為什么需要復雜度分析
我們可以把代碼跑一遍,然后通過一些工具來統計、監控就能得到演算法執行的時間和占用的記憶體大小,為什么還要做時間、空間復雜度分析呢?這種分析方法能比我實實在在跑一遍得到的資料更準確嗎?
首先,肯定的說這種評估演算法執行效率的方法是正確的,很多資料結構和演算法書籍還給這種方法起了一個名字,叫事后統計法,但是這種統計方法存在一定的局限性,
1、測驗結果依賴測驗的環境以及資料規模的影響
比如,我們拿同樣一段代碼,再不同的機器以及不同的資料規模可能會有不同的結果,
2、掌握復雜度分析,將能撰寫出性能更優的代碼
所以我們需要一個不用具體的測驗環境、測驗資料來測驗,就可以粗略地估計演算法的執行效率的方法,這就是我們需要的時間、空間復雜度分析方法,
復雜度分析提供了一個粗略的分析模型,與實際的性能測驗并不沖突,更不會浪費太多時間,重點在于在編程時,要具有這種復雜度分析的思維,有助于產出效率高的代碼,
大 O 復雜度表示法
演算法的執行效率,簡單的說就是代碼執行的時間,但是怎么樣在不運行代碼的情況下,用“肉眼”得到一段代碼的執行時間呢?這里有段非常簡單的代碼,求 1,2,3...n 的累加和,現在來估算一下這段代碼的執行時間,
1 function countSum(n) { 2 let sum = 0; 3 console.log(n) 4 for (i = 0; i <= n; ++i) { 5 sum = sum + i; 6 } 7 return sum; 8 }
每行代碼對應的 CPU 執行的個數、執行的時間都不一樣,所以只是粗略估計,我們可以假設每行代碼執行的時間都一樣為 unit_time,在這個假設的基礎之上,這段代碼的總執行時間是多少呢?
第 2、3 行代碼分別需要 1 個 unit_time 的執行時間,第 4、5 行都運行了 n 遍,所以需要 2n * unit_time 的執行時間,所以這段代碼總的執行時間就是 (2n+2) * unit_time,
盡管我們不知道 unit_time 的具體值,但是通過代碼執行時間的推導程序,我們可以得到一個非常重要的規律,那就是所有代碼的執行時間 T(n) 與代碼的執行次數 f(n) 成正比,
我們可以把這個規律總結成一個公式,這個公式就是資料結構書上說的大O表示法,
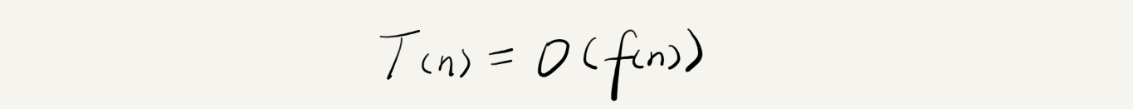
我來具體解釋一下這個公式:
- T(n) 表示代碼執行的時間
- n 表示資料規模的大小
- f(n) 表示代碼執行的次數總和
因為這是一個公式,所以用 f(n) 來表示,公式中的 O,表示代碼的執行時間 T(n) 與 f(n) 運算式成正比,
所以,上面例子中的 T(n) = O(2n+2),這就是大 O 時間復雜度表示法,大 O 時間復雜度實際上并不具體表示代碼真正的執行時間,而是表示代碼執行時間隨資料規模增長的變化趨勢,所以,也叫作漸進時間復雜度(asymptotic time complexity),簡稱時間復雜度,
時間復雜度分析
分析大O一般的步驟如下:
- 用常數1代替運行中的所有的加法常數 n + 2 + 3 + 4 等于 n + 1
- 在修改后的運行次數函式中,只保留最高階項 如 n^3 + n^2 等于 n^3
- 如果最高階項存在且不為1,則去掉與這個項相乘的常數 如 3n^2 等于 n^2
通過上面三個步驟可以總結出幾個方法
1. 只關注回圈執行次數最多的一段代碼
大 O 這種復雜度表示方法只是表示一種變化趨勢,通過上面的公式我們會忽略掉公式中的常量、低階、系數,只需要記錄一個最大階的量級,所以我們在分析一個演算法、一段代碼的時間復雜度的時候,也只關注回圈執行次數最多的那一段代碼就可以了,這段核心代碼執行次數的 n 的量級,就是整段要分析代碼的時間復雜度,
2.加法法則:總復雜度等于量級最大的那段代碼的復雜度
如果是很長的一個代碼段,可以把他們拆分計算時間復雜度,然后再加起來
