
目錄示例代碼托管在:http://www.github.com/dashnowords/blogs
博客園地址:《大史住在大前端》原創博文目錄
華為云社區地址:【你要的前端打怪升級指南】
- 一. PCM格式是什么
- 二. 瀏覽器中的音頻采集處理
- 三. 需求實作
- 方案1——服務端FFmpeg實作編碼
- 方案2——ScriptProcessorNode手動處理資料流
- 參考文獻
本文中最重要的資訊:32為浮點數表示
16bit位深資料時是用-1+1的小數來表示16位的-32768+32767的!翻遍了MDN都沒找到解釋,我的內心很崩潰!
最近不少朋友需要在專案中對接百度語音識別的REST API介面,在讀了我之前寫的【Recorder.js+百度語音識別】全堆疊方案技術細節一文后仍然對Web音頻采集和處理的部分比較困惑,本文僅針對音頻流處理的部分進行解釋,全堆疊實作方案的技術要點,可以參見上面的博文,本篇不再贅述,
一. PCM格式是什么
百度語音官方檔案對于音頻檔案的要求是:
pcm,wav,arm及小程式專用的m4a格式,要求引數為16000采樣率,16bit位深,單聲道,
PCM編碼,全稱為"脈沖編碼調制",是一種將模擬信號轉換成數字信號的方法,模擬信號通常指連續的物理量,例如溫度、濕度、速度、光照、聲響等等,模擬信號在任意時刻都有對應的值;數字信號通常是模擬信號經過采樣、量化和編碼等幾個步驟后得到的,
比如現在麥克風采集到了一段2秒的音頻模擬信號,它是連續的,我們有一個很菜的聲卡,采集頻率為10Hz,那么經過采樣后就得到了20個離散的資料點,這20個點對應的聲音值可能是各種精度的,這對于存盤和后續的使用而言都不方便,此時就需要將這些值也離散化,比如在上例中,信號的范圍是052dB,假設我們希望將063dB的值都以整數形式記錄下來,如果采用6個bit位來存盤,那么就可以識別(26-1=63)個數值,這樣采集的信號通過四舍五入后都以整數形式保存就可以了,最小精度為1dB;如果用7個`bit`位來保存,可存盤的不同數值個數為(27-1=127)個,如果同樣將0~63dB映射到這個范圍上的話,那么最小精度就是0.5dB,很明顯這樣的處理肯定是有精度損失的,使用的位數越多精度越高,計算機中自然需要使用8的整數倍的bit位來進行存盤,經過上述處理后資料就被轉換成了一串0和1組成的序列,這樣的音頻資料是沒有經過任何壓縮編碼處理的,也被稱為“裸流資料”或“原始資料”,從上面的示例中很容易看出,用10Hz的采樣率,8bit位存盤采樣點數值時,記錄2秒的資料一共會產生2X10X8 = 160個bit位,而用16bit位來存盤采樣點資料時,記錄1秒的資料也會產生1X10X16 = 160個bit位,如果沒有任何附加的說明資訊,就無法知道這段資料到底該怎么使用,按照指定要求進行編碼后得到的序列就是pcm資料,它在使用之前通常需要宣告采集相關的引數,
下圖就是一段采樣率為10Hz,位深為3bit的pcm資料,你可以直觀地看到每個步驟所做的作業,

wav格式也是一種無損格式,它是依據規范在pcm資料前添加44位元組長度用來填充一些宣告資訊的,wav格式可以直接播放,而百度語音識別介面中后兩種格式都需要經過編碼演算法處理,通常會有不同程度的精度損失和體積壓縮,所以在使用后兩種資料時必然會存在額外的編解碼時間消耗,所以不難看出,各種格式之間的選擇其實就是對時間和空間的權衡,
二. 瀏覽器中的音頻采集處理
瀏覽器中的音頻處理涉及到許多
API的協作,相關的概念比較多,想要對此深入了解的讀者可以閱讀MDN的【Web 媒體技術】篇,本文中只做大致介紹,
首先是實作媒體采集的WebRTC技術,使用的舊方法是navigator.getUserMedia( ),新方法是MediaDevices.getUserMedia( ),開發者一般需要自己做一下兼容處理,麥克風或攝像頭的啟用涉及到安全隱私,通常網頁中會有彈框提示,用戶確認后才可啟用相關功能,呼叫成功后,回呼函式中就可以得到多媒體流物件,后續的作業就是圍繞這個流媒體展開的,
