目錄:https://www.cnblogs.com/onsummer/p/12799366.html
1 可擴展的格式
繼承自 glTF 的可擴展性,3dTiles 在定義上也留下了可擴展的余地,包括但不局限于:優化幾何資料的存盤,擴展屬性資料等,
2 官方當前的兩種擴展
- 層級屬性
- 點云的 draco 壓縮
下面,將簡單介紹這兩個擴展,
3 以 “b3dm 型別的瓦片屬性資訊” 引入
b3dm 瓦片的屬性資訊寫在批次表(batchtable) 中,b3dm 中每個獨立的模型,叫做
batch,(等價于要素表中的要素)這個概念引申自圖形編程,意思是“一次性向圖形處理器(GPU)發送的資料”,即批次,一個 b3dm 瓦片有多少個batch(有多少個要素),是由要素表的 JSON 表頭中的BATCH_LENGTH屬性記錄的,而批次表(batchtable)的每個屬性資料長度,都與這個
BATCH_LENGTH相等,
以上是 03 篇與 04 篇的回顧,
批次表記錄屬性資料是有缺陷的,
- 第一,對字串、布林值等非數字型資料的支持較差,只能記錄在批次表JSON頭,二進制體無法記錄非數字型資料;
- 第二,也就是此擴展重點解決的問題,當
batch之間存在邏輯分層、從屬關系時,如何記錄它們的層級屬性資料的問題
3.1 區分每一個頂點是誰
此小節需要對 glTF 格式規范比較熟悉,知道“頂點屬性”的概念,知道 WebGL 的幀快取技術,
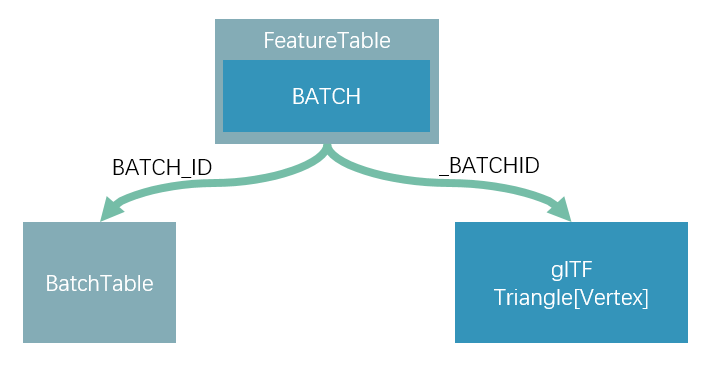
b3dm 瓦片內置的 glTF 模型中,每個 primitive 的 attribute,也即頂點屬性中會加上一個新的屬性,與 POSITION、UV0 等并列,叫做 _BATCHID,
這樣,通過 _BATCHID,使用 WebGL 中的幀快取技術,在 FBO 上繪制 _BATCHID 的顏色附件,即可完成快速查詢,
要素表通過 BATCH_ID 訪問 批次表里的屬性資料,幾何資料(glTF 中的 vertex)通過 _BATCHID 系結要素,
3.2 不同模型要素有不同的屬性怎么辦
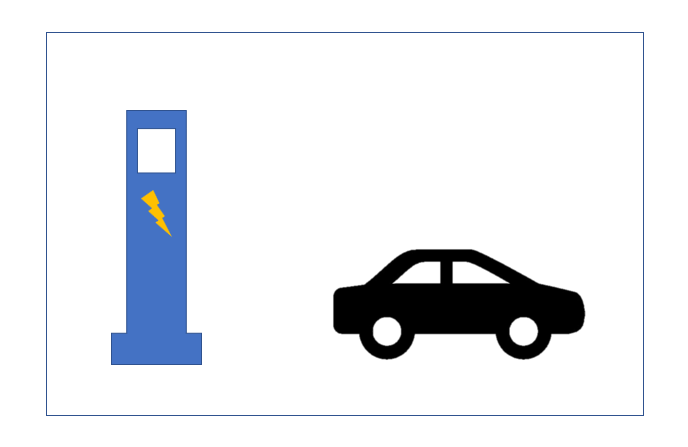
假設有這么一塊空間范圍,歸屬在 0.b3dm 瓦片內,瓦片的 glTF 模型擁有兩個 BATCH,即兩個要素,為了方便觀察,不妨具象化:
-
空間范圍 = 一個停車場
-
BATCH1 = 充電樁
-
BATCH2 = 電動汽車
如下圖所示:
現在,我用一個簡單的 JSON 來描述這兩個要素的屬性資料:
{
"Charger": {
"Price": 0.5,
"DeviceId": "abcdefg123"
},
"Car": {
"Brand": "Tesla",
"Owner": "Jacky"
}
}
這樣的資料不符合原生批次表的存盤邏輯,即每個 batch 的屬性名稱應完全一致,
顯然,充電樁的 Price(就是單價)、DeviceId 和車子的 Brand(品牌)、Owner 并不是一樣的,
如果用這個擴展來表示,在批次表的 JSON 中將會是:
{
"extensions": {
"3DTILES_batch_table_hierarchy": {
// ...
