簡要介紹:
。(小編輯。我問這個問題的目的不是關于演算法本身。我完全知道用3個區域變數或3個元素的陣列進行快速迭代解決。實際上,我特意讓這兩個測驗的復雜度差異達到了我能想到的最低程度。我想知道的是,如果在自定義堆疊和迭代中實作一個與遞回演算法相同的演算法來攻擊同一個問題,是否可以提高性能!)
當我們學習了關于遞回的知識后,我們就開始學習了。
當我們在學校學習編程時,我們通常被告知,與遞回相比,迭代通常更有效率,除非遞回提供了一種具體而優雅的方式來解決問題。
因此,最近我決定將其納入一個簡單的測驗。鑒于函式呼叫本質上是由呼叫堆疊處理的,因此有可能實作一個自定義堆疊來處理所需的區域變數,并將遞回實作變成迭代實作。下面是我在遞回基礎上實作斐波那契數計算器的例子,據說是使用迭代的等效演算法,都是用C語言撰寫的。
方法:。
遞回植入。(fibon_recu):
uint64_t calls = 0;
/* 使用遞回演算法計算斐波納契數。*/
uint64_t fibonacci(uint8_t idx)
{
呼叫 。
return (idx <= 1) ? idx : (fibonacci(idx - 1) fibonacci(idx - 2) 。)
}
迭代植入。(fibon_iter):
uint64_t loop_count。
/* 使用源自遞回演算法的基于堆疊的方法計算斐波那契數。*/
uint64_t fibonacci(uint8_t idx)
{
uint64_t ret = 0;
uint8_t stack_val[ARR_STACK_SIZE], cache;
uint16_t stack_size;
loop_count = 0;
//將索引推入模擬堆疊。
stack_size = 1;
*stack_val = idx;
while(stack_size)
{
//彈出模擬堆疊頂。
stack_size -= 1;
cache = *(stack_val stack_size)。
if(cache > 1)
{
//push <index - 1> and <index - 2> into simulated stack。
