在我正在處理的資料集中,每個唯一 ID 都有一個總薪酬。我已經通過使用總結了每個 ID 的總支付
df['Total Courier Pay'] = df.groupby(['ID'])['Total Pay'].transform(sum)
df
excel 表中的輸出如下所示:
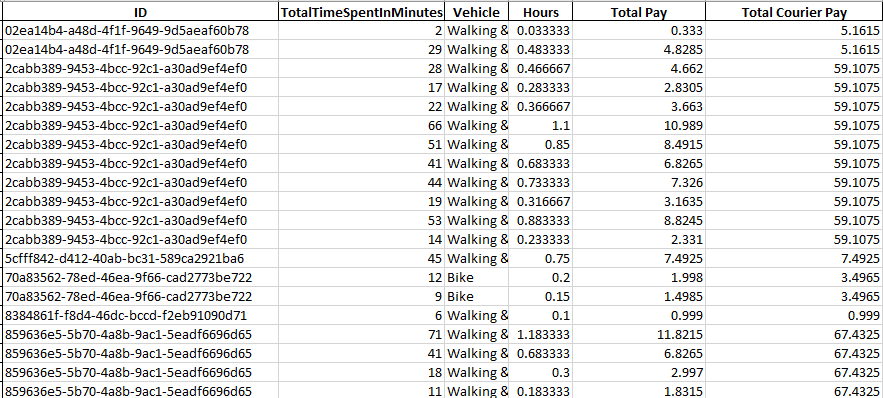
我很高興保留顯示的所有列,但有沒有辦法清理它,使其看起來更像這樣,而不是每個 ID 都有重復的行?:
ID Total Courier Pay
1 5.1615
2 59.1075
3 7.4925
是否可以在僅顯示 ID 和 Total Courier Pay 的同一作業簿中創建新作業表?
提前致謝!
uj5u.com熱心網友回復:
df['Total Courier Pay'] = df.groupby(['ID'])['Total Pay'].transform(sum)
new_df = df.drop_duplicates(subset=['ID'])[['ID','Total Courier Pay']]
uj5u.com熱心網友回復:
經過@Pedro Maia 的一些幫助并閱讀了其他一些論壇,這似乎對我有用:
df.drop_duplicates('ID', inplace=True)
感謝您的幫助 :) - 這將更改當前的 Excel 作業表而不是創建一個新的作業表。
uj5u.com熱心網友回復:
根據您的示例,您似乎只想創建一個單獨的 DataFrame,其中只有“ID”和“Total Courier Pay”。在這種情況下,你可以做
total_pay_by_ID = (
df.groupby('ID', as_index=False)['Total Pay']
.sum()
.rename(columns={'Total Pay': 'Total Courier Pay'})
)
是否可以在僅顯示 ID 和 Total Courier Pay 的同一作業簿中創建新作業表?
要將其保存到'sheet_name'現有 Excel 檔案的新作業表中,'path/to/excel/file.xlsx'您可以執行以下操作
with pd.ExcelWriter('path/to/excel/file.xlsx', mode='a') as writer:
total_pay_by_ID.to_excel(writer, sheet_name='sheet_name')
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/343409.html
下一篇:從具有相似前綴的列中劃分元素