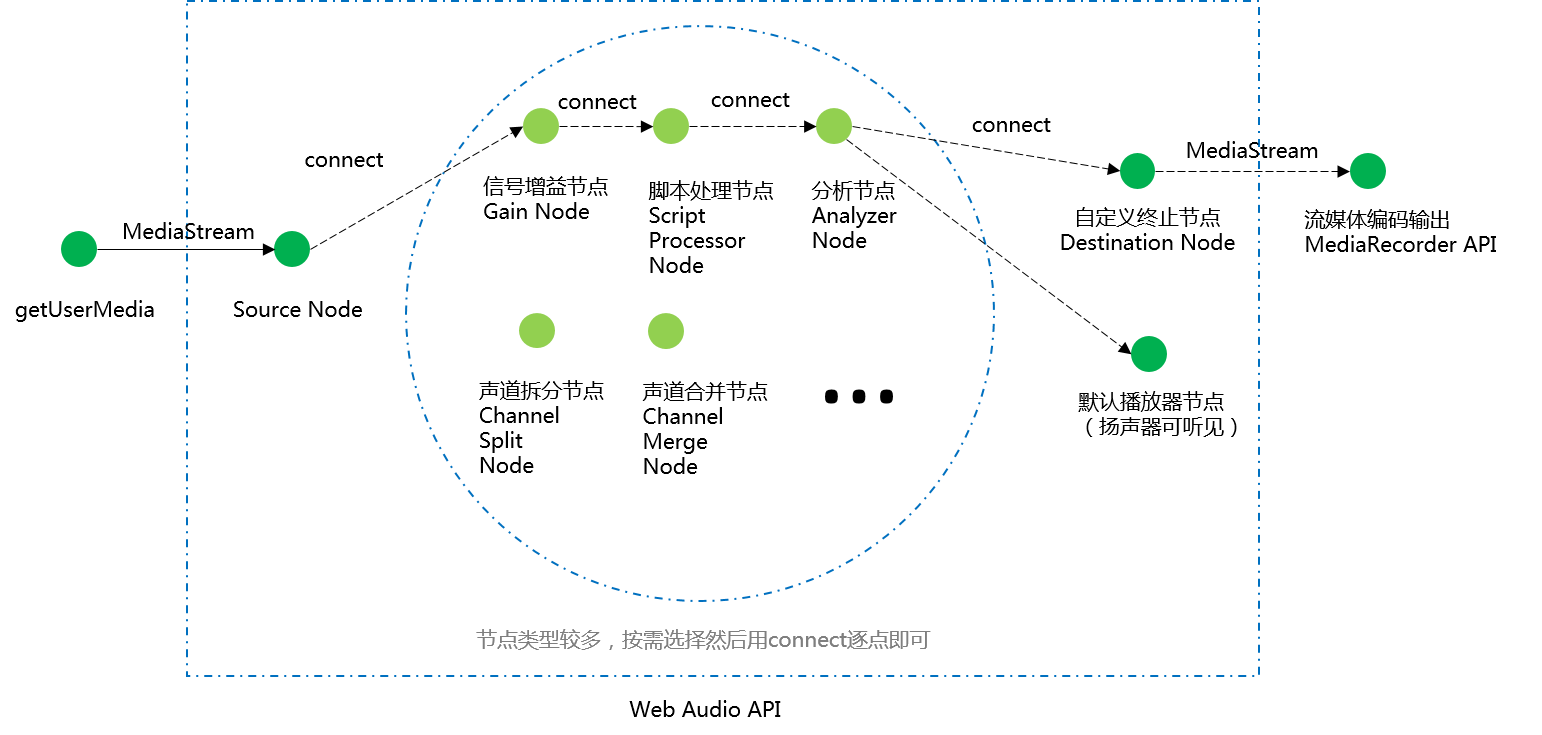
瀏覽器中的音頻處理的術語稱為AudioGraph,其實就是一個【中間件模式】,你需要創建一個source節點和一個destination節點,然后在它們之間可以連接許許多多不同型別的節點,source節點既可以來自流媒體物件,也可以自己填充生成,destination可以連接默認的揚聲器端點,也可以連接到媒體錄制APIMediaRecorder來直接將pcm資料轉換為指定媒體編碼格式的資料,中間節點的型別有很多種,可實作的功能也非常豐富,包括增益、濾波、混響、聲道的合并分離以及音頻可視化分析等等非常多功能(可以參考MDN中給出的AudioContext可創建的不同型別節點),當然想要熟練使用還需要一些信號處理方面的知識,對于非工科背景的開發者而言并不容易學習,
三. 需求實作
一般的實作方法是從getUserMedia方法得到原始資料,然后根據相關引數手動進行后處理,相對比較繁瑣,
方案1——服務端FFmpeg實作編碼
很多示例都是將音頻源節點直接連接到默認的輸出節點(揚聲器)上,但是幾乎沒什么意義,筆者目前還沒有找到使用Web Audio API自動輸出pcm原始采樣資料的方法,可行的方法是使用MediaRecorder來錄制一段音頻流,但是錄制實體需要傳入編碼相關的引數并指定MIME型別,最終得到的blob物件通常是經過編碼后的音頻資料而非pcm資料,但也因為經過了編碼,這段原始資料的相關引數也就已經存在于輸出后的資料中了,百度語音官方檔案推薦的方法是使用ffmpeg在服務端進行處理,盡管明顯在音頻的編解碼上繞了彎路,但肯定比自己手動編碼難度要低得多,而且ffmepg非常強大,后續擴展也方便,參考資料大致從錄音結束到回傳結果,PC端耗時約1秒,移動端約2秒,
核心示例代碼(完整示例見附件或開頭的github代碼倉):
//WebRTC音頻流采集
navigator.mediaDevices.getUserMedia({audio:true})
.then((stream) => {
//實體化音頻處理背景關系
ac = new AudioContext({
sampleRate:16000 //設定采樣率
});
//創建音頻處理的源節點
let source = ac.createMediaStreamSource(stream);
//創建音頻處理的輸出節點
let dest = ac.createMediaStreamDestination();
//直接連接
source.connect(dest);
//生成針對音頻輸出節點流資訊的錄制實體,如果不通過ac實體調節采樣率,也可以直接將stream作為引數
let mediaRecorder = window.mediaRecorder = new MediaRecorder(dest.stream, {
mimeType: '',//chreome中的音軌默認使用格式為audio/webm;codecs=opus
audioBitsPerSecond: 128000
});
//給錄音機系結事件
bindEventsForMediaRecorder(mediaRecorder);
})
.catch(err => {
console.log(err);
});
錄音機事件系結:
//給錄音機系結事件
function bindEventsForMediaRecorder(mediaRecorder) {
mediaRecorder.addEventListener('start', function (event) {
console.log('start recording!');