*(stack_val stack_size) = cache - 1;
*(stack_val stack_size 1) = cache - 2。
stack_size = 2;
}
else; }
{
ret = cache;
}
loop_count ;
}
return ret;
}
值得一提的是,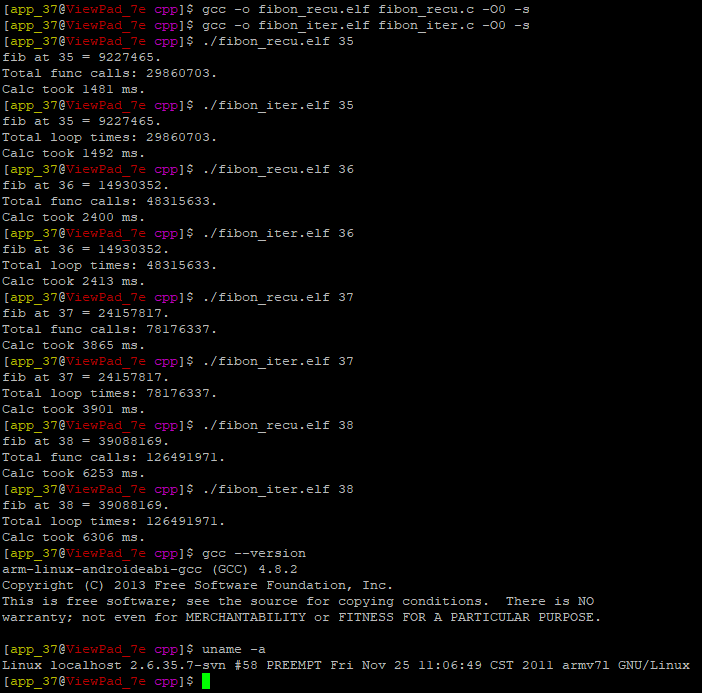
其中fibon_recu代表遞回測驗,fibon_iter代表迭代測驗。只是為了參考,以防這些資訊是相對的,我決定把gcc版本和基本設備資訊都放在圖上。
更新:
<2021年9月7日;11:00 UTC>
感謝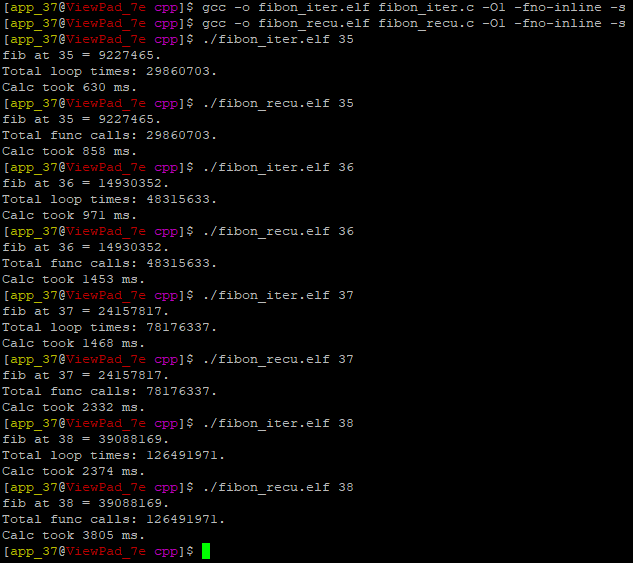
-O2:
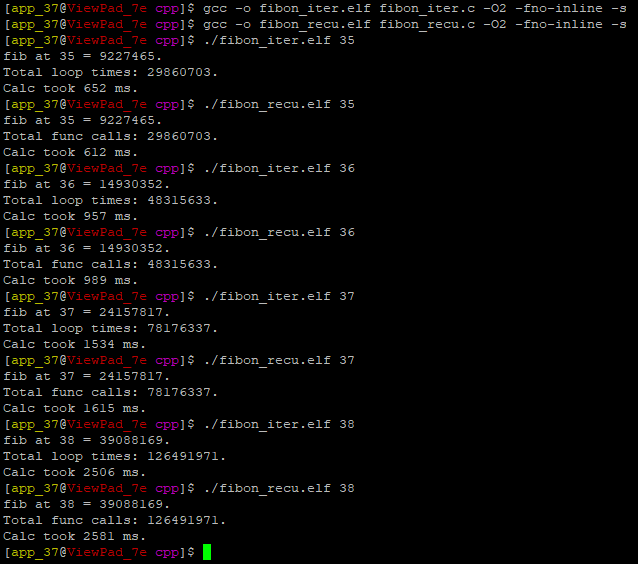
事實證明,Eugene提到的編譯器行為在我的測驗環境中確實成立,-O1標志保留了所有的遞回bl呼叫,而-O2標志優化了尾部的bl呼叫。John觀察到的改進也可以在我的設備上重現,如上面的結果所示:-O1標志使迭代的表現比遞回好得多。
因此,我猜測測驗結果顯示,指令的復雜性和遞回呼叫在效率和性能方面是相互競爭的。-O0標志完全沒有給出自制堆疊的優化,導致額外的復雜性,甚至打破了迭代的優勢。-O1標志保留了遞回呼叫,同時優化了迭代實作,使后者的性能得到了提升。-O2標志洗掉了尾部遞回,并使遞回實作比-O1下的運行更好,使競爭的因素再次顯現。
原問題:
為什么看似等價的迭代實作仍然沒有比遞回實作表現得更好?我是否有什么明顯的錯誤,或者有什么東西其實是隱藏在眾目睽睽之下的?
謝謝!
<uj5u.com熱心網友回復:
這只是更多的匯編和更多的堆疊訪問。
相對于基于暫存器的引數傳遞來說。你可以很容易地看到第一種演算法和第二種演算法之間的差異。更多的匯編代碼并不一定會轉化為更慢的速度,但在這種情況下,它確實如此。
當代主流 ISA 和 API 有一些實作函式呼叫的內置功能,即使在 -O0 時也是活躍的。
uj5u.com熱心網友回復:
我想知道的是,如果實作一個與遞回演算法相同的演算法,在自定義堆疊和迭代中攻擊相同的問題,可以提高性能!