1 function countSum(n) { 2 let sum_1 = 0; 3 console.log('計算:sum_1') 4 for (let p = 0; p < 100; ++p) { 5 sum_1 = sum_1 + p; 6 } 7 8 let sum_2 = 0; 9 console.log('計算:sum_2') 10 for (let q = 0; q < n; ++q) { 11 sum_2 = sum_2 + q; 12 } 13 14 let sum_3 = 0; 15 console.log('計算:sum_3') 16 for (let i = 0; i <= n; ++i) { 17 j = 1; 18 for (let j = 0; j <= n; ++j) { 19 sum_3 = sum_3 + i * j; 20 } 21 } 22 23 return sum_1 + sum_2 + sum_3; 24 }
這個代碼分為三部分,分別是求 sum_1、sum_2、sum_3,我們可以分別分析每一部分的時間復雜度,然后把相加,再取一個量級最大的作為整段代碼的復雜度,
第一段的時間復雜度是多少呢?這段代碼回圈執行了 100 次,所以是一個常量的執行時間,跟 n 的規模無關,強調一下,即便這段代碼回圈 10000 次、100000 次,只要是一個已知的數,跟 n 無關,照樣也是常量級的執行時間,當 n 無限大的時候,就可以忽略,盡管對代碼的執行時間會有很大影響,但是回到時間復雜度的概念來說,它表示的是一個演算法執行效率與資料規模增長的變化趨勢,所以不管常量的執行時間多大,我們都可以忽略掉,因為它本身對增長趨勢并沒有影響,
那第二段代碼和第三段代碼的時間復雜度應該很容易分析出來是 O(n) 和 O(n^2),
綜合這三段代碼的時間復雜度,我們取其中最大的量級,所以,整段代碼的時間復雜度就為 O(n^2),也就是說:總的時間復雜度就等于量級最大的那段代碼的時間復雜度,
3.乘法法則:嵌套代碼的復雜度等于嵌套內外代碼復雜度的乘積
假設有一個嵌套的回圈,我們把第一層回圈叫T1,那么T1(n)=O(f(n)),第二層回圈叫T2,那么T2(n)=O(g(n)),總共時間 T(n)=T1(n)*T2(n) = O(f(n))*O(g(n))= O(f(n) * g(n))
假設 T1(n) = O(n),T2(n) = O(n^2),則 T1(n) * T2(n) = O(n^3),在具體的代碼上,我們可以把乘法法則看成是嵌套回圈
如上面計算sum_3的代碼段 兩個回圈為O(n^2),
常見時間復雜度實體分析

O(1)
O(1) 只是常量級時間復雜度的一種表示方法,并不是指只執行了一行代碼,比如這段代碼,即便有 3 行,它的時間復雜度也是 O(1),而不是 O(3),
1 const i = 8; 2 const j = 6; 3 const sum = i + j;
只要代碼的執行時間不隨 n 的增大而增長,這樣代碼的時間復雜度我們都記作 O(1),或者說,一般情況下,只要演算法中不存在回圈陳述句、遞回陳述句,即使有成千上萬行的代碼,其時間復雜度也是Ο(1),
O(logn)
對數階時間復雜度非常常見,如
1 i=1; 2 while (i <= n) { 3 i = i * 2; 4 }
根據說的復雜度分析方法,第三行代碼是回圈執行次數最多的,所以,我們只要能計算出這行代碼被執行了多少次,就能知道整段代碼的時間復雜度,從代碼中可以看出,變數 i 的值從 1 開始取,每回圈一次就乘以 2,當大于 n 時,回圈結束,實際上變數 i 的取值就是一個等比數列,如果我把它一個一個列出來,就應該是這個樣子的:

所以,我們只要知道 x 值是多少,就知道這行代碼執行的次數了,通過 2x=n 求解 x 這個問題我們想高中應該就學過了,我就不多說了,x=log2n,所以,這段代碼的時間復雜度就是 O(log2n),
O(n)
O(n)級別有個非常顯著的特征就,它會存在一個回圈,且回圈的次數是和n相關
