我有一個資料框架,其中包含測驗案例的運行資料。 該資料框架中最重要的指標是'Elapsed Time'列,它是一個timedelta物件,告訴我們一個特定測驗案例的運行時間。
該資料集看起來像這樣。(沒有任何東西被排序,即使它可能看起來是這樣的 btw)
| Test key | 。Started At | 完成于經過的時間。版本 | 。||||
|---|---|---|---|---|---|---|
| 0 | TEST-1676 | TEST-1676 | 2021-06-10 14:40:00 | 2021-06-10 15:24:00 | 0天 00:44:00 | 8.0.1.0 |
| 1 | TEST-1518 | |||||
| TEST-1518 | 2021-06-11 12:14:00 | 2021-06-11 12:36:00 | 2021-06-11 12:36:00 | 0天 00:22:00 | 8.0.1.0 | |
| 2 | TEST-1518 | |||||
| TEST-1518 | 2021-06-11 09:29:00 | 2021-06-11 09:44:00 | 2021-06-11 09:44:00 | 0天 00:15:00 | 8.0.1.0 |
...
| Test key | 。Started At | 完成于經過的時間。版本 | 。||||
|---|---|---|---|---|---|---|
| 1037 | TEST-1140 | 2018-11-28 09:35:00 | 2018-11-28 10:35:00 | 0天 01:00:00 | nan | |
| 1038 | TEST-1138 | 2018-11-28 10:56:002018-11-28 11:08:00 | 0天 00:12:00 | nan |
- 我做錯了什么?
- 為什么應用于所有組的總和是不同的?
- 當夏日化時,我怎么會得到一個負的 Timedelta?
編輯:
以下是產生錯誤輸出的代碼:
uj5u.com熱心網友回復:
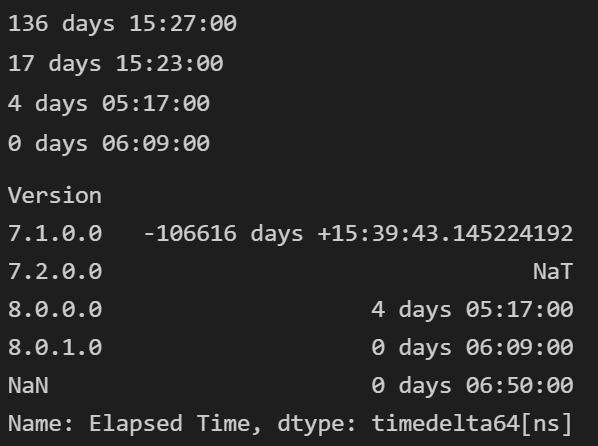
你有8行NaNs作為版本。默認情況下,groupby洗掉了NaN,因此缺少6小時50分鐘。
使用:
df_runs. groupby(['Version'], dropna=False)['Elapsed Time'].sum()
輸出:
Version
7.1.0. 0 136天 15:27: 00
7.2.0. 0 17天 15:23: 00
8.0.0.0 4天 05:17:00
8.0.1.0 0 天 06:09:00
NaN 0 天 06:50:00
名稱。經過的時間, dtype: timedelta64[ns]
uj5u.com熱心網友回復:
在看到mozways的回答和一些更多的評論后,似乎他的資料沒有問題。
然后我用以下方法檢查了我的資料是否有NaN值:
df_na = df_runs[df_runs.isna().any(axis=1)]
df_na
這就回傳了幾行沒有填寫任何日期的資料。
這是給定資料中的一個失敗,在日期列中不應該有任何 NaN 值,因為沒有這些值,測驗運行就無法完成。
然而,這對于sum()函式來說并不重要,因為NaN值被簡單地忽略了。這可以通過在單個組上使用sum來證明,在那里它是有效的。
為什么在我的機器上會產生錯誤的值? - 我不知道。
我是怎么做到的?
我是如何修復它的? 要么放棄
標籤:NaN值,要么將它們替換為零。# EITHER: drop NaN values。
df_runs = df_runs.dropna()
# OR: 用Timedelta zero替換NaN。
df_runs['Elapsed Time'] = df_runs['Elapsed Time'].fillna(pd.Tomedelta(0)