這假設演算法實際上是相同的。 你的基于堆疊的演算法并不與遞回版本相同--首先,你在基于堆疊的版本中比遞回版本執行了更多的賦值和測驗,這就扼殺了你通過不遞回呼叫函式而獲得的任何收益。其次,遞回版本(很可能)是通過暫存器傳遞引數,而不是通過堆疊。
在我的系統中,開啟第1級優化顯著地改善了基于堆疊的版本相對于遞回版本的運行時性能(基于堆疊的版本所需的時間遠遠少于遞回版本)。 在我的系統中,從-O0到-O1,遞回版本加快了~26%,基于堆疊的版本加快了~67%。
而對于它的價值,這是 fibonacci 的一個天真的迭代實作:
unsigned long fib_it( int n )
{
/**。
* 圓形緩沖區,用于存盤
*中間值
*/
unsigned long f[3] = { 0ul, 1ul, 1ul }。
if ( n <= 2 )
return f[n];
int i;
for ( i = 3; i <= n; i )
f[i % 3] = f[(i-1) % 3] f[(i-2) % 3] 。
return f[(i 2) % 3] 。
}
當n變大時,它在運行時間和記憶體使用方面都絕對超越了遞回和基于堆疊的版本(你基本上只需要擔心溢位)。 正如其他人所展示的那樣,有一些更快的演算法可以最大限度地減少中間計算的數量,并且有一個閉合形式的版本更快。
如果一個遞回演算法對你來說執行得太慢,你不會通過用你自己的堆疊重新實作它的遞回性來加速它--你會通過使用非遞回方法來加速它。 作為斐波那契函式的定義,Fn = Fn-1 Fn-2 是緊湊且易于理解的,但是作為函式的實作,它的效率非常低,因為它多次計算同樣的值。 上面的迭代版本對每個值只計算一次。
像quicksort這樣的遞回函式之所以快速,是因為它們在每次呼叫時都會極大地減少問題空間的大小。 遞回斐波那契卻沒有這樣做。
編輯
一些數字。 我的測驗線束需要兩個引數--要計算的第N個數字和要使用的演算法--s用于你的基于堆疊的版本,r用于遞回,而i用于我上面的迭代版本。 對于小N來說,差異不是太大(用-O1編譯):
$ ./fib -n 5 -r
i F(i) clocks seconds
- ---- ------ -------
5 5 1 0.000001
$ ./fib -n 5 -s
i F(i) clocks seconds
- ---- ------ -------
5 5 2 0.000002
$ ./fib -n 5 -i
i F(i) clocks seconds
- ---- ------ -------
5 5 2 0.000002
盡管如此,當N變大時,差異就顯現出來了:
$ ./fib -n 40 -r
i F(i) clocks seconds
- ---- ------ -------
40 102334155 543262 0.543262
$ ./fib -n 40 -s
i F(i) clocks seconds
- ---- ------ -------
40 102334155 330824 0.330824
$ ./fib -n 40 -i
i F(i) clocks seconds
- ---- ------ -------
40 102334155 2 0.000002
一旦你超過N=50,遞回和基于堆疊的版本的運行時間就會變得令人厭惡地長,而迭代版本的運行時間則沒有變化:
$ ./fib -n 50 -r
i F(i) clocks seconds
- ---- ------ -------
50 12586269025 66602759 66.602759
$ ./fib -n 50 -s
i F(i) clocks seconds
- ---- ------ -------
50 12586269025 39850376 39.850376
$ ./fib -n 50 -i
i F(i) clocks seconds
- ---- ------ -------
50 12586269025 2 0.000002
現在,這是事情在我的系統上的表現,這是一個使用非常粗糙的工具(對clock的幾個呼叫)的0級分析。
uj5u.com熱心網友回復:
我用-O3和-fno-inline比較了兩個階乘函式。因為有行內的兩個版本都是一樣的! 即使如此,遞回函式也不會呼叫自己;但它會以某種方式保留一條額外的指令:
sub 和 cmp
11e0: 89 fa mov edx,edi
11e2: | | 83 ef 01 sub edi,0x1.
11e5: | | 0f af c2 imul eax,edx
11e8: | | 83 ff 01 cmp edi,0x1.
11eb: |-- 75 f3 jne 11e0 <frec 0x10>
非rec:更緊密的內回圈:
11c0: | /-> 44 0f af c0 imul r8d,eax
11c4: | | 83 e8 01 sub eax,0x1.
11c7: |-- 75f7 jne 11c0 <fnonrec 0x10>
程式:
int fnonrec(int n) {
int p = 1;
while (n-- > 1)
p *= n;
return p。
}
int frec(int n) {
if (n == 1)
return 1;
return (n * frec(n-1) )。)
}
int main(void) {
for (int i = 0; i < 10000; i )
//printf("%d
", frec(rand()00 1));
printf("%d
", fnonrec(rand()%1000 1) )。
}
兩者都需要8毫秒重定向到dev/null,遞回在上述(馬虎、溢位)形式中多做了50%的指令。
直到
-O1 frec() 遞回呼叫自己;如果沒有 "keep-recursion "編譯標志,就很難進行公平比較。只有行內可以被控制,這與遞回有關:
fno-inline。即使編譯器將其行內到自身。洗掉遞回并不是行內。uj5u.com熱心網友回復:
為什么看似等價的迭代實作仍然沒有比遞回實作更好的表現?我是否有什么明顯的錯誤,或者有什么東西其實是隱藏在眾目睽睽之下的?
因為在禁用優化的情況下對代碼進行基準測驗是完全無稽之談。gcc -O0禁用了所有的優化(但據說可以提高編譯速度)。在比較這兩個片段的效率時,你實際上已經禁用了回圈解卷、尾部呼叫優化和其他一切極其相關的功能。
此外,為了使比較盡可能公平,我在編譯這兩段代碼時使用了 -O0 標志以禁用編譯器優化。
不,你讓它盡可能的不公平,因為你可以做到。
你基本上拿了兩輛跑車,去掉了發動機,然后手動將它們分別推下兩個不同的斜坡,看看哪輛車最快......
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/319321.html
標籤: