我有一個包含 40 萬條記錄的 MySQL 表 (TABLE1)
CREATE TABLE `TABLE1` (
`ID` bigint(20) NOT NULL AUTO_INCREMENT,
`NAME` varchar(255) NOT NULL,
`VALUE` varchar(255) NOT NULL,
`UID` varchar(255) NOT NULL,
`USER_ID` varchar(255) DEFAULT NULL,
PRIMARY KEY (`ID`),
UNIQUE KEY `ukey1` (`VALUE`,`NAME`,`UID`),
UNIQUE KEY `ukey2` (`UID`,`NAME`,`VALUE`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `TABLE2` (
`ID` bigint(20) NOT NULL AUTO_INCREMENT,
`UID` varchar(255) DEFAULT NULL,
`TABLE3ID` bigint(20) NOT NULL
PRIMARY KEY (`ID`),
KEY `FKEY` (`TABLE3ID`),
CONSTRAINT `FKEY` FOREIGN KEY (`TABLE3ID`) REFERENCES `TABLE3` (`ID`),
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `TABLE3` (
`ID` bigint(20) NOT NULL AUTO_INCREMENT,
`TYPEID` bigint(20) NOT NULL,
PRIMARY KEY (`ID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
以下查詢很慢,需要幾個小時,最后失敗
delete from TABLE1 t1
inner join TABLE2 t2 on t1.UID=t2.UID
inner join TABLE3 t3 on t2.TABLE3ID=t3.ID
where t3.TYPEID in (234,3434) t1.USER_ID is not null and t1.USER_ID <> '12345';
可視化解釋顯示以下內容并在 UID 上添加索引沒有幫助。如何優化這個查詢的性能?
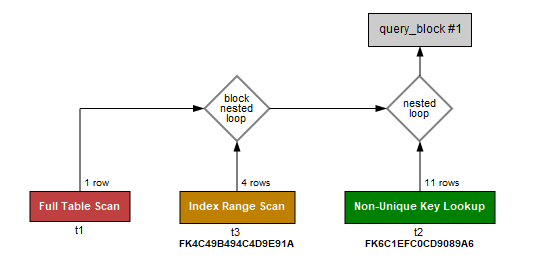
- 我嘗試在 TABLE1.UID 上添加索引
- 轉換為子查詢
- 一個簡單的查詢
SELECT * FROM TABLE3 where UID="SOMEUID"需要 800 毫秒來獲取資料
uj5u.com熱心網友回復:
將其更改為 JOIN。
DELETE t1
FROM TABLE1 AS t1
JOIN (SELECT uid FROM ...) AS t2 ON t1.uid = t2.uid
WHERE USER_ID is not null and USER_ID <> '12345';
我發現WHERE uid IN (subquery)有時MySQL 的實作很差。它不是獲取子查詢的所有結果并在表的索引中查找它們,而是掃描表并對每一行執行子查詢,然后檢查 uid 是否在該結果中。
uj5u.com熱心網友回復:
首先備份該表,這是執行洗掉查詢的第一條規則,否則您可以破壞它并采取您之前考慮過的所有預防措施
( uid1,uid2,...uid45000)
括號之間的那些值是什么意思?您是否需要在串列中比較所有 UID 值或其中一些值?
因為您可以避免像這樣手動放置所有UIDS。
delete from TABLE1 where UID in (SELECT T.UID FROM TABLE1 as T where T.UID is not NULL and USER_ID <> '12345');
在執行此操作之前,請檢查括號之間您想要什么,并首先使用虛擬值在 TEST 環境中運行該命令
考慮到您在 UIDS 欄位中的表中具有 varchars 型別,這就是此操作比使用整數值花費更多時間的原因
另一種方式是你需要創建一個新表并將你需要為舊表存盤的資料,然后截斷原表并再次將新表的相同值重新插入到舊表中
請在運行解決方案之前與您的隊友檢查您的所有限制并使用虛擬值進行測驗
uj5u.com熱心網友回復:
我會將您的 uid 過濾器串列分成塊(100 個塊或其他,需要測驗)并對其進行迭代或多執行緒
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/314080.html