我正在撰寫一個小程式,它從一個文本檔案中讀取,該檔案包含許多我們在雜貨店購買的物品。這個程式是一個更大的應用程式的一部分,我在其中集成了 Python 和 C ,但為了簡單起見,我隔離了應用程式的這部分,因為它似乎是問題所在。
問題是文本檔案(菠菜)中的第一項在 txt 檔案中出現了 5 次,但程式列印了一些垃圾資料,然后是 Spinach,然后是 1 作為表示 Spinach 在檔案中出現的次數的數字。但應該是 5。在專案串列的下方,您還可以看到再次列印了 Spinach 一詞,但這次用數字 4 表示它在 txt 檔案中存在的次數。但是菠菜這個詞應該只列印一次,數字 5 代表它在 txt 檔案中存在的時間。例如,菠菜 - 5。查看下圖。
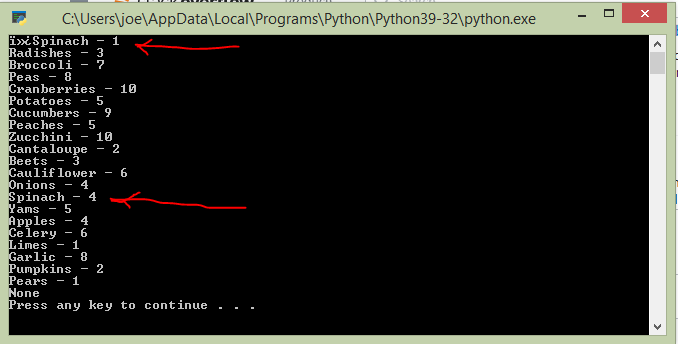 ,
,
我不確定問題是否出在 freq = {} 字典中。拜托,有人可以幫我找出導致問題的原因嗎?請具體點,因為我剛剛在學習 python。請查看以下 .py 檔案的代碼,并查看 .txt 檔案中的專案串列。
預先感謝您的幫助。
應用程式
def wordFrequency(item): # This function gets called printed out by WordFrequency , it takes one argument which passes from cpp
count = 0 # this variable is use to count the frequency of the list iitem
with open('items.txt')as myfile: # opening file
lines = myfile.readlines() #reading all the lines of the file
for line in lines:
if(line.strip("\n") == item): # removing the \n from the last
count 1
myfile.close()
return count
# Display only
def displayWordFrequency():
with open('items.txt')as myfile: # opening file
lines = myfile.readlines()
freq ={} # using dictionary to store the value of the list
for line in lines:
if(line.strip("\n") in freq): # put the condition if the value is present aleady then it will increment it otherwise it will put one for it
freq[line.strip("\n")] = 1 #strip to remove \n which passes as an argument
else:
freq[line.strip("\n")] = 1
for key , value in freq.items(): # loops through dictionary and prints the values
print(f"{key} - {value}") # Key is the string and the value is the integer
myfile.close()
print(displayWordFrequency())
專案.txt
Spinach
Radishes
Broccoli
Peas
Cranberries
Broccoli
Potatoes
Cucumbers
Radishes
Cranberries
Peaches
Zucchini
Potatoes
Cranberries
Cantaloupe
Beets
Cauliflower
Cranberries
Peas
Zucchini
Peas
Onions
Potatoes
Cauliflower
Spinach
Radishes
Onions
Zucchini
Cranberries
Peaches
Yams
Zucchini
Apples
Cucumbers
Broccoli
Cranberries
Beets
Peas
Cauliflower
Potatoes
Cauliflower
Celery
Cranberries
Limes
Cranberries
Broccoli
Spinach
Broccoli
Garlic
Cauliflower
Pumpkins
Celery
Peas
Potatoes
Yams
Zucchini
Cranberries
Cantaloupe
Zucchini
Pumpkins
Cauliflower
Yams
Pears
Peaches
Apples
Zucchini
Cranberries
Zucchini
Garlic
Broccoli
Garlic
Onions
Spinach
Cucumbers
Cucumbers
Garlic
Spinach
Peaches
Cucumbers
Broccoli
Zucchini
Peas
Celery
Cucumbers
Celery
Yams
Garlic
Cucumbers
Peas
Beets
Yams
Peas
Apples
Peaches
Garlic
Celery
Garlic
Cucumbers
Garlic
Apples
Celery
Zucchini
Cucumbers
Onions
uj5u.com熱心網友回復:
您可以使用字典理解回圈遍歷set資料以洗掉重復項來實作這一點。要保持順序,您必須回顧原始串列
# see question for full list
s = """Spinach
Radishes
Broccoli
Peas
Cranberries
Broccoli
Potatoes
Cucumbers
...
Celery
Zucchini
Cucumbers
Onions"""
s = s.split('\n') # get the data as list
s_dict = {k: s.count(k) for k in set(s)}
original_indices = sorted(map(s.index, set(s)))
print('\n'.join(' - '.join((s[i], str(s_dict[s[i]]))) for i in original_indices))
編輯
如果您使用字典并且順序很重要,最好使用標準庫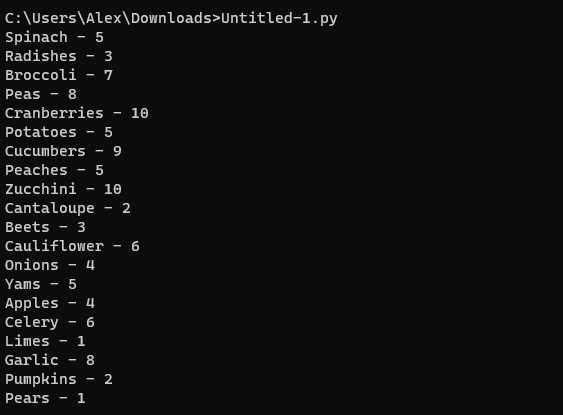
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/334484.html
上一篇:無效的地圖鍵型別“識別符號”