}
}
}
映入眼簾的是 extensions,它是一個 JSON,下面有一個 3DTILES_batch_table_hierarchy 的屬性,其值也是一個 JSON:
{
"classes": [
{ /* ... */ },
{ /* ... */ }
],
"instancesLength": 2,
"classIds": [0, 1]
}
其中,classes 是描述每個分類的陣列,這里有充電樁類、電動汽車類,詳細展開電動汽車類:
[
{ /* 電動汽車類,略 */ },
{
"name": "Car",
"length": 1,
"instances": {
"Brand": ["Tesla"],
"Owner": ["Jacky"]
}
}
]
每個 class 就記錄了該類別下,所有模型要素的屬性值(此處是 Brand 和 Owner),以及有多少個模型要素(length 值,此處是 length = 1 輛車),
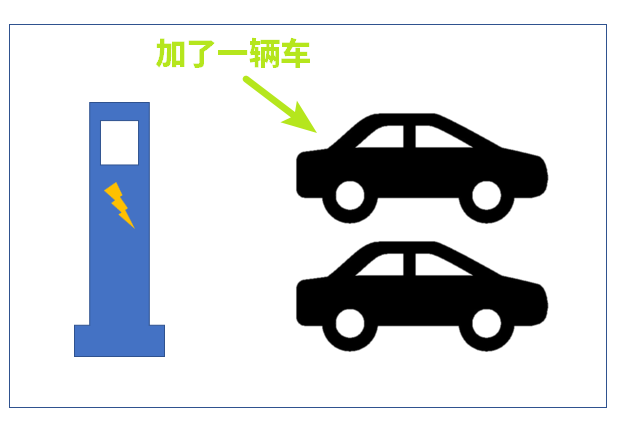
擴展:如果這個 b3dm 又多增加了一個電動汽車,那么這個 JSON 就應該變成下面的樣子了
{
"name": "Car",
"length": 2, // <- 變成 2
"instances": {
"Brand": ["Tesla", "Benz"], // <- 加一個值
"Owner": ["Jacky", "Granger"] // <- 加一個值
}
}
圖示:
3.2.1 屬性:3DTILES_batch_table_hierarchy.classes
classes 代表此 b3dm 內有多少個模型種類,這里有充電樁、汽車兩類,
3.2.2 屬性:3DTILES_batch_table_hierarchy.instancesLength
instancesLength 代表所有模型種類的數量和,這里每個種類都只有 1 個 batch(要素),加起來就是 2
instancesLength 和 b3dm 中要素表的 BATCH_LENGTH 并不是相等的,
當且僅當模型之間不構成邏輯層級時,這兩個數字才相等,顯然,此例中的 “充電樁”和“電動汽車”不構成邏輯分層、從屬關系,
有關這一條,在 3.3 小節中的層級關系會詳細展開,
3.2.3 屬性:3DTILES_batch_table_hierarchy.classIds
classIds 是一個 classId 陣列,每個陣列元素代表每個 batch 的 分類 id,若兩個 batch 是 classes 陣列中的某個 class,那么它倆的 classId 是一樣的,
這個陣列去重后的 id 數量,就等于 classes 陣列的長度,
例如,classIds: [0,0,0, 1,1],有 0、1 兩個 classId,那么 classes 陣列的長度就應該是 2.
3.3 虛要素:由多個實際的要素構成的屬性
現在,換一個場景,假設有一塊空間,上面有墻模型要素、窗模型要素、門模型要素、屋頂模型、樓板模型要素共 5 類,每個分類有 1、2、1、1、1 個模型要素,即
- 1個墻模型要素
- 2個窗模型要素
- 1個門模型要素
- 1個屋頂模型要素
- 1個樓板模型要素
通過 3.2,很快得到擴展 JSON:
{
"classes": [ /* 5個分類物件 */
{ "name": "Wall", /* length 和 intances 屬性值略 */ },
{ "name": "Window", /* length 和 intances 屬性值略 */ },
{ "name": "Door", /* length 和 intances 屬性值略 */ },
{ "name": "Roof", /* length 和 intances 屬性值略 */ },
{ "name": "Floor", /* length 和 intances 屬性值略 */ },
],
"instancesLength": 6,
"classIds": [0,1,1,2,3,4]
}
顯然,這 6 個模型要素可以構成一個屋子,此時,這 6 個模型要素并無邏輯資訊寫在 JSON 中,
那么,現在可以新增一個 class:
{
"classes": [
/* 同上,省略 5 個分類物件 */
{
"name": "House",
"length": 1,
"instances": {
"HouseArea": [48.94]
}
}
],
"instancesLength": 7, // <- 注意,變成 7 了
"classIds": [0,1,1,2,3,4, 5] // <- 注意,多了個 Id
}
這個新增的 House class,它在 glTF 中并沒有對應的一個圖形資料,但是它確確實實就是存在的,由上面 6 個模型要素構成,且有它自己的屬性:HouseArea,房屋面積,其值是 48.94 平方米,
同時,因虛構出來一個模型要素,instancesLength 不得不加一個,且 classIds 也加了一個,
由此,不妨修改一下 instancesLength 的定義:classes 中各個 class 的 length 之和,
提問,此時要素表的 BATCH_LENGTH 與 instancesLength 一樣嗎?
