我試圖將所有 3 個 Pandas 資料幀組合在一起data, data2, data3,以同步順序對它們進行排序date,并洗掉所有重復的行。不超過 1 個date值必須相同,但是 '2021-10-21 00:03:00' 的日期同時存在data2,data3因此輸出中應該只存在一行。我可以添加什么到 coed 以便我實作Expected Output?
代碼:
import pandas as pd
data = {'Unix Timesamp': [1444311600000, 1444311660000, 1444311720000],
'date': ['2015-10-08 13:40:00', '2015-10-08 13:41:00', '2015-10-08 13:42:00'],
'Symbol': ['BTCUSD', 'BTCUSD', 'BTCUSD'],
'Open': [10384.54, 10389.08,10387.15],
'High': [10389.08, 10389.08, 10388.36],
'Low': [10340.2, 10332.8, 10385]}
data2 = {'Unix Timesamp': [1634774460000, 1634774520000, 1634774580000],
'date': ['2021-10-21 00:01:00', '2021-10-21 00:02:00', '2021-10-21 00:03:00'],
'Symbol': ['BTCUSD', 'BTCUSD', 'BTCUSD'],
'High': [4939.97, 4961.75, 4964.33],
'Open': [4939.95, 4959.18,4964.33]}
data3 = {'Unix Timesamp': [1634774640000, 1634774640000],
'date': ['2021-10-21 00:03:00', '2021-10-21 00:04:00'],
'High': [4964.33, 4867.33],
'Symbol': ['BTCUSD', 'BTCUSD'],
'Open': [4964.33, 4800.2]}
dataset = pd.DataFrame.from_dict(data)
dataset2 = pd.DataFrame.from_dict(data2)
dataset3 = pd.DataFrame.from_dict(data3)
dataset.drop('Low',1).append([dataset2, dataset3], ignore_index=True).drop_duplicates()
輸出:
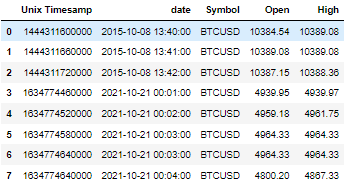
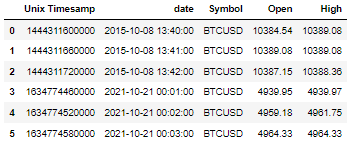
預期輸出(輸出中的第 6 行不應存在):
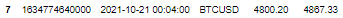
uj5u.com熱心網友回復:
下面的代碼應該滿足您的要求。確保在.drop_duplicates()方法的括號內包含“ subset=['date'] ” 。示例:.drop_duplicates(subset=['date'])
dataset.drop('Low',1).append([dataset2, dataset3],ignore_index=True).drop_duplicates(subset=['date'])
有關更多資訊,請參閱https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.drop_duplicates.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/343394.html
上一篇:將日期時間索引與日期時間列進行比較并更改另一列中的相應值
下一篇:Pandas-回圈作業表