在一個很長的字串中,我想洗掉以 開頭的所有內容,SPAIN: 直到我們連續獲得至少 4 個以 a 結尾的大寫字母: (即INDIA: orSOUTH AFRICA: 或NORTHERN-IRELAND:)。
我的嘗試 A2 是很長的字串:
=REGEXREPLACE(A2,"SPAIN: .*([A-Zà-?\-\' ]{4,}): ","$1: ")
不幸的是,上面的方法不起作用,因為它會擦除字串中的最后 4 個大寫字母之前的所有內容。
有任何想法嗎?
此處使用的作業表示例: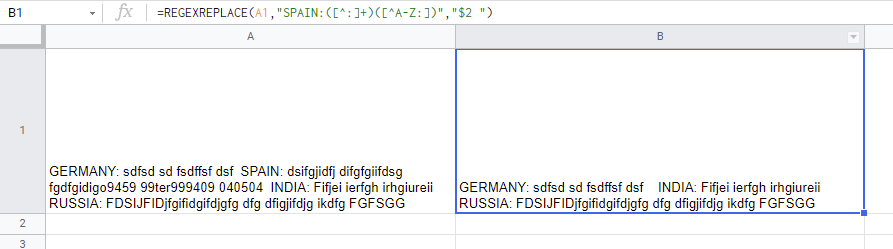
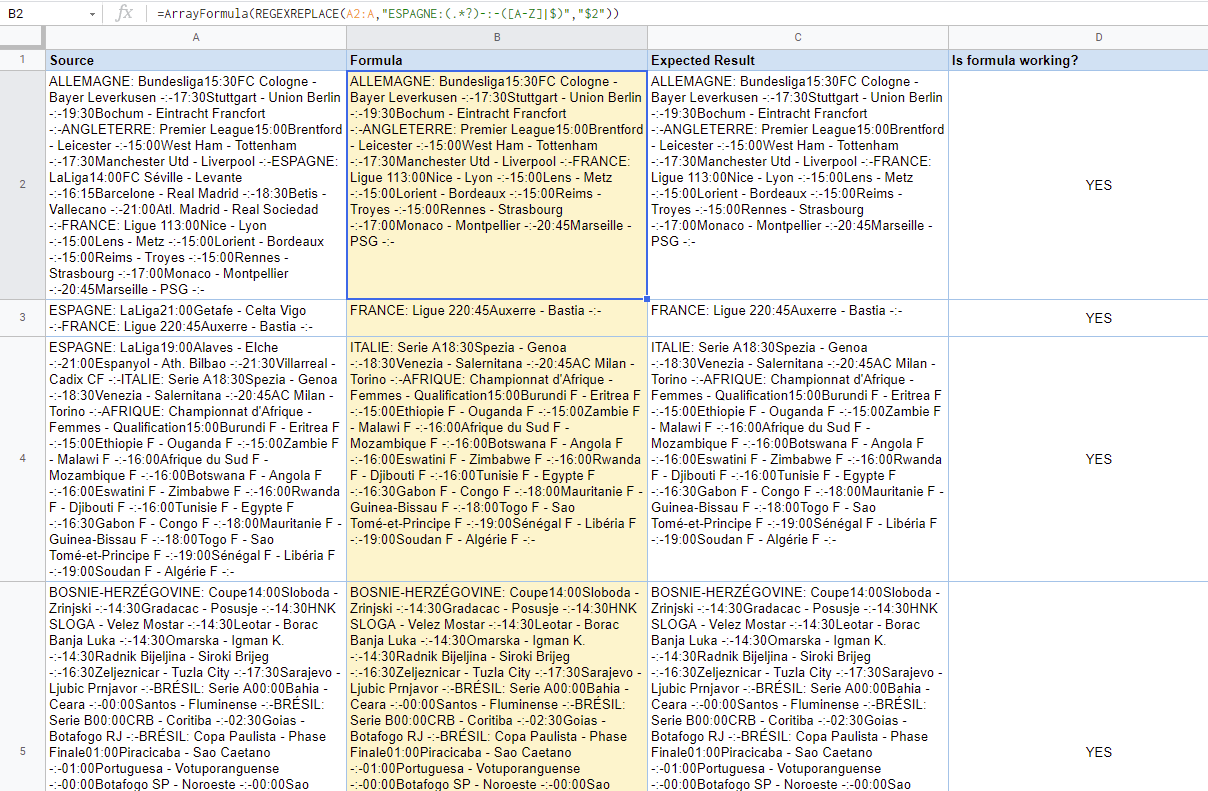
對于樣品表將作業以下公式:
=ArrayFormula(REGEXREPLACE(A2:A,"ESPAGNE:(.*?)-:-([A-Z]|$)","$2"))
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/335163.html