我在輸入中有一個 datafame,我想在“本地化”列中提取此串列中的單詞 ["SECTION 11","C?NE","BELLY"],我必須在資料框中創建新列“單詞”。如果串列中的單詞存在于“localisation”列中,我會在創建的“word”列中填寫單詞。否則我將全文放在“word”列中 這是我的資料框
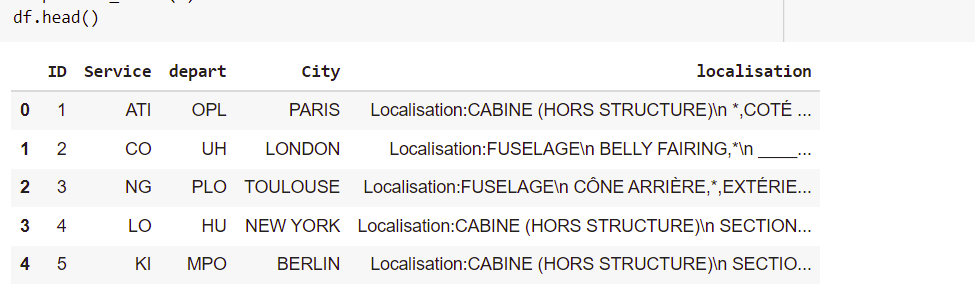
我創建了新列“word” 我從串列中選擇了包含單詞的行 我用從串列中找到的關鍵字填充“word”列
["SECTION 11","C?NE","BELLY"]
df["temp"]=df["localisation"].str.extract("Localisation[\s]*:.*\n([^_\n]{3,})\n[^\n]*\n")
df["word"]=df["temp"].str.extract("(SECTION 11|C?NE|BELLY)")
df["temp"]=df["localisation"].str.extract("Localisation[\s]*:.*\n([^_\n]{3,})\n[^\n]*\n")
df["word"]=df["temp"].str.extract("(SECTION 11|C?NE|BELLY)")
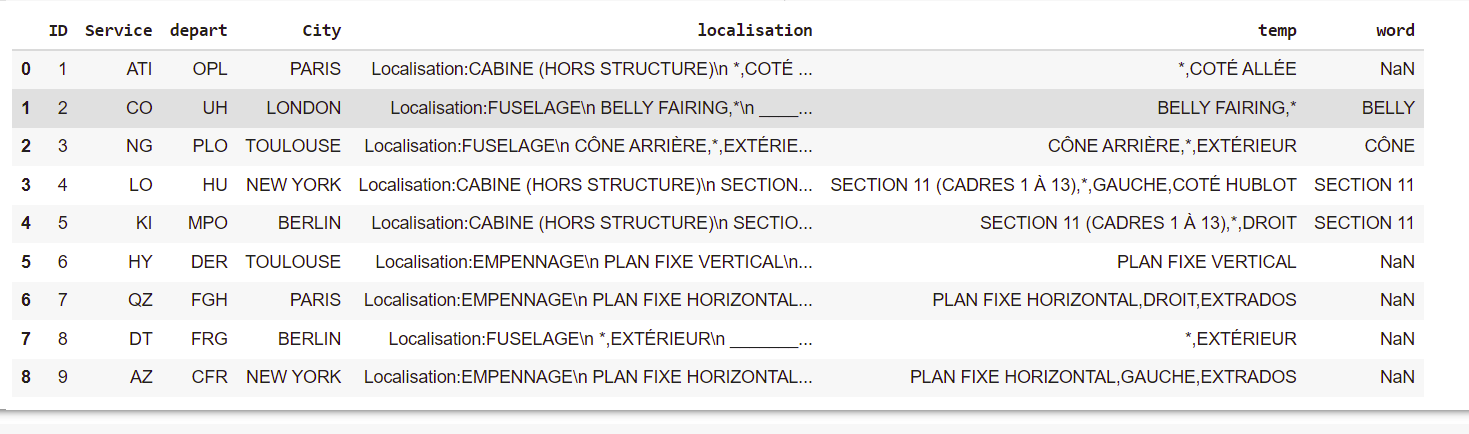
我的問題如果在“本地化”列中找不到串列中的單詞,我將無法放置全文。我的行中有空值或者我必須放全文
uj5u.com熱心網友回復:
您需要.fillna與df["localisation"]as 引數一起使用:
df["word"]=df["localisation"].str.extract(r"\b(SECTION 11|C?NE|BELLY)\b", expand=False).fillna(df["localisation"])
另請注意,我建議r"\b(SECTION 11|C?NE|BELLY)\b"使用帶有單詞邊界的正則運算式,僅將您的替代詞作為整個單詞匹配。請注意,在 Pandas 的幕后使用\bPython中的單詞邊界是可識別 Unicode 的re。
如果您不需要全詞搜索,您可以繼續使用r"SECTION 11|C?NE|BELLY"。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/342422.html