我真的不確定我正在嘗試做的事情是否有技術術語,所以我會盡量說清楚。
我目前有 18 個 2x9 = 18 個單元格的表格。這些是我將在實驗中使用的令牌集。
這些表格中的每一個都有不同的語言背景,尤其是不同的主要動詞。例如這里是我的前兩個表:
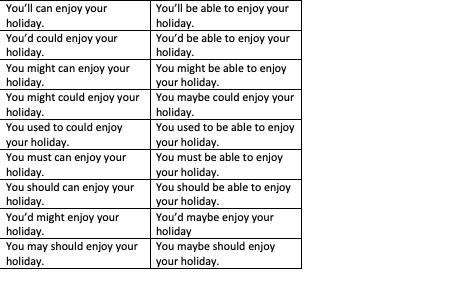
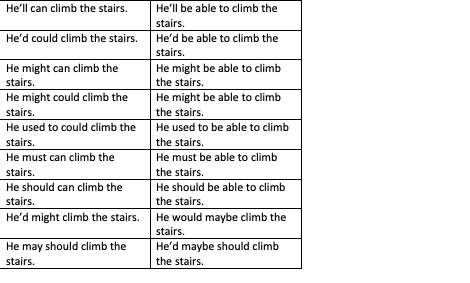
... 總共 18 次。
我想要做的是“洗牌”這些表,以便每個表包含 18 個原始條件中的每個條件之一,并且沒有條件重復兩次。
例如,第一個表格中的單元格 1 將包含“您可以享受……”,單元格 2 將包含“他可以攀爬……”,依此類推,第二個表格會將這些背景關系向下移動一個細胞。
我不確定如何自動執行此操作(手動執行非常痛苦)。有沒有辦法在R中做到這一點?
至關重要的是,我并不是要隨機化。有一種有序的方式來打亂表格。
祝一切順利,
卡梅倫
uj5u.com熱心網友回復:
所以首先我重新創建了你的表格,使用基礎 R 的sentences物件來模擬每個單元格:
start_index <- seq(1,18*18,18)
end_index <- seq(18,18*18,18)
for (i in 1:18){
tables[[i]] <- sentences[start_index[i]:end_index[i]]
}
然后撰寫了一個函式來回圈遍歷它們,使用表索引作為引數:
tablemaker <- function(n){
new_table <- list()
for (i in 1:18){
new_table[i] <- tables[[ifelse(n-1 i > 18,n-1 i-18 ,n-1 i)]][i]
}
return(new_table)
}
之后,我們可以映射它們:
new_tables <- purrr::map(1:18, tablemaker)
然后檢查以確保所有單元格仍然是唯一的:
> 18*18
[1] 324
> length(unique(unlist(new_tables)))
[1] 324
> length(unique(unlist(tables)))
[1] 324
uj5u.com熱心網友回復:
這個怎么樣:
tab1 <- matrix(paste("cell", 1:18, ", table 1"), ncol=2)
tab2 <- matrix(paste("cell", 1:18, ", table 2"), ncol=2)
tab3 <- matrix(paste("cell", 1:18, ", table 3"), ncol=2)
tab4 <- matrix(paste("cell", 1:18, ", table 4"), ncol=2)
tab5 <- matrix(paste("cell", 1:18, ", table 5"), ncol=2)
tab6 <- matrix(paste("cell", 1:18, ", table 6"), ncol=2)
tab7 <- matrix(paste("cell", 1:18, ", table 7"), ncol=2)
tab8 <- matrix(paste("cell", 1:18, ", table 8"), ncol=2)
tab9 <- matrix(paste("cell", 1:18, ", table 9"), ncol=2)
tab10 <- matrix(paste("cell", 1:18, ", table 10"), ncol=2)
tab11 <- matrix(paste("cell", 1:18, ", table 11"), ncol=2)
tab12 <- matrix(paste("cell", 1:18, ", table 12"), ncol=2)
tab13 <- matrix(paste("cell", 1:18, ", table 13"), ncol=2)
tab14 <- matrix(paste("cell", 1:18, ", table 14"), ncol=2)
tab15 <- matrix(paste("cell", 1:18, ", table 15"), ncol=2)
tab16 <- matrix(paste("cell", 1:18, ", table 16"), ncol=2)
tab17 <- matrix(paste("cell", 1:18, ", table 17"), ncol=2)
tab18 <- matrix(paste("cell", 1:18, ", table 18"), ncol=2)
l <- list(
tab1, tab2, tab3, tab4, tab5, tab6, tab7, tab8, tab9,
tab10, tab11, tab12, tab13, tab14, tab15, tab16, tab17, tab18)
newtabs <- lapply(1:9, function(i)t(sapply(l, function(x)x[i, ])))
該newtabs物件將是一個串列,其中每個元素將是您想要的表之一。例如,在上面,第一個表是:
> newtabs[[1]]
[,1] [,2]
[1,] "cell 1 , table 1" "cell 10 , table 1"
[2,] "cell 1 , table 2" "cell 10 , table 2"
[3,] "cell 1 , table 3" "cell 10 , table 3"
[4,] "cell 1 , table 4" "cell 10 , table 4"
[5,] "cell 1 , table 5" "cell 10 , table 5"
[6,] "cell 1 , table 6" "cell 10 , table 6"
[7,] "cell 1 , table 7" "cell 10 , table 7"
[8,] "cell 1 , table 8" "cell 10 , table 8"
[9,] "cell 1 , table 9" "cell 10 , table 9"
[10,] "cell 1 , table 10" "cell 10 , table 10"
[11,] "cell 1 , table 11" "cell 10 , table 11"
[12,] "cell 1 , table 12" "cell 10 , table 12"
[13,] "cell 1 , table 13" "cell 10 , table 13"
[14,] "cell 1 , table 14" "cell 10 , table 14"
[15,] "cell 1 , table 15" "cell 10 , table 15"
[16,] "cell 1 , table 16" "cell 10 , table 16"
[17,] "cell 1 , table 17" "cell 10 , table 17"
[18,] "cell 1 , table 18" "cell 10 , table 18"
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/315276.html
下一篇:在列內計算并基于另一列求平均值