我在這里檢查了建議: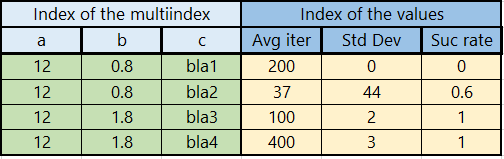
不創建多索引并在下一行中設定每個值的代碼:
df_a = pd.DataFrame.from_dict(dictionary, orient="index").stack().to_frame()
df_b = pd.DataFrame(df_a[0].values.tolist(), index=df_a.index)
uj5u.com熱心網友回復:
使用ast.literal_eval每個字串轉換成字典,并建立從那里指數:
import pandas as pd
from ast import literal_eval
dictionary ={
"{'a': 12.0, 'b': 0.8, 'c': ' bla1'}": [200, 0.0, '0.0'],
"{'a': 12.0, 'b': 0.8, 'c': ' bla2'}": [37, 44, '0.6'],
"{'a': 12.0, 'b': 1.8, 'c': ' bla3'}": [100, 2.0, '1.0'],
"{'a': 12.0, 'b': 1.8, 'c': ' bla4'}": [400, 3.0, '1.0']
}
keys, data = zip(*dictionary.items())
index = pd.MultiIndex.from_frame(pd.DataFrame([literal_eval(i) for i in keys]))
res = pd.DataFrame(data=list(data), index=index)
print(res)
輸出
0 1 2
a b c
12.0 0.8 bla1 200 0.0 0.0
bla2 37 44.0 0.6
1.8 bla3 100 2.0 1.0
bla4 400 3.0 1.0
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/343388.html