我正在使用以下腳本在 Athena 中創建一個表
CREATE EXTERNAL TABLE `itcfmetadata`(
`itcf id` string,
`itcf control name` string,
`itcf control description` string,
`itcf process` string,
`standard` string,
`controlid` string,
`threshold` string,
`status` string,
`date reported` string,
`remediation (accs specific)` string,
`aws account id` string,
`aws resource id` string,
`aws account owner` string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
LOCATION
's3://itcfmetadata/'
TBLPROPERTIES (
'skip.header.line.count'='1');
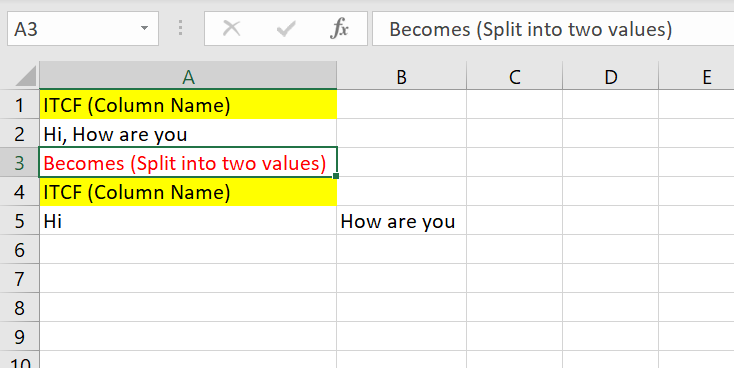
S3 源檔案是 csv 檔案。這個檔案是從一個excel檔案轉換而來的,這個csv檔案沒有逗號分隔值,它更像是一個excel檔案。問題是當任何列包含諸如“嗨,你好嗎”之類的文本時。它被分成兩部分,因為有一個逗號,“嗨”和“你好嗎”變成兩個值并分成兩行。如何使用上面的創建腳本避免這種情況?
CSV 檔案:
uj5u.com熱心網友回復:
嘗試使用
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
代替 DELIMITED
該DELIMITED解串器只是看你提供的分隔符。csv deserializet 將只使用一對雙引號之外的那些"。
查看檔案:https : //docs.aws.amazon.com/athena/latest/ug/csv-serde.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/346024.html
上一篇:使用hcl2創建ami時出現Packer錯誤:“查詢AMI時出錯:InvalidAMIID.Malformed:ID無效:”