_FPS) # fourcc = cv2.VideoWriter_fourcc(*"mp4v")#fourcc = int(cap.get(cv2.CAP_PROP_FOURCC)) # 視頻的編碼#定義視頻物件輸出writer = cv2.VideoWriter(save_path, fourcc, fps, (width, height))
# 檢查是否匯入視頻成功if not cap.isOpened():print("視頻無法打開")exit()
frame_id = 0while True:ret, frame = cap.read()if not ret:print("視頻推理完畢...")break
frame_id += 1# if frame_id % 3 != 0:# continuecanvas, r, dw, dh, new_unpad_w, new_unpad_h = resize_unscale(frame, (640, 640))img = canvas.copy().astype(np.float32) # (3,640,640) RGBimg /= 255.0img[:, :, 0] -= 0.485img[:, :, 1] -= 0.456img[:, :, 2] -= 0.406img[:, :, 0] /= 0.229img[:, :, 1] /= 0.224img[:, :, 2] /= 0.225img = img.transpose(2, 0, 1)[]() img = np.expand_dims(img, 0) # (1, 3,640,640)
# 推理img_det, boxes, color_seg, fps = infer(frame, img, r, dw, dh, new_unpad_w, new_unpad_h)if img_det is None:continue
color_mask = np.mean(color_seg, 2)img_merge = canvas[dh:dh + new_unpad_h, dw:dw + new_unpad_w, :]
# merge: resize to original sizeimg_merge[color_mask != 0] = \img_merge[color_mask != 0] * 0.5 + color_seg[color_mask != 0] * 0.5img_merge = img_merge.astype(np.uint8)img_merge = cv2.resize(img_merge, (width, height),interpolation=cv2.INTER_LINEAR)img_merge = cv2AddChineseText(img_merge, f'幀數:{frame_id} 幀率:{fps} 前方共有 {boxes.shape[0]} 輛車...', (100, 50), textColor=(0, 0, 255), textSize=30)img_merge = cv2AddChineseText(img_merge, '前方綠色區域為可行駛區域,紅色為檢出的車道線...',(100, 100), textColor=(0, 0, 255), textSize=30)
for i in range(boxes.shape[0]):x1, y1, x2, y2, conf, label = boxes[i]x1, y1, x2, y2, label = int(x1), int(y1), int(x2), int(y2), int(label)img_merge = cv2.rectangle(img_merge, (x1, y1), (x2, y2), (0, 255, 0), 2, 2)
# cv2.imshow('img_merge', img_merge)# cv2.waitKey(0)writer.write(img_merge)
cap.release() # 釋放攝像頭writer.release() # 可以實作預覽cv2.destroyAllWindows()
if __name__=="__main__":source = 'inference/videos/1.mp4'save_path = '/home/AidLux_Course/YOLOP/inference/output/test.mp4'main(source, save_path)
代碼運行結果:
4.總結
感謝成都阿加犀公司舉辦的訓練營課程,讓筆者能夠學習自動駕駛的基礎知識,以及自動駕駛演算法在移動端的部署,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/556951.html
標籤:其他
上一篇:共探AI大模型時代下的挑戰與機遇,華為云HCDE與大模型專家面對面
下一篇:返回列表