});
mediaRecorder.addEventListener('stop', function (event) {
console.log('stop recording!');
});
mediaRecorder.addEventListener('dataavailable', function (event) {
console.log('request data!');
console.log(event.data);//這里拿到的blob物件就是編碼后的檔案,既可以本地試聽,也可以傳給服務端
//用a標簽下載;
createDownload(event.data);
//用audio標簽加載
createAudioElement(event.data);
});
}
本地測驗時,可以將生成的音頻下載到本地,然后使用ffmpeg將其轉換為目標格式:
ffmpeg -y -i record.webm -f s16le -ac 1 -ar 16000 16k.pcm
詳細的引數說明請移步ffmpeg documentation,至此就得到了符合百度語音識別介面的錄音檔案,
方案2——ScriptProcessorNode手動處理資料流
如果覺得使用ffmpeg有點“殺雞用牛刀”的感覺,那么就需要自己手動處理二進制資料了,這是就需要在audioGraph中添加一個腳本處理節點scriptProcessorNode,按照MDN的資訊該介面未來會廢棄,用新的Audio Worker API取代,但目前chrome中的情況是,Audio Worker API標記為試驗功能,而舊的方法也沒有明確的提示說明會移除(通常計劃廢除的功能,控制臺都會有黃色字體的提示),但無論如何,相關的基本原理是一致的,
scriptProcessorNode節點使用一個緩沖區來分段存盤流資料,每當流資料填充滿緩沖區后,這個節點就會觸發一個audioprocess事件(相當于一段chunk),在回呼函式中可以獲取到該節點輸入信號和輸出信號的記憶體位置指標,然后通過手動操作就可以進行資料處理了,
先來看一個簡單的例子,下面的示例中,處理節點什么都不做,只是把單聲道輸入流直接拷貝到輸出流中:
navigator.mediaDevices.getUserMedia(constraints)
.then((stream) => {
ac = new AudioContext({
sampleRate:16000
});
let source = ac.createMediaStreamSource(stream);
//構造引數依次為緩沖區大小,輸入通道數,輸出通道數
let scriptNode = ac.createScriptProcessor(4096, 1, 1);
//創建音頻處理的輸出節點
let dest = ac.createMediaStreamDestination();
//串聯連接
source.connect(scriptNode);
scriptNode.connect(dest);
//添加事件處理
scriptNode.onaudioprocess = function (audioProcessingEvent) {
//輸入流位置
var inputBuffer = audioProcessingEvent.inputBuffer;
//輸出流位置
var outputBuffer = audioProcessingEvent.outputBuffer;
//遍歷通道處理資料,當前只有1個輸入1個輸出
for (var channel = 0; channel < outputBuffer.numberOfChannels; channel++) {
var inputData = https://www.cnblogs.com/dashnowords/p/inputBuffer.getChannelData(channel);