表示從屬關系:屬性 3DTILES_batch_table_hierarchy.parentIds
為了表示 House 類與其他 5 類的關系,新增一個屬性與 classes、instancesLength、classIds 并列:
{
/* 3DTILES_batch_table_hierarchy 三個屬性 classes、instancesLength、classIds,略前兩個 */
"classIds": [0,1,1,2,3,4, 5],
"parentIds": [6,6,6,6,6,6, 6]
}
parentId 是什么呢?
重復一下 3.3 的假設,一共 6 個物體模型要素:1個墻模型要素、2個窗模型要素、1個門模型要素、1個屋頂模型要素、1個樓板模型要素
那么,索引從 0 開始計算,第 2 個是窗模型要素,其 classId 是 classIds[2] = 1,其 parentId = parentIds[2] = 6,
現在,得到它的 parentId 是 6,從 classes 中的 class 挨個往下找,終于在 House 這個 class 找到了第 6 個模型要素(因為 0~5 被前 5 個 class 包了),
結論
parentId 是 classes 中記錄的所有模型要素的 順序序號,包括物體的模型要素,以及在本小節中提到的虛要素,即 House,
讀者應該注意到了,如果自身已經沒有 parent 了,即它已經是這個 b3dm 中邏輯層級最高的要素模型了,它的 parentId 就是它在 classes 中的順序號本身,
優缺點
優點:強大的可擴展性,理論上可以無限層級嵌套虛擬的要素屬性,十分適合 BIM 資料的構造,
缺點:不易讀寫,不適合 b3dm 的增減,難以修改,
4 再看 “pnts 瓦片的幾何壓縮” 擴展
和 glTF 的 頂點屬性可以被 Google Draco 壓縮工具壓縮一樣,點云瓦片也支持了此壓縮工具,極大地降低了點云瓦片的體積,
pnts 中 要素表 的資料壓縮
這個瓦片比起上面那個就簡單多了,它位于 pnts 瓦片的 要素表JSON頭中:
{ "POINTS_LENGTH": 20, // <- pnts 中有多少個點,這里有 20 個點 /* 其他 pnts 要素表屬性,略 */ "extensions": { "3DTILES_draco_point_compression": { "properties": { "POSITION": 0, "RGB": 1, "BATCH_ID": 2 }, "byteOffset": 0, "byteLength": 100 } }}
它指示了 pnts 瓦片的 POSITION、RGB、BATCH_ID 三個資料位于要素表二進制塊中,從第 0 個位元組開始計,長度為 100 個位元組,讀取出來,把這 100 個位元組二進制資料交給 Draco 解碼器,就能解碼出來這 20 個點的對應資料,
目前,這個擴展功能僅支持壓縮 pnts 瓦片要素表中的 "POSITION","RGBA","RGB","NORMAL" 和"BATCH_ID" 資料,
被壓縮的資料,例如這里的 POSITION、RGB、BATCH_ID,它們的 byteLength 值一律為 0(原本是指的要素表二進制資料塊的位元組起始偏移量),
pnts 中 批次表 的屬性資訊壓縮
Draco 壓縮工具能壓縮的資料型別是數字,所以,批次表中的資料,也可以被壓縮,
假設,某 pnts 瓦片的批次表記錄了 Intensity、Classification 兩個點云的屬性資訊,它的批次表 JSON 如下所示:
{ "Intensity": { "byteOffset": 0, "type": "SCALAR", "componentType": "UNSIGNED_BYTE" }, "Classification": { "byteOffset": 0, "type": "SCALAR", "componentType": "UNSIGNED_BYTE" }}
顯然,兩個屬性資訊都是標量,數字型別均為無符號的位元組,那么,使用了 Draco 壓縮之后,批次表的 extensions 應寫為:
{
"Intensity": { /* 略,見上 */ },
"Classification": { /* 略,見上 */ },
"extensions": {
"3DTILES_draco_point_compression": {
"properties": {
"Intensity": 3,
"Classification": 4
}
}
}
}
注意
pnts 批次表的 3DTILES_draco_point_compression 擴展只需要 properties 屬性即可,不需要 byteLength 和 byteOffset,
究其原因,Cesium 團隊是將批次表二進制資料一并壓縮進了要素表二進制塊內,而且會把所有被壓縮的屬性,不管是 要素表,還是批次表,的 byteOffset 均歸零,
回顧 pnts 瓦片的規范,若 pnts 瓦片內的點要進行 batch 分類,那么其分類資訊在要素表中就記錄得夠詳細了,全域的 BATCH_LENGTH、逐點的 BATCH_ID 足夠將未壓縮的批次表屬性資訊訪問出來,
5 即將到來的大變動
- 隱式瓦片
- glTF 瓦片
- 元資料
- ...
精力有限,以后有可能的話專門出一個專題講解更新中的擴展項,
6 再談 extensions 和 extras
某個 extensions 用到的具體資料,如果不方便寫在 extensions 的 JSON 中,可以掛在 extras 中,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/287569.html
標籤:GIS
上一篇:分享Sql性能優化的一些建議