1 function countSum (n) { 2 let sum = 0 3 for (let i = 0; i < n; i++) { 4 sum += i 5 } 6 }
O(n^2)
O(n^2)級別的有雙重回圈
function countSum (n) { let sum = 0 for (let i = 0; i < n; i++) { sum += i for (let J = 0; J < n; i++) { // do some thing } } }
不是所有的雙重回圈都是n^2
1 function countSum (n, m) { 2 let sum = 0 3 for (let i = 0; i < n; i++) { 4 sum += i 5 for (let J = 0; J < m; i++) { 6 // do some thing 7 } 8 } 9 }
這種是由兩個資料規模n、m來決定的時間復雜度,所以是O(n * m),關鍵還是要分析嵌套的回圈跟外面那層回圈的關系,
時間復雜度耗費時間從小到大依次排列
O(1) < O(logn) < O(n) < O(nlogn) < O(n2) < O(n3) < O(2n) < O(n!) < O(nn)
常見排序演算法對應的時間復雜度
| 排序方法 | 時間復雜度(平均) | 時間復雜度(最壞) | 時間復雜度(最好) | 空間復雜度 | 穩定性 | 復雜性 |
|---|---|---|---|---|---|---|
| 直接插入排序 | O(n2)O(n2) | O(n2)O(n2) | O(n)O(n) | O(1)O(1) | 穩定 | 簡單 |
| 希爾排序 | O(nlog2n)O(nlog2n) | O(n2)O(n2) | O(n)O(n) | O(1)O(1) | 不穩定 | 較復雜 |
| 直接選擇排序 | O(n2)O(n2) | O(n2)O(n2) | O(n2)O(n2) | O(1)O(1) | 不穩定 | 簡單 |
| 堆排序 | O(nlog2n)O(nlog2n) | O(nlog2n)O(nlog2n) | O(nlog2n)O(nlog2n) | O(1)O(1) | 不穩定 | 較復雜 |
| 冒泡排序 | O(n2)O(n2) | O(n2)O(n2) | O(n)O(n) | O(1)O(1) | 穩定 | 簡單 |
| 快速排序 | O(nlog2n)O(nlog2n) | O(n2)O(n2) | O(nlog2n)O(nlog2n) | O(nlog2n)O(nlog2n) | 不穩定 | 較復雜 |
| 歸并排序 | O(nlog2n)O(nlog2n) | O(nlog2n)O(nlog2n) | O(nlog2n)O(nlog2n) | O(n)O(n) | 穩定 | 較復雜 |
| 基數排序 | O(d(n+r))O(d(n+r)) | O(d(n+r))O(d(n+r)) | O(d(n+r))O(d(n+r)) | O(n+r)O(n+r) | 穩定 | 較復雜 |
空間復雜度
時間復雜度的全稱是漸進時間復雜度,表示演算法的執行時間與資料規模之間的增長關系,同理,空間復雜度全稱就是漸進空間復雜度(asymptotic space complexity),表示演算法的存盤空間與資料規模之間的增長關系,空間復雜度分析跟時間復雜度類似,
1 function run (n) { 2 let name = 'joel' 3 let step= 2 4 const arr = [] 5 6 for (let i = 0; i < n; i++) { 7 arr.push(i * step) 8 } 9 }
再第4行代碼我們初始化一個陣列,再第7行代碼對這個陣列進行push 操作,這個回圈是依賴外部的n,所以這個空間復雜度為 O(n),我們常見的空間復雜度就是 O(1)、O(n)、O(n2 )
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/275362.html
標籤:其他