var outputData = outputBuffer.getChannelData(channel);
//用按鈕控制是否記錄流資訊
if (isRecording) {
for (let i = 0; i < inputData.length; i = i + 1) {
//直接將輸入的資料傳給輸出通道
outputData[i] = inputData[i];
}
}
};
}
在上面的示例加工后,如果直接將結果連接到ac.destination(默認的揚聲器節點)就可以聽到錄制的聲音,你會聽到輸出信號只是重復了一遍輸入信號,
但是將資料傳給
outputData輸出后是為了在后續的節點中進行處理,或者最終作為揚聲器或MediaRecorder的輸入,傳出后就無法拿到pcm資料了,所以只能自己來假扮一個MediaRecorder,
首先在上面示例中向輸出通道透傳資料時,改為自己存盤資料,將輸入資料列印在控制臺后可以看到緩沖區大小設定為4096時,每個chunk中獲取到的輸入資料是一個長度為4096的Float32Array定型陣列,也就是說每個采樣點資訊是用32位浮點來存盤的,【recorder.js】給出的轉換方法如下:
function floatTo16BitPCM(output, offset, input) {
for (let i = 0; i < input.length; i++, offset += 2) {
let s = Math.max(-1, Math.min(1, input[i]));
output.setInt16(offset, s < 0 ? s * 0x8000 : s * 0x7FFF, true);
}
}
看起來的確是不知道在干嘛,后來參考文獻中找到了相關解釋:
32位存盤的采樣幀數值,是用
-1到1來映射16bit存盤范圍-32768~32767的,
現在再來看上面的公式就比較容易懂了:
//下面一行代碼保證了采樣幀的值在-1到1之間,因為有可能在多聲道合并或其他狀況下超出范圍
let s = Math.max(-1, Math.min(1, input[i]));
//將32位浮點映射為16位整形表示的值
output.setInt16(offset, s < 0 ? s * 0x8000 : s * 0x7FFF, true);
如果s>0其實就是將01映射到到032767,正數第一位符號位為0,所以32767對應的就是0111 1111 1111 1111也就是0x7FFF,直接把s當系數相乘就可以了;當s為負數時,需要將0-1映射到0-32768,所以s的值也可以直接當做比例系數來進行轉換計算,負數在記憶體中存盤時需要使用補碼,補碼是原碼除符號位以外按位取反再+1得到的,所以-32768原碼是1000 0000 0000 0000(溢位的位直接丟棄),除符號位外按位取反得到1111 1111 1111 1111,最后再+1運算得到1000 0000 0000 0000(溢位的位也直接丟棄),用16進制表示就是0x8000,順便多說一句,補碼的存在是為了讓正值和負值在二進制形態上相加等于0,
公式里的output很明顯是一個ES6-ArrayBuffer中的DataView視圖,用它可以實作混合形式的記憶體讀寫,最后的true表示小端系統讀寫,對這一塊知識不太熟悉的讀者可以閱讀阮一峰前輩的ES6指南(前端必備工具書)進行了解,
參考文獻
how-to-convert-between-most-audio-formats-in-net,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/176542.html
標籤:JavaScript
上一篇:前后端分離專案一臺服務器上線