我想繪制我的資料框架,其中包含不同路徑長度(5公里以下、5-10公里、10-30公里......)的不同模式分割值(汽車使用率%,自行車使用率%)。 我的資料框架中的每個元素都包含了每個路徑長度的車輛使用百分比。
我的目標是在一個圖中繪制所有的值。 我想創建一個條形圖,每個路徑長度都有一個條形圖,代表所有車輛的百分比(模式劃分)。
我的資料框架的第一列包含車輛模式(汽車、自行車......),第2-10列包含每個路徑長度組的百分比。
我試過:
testtest < - ggplot() geom_col(data = ms_gruppen_d。
aes(x = colnames(ms_gruppen_d)[2。 9],
y = ms_gruppen_d[, 2: 9],
填充= ms_gruppen_d[。 1]))
我的值不是分類的,所以我不能使用 "計數 "函式。 誰能幫幫我?
謝謝
ms_gruppen_d < -結構(list(VM= c("Fu?verkehr"/span>。 "Fahrrad", "Motorrad/Moped/Mofa","Privater_pkw",/span> "Gewerb_pkw"。 "Lkw_bis_3_5_", "Lkw_ab_3_5_", "Sattelzug", "?PNV")。 `Laenge unter 5km` = c(/span>0. 218428835651906,
0.208360071967382, 0, 0。 337471470224058, 0. 195785602540656, 0.0103830833919553,
0.0123737357892543, 0, 0。 0171972004347874)。 `Laenge 5 - 10km` = c(0. 138928420064367,
0.140725324716725, 0.00988051174398964, 0. 289334484453904, 0.308718256514345,
0.0356902893023975, 0。 00988051174398964, 0.0222528559093808,
0. 044589345550901)。 `Laenge 10-20km` = c(/span>0. 0667063809168976,
0.172327489225668, 0, 0。 271668790053295, 0. 346741728107974, 0.0573103622018356,
0.0292526145926873,/span> 0. 0149058863164426, 0.0410867485852005),
`Laenge 20-30km` = c(0。 0405426428226048, 0.1463357744637,
0.0236972749606593,/span> 0. 271246395715663, 0.354248166536575,
0.0855256681459516,/span> 0. 0173953892663395, 0.0432292937973128,
0. 0177793942911947)。 `Laenge 30-50km` = c(0. 0213163894963155,
0.0503758065644924,/span> 0. 0159090254544127, 0.178916279908378,
0.485985672387571, 0。 148087763700495, 0.0378558845704386,
0.026693520571143, 0。 0348596573467541)。 `Laenge 50-100km` = c(0. 00652604845092996,
0.0123285212525124, 0, 0。 177307097376991, 0.380919125770432,
0.154233838933756, 0. 213479807823156, 0.0441531204824327,
0. 0110524399097905)。 `Laenge 100-200km` = c(0, 0. 00431357399129567,
0, 0.087013827371374, 0. 173016082279325, 0.203265193001196,
0.399659385606215, 0。 0655495360275712, 0.0671824017230226
)。 `Laenge 200-300km` = c(0, 0, 0, 0。 00953852353026925, 0.147233787704061,
0.130598939323796,/span> 0. 518334554408677, 0.146338992010429,
0. 0479552030227669)。 `Laenge 300km ` = c(0, 0, 0, 0. 0333890118493603,
0.0876659311982381,/span> 0. 0979219742771943, 0.420951006142259,
0.297349051156633, 0. 062723025376315)),行。 names = c(NA,)
-9L)。 class = "data. frame")
uj5u.com熱心網友回復:
主要問題是我認為你的資料是寬格式的,而不是長格式的。你可以使用tidyr::pivot_longer()重新塑造資料。下面是你如何使用該函式來制作一個分組條形圖的方法:
library(ggplot2)
#重塑資料,不包括第1列。
df <- tidyr:: pivot_longer(ms_gruppen_d, -1。 names_to = "Laenge")
# 讓距離列印得更漂亮。
df$Laenge < -因子(df$Laenge。 水平= colnames(ms_gruppen_d)[-1])
levels(df$Laenge) < - gsub("Laenge", "", levels(df$Laenge))
# A grouped bar chart
ggplot(df, aes(Laenge。 值,填充=VM))
geom_col(position = "dodge")
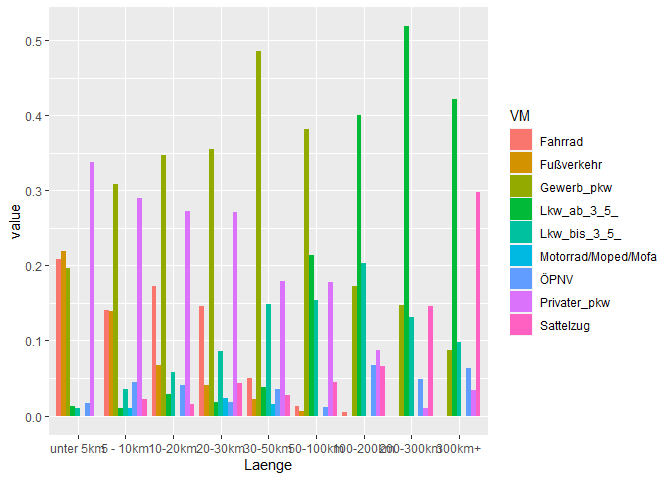
然而,我認為在這種情況下,疊加條形圖可能更有意義,因為所有的分數加起來都應該是1。
ggplot(df, aes(Laenge。 值,填充=VM))
geom_col(position = "stack"/span>)
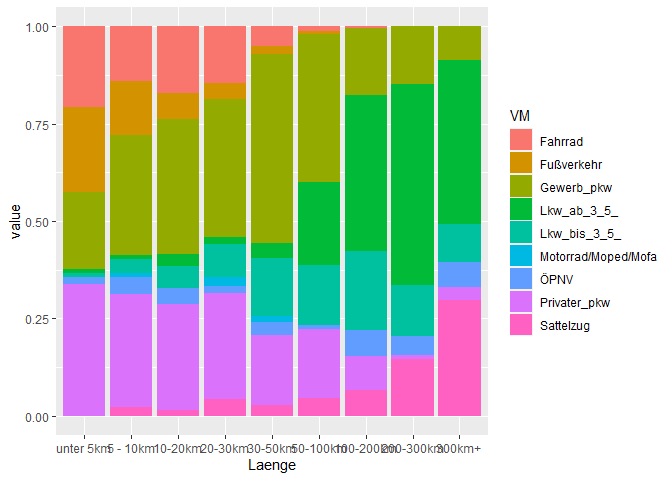
創建于2021-09-10,由reprex包(v2.0.1)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/318951.html
標籤:
上一篇:用R的圖示來可視化數量