我正試圖用ggplot繪制土壤剖面圖。然而,geom_col首先將所有沙層分組,然后是所有泥炭層,最后是所有粘土層。我希望這個順序取決于我的資料框架中的順序,或者,取決于depth_min的順序。因此,第一個剖面是沙-泥-泥炭-沙,最后一個是泥炭-泥炭-泥炭。 我試著用順序作為一種審美,但這似乎已經過時了,我在網上廣泛搜索,但只找到了許多關于顛倒堆疊順序或改變圖例順序的帖子。有什么解決辦法嗎?或者,也許我不應該使用geom_col,而應該使用其他函式(最好是ggplot)?
可重復的例子:
d <- read.csv(text='Location,depth_min,depth_max, depth,software
1,0,20,20,沙
1,20,30,10,粘土
1,30,60,30,泥炭
1,60,100,40,沙土
2,0,30,30,粘土
2,30,90,60,泥炭
3,0,40,40,泥炭
3,40,70,30,粘土
3,70,120,50,泥炭',header=T)
d %>%。
ggplot(aes(x=Location, y=depth。 填充=土壤))
geom_col(position="stack")
scale_y_reverse()
theme_bw()
uj5u.com熱心網友回復:
嘗試使用geom_segment()而不是geom_col()。下面是一個例子,它應該能讓你更接近你所尋找的東西:
d %>%
ggplot()
geom_segment(aes(x = Location,)
xend = Location,
y = depth_min,
yend = depth_max,
color = soil),
size = 2)
scale_y_reverse()
uj5u.com熱心網友回復:
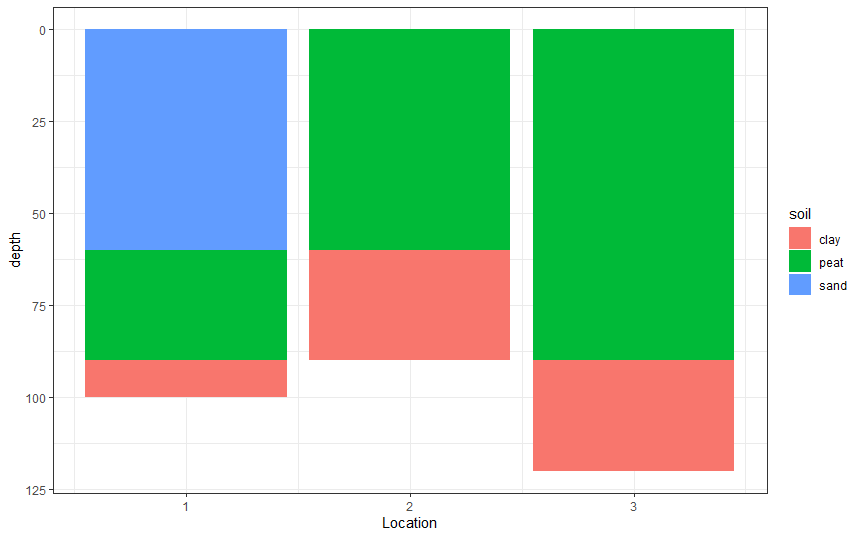
實作你所期望的結果的一個選項是為你的資料添加一個索引或順序列,這可以映射到group審美上,以你所期望的順序堆疊你的資料:
library(dplyr)
library(ggplot2)
d %>%。
group_by(Location) %>%
mutate(order = row_number()) %> %
ggplot(aes(x=Location, y=depth。 填充=土壤。 group = order))
geom_col(position="stack")
scale_y_reverse()
theme_bw()
uj5u.com熱心網友回復:
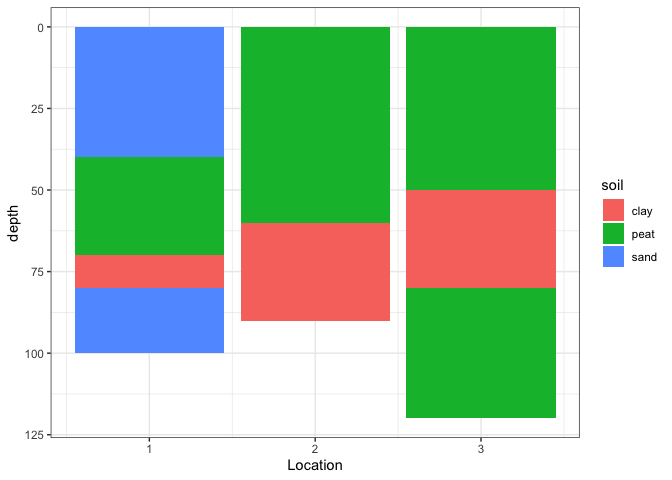
排序/控制堆疊的一種方法是將你的填充變數強制變成一個向量,并按照你所需要的順序定義層次。
library(dplyr)
library(ggplot2)
# check what the following delivers
d %> %突變(soil2 = factor(soil。 水平= c("泥炭"。 "粘土"。 "沙子"))%> % pull(soil2)
這就給了你一個具有定義排序的因子
[1]沙土 泥炭 沙土 泥炭 泥炭
級別:泥炭粘土沙子
假設這就是我們想要的,我們可以將其注入ggplot中。 ggplot將按照因子水平排序。
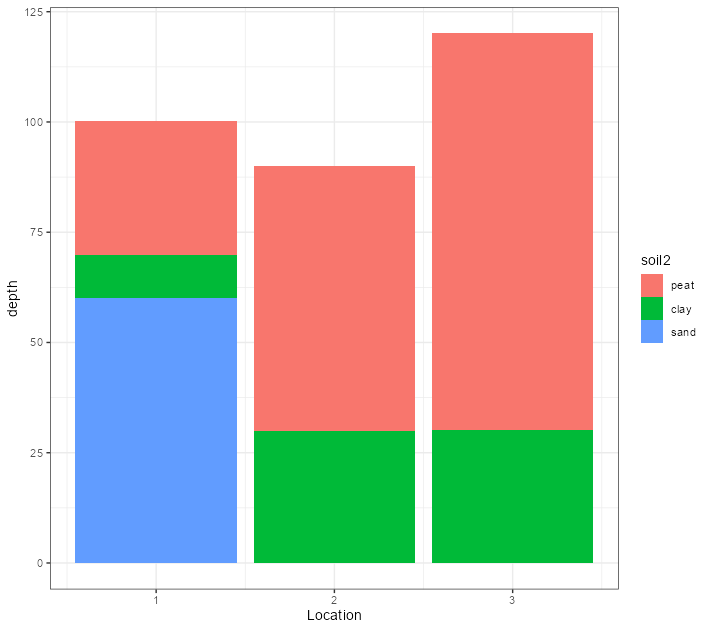
d %>%
突變(soil2 =因子(soil, 水平= c("泥炭"。 "粘土"。 "沙子"))%> %
ggplot(aes(x=Location, y=depth。 填充= soil2))
geom_col(position="stack")
theme_bw()
Voila。
嘗試改變因子水平的順序,看看這對堆疊順序的影響。
如果你想分割你的填充物,你需要為其引入一個單獨的變數,并按照上面的規定將其提供給組審美。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/330223.html
標籤: