我喜歡畫2x2/BCG矩陣。這次我有一個相當大的資料集(超過50個主題和多個值,例如A和B)。我想知道我怎樣才能用Python來畫這個?
結果應該是類似的。
結果應該是這樣的:
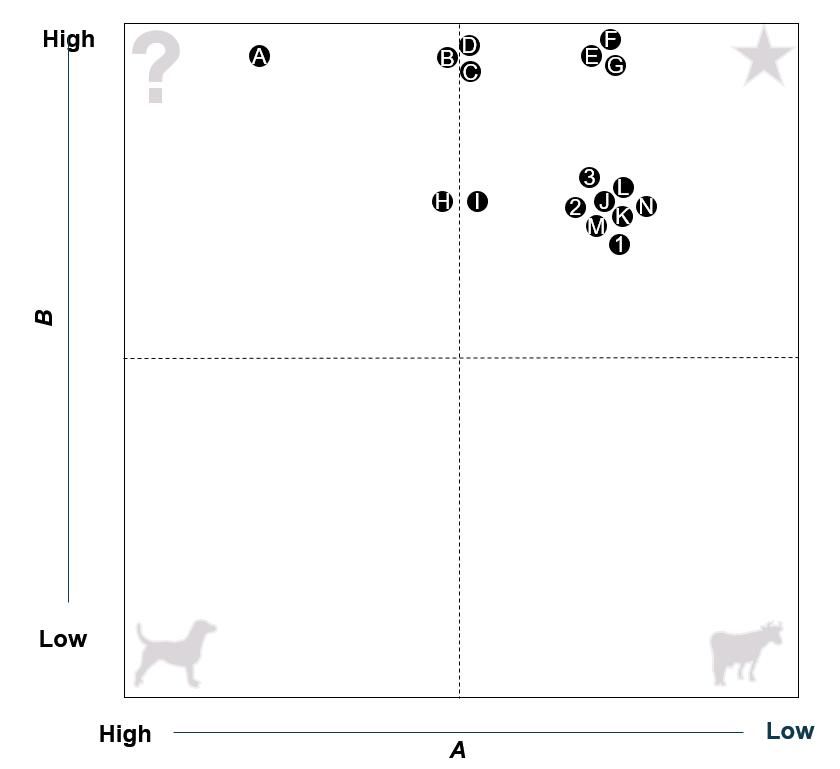
我找到了幾個關于散點圖的問題,但沒有一個能真正很好地處理例如兩個數值相同的主題(見圖中的主題3、2、L、J...)。
ID應該顯示在圖中,具有相同數值的ID不應該重疊,而應該保持在一起。
有什么方法可以做到這一點嗎?如果沒有Python,我也很樂意聽取其他建議。
下面是一個資料集的例子:
ID Name value_A value_B
A topic_1 2 4
B topic_24 2
C 主題_3 3 3
D 主題_4 3 5
E 主題_5 3 4
F 主題_6 5 1
G主題_7 4 5
H主題_8 1 2
I topic_94 1
J 主題_10 3 3
K 主題_11 5 5
L 主題_12 5 3
M主題_13 3 5
N 主題_14 1 5
O 主題_15 4 1
P topic_16 4 2
Q topic_17 1 5
R 主題_18 2 3
S topic_19 1 2 2
T主題_20 5 1
U topic_21 3 4 4
V topic_22 2 5 5
W 主題_23 1 3
X 主題_24 3 3
Y 主題_25 4 1
Z主題_26 2 4
1 topic_27 2 4
2 topic_28 5 4
3 topic_29 3 3
4 topic_30 4 4
5 topic_31 3 2
6 topic_32 4 2
7 topic_33 2 3
8 topic_34 2 3
9 topic_35 2 5
10 topic_36 4 2
uj5u.com熱心網友回復:
下面的代碼應該很接近你要找的東西,我想。基本的想法是,聚集在某一位置的每一組點都被放置在以該位置為中心的圓內。我以一種臨時的方式定義了圓的半徑,只是為了使它在我遇到的尺寸中看起來更漂亮,但你可能需要為你的具體任務改變一下。
首先,這只是將你的值復制/粘貼到一個串列中。
values = ['ID Name value_A value_B',
'A topic_1 2 4'。
'B topic_2 4 2'。
'C topic_3 3 3'。
'D topic_4 3 5'。
'E topic_5 3 4'。
'F topic_6 5 1'。
'G topic_7 4 5'。
'H topic_8 1 2',
'I topic_9 4 1',
'J topic_10 3 3'。
'K topic_11 5 5'。
'L topic_12 5 3'。
'M topic_13 3 5'。
'N topic_14 1 5',
'O topic_15 4 1',
'P topic_16 4 2'。
'Q topic_17 1 5'。
'R topic_18 2 3'。
'S topic_19 1 2',
'T topic_20 5 1',
'U topic_21 3 4'。
'V topic_22 2 5'。
'W topic_23 1 3',
'X topic_24 3 3',
'Y topic_25 4 1',
'Z topic_26 2 4'。
'1 topic_27 2 4'。
'2 topic_28 5 4'。
'3 topic_29 3 3'。
'4 topic_30 4 4'。
'5 topic_31 3 2'。
'6 topic_32 4 2'。
'7 topic_33 2 3'。
'8 topic_34 2 3'。
'9 topic_35 2 5'。
'10 topic_36 4 2']
接下來,把你上面提供的資料,以稍微不同的方式組織成一個ID的串列和另一個A和B的值。
import re
values = [re.split(r's ', v) for v in values] [1:]
points = [[int(v[2]), int(v[3)] ] for v in values ]
labels = [v[0] for v in values ]
現在我們需要找到唯一的AB對和它們的ID。有很多方法可以從你的原始串列中得出這個結果,其他人可能會根據你的原始資料結構和效率考慮,提出改進建議。
unique_points = []
n_labels = []
for i in range(len(point))。
if points[i] not in unique_points:
unique_points.append(point[i])
n_labels.append([labels[i],])
else:
n_labels[unique_points.index(point[i])] = [labels[i],]. = [標簽[i],]
在我的另一個專案中,我設計了這個類來做一些與你想做的事情非常相似的事情,所以我在這里用一些變化來重新實作它。基本上,每個獨特的點和伴隨的ID都進入了他們自己的物件,這使得你可以很容易地將這些點繪制在以獨特的點為中心的圓中。
import numpy as np
from matplotlib import pyplot as plt
class clique()。
def __init__(self, center, labels, r)。
self.n = len(label)
self.x = center[0]
self.y = center[1]
self.labs = labels
self.r = r
# 下面的隨機加法只是將點旋轉一下。
# 圓圈,所以相同大小的組看起來是不同的。
self.theta = np.range(0, 2 * np.pi, 2 * np.pi / self.n) np.random.rand() *2 * np.pi
if self.n == 1:
self.nodes_x = [self.x,] 自身.nodes_y = [self.x,]。
self.nodes_y = [self.y,] 自身.nodes_y = [self.y,]。
else:
self.nodes_x = self.x r * np.cos(self.theta)
self.nodes_y = self.y r * np.sin(self.theta)
def draw_nodes(self, shape = 'o', color = 'k', markersize = 12)。)
for i in range(len(self.nodes_x))。
plt.plot(self.nodes_x[i], self.nodes_y[i], shape, color = color,
markersize = markersize)
def label_nodes(self, color = 'w'/span>, fs = 10) 。
for i in range(len(self.nodes_x))。
plt.text(self.nodes_x[i], self.nodes_y[i], self.labels[i],
va = 'center', ha = 'center', color = color, fontsize = fs)
現在,為每個點群創建clique物件并繪制它。
for i in range(len(unique_points))。
radius = 0.05 0.2 / 5 * len(n_labels[i])
G = clique(unique_points[i], n_labels[i], radius)
G.draw_nodes()
G.label_nodes()
最后,再清理一下繪圖。
plt.axis('equal') # This ensures things look circular on the
# 數字。如果你想要非等軸和一個圓形的
# 外觀,你需要計算出 的方程。
# 在 "clique "中繪制基于的橢圓。
# 圖形尺寸
A = np.array([u[0] for u in unique_points] )
B = np.array([u[1] for u in unique_points] )
plt.xticks([min(A), max(A)], ['Low'/span>, 'High'/span>])
plt.yticks([min(B), max(B)], ['Low', 'High'] )
plt.xlabel('A')
plt.ylabel('B')
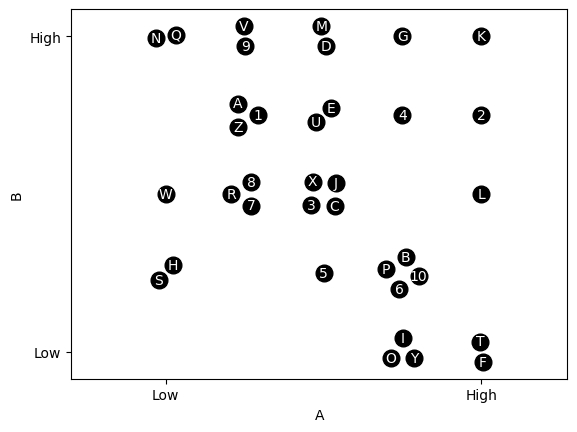
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/331507.html
標籤:
上一篇:沒有這樣的檔案或目錄:'Tensorflow/workspace/annotations\\label_map.pbtxtonJupyter為什么我的代碼不起作用?
下一篇:不確定如何解決TypeError。_utils_ipfs__WEBPACK_IMPORTED_MODULE_5__.default.files.add不是一個函式。