我使用的是減肥資料集:
我使用的是減肥資料集。
structure(list(id =結構(c(1L。 2L。 3L, 4L, 5L。 6L, 7L。 8L, 8L,
9L, 10L。 11L,/span> 12L。 1L, 2L。 3L, 4L。 5L, 6L。 7L,/span> 8L。 9L, 10L。 11L,
12L, 1L。 2L, 3L。 4L, 5L。 6L, 7L。 8L, 9L。 10L, 11L。 12L, 1L。 2L, 2L,
3L, 4L, 5L。 6L, 7L。 8L, 9L, 10L。 11L, 12L), 。 標簽 = c("1"。 "2",
"3", "4"。 "5",/span> "6"。 "7", "8", "9"。 "10",/span> "11"。 "12")。 class = " factor"),
飲食=結構(c(1L。 1L, 1L, 1L。 1L, 1L, 1L。 1L, 1L。 1L, 1L,
1L,/span> 1L。 1L, 1L。 1L, 1L。 1L, 1L。 1L, 1L。 1L, 1L。 1L, 1L。 2L, 2L,
2L, 2L。 2L, 2L。 2L, 2L。 2L, 2L。 2L, 2L。 2L, 2L。 2L, 2L。 2L, 2L,
2L, 2L。 2L, 2L。 2L, 2L。 2L, 2L), 。 標簽 = c("no"。 "yes")。 class = " factor"),
練習=結構(c(1L。 1L, 1L。 1L, 1L, 1L。 1L, 1L, 1L, 1L,
1L,/span> 1L。 1L, 2L。 2L, 2L。 2L, 2L。 2L, 2L。 2L, 2L。 2L, 2L。 2L, 2L,
1L, 1L。 1L, 1L。 1L, 1L。 1L, 1L。 1L, 1L。 1L, 1L。 2L, 2L。 2L, 2L,
2L, 2L,, 2L, 2L。 2L, 2L。 2L, 2L), 。 標簽 = c("no"/span>, "yes"/span>.
)。 class = "factor")。 t1 = c(/span>10. 43, 11.59, 11. 35, 11.12,
9.5, 9.5, 11. 12, 12.51, 11. 35, 11.12, 11. 12, 10.2, 11.12,
9.96, 12.05, 8. 11, 12.05, 12. 05, 12.28, 10. 66, 11.35, 10.2,
10.2, 9.5, 10. 2, 12.98, 13. 21, 10.2, 11. 59, 12.05, 11.59,
12.05, 11.82, 11。 12, 12.51, 11. 59, 10.43, 11. 35, 11.82, 10.2,
13.67, 10.66, 10. 2, 12.05, 11.82, 10. 43, 12.74, 11. 35), t2 = c( 13. 21,
10.66, 11.12, 9. 5, 9.73, 12. 74, 12.51, 12. 28, 11.59, 10.66,
13.44, 11.35, 12. 51, 12.74, 13. 67, 14.37, 14. 6, 12.98, 12.05,
14.37, 14.6, 11. 82, 14.13, 13. 21, 12.51, 12. 98, 11.12, 9.73,
13.44, 13.67, 12. 98, 11.35, 12. 05, 15.29, 11. 82, 12.05, 12.51,
14.83, 13.9, 13. 21, 14.13, 15. 06, 12.98, 11. 35, 12.51, 14.13,
12.74, 11. 35), t3 = c(11. 59, 13.21, 11. 35, 11.12, 12.28,
10.43,/span> 11.59,/span> 12. 74, 9.96, 11. 35, 10.66, 11. 12, 15.76, 16.68,
17.84, 14.6, 17. 84, 17.61, 18. 54, 16.91, 15. 52, 17.38, 19,
14.13, 14.6, 14. 6, 12.05, 15. 52, 13.9, 12. 74, 13.21, 14.83,
14.6, 10.89, 15. 52, 12.98, 14. 37, 15.06, 13. 44, 14.13, 15.29,
14.6, 15.06, 15. 52, 13.9, 14.37, 15. 06, 15. 06))。 class = c("tbl_df"。
"tbl", "data.frame"), 行。 names = c(NA。 -48L))
到目前為止,看起來至少在這里我可以把分數分開:
weight <- weightloss
摘要 <-體重 %>%
get_summary_stats(type = "mean_sd"/span>)
摘要
這給了我這個:
A tibble: 3 x 4
變數 n 平均數 sd
<chr> <Dbl> <dbl> <dbl>
1 t1 48 11.2 1.09
2 t2 48 12.7 1.42
3 t3 48 14.2 2.26
我正試圖對其進行RMANOVA,但我想得到三個組中每個組的boxplot,都在一個圖中。然而,我不確定在這種情況下如何繪制x和y。我試著用這個方法來繪制x:
trial_type < - c("t1"/span>。 "t2","t3")
factor(trial_type)
但這就是我的問題所在......我不確定你在這種情況下如何得到y。y顯然是每次試驗的分數。我試著用這個因素進行分組,看看是否能以某種方式對分數進行分類,但我也沒有想出辦法。
我只是不確定你是如何在 ggplot 中繪制的。任何幫助都將是巨大的! 我可以想象,對于任何使用試驗的資料來說,這是一個非常有用的學習技能。
uj5u.com熱心網友回復:
你可能要先pivot_longer,然后分組才會變得容易。
在透視之后,所有的值都會在同一列('values'),并且會有一個分組列('trial')
library(dplyr)
df<-df %> % pivot_longer(names_to = 'trial'。 values_to = 'value'。 cols = matches('td'))
與(df。 boxplot(value ~ trial))
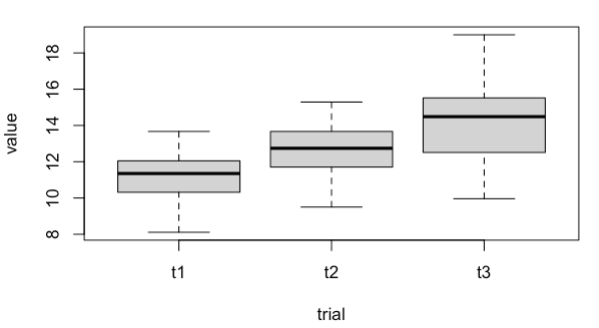
如果你喜歡ggplot:
ggplot(df, aes(x=trial, y=value))
geom_boxplot()
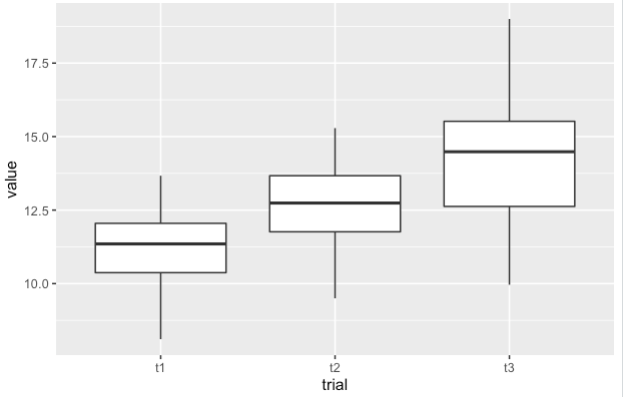
uj5u.com熱心網友回復:
一種ggplot和reshape2方式;
library(reshape2)
df %>%
melt(id.vars='id',measure。 vars = c('t1'。 't2','t3')) %> %
ggplot(aes(x=variable, y=值))
geom_boxplot(aes(color=variable)
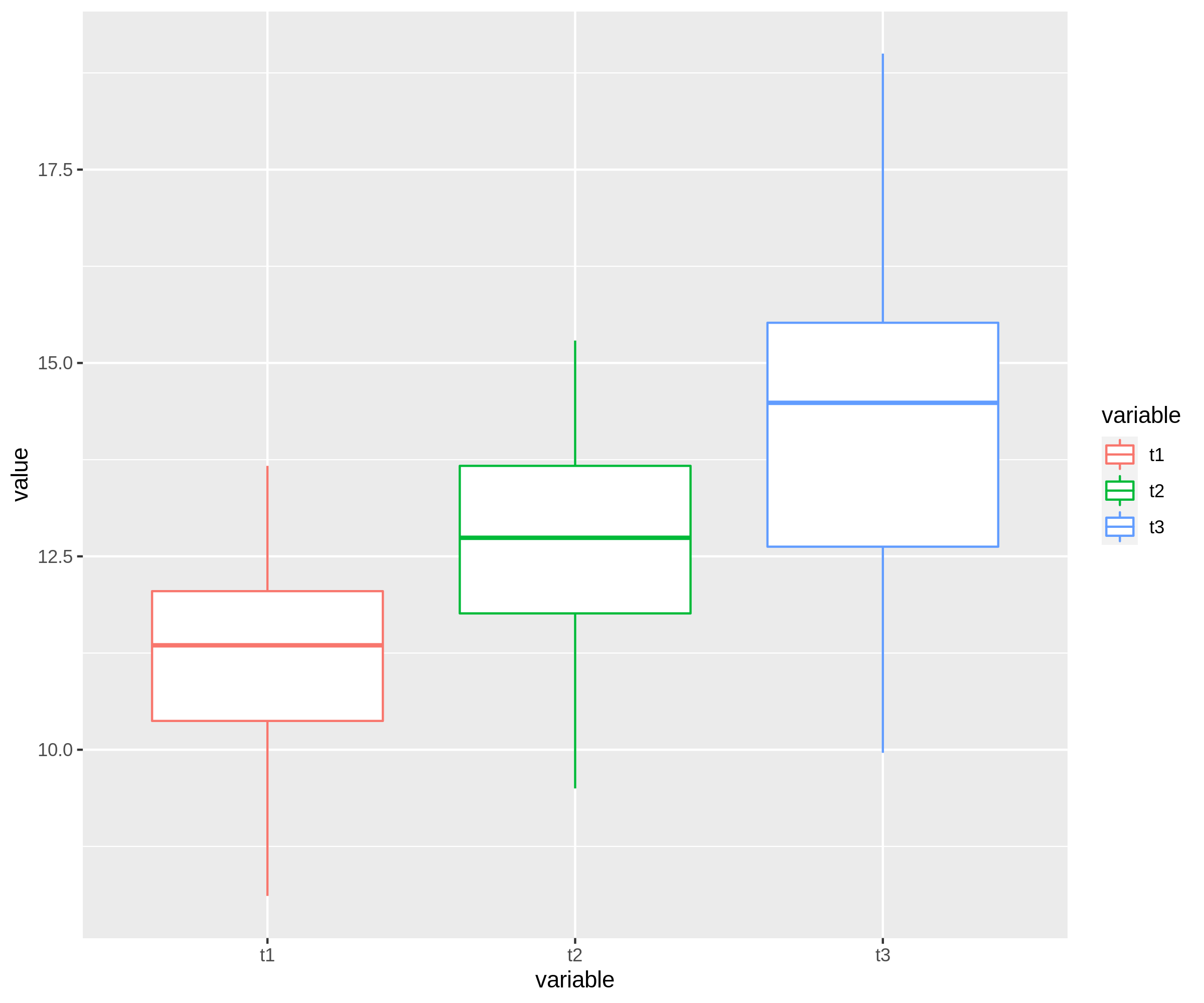
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/318940.